Data Scientist Loves to code in Java, Scala – Areas of Interest: Big Data, Data Analytics, Machine Learning, Hadoop, Cassandra – Currently working as Team Lead for Managed Security Services Portal at Verizon
Data –user generated; Amazon, Social Networks: Twitter, Facebook, Four Square –machine generated; credit cards, RFID, POS, cell phones, GPS, firewalls, routers –more and more connected –less structured –data sets becoming larger and larger –joins and relationships are exploding –cloud computing - scaling and tolerance needs –backing up is replaced with having multiple active copies –nodes can crash and applications should survive –nodes can be added or removed at any point of time
connect to the Internet) – 'Internet of Things' will infuse intelligence into all our systems and present us with a whole new way to run a home, an enterprise, a community or an economy. In a 4G world, wireless will connect everything and that there's really no limit to the number of connections that can be part of the mobile grid: vehicles, appliances, buildings, roads, medical monitors.“ – recently announced a partnership with American Security Logistics (ASL), to "wirelessly connect a series of location based tracking devices that can be used to help keep tabs on an array of valuables - from people to pets to pallets. – 2013, the number of devices connected to the Internet will reach 1 trillion - up from 500 million in 2007.
RDBMS – neither economical or capable – scaling up doesn't work – scaling out with traditional DB is not easy • scaling reads to a relational DB is hard • scaling writes is almost impossible – when you try to do, it is not relational anymore – sharding scales • but you lose all features that make RDBMS useful • operational nightmare – volumes of data strain commercial RDBMS – cloud computing – rethink how we store data. Understand your data, find the most efficient model – de-normalization. normalization strives to remove duplication but duplication is an interesting alternative to joins
•Pros –SQL lets you query all data at once –enforces data integrity –minimizes repetition –proven –familiar to DBA, users •Cons –rigidly schematic –joins rapidly become a bottleneck –difficult to scale up –gets in way of parallization –optimization may mitigate benefits of normalization (Sharding)
•Pros –schemaless –master-master replication –scales well –everything runs in parallel –built for the web •Cons –integrity-enforcement migrates to code –limited ORM tooling –significant learning curve –proven only in a sub-set of cases –Unlearning normalization is difficult
– Relational databases do not fit every problem – stuffing files in to an RDBMS, maybe there is something better – using RDBMS for caching, perhaps a lighter weight solution is better – cramming log data into a RDBMS, perhaps a KeyValue store is better – trying to do parallel processing with a DB maybe Hadoop MapReduce is better – executing a long running process taking few hours, may be MapReduce with Hadoop/Hbase is better and get it done in minutes – Despite the hype, RDBMS are not doomed, but – their role and place will certainly change – Scaling is a real challenge for relational db • sharding is a band-aid, not feasible beyond a few nodes – There is a hit in overcoming the initial leaning curve • it changes how you build applications (jsp, jsf, jpa) – Drop ACID and think about data
–Webapps need • elastic scalability • flexible schemas • geographic distribution • high availability • reliable storage –Webapps can do without • complicated queries • strong transactions ( some form of consistency is still desirable) –DB vs NoSQL • Strong consistency vs Eventual consistency • Big dataset vs Huge Datasets • Scaling is possible vs Scaling is easy • SQL vs MapReduce, API etc • Good availability vs Very high availability
CAP Theorem – Distributed systems can have any two • Consistency (data is correct at all times) – ACID transactions • Availability (read and write all the time) – Total Redundancy • Partition Tolerance (plug and play nodes) – Infinite scale out – CA - corruption is possible if live nodes cant communicate – CP - completely inaccessible if any nodes are dead – AP - always available, but not always read most recent – Cassandra chooses A and P but allows them to be tunable to have more C – RDBMS are typically CA
BASE – ACID Alternative – Basically Available (appears to work all the time) – Soft state (doesn't have to be consistent all the time) – Eventually consistent (but eventually it will be) –BASE (basically available, soft state, eventually consistent) rather than ACID (atomicity, consistency, isolation, durability )
does it solve –Reliable and simple scaling –No single point of failure (all nodes are identical) –High write throughput –Large data sets –Scale out not up –Online load balancing, cluster growth –flexible schema –key-oriented queries –CAP aware
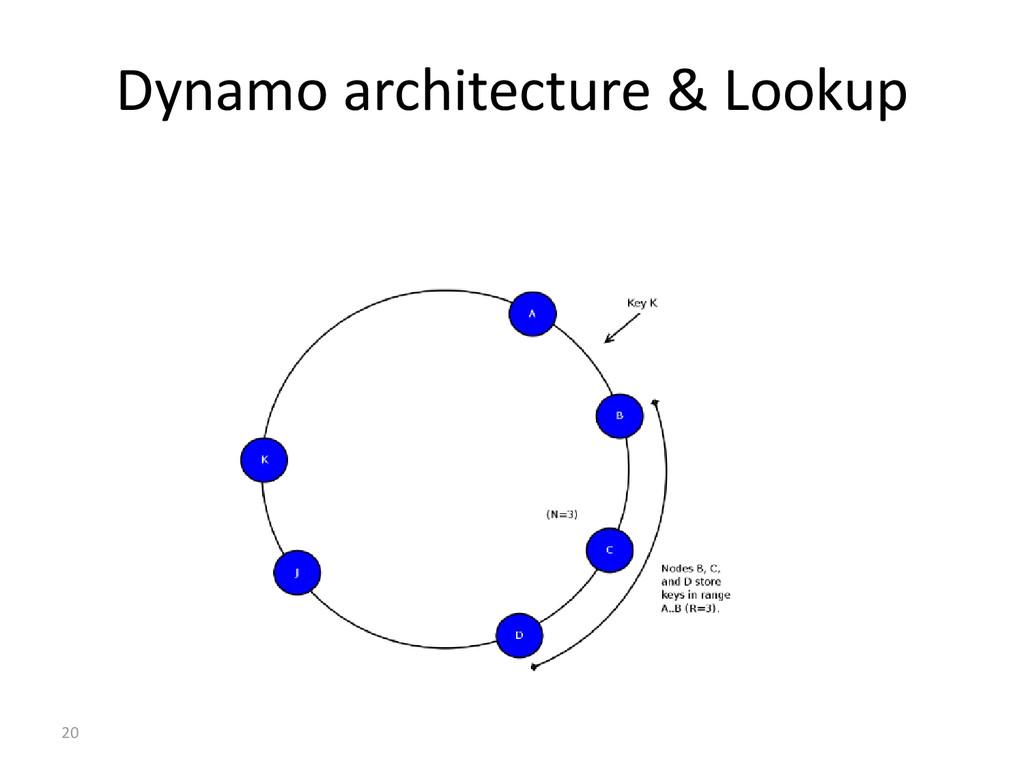
– Designed by Avinash Lakshman and Prashant Malik – Open sourced by Facebook in 2008 – Apache Incubator – Graduated in March 2009 – Dynamo's fully distributed design – Bigtable's Column Family-based data model
production cluster has over 100 TB of data in over 150 machines. – Fault Tolerant • automatically replicated to multiple nodes for fault-tolerance • Replication across multiple data centers supported • Failed nodes can be replaced with no downtime – Decentralized • Every node in the cluster is identical • no network bottlenecks • no SPOF – You're in control • Choose between synchronous or asynchronous replication for each update • Highly available asynchronous operations are optimized with features like Hinted Handoff and Read Repair – Rich Data Model • Allows efficient use for many applications beyond simple key/value – Elastic • Read and write throughput both increase linearly as new machines are added, with no downtime or interruption to application – Durable • Cassandra is suitable for applications that can't afford to lose data, even when an entire data center goes down
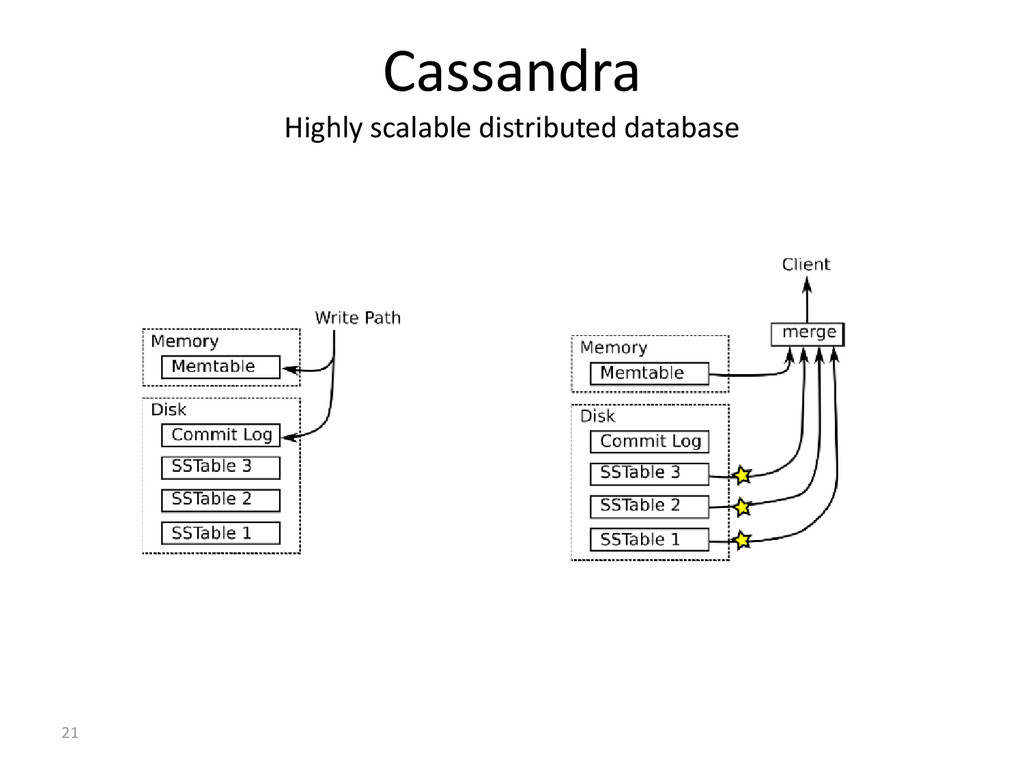
fail. –Incremental scalability –Eventually Consistent (Hinted Handoff, Read Repair) –Tunable tradeoffs between consistency and latency – partitioning, replication –Minimal administration –No Single Point Of Failure (SPOF) –Key-Value store (with some structure) –Schemaless –MapReduce support –Two read paths available: high-performance weak reads/quorum reads –Reads and writes atomic within a single Column Family –Versioning and conflict resolution (last update wins)
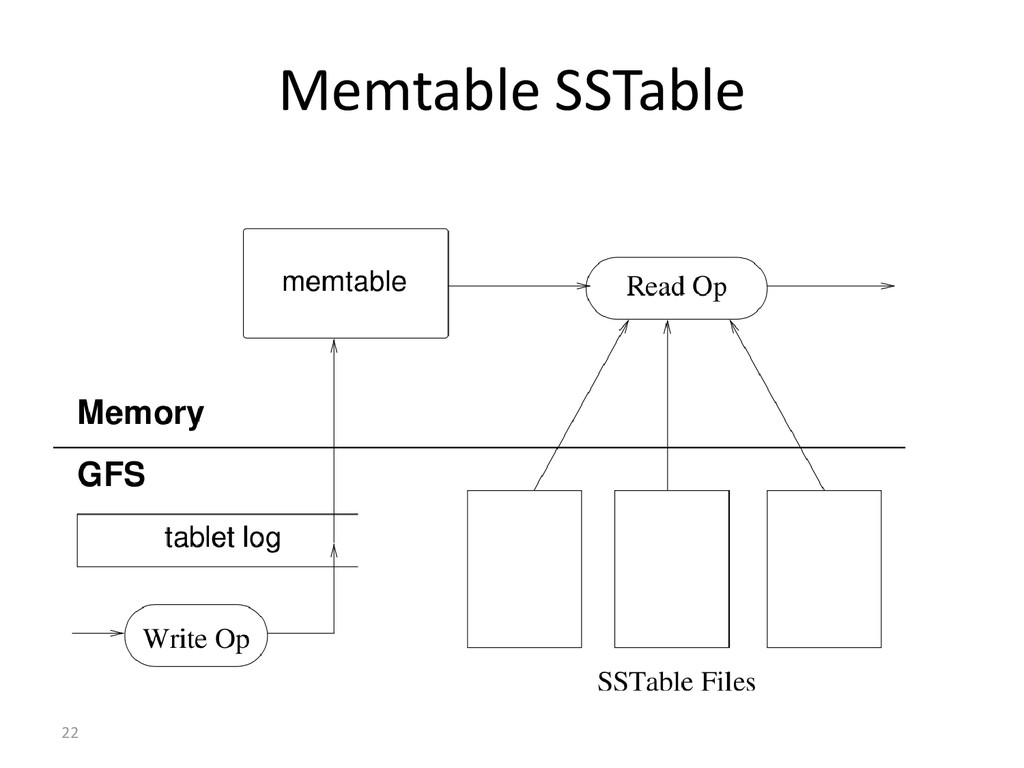
reads – no seeks – sequential disk access – atomic within CF – Fast – Any node – Always writable (hinted hand-off) – Writes go to a commit log and in-memory storage (memtable) – Memtable is occasionally flushed to disk (SSTable) – The SSTables are periodically compacted – Partitioner – Wait for W responses – client issues a write req to a random node in the cassandra cluster partitioner determines the nodes responsible for the data – No locks in critical path – always writable - accepts writes during failure scenarios
nodes – read repair – usual cache conventions apply – Bloom Filters before SSTable – reads (memtable, sstable) – Partitioner – Wait for N – R responses in the background and perform read repair – Read multiple SSTables – Slower than writes (but still fast) – Scales to billions of rows – Read repair when out of synch – Row Cache avoid SSTable lookup – key cache avoid index scan
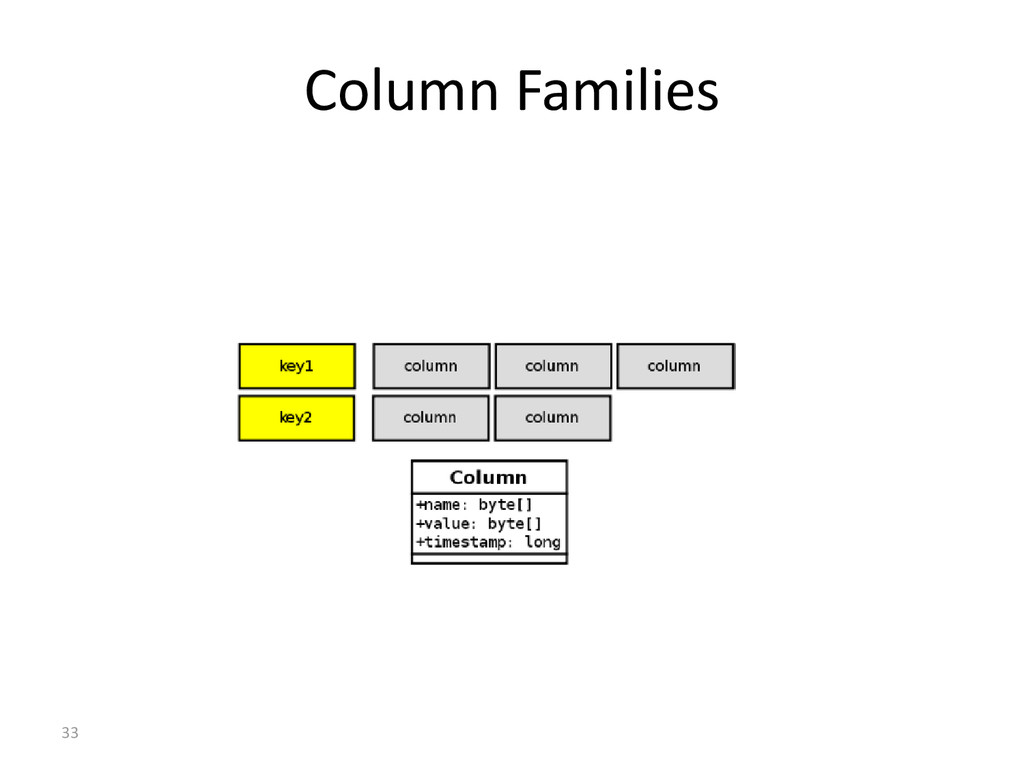
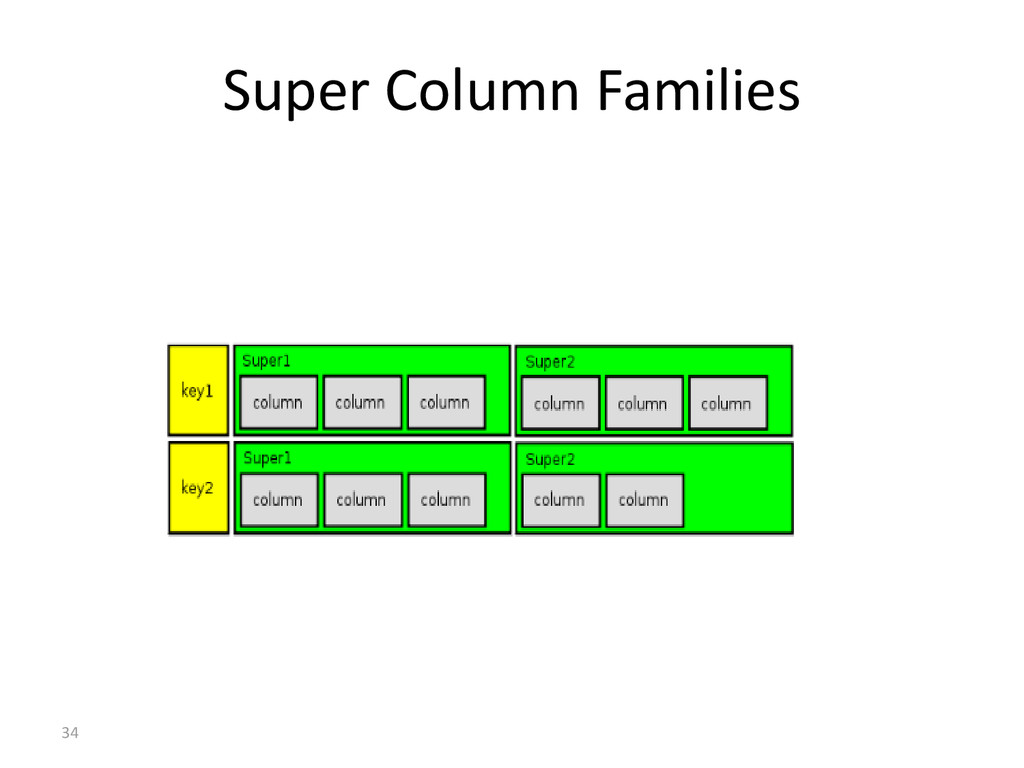
Clusters can contain multiple keyspaces. • Keyspace: namespace for ColumnFamilies. (Analogous to DB schema) • ColumnFamilies: contain multiple columns, referenced by row keys. (Analogous to table) • SuperColumns: columns that themselves have subcolumns.
different columns. Columns can be created dynamically. Columns are always sorted in row by Column name. • User = { keyhole : { username: “keyhole", email: " [email protected]“}, spacer: { username: “spacer", email: “[email protected]", phone: "(888) 888-8888“} }
different columns. Columns can be created dynamically. Columns are always sorted in row by Column name. • User = { keyhole : { username: “keyhole", email: " [email protected]“}, spacer: { username: “spacer", email: “[email protected]", phone: "(888) 888-8888“} }
an NRDBMS now, but ought to learn one anyway – Its not just for Twitter and bleeding edge startups Amazon, Facebook, Google, IBM, Microsoft all get this – Sometimes it is simply the right tool for the job – if you are in the cloud you are going to use them – best of both worlds - external mapping layer JPA driver – Next Big thing - In Memory elastic DB • memory can be much more efficient than disk • RAMClouds become much more attractive for apps with high throughputs requirements
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions Twitter @joealex Email [email protected]](https://files.speakerdeck.com/presentations/983c7ace007645dbbdefb47d3810d5b4/slide_38.jpg){kind=link}