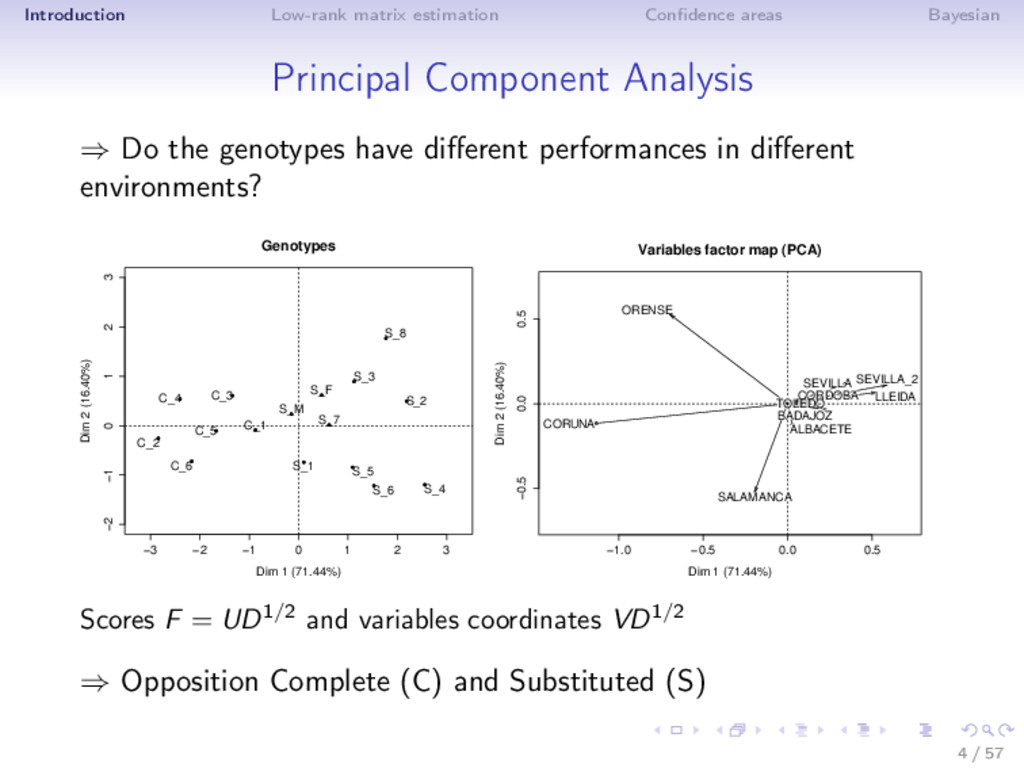
Principal Component Analysis Julie Josse Statistics Department, Agronomy University Agrocampus, Rennes, France Workshop in Biostatistics, Stanford University, 15 January 2015 1 / 57
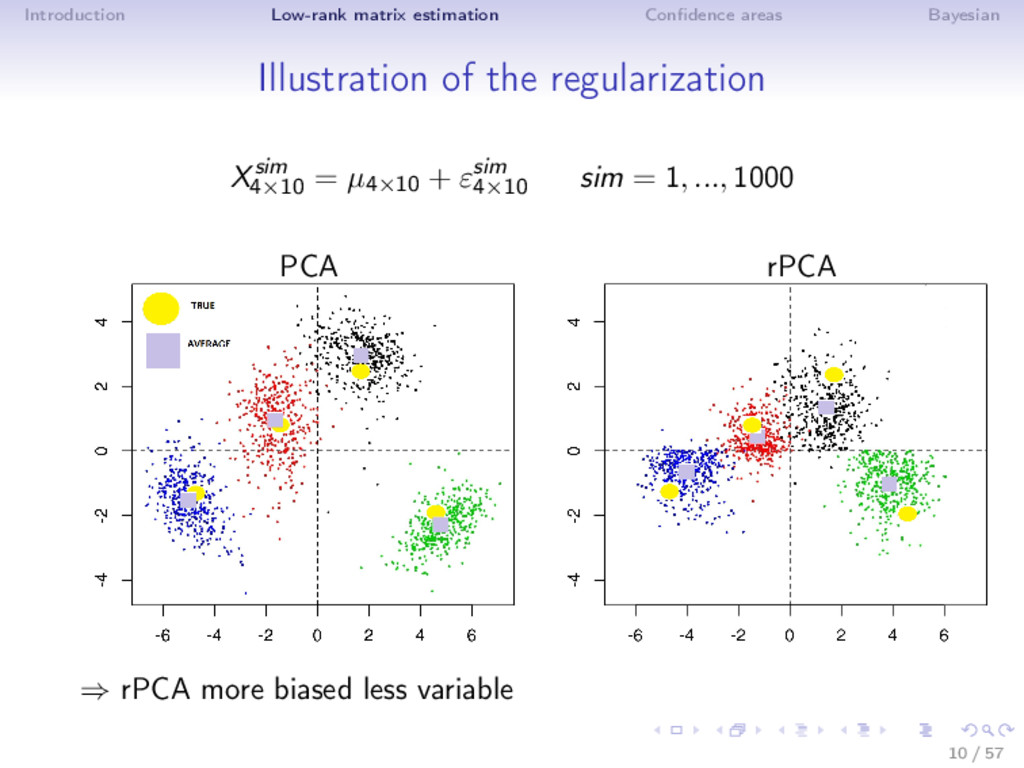
⇒ Gaussian noise model Xn×p = µ + ε, with εij iid ∼ N 0, σ2 with µ of low rank k Image, collaborative filtering... ⇒ Classical solution: truncated SVD ˆ µk = k l=1 ul dl v l Hard thresholding: dl · 1(l ≤ k) = dl · 1(dl ≥ λ) argminµ X − µ 2 2 : rank (µ) ≤ k ⇒ Selecting k? Cross-validation (Josse & Husson, 2012) Not the best in MSE to recover µ! 6 / 57
autoencoder Gaussian model: X = µ + ε, with εij iid ∼ N 0, σ2 ⇒ Classical formulation: • ˆ µk = argminµ X − µ 2 2 : rank (µ) ≤ k • TSVD: ˆ µk = k l=1 ul dl v l = k l=1 fl v l F = XV (V V )−1 V = (F F)−1F X ˆ µk = FV = XV (V V )−1V = XPV 13 / 57
autoencoder Gaussian model: X = µ + ε, with εij iid ∼ N 0, σ2 ⇒ Classical formulation: • ˆ µk = argminµ X − µ 2 2 : rank (µ) ≤ k • TSVD: ˆ µk = k l=1 ul dl v l = k l=1 fl v l F = XV (V V )−1 V = (F F)−1F X ˆ µk = FV = XV (V V )−1V = XPV ⇒ Another formulation: autoencoder (Boulard & Kamp, 1988) ˆ µk = XBk, where Bk = argminB X − XB 2 2 : rank (B) ≤ k 13 / 57
Bootstrap = Feature noising ˆ µboot k = XBk, Bk = argminB EX∼L(X) X − XB 2 2 : rkB ≤ k Bk = argminB Eε X − (X + ε)B 2 2 : rkB ≤ k ⇒ Equivalent to a ridge autoencoder problem ˆ µ(k) λ = XBλ, Bλ = argminB X − XB 2 2 + λ B 2 2 : rkB ≤ k ⇒ Solution: singular-value shrinkage estimator ˆ µboot k = k l=1 ul dl 1 + λ/d2 l vl with λ = nσ2 ˆ µ(λ) k = XBλ, Bλ = X X + S −1 X X, S = diag(λ) 15 / 57
bootstrap Model: X = µ + ε, with εij ∼ N 0, σ2 ⇒ Aim: recover µ ˆ µ∗ k = XB∗ k , B∗ k = argminB EX∼L(µ) µ − XB 2 2 : rank (B) ≤ k ⇒ X as a proxy for µ ˆ µboot k = XBk, Bk = argminB EX∼L(X) X − XB 2 2 : rank (B) ≤ k ⇒ X is bigger than µ! ˆ µ = XB as a proxy for µ: B = argminB E˜ ˆ µ∼L(ˆ µ) ˆ µ − ˜ ˆ µB 2 2 16 / 57
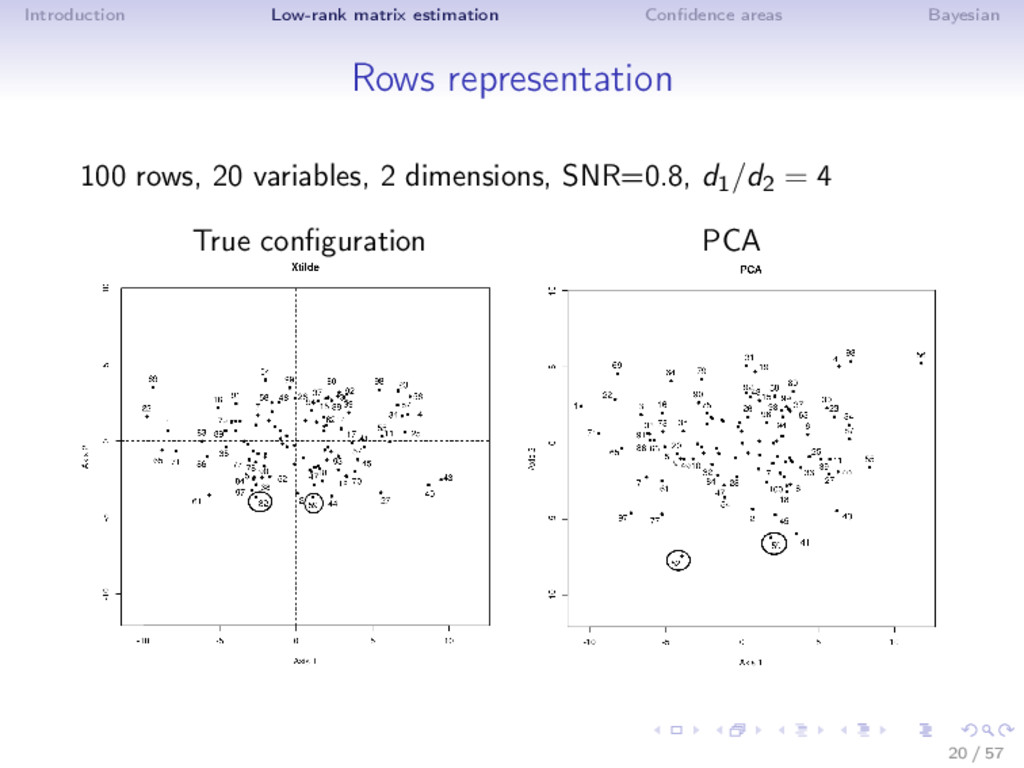
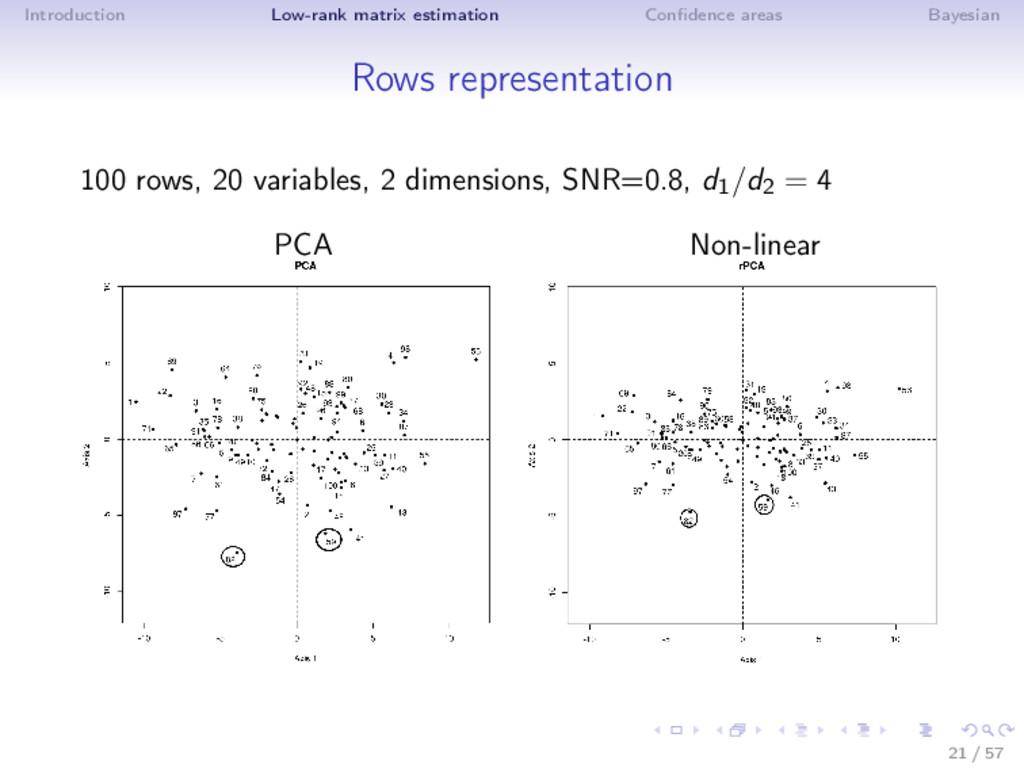
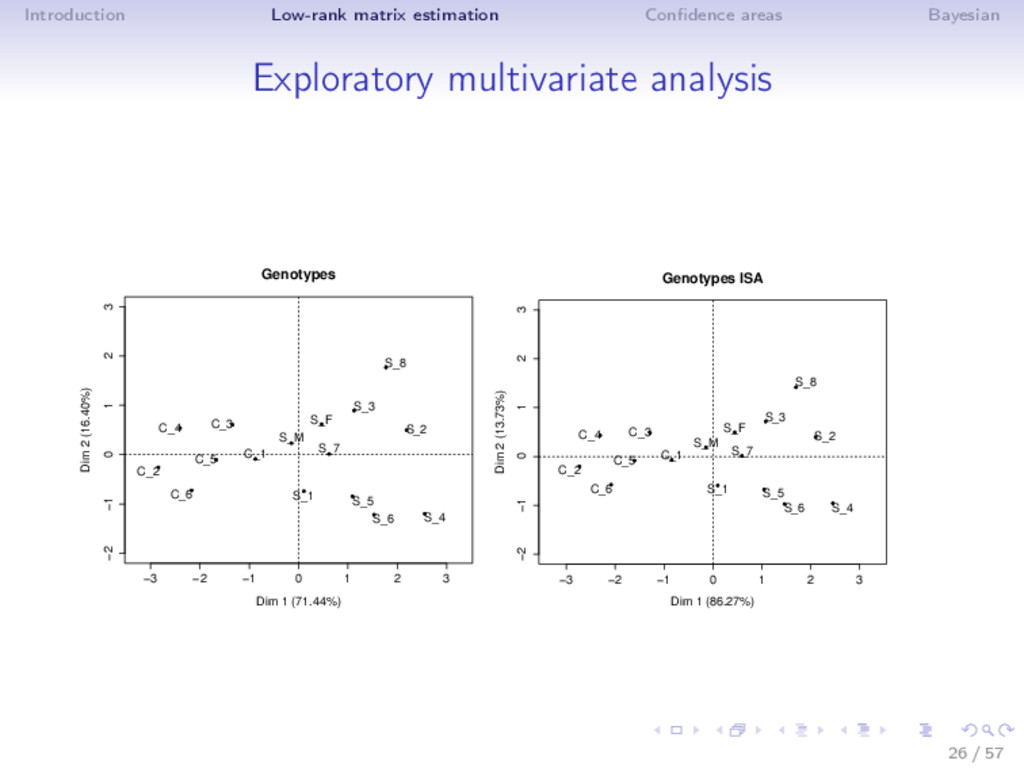
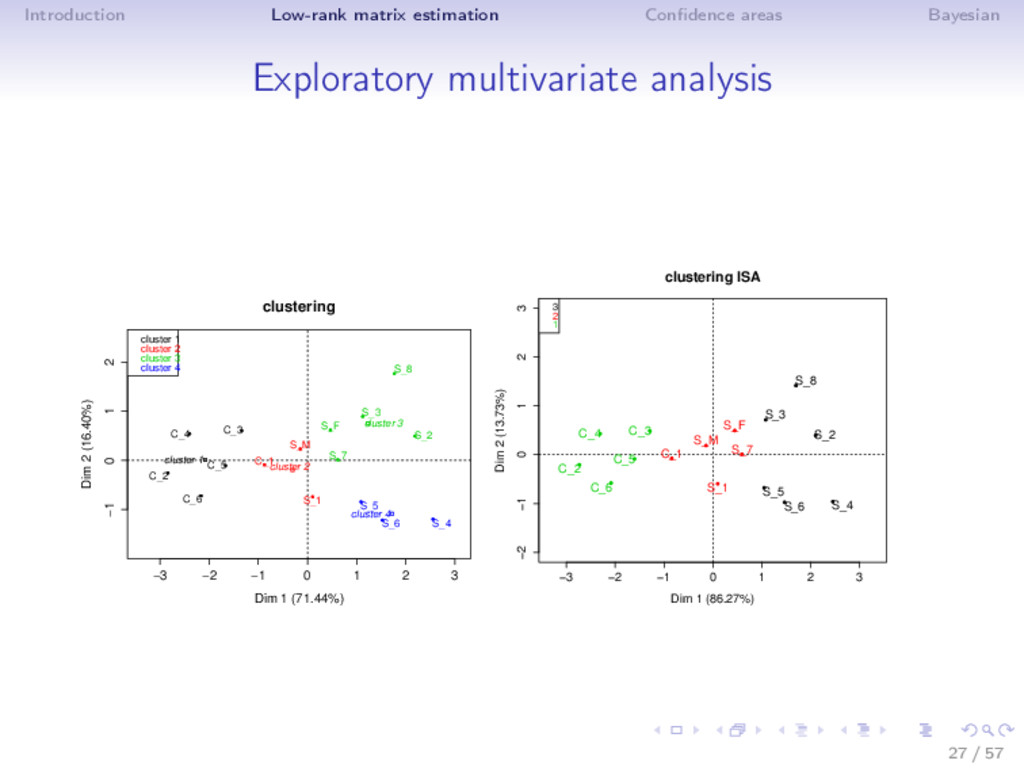
Different noise regime • low noise: truncated SVD • moderate noise: Asympt, SA, ISA (non-linear transformation) • high noise (SNR low, k large): Soft thresholding ⇒ Adaptive estimator is very flexible! (selection with SURE) ⇒ ISA performs well in MSE (even outside the Gaussian noise) and as a by-product estimates accurately the rank! Rq: not the usual behavior n > p: rows more perturbed than the columns; n < p: columns more perturbed; n = p 19 / 57
Feature noising = regularization B = argminB X − XB 2 2 + S 1 2 B 2 2 Sjj = n i=1 Var X∼L(X) Xij ˆ µ = X(X X + δ 1−δ S)−1X X, S diagonal with row-sums of X ⇒ New estimator ˆ µ that does not reduce to singular value shrinkage ⇒ ISA estimator - iterative algorithm 1. ˆ µ = X ˆ B 2. ˆ B = (ˆ µ ˆ µ + S)−1 ˆ µ ˆ µ 30 / 57
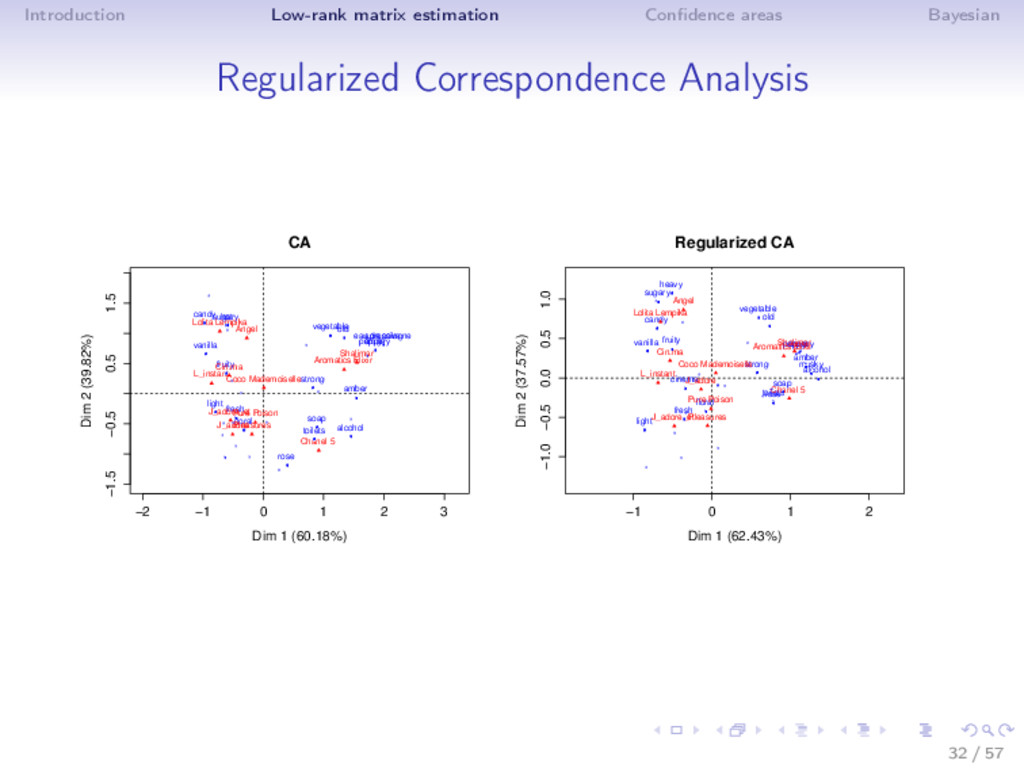
⇒ Correspondence Analysis M = R−1 2 X − 1 N rc C−1 2 , where R = diag (r) , C = diag (c) ⇒ Population data: perfume data set • 12 luxury perfumes described by 39 words - N=1075 • d1 = 0.44, d2 = 0.15 ⇒ Sample data: N = 400 - same proportion d1 d2 RV U RV V k RV row RV col CA 0.59 0.31 0.83 0.75 0.91 0.71 Non-linear 0.35 0.10 0.83 0.75 0.93 0.74 ISA 0.42 0.12 0.86 0.77 2 0.94 0.75 31 / 57
X = µ + ε, εij ∼ N 0, σ2 ˆ µk = k l=1 ul dl v l vec(ˆ µk) = Pvec(X) 2 projections: X − FV 2 ˆ µk = FV = XPV = PF X V = (F F)−1F X ⇒ PF = F(F F)−1F F = XV (V V )−1 ⇒ PV = V (V V )−1V Pnp×np = (PV ⊗ In) + (Ip ⊗ PF ) − (PV ⊗ PF ) (Pazman & Denis 2002) 36 / 57
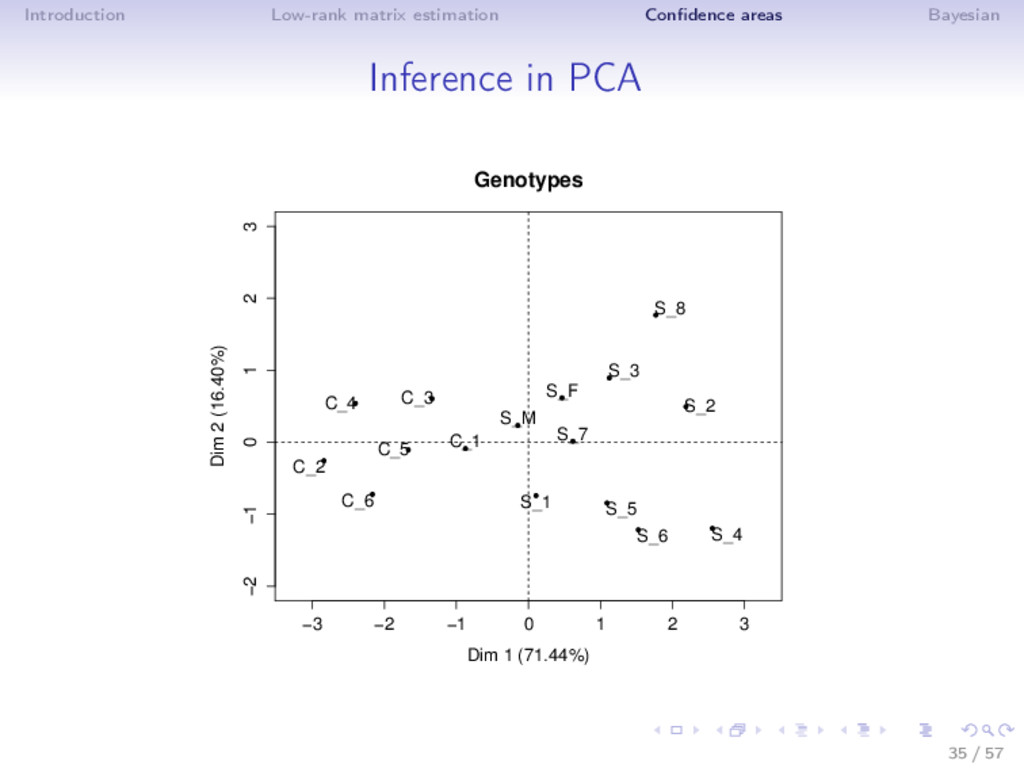
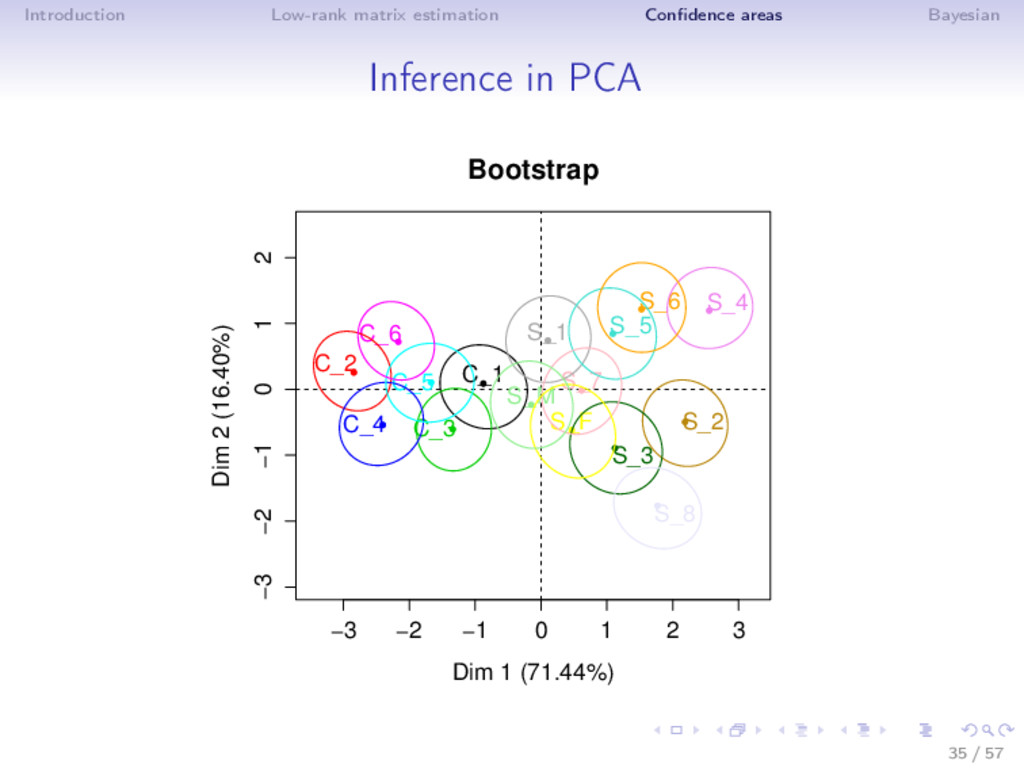
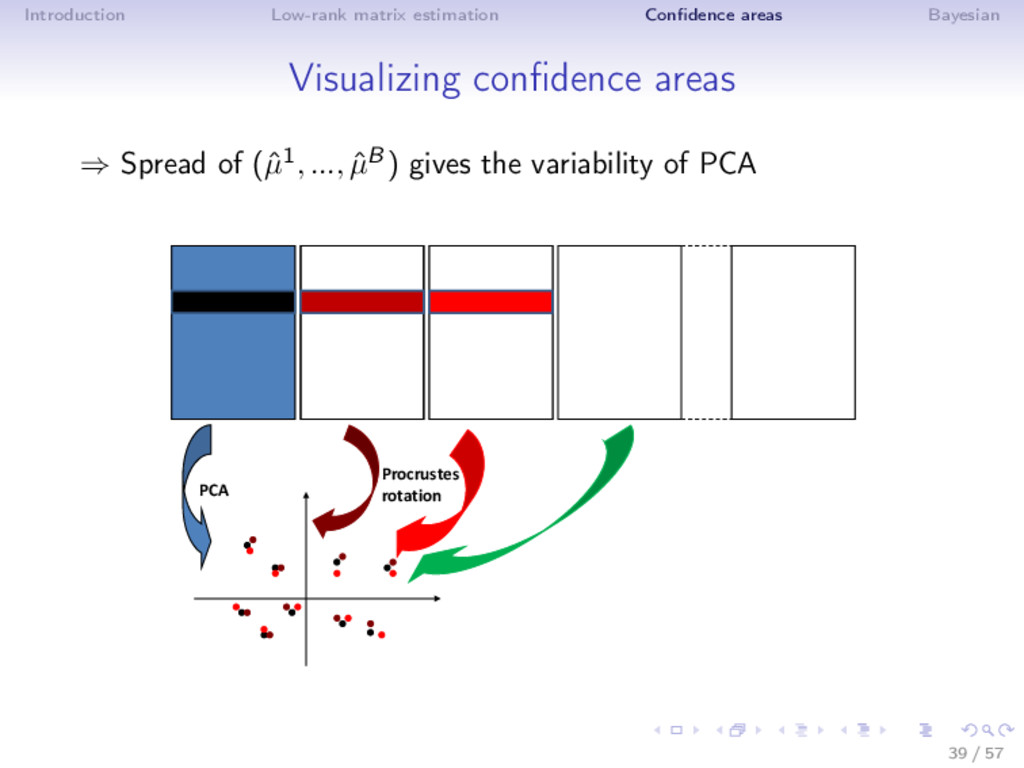
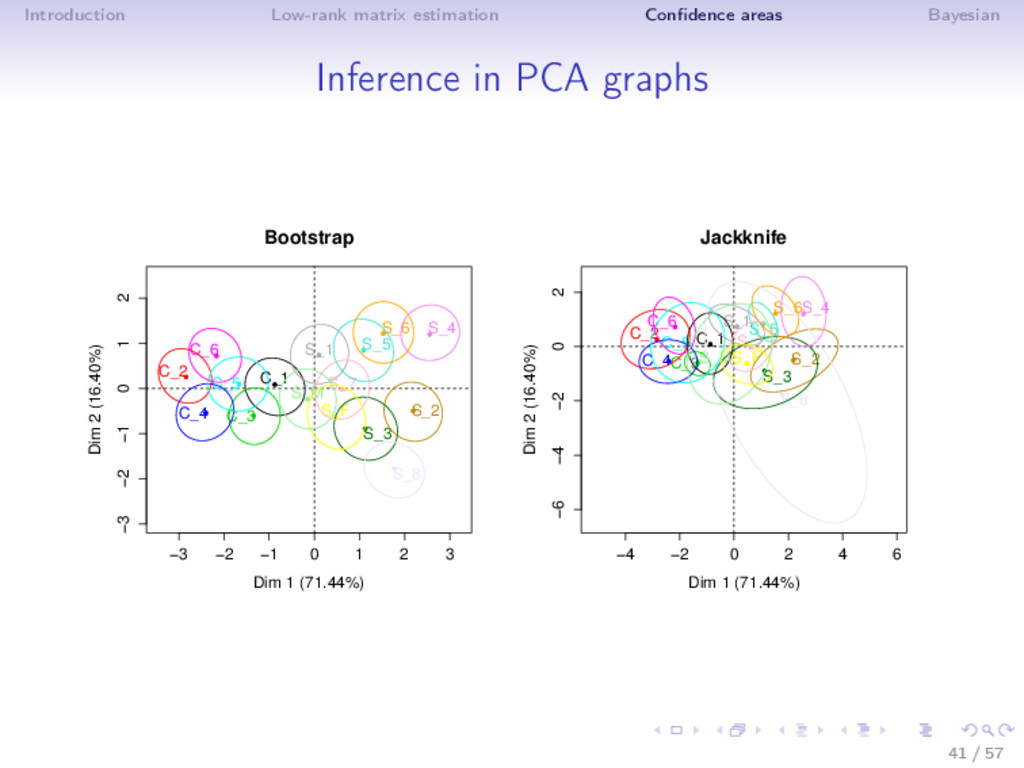
Bootstrap ⇒ Rows bootstrap (Holmes, 1985, Timmerman et al, 2007) • random sample from a population - sampling variance • confidence areas around the position of the variables ⇒ Residuals bootstrap • full population data - X = µ + ε - noise fluctuation • confidence areas around the individuals and the variables 37 / 57
Bootstrap ⇒ Rows bootstrap (Holmes, 1985, Timmerman et al, 2007) • random sample from a population - sampling variance • confidence areas around the position of the variables ⇒ Residuals bootstrap • full population data - X = µ + ε - noise fluctuation • confidence areas around the individuals and the variables 1. residuals ˆ ε = X − ˆ µk. Bootstrap or draw from N(0, ˆ σ2) : εb 2. Xb = ˆ µk + εb 3. PCA on Xb → (ˆ µ1 = U1D1V 1 , ..., ˆ µB = UBDBV B ) 37 / 57
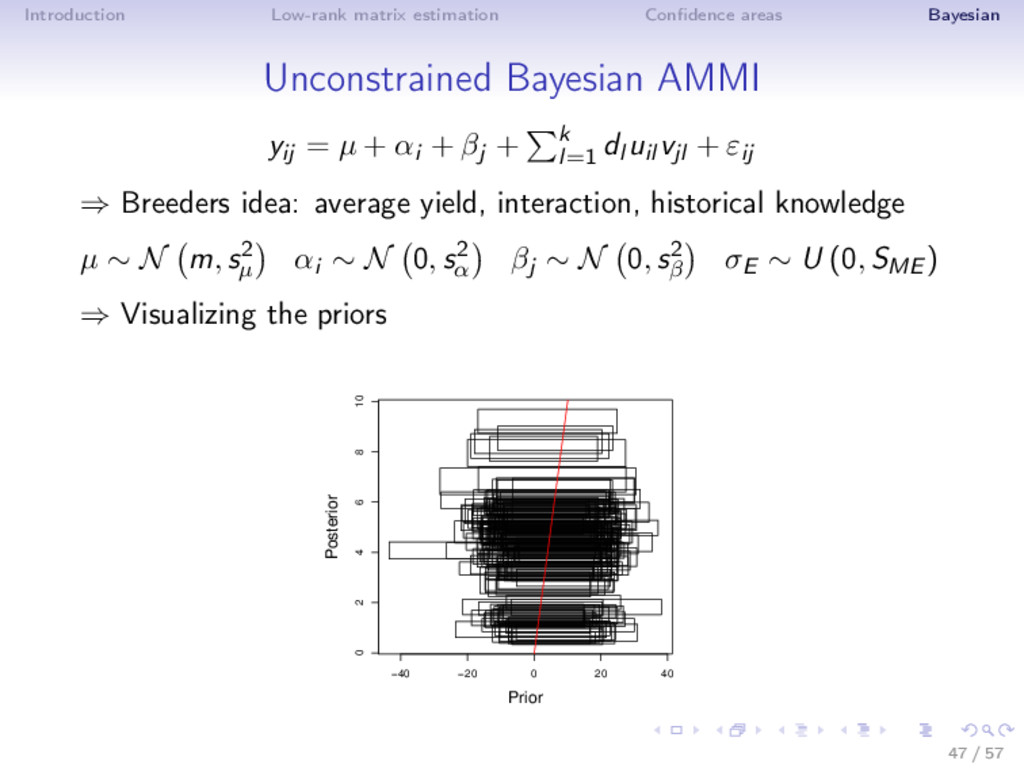
SVD X = µ + ε = UDV + ε ⇒ Overparametrization issue ⇒ Ensure priors and posteriors that meet the constraints? • Hoff (2009): - uniform prior for U and V special cases of von Mises-Fisher distributions (Stiefel manifold); (dl )l=1...k ∼ N 0, s2 λ - conditional posterior of U and V are also VMF - draw from the posterior of µ. Point estimate ˆ µ, small MSE • Todeschini, et al. (2013): each dl has its s2 γl , hierarchical 45 / 57
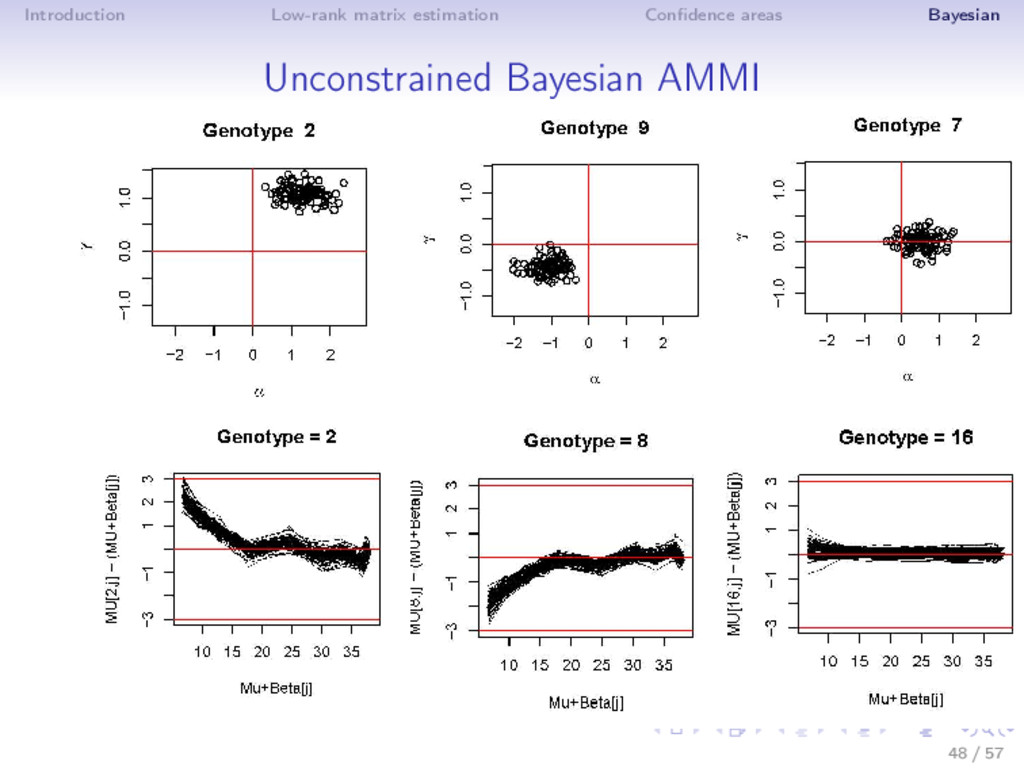
⇒ Easy to answer questions in a unique framework: best genotypes across environments, for one environment, stability, probability that a genotype produces less than a certain threshold? ⇒ To use for PCA graphs (shrinked biplot + ellipses) ⇒ Properties? Comparison? ⇒ Uncertainty on k... 49 / 57
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}