Data Scientist Loves to code in Java, Scala – Areas of Interest: Big Data, Data Analytics, Machine Learning, Hadoop, Cassandra – Currently working as Team Lead for Managed Security Services Portal at Verizon
PB – Convert 350 billion annual meter readings to better predict power consumption – Turn 12 terabytes of Tweets created each day into improved product sentiment analysis • Types – structured, semi/un-structured – Text, audio, video, click streams, logs, machine – Monitor 100’s of live video feeds from surveillance cameras to target points of interest • Velocity (time sensitive) – ideally processed as it is streaming (realtime, near-realtime, batch) – Scrutinize 5 million trade events created each day to identify potential fraud – Analyze 500 million daily call detail records in real-time to predict customer churn faster
a sea of data, sometimes we throw away a lot. • Still we cant make much sense of it • We consider data as a cost • But Data is an opportunity • This is what Big Data is about – New Insights – New Business
• Based on papers published by Google – MapReduce: http://research.google.com/archive/mapreduce.html – GFS: http://research.google.com/archive/gfs.html
in 2007 • Average job size: 180Gb • Time 180Gb of data would take to read sequentially off a single disk drive: 45 minutes • Solution: parallel reads • – 1 HDD = 75Mb/sec • – 1,000 HDDs = 75Gb/sec (Far more acceptable) • Data Access Speed is the Bottleneck • We can process data very quickly, but we can only read/write it very slowly
The Hadoop Distributed File System (HDFS) – MapReduce • There are many other projects based around core Hadoop – Often referred to as the “Hadoop Ecosystem” – Pig, Hive, HBase, Flume, Oozie, Sqoop etc • A set of machines running HDFS and MapReduce is known as a Hadoop Cluster • Individual machines are known as nodes. A cluster can have as few as one node, as many as several thousands • More nodes = better performance
of one part of the system should result in a graceful decline in performance. Not a full halt • System should support data recoverability – If components fail, their workload should be picked up by still functioning units • System should support individual recoverability – Nodes that fail and restart should be able to rejoin the group activity without a full group restart
Concurrent operations or partial internal failures should not cause the results of the job to change • System should be scalable – – Adding increased load to a system should not cause outright failure. Instead, should result in a graceful decline • Increasing resources should support a proportional increase in load capacity
these issues: – Nodes talk to each other as little as possible, Probably never. – This is known as a “shared nothing” architecture – Programmer should not explicitly be allowed to write code which communicates between nodes • Data is spread throughout machines in the cluster – Data distribution happens when data is loaded on to the cluster • Instead of bringing data to the processors, Hadoop brings the processing to the data
is shipped around) • Heavy Parallelization • Process Management • Append-only files • Express your computation in Map Reduce, get parallelism and and scalability for free
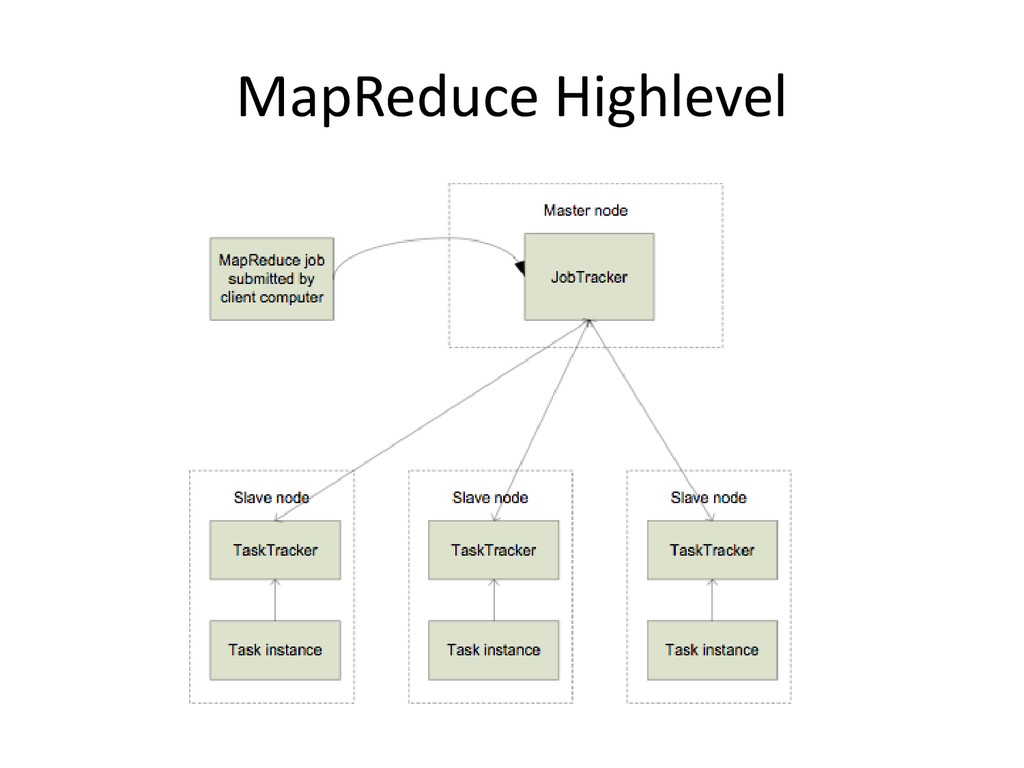
runs one or more daemons executing MapReduce code or HDFS commands. Each daemon’s responsibilities in the cluster are: – NameNode: manages HDFS and communicates with every DataNode daemon in the cluster – JobTracker: dispatches jobs and assigns splits to mappers or reducers as each stage completes – TaskTracker: executes tasks sent by the JobTracker and reports status – DataNode: Manages HDFS content in the node and updates status to the NameNode
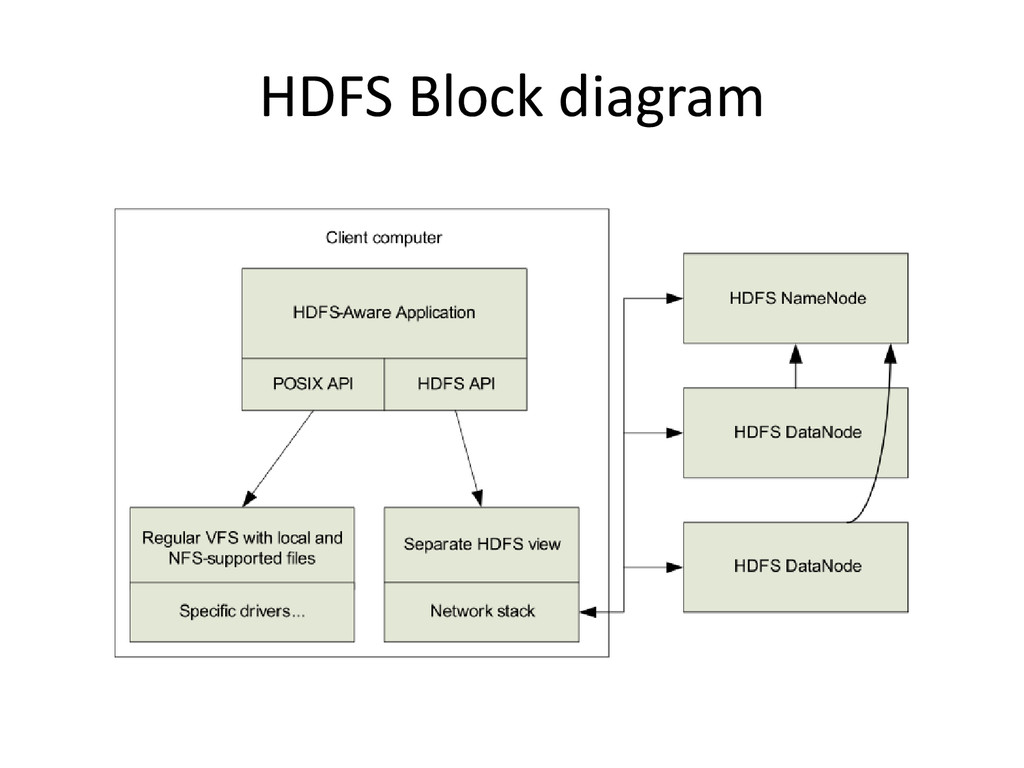
(Google File System) • Provides redundant storage of massive amounts of data – Using cheap, unreliable computers • At load time, data is distributed across all nodes – Provides for efficient MapReduce processing
fail all the time • “Modest” number of HUGE files – Just a few million – Each file likely to be 100Mb or larger – Multi-Gigabyte files typical • Large streaming reads – Not random access • High sustained throughput should be favored over low latency
• Files are stored as ‘blocks’ – Much larger than for most filesystems – Default is 64Mb • Provides reliability through replication – Each block is replicated across three or more DataNodes • Single NameNode stores metadata and co-ordinates access – Provides simple, centralized management • No data caching – Would provide little benefit due to large datasets, streaming reads • Familiar interface, but customize the API – Simplify the problem and focus on distributed applications
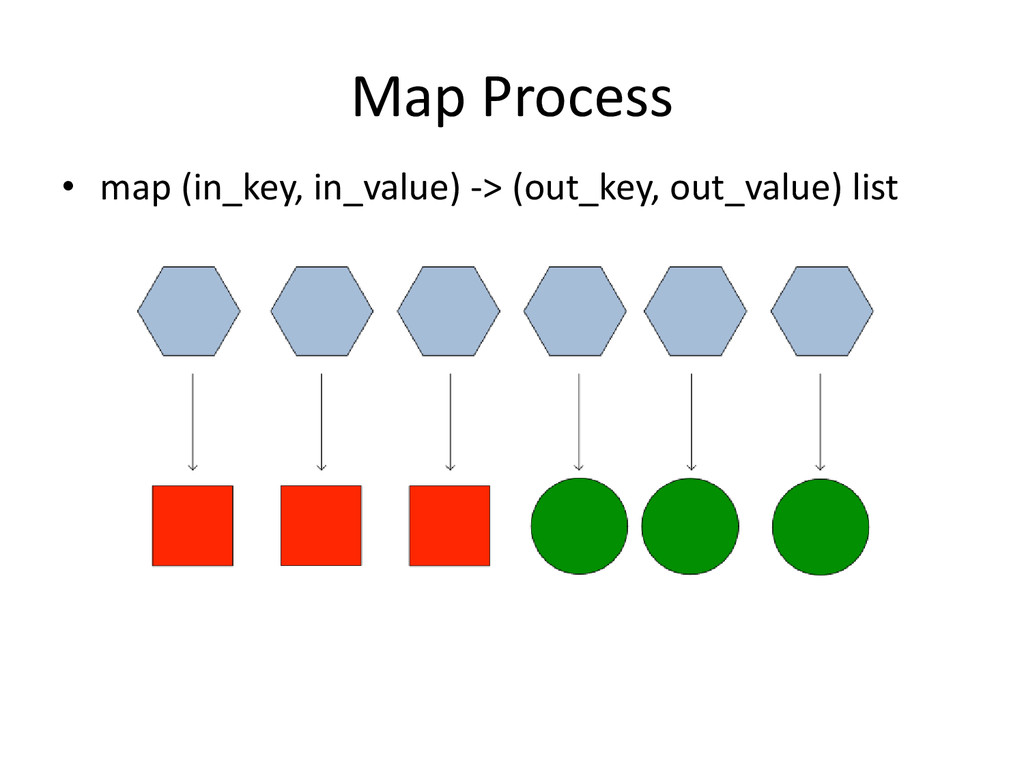
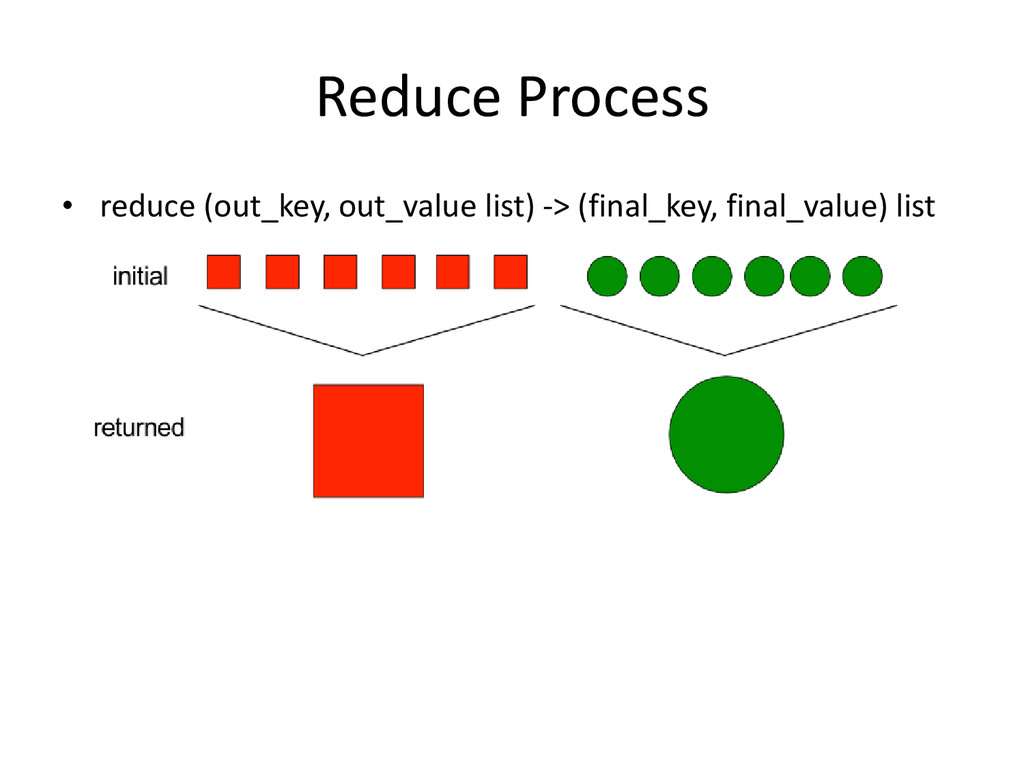
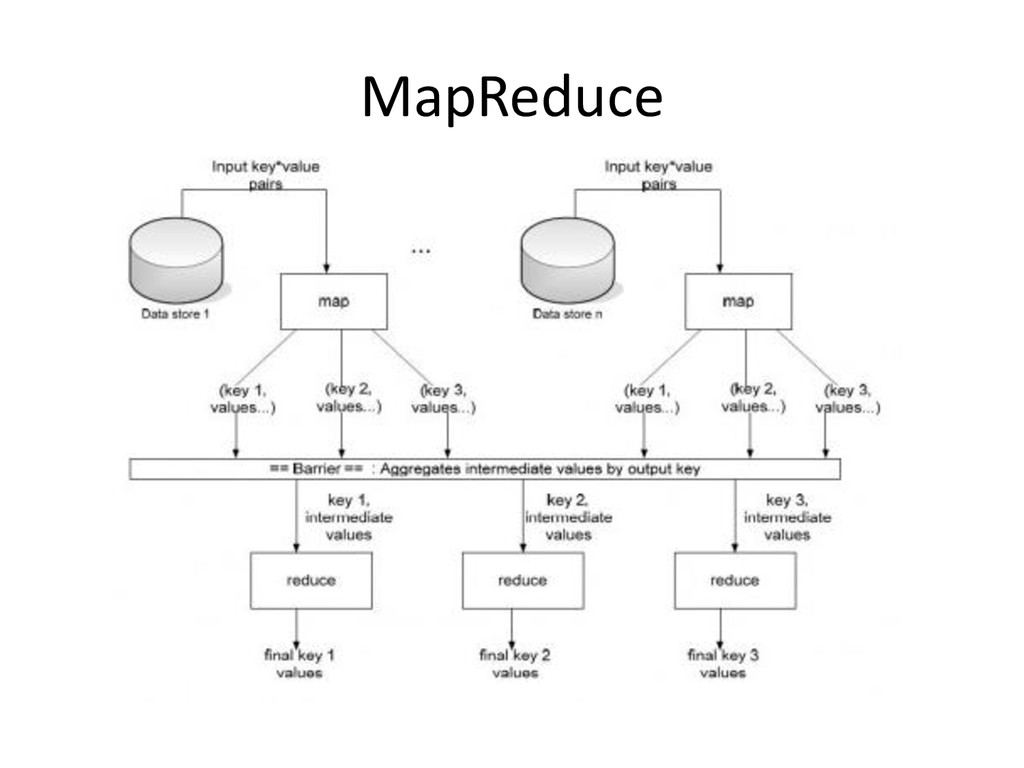
across multiple nodes in the Hadoop cluster • Consists of two phases: Map, and then Reduce – Between the two is a stage known as the shuffle and sort • Each Map task operates on a discrete portion of the overall dataset. Typically one HDFS block of data • After all Maps are complete, the MapReduce system distributes the intermediate data to nodes which perform the Reduce phase
• Status and monitoring tools • A clean abstraction for programmers – – MapReduce programs are usually written in Java – – Can be written in any scripting language using Hadoop Streaming – – All of Hadoop is written in Java • MapReduce abstracts all the “housekeeping” away from the developer – – Developer can concentrate simply on writing the Map and Reduce functions
set of text files k is a line offset v is the line for that offset • let map(k, v) = • for each word in v: • emit(word, 1) • Reduce • // k is a word vals is a list of 1s • let reduce(k, vals) = • emit(k, vals.length())
other than Java – Perl, Ruby, Python, Etc • The Streaming API allows developers to use any language they wish to write Mappers and Reducers – As long as the language can read from standard input and write to standard output • Advantages of the Streaming API: – No need for non-Java coders to learn Java – Fast development time – Ability to use existing code libraries
FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); conf.setMapperClass(WordMapper.class); conf.setMapOutputKeyClass(Text.class); conf.setMapOutputValueClass(IntWritable.class); conf.setReducerClass(SumReducer.class); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); JobClient.runJob(conf); • Driver is submitted to the Hadoop cluster for processing, along with the rest of the code in a .jar file.
has the form: public class WordMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> collector, Reporter reporter) throws IOException { /* implementation here */ } } • The implementation itself uses standard Java text manipulation tools; you can use regular expressions, scanners, whatever is necessary.
IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> collector, Reporter reporter) throws IOException { /* implementation */} } • The reducer iterates over keys and values generated in the previous step and sums up the occurrence of the word
represents a key and value delimited by a separator – TextInputFormat — The key is the byte offset, the value is the text itself for each line – Sequence Input Format — Raw format serialized key/value pairs • Output Formats – Specify final output
warehousing app – Data analysts are very familiar with SQL than Java etc – Hive allows users to query data using HiveQL, a language very similar to standard SQL – Hive turns HiveQL queries into standard MapReduce jobs – Automatically runs the jobs, and displays the results to the user – Note that Hive is not an RDBMS • Results take many seconds, minutes, or even hours to be produced • Not possible to modify the data using HiveQL – Features for analyzing very large data sets
– Pig can be used as an alternative to writing MapReduce jobs in Java (or some other language) – Provides a scripting language known as Pig Latin – Abstracts MapReduce details away from the user – Made up of a set of operations that are applied to the input data to produce output – Fairly easy to write complex asks such as joins of multiple datasets – Under the covers, Pig Latin scripts are converted to MapReduce jobs
datastore • Distributed: designed to use multiple machines to store and serve data • Sparse: each row may or may not have values for all columns • Column-oriented: Data is stored grouped by column, rather than by row. Columns are grouped into ‘column families’, which define what columns are physically stored together – Leverages HDFS – Modeled after Google’s BigTable datastore
distributed, reliable, available service for efficiently moving large amounts of data as it is produced. – Ideally suited to gathering logs from multiple systems and inserting them into HDFS as they are generated • Sqoop – Sqoop is “the SQL-to-Hadoop database import tool” – Designed to import data from RDBMS into Hadoop – Can also send data the other way, from Hadoop to an RDBMS – Uses JDBC to connect to the RDBMS • Oozie – Dataflow
easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing • Spark – Spark is an open source cluster computing system that aims to make data analytics fast. • Impala – real-time processing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions Twitter @joealex Email [email protected]](https://files.speakerdeck.com/presentations/851c34ca51e447ad92c3e0c3e0f7493e/slide_40.jpg){kind=link}