References 1 Introduction 2 Single imputation based on principal component methods 3 Multiple imputation for continuous data with PCA 4 Multiple imputation for categorical data with MCA 5 Conclusion 2 / 37
References Missing values NA NA NA NA NA NA . . . . . . . . . . . . . . . . . . . . . . . . NA NA NA • Aim: inference on a quantity θ from incomplete data → point estimate ˆ θ and associated variability T 3 / 37
References Missing values NA NA NA NA NA NA . . . . . . . . . . . . . . . . . . . . . . . . NA NA NA • Aim: inference on a quantity θ from incomplete data → point estimate ˆ θ and associated variability T • R: response indicator (known) X = Xobs, Xmiss : data (partially known) MAR assumption: P (R|X) = P R|Xobs • Likelihood approaches → EM, SEM • Multiple Imputation → P Xmiss|Xobs 3 / 37
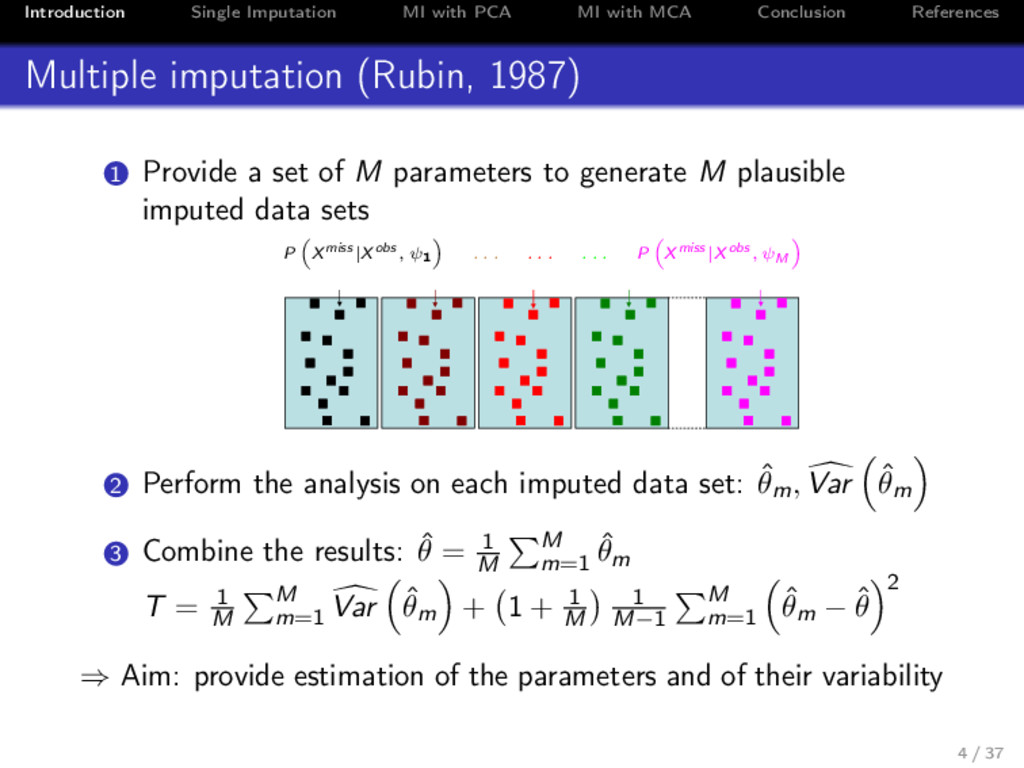
References Multiple imputation (Rubin, 1987) 1 Provide a set of M parameters to generate M plausible imputed data sets P Xmiss |Xobs , ψ1 . . . . . . . . . P Xmiss |Xobs , ψM ( ˆ F ˆ u′)ij ( ˆ F ˆ u′)1 ij + ε1 ij ( ˆ F ˆ u′)2 ij + ε2 ij ( ˆ F ˆ u′)3 ij + ε3 ij ( ˆ F ˆ u′)B ij + εB ij 2 Perform the analysis on each imputed data set: ˆ θm, Var ˆ θm 3 Combine the results: ˆ θ = 1 M M m=1 ˆ θm T = 1 M M m=1 Var ˆ θm + 1 + 1 M 1 M−1 M m=1 ˆ θm − ˆ θ 2 ⇒ Aim: provide estimation of the parameters and of their variability 4 / 37
References Generating imputed data sets To simulate P Xmiss|Xobs, ψ : Joint modelling or Fully conditional specification: • JM: define P (X, ψ), draw from P Xmiss|Xobs, ˆ ψ1 , P Xmiss|Xobs, ˆ ψ2 , . . ., P Xmiss|Xobs, ˆ ψM • FCS: define P (Xk |X−k , ψ−k ), draw from P Xmiss k |Xobs −k , ˆ ψ−k for all k. Repeat with ˆ ψ2 −k 1≤k≤K , . . ., ˆ ψM −k 1≤k≤K . Theory Fit Time JM + − + FCS − + − However... I < K? high dependence? high dimensionality? 5 / 37
References Generating imputed data sets To simulate P Xmiss|Xobs, ψ : Joint modelling or Fully conditional specification: • JM: define P (X, ψ), draw from P Xmiss|Xobs, ˆ ψ1 , P Xmiss|Xobs, ˆ ψ2 , . . ., P Xmiss|Xobs, ˆ ψM • FCS: define P (Xk |X−k , ψ−k ), draw from P Xmiss k |Xobs −k , ˆ ψ−k for all k. Repeat with ˆ ψ2 −k 1≤k≤K , . . ., ˆ ψM −k 1≤k≤K . Theory Fit Time JM + − + FCS − + − However... I < K? high dependence? high dimensionality? Could principal component methods provide another way to deal with missing values? 5 / 37
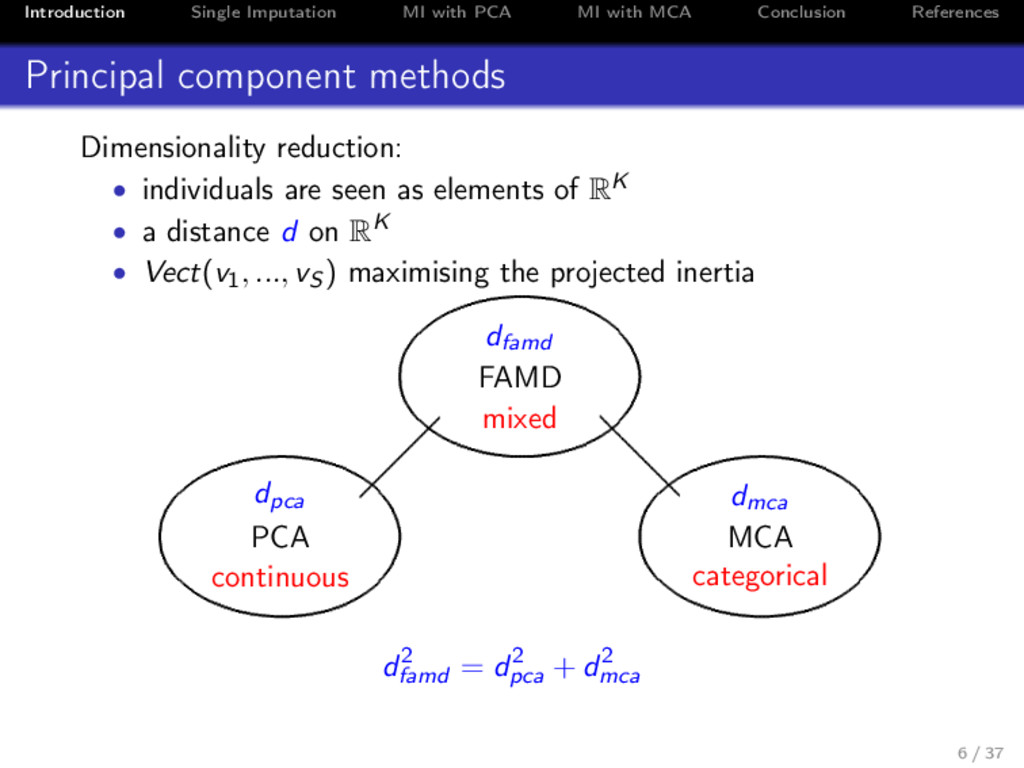
References Principal component methods Dimensionality reduction: • individuals are seen as elements of RK • a distance d on RK • Vect(v1, ..., vS ) maximising the projected inertia dfamd FAMD mixed dpca PCA continuous dmca MCA categorical d2 famd = d2 pca + d2 mca 6 / 37
References 1 Introduction 2 Single imputation based on principal component methods 3 Multiple imputation for continuous data with PCA 4 Multiple imputation for categorical data with MCA 5 Conclusion 7 / 37
References How to perform FAMD? SVD X, (DΣ)−1 , 1 I 1I −→ XI×K = UI×K Λ1/2 K×K VK×K with U 1 I 1I U = 1K V D−1 Σ V = 1K • principal components: ˆ FI×S = ˆ UI×S ˆ Λ1/2 S×S • loadings: ˆ VK×S • fitted matrix: ˆ XI×K = ˆ UI×S ˆ Λ1/2 S×S ˆ VK×S ˆ X − X 2 D−1 Σ ⊗1 I 1 = tr ˆ X − X D−1 Σ ˆ X − X 1 I 1I minimized under the constraint of rank S 9 / 37
References Properties of the method • The distance between individuals is: d2(i, i ) = k j=1 (xij − xi j )2 σ2 xj + K j=k+1 1 Ij (xij − xi j )2 • The principal component Fs maximises: var∈continuous r2(Fs, var) + var∈categorical η2(Fs, var) 10 / 37
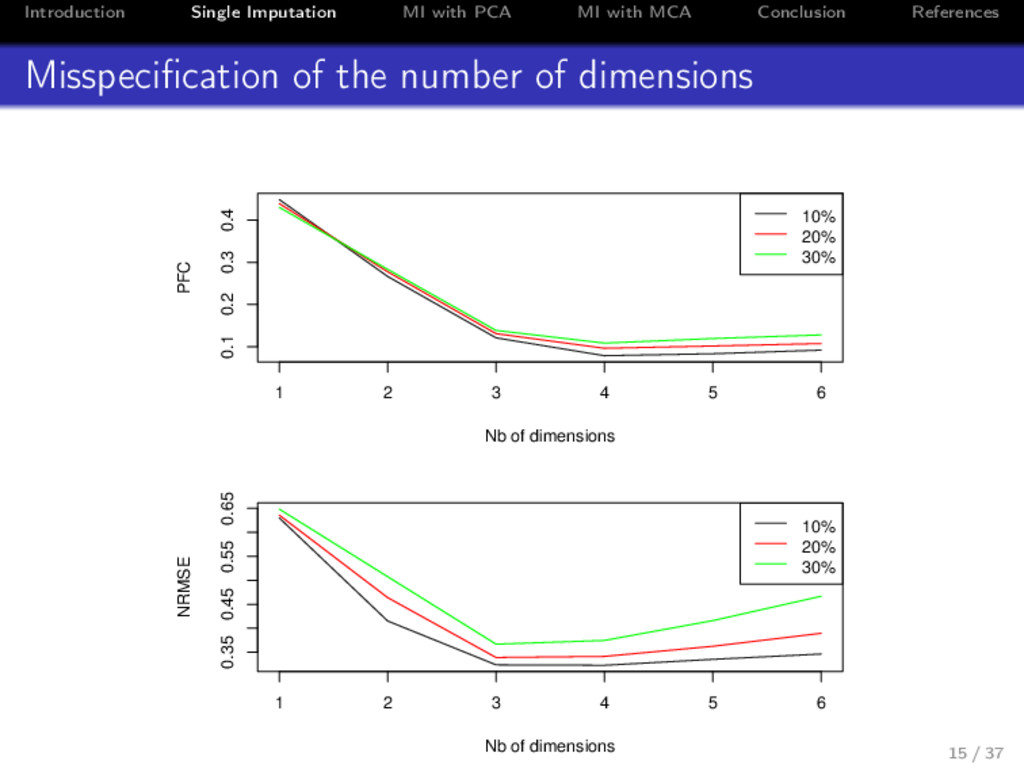
References How to choose the number of dimensions? By cross-validation procedures: • adding missing values on the incomplete data set • predicting each of them using FAMD for several number of dimensions • calculating the prediction error Several ways: • Leave-one-out (Bro et al., 2008) • Repeated cross-validation 14 / 37
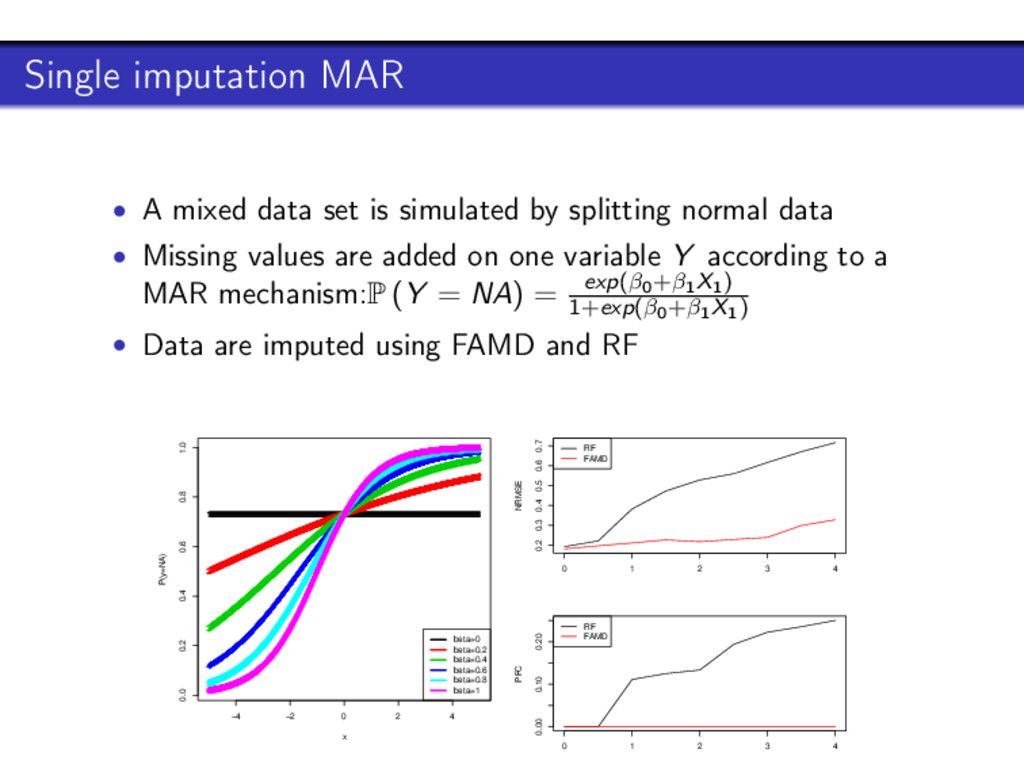
References Simulation results Single imputation with FAMD shows a high quality of prediction compared to random forests (Stekhoven and Bühlmann, 2012) • on real data • when the relationships between continuous variables are linear • for rare categories • with MAR/MCAR mechanism Can impute mixed, continuous or categorical data 16 / 37
References Simulation results Single imputation with FAMD shows a high quality of prediction compared to random forests (Stekhoven and Bühlmann, 2012) • on real data • when the relationships between continuous variables are linear • for rare categories • with MAR/MCAR mechanism Can impute mixed, continuous or categorical data But a single imputation method only 16 / 37
References From single imputation to multiple imputation P Xmiss |Xobs , ψ1 . . . . . . . . . P Xmiss |Xobs , ψM ( ˆ F ˆ u′)ij ( ˆ F ˆ u′)1 ij + ε1 ij ( ˆ F ˆ u′)2 ij + ε2 ij ( ˆ F ˆ u′)3 ij + ε3 ij ( ˆ F ˆ u′)B ij + εB ij 1 Reflect the variability on the parameters of the imputation model → ˆ UI×S , ˆ Λ1/2 S×S , ˆ VK×S 1 , . . . , ˆ UI×S , ˆ Λ1/2 S×S , ˆ VK×S M Bayesian or Bootstrap 2 Add a disturbance on the prediction by ˆ Xm = ˆ Um ˆ Λ1/2 m ˆ Vm → need to distinguish continuous and categorical data 17 / 37
References 1 Introduction 2 Single imputation based on principal component methods 3 Multiple imputation for continuous data with PCA 4 Multiple imputation for categorical data with MCA 5 Conclusion 18 / 37
References PCA model (Caussinus, 1986) Model XI×K = ˜ XI×K + εI×K = UI×S Λ 1 2 S×S VK×S + εI×K with ε ∼ N 0, σ21K Maximum Likelihood: ˆ XS = UI×S Λ 1 2 S×S VK×S → σ2 = X − X S 2 /degrees of f. Bayesian formulation: • Hoff (2007): Uniform prior for U and V, Gaussian on (λs)s=1...S • Verbanck et al. (2013): Prior on ˜ X 19 / 37
References Multiple imputation with Bayesian PCA (Audigier et al., 2015) 1 Variability of the parameters, M plausible (˜ xij )1, . . . , (˜ xij )M • Posterior distribution: Bayesian PCA ˜ x(s) ij |x(s) ij = N(Φs x(s) ij , Φsσ2) 2 Imputation according to the PCA model using the set of M parameters xmiss ij ← N(ˆ xij , ˆ σ2) 21 / 37
References Multiple imputation with Bayesian PCA (Audigier et al., 2015) 1 Variability of the parameters, M plausible (˜ xij )1, . . . , (˜ xij )M • Posterior distribution: Bayesian PCA ˜ x(s) ij |x(s) ij = N(Φs x(s) ij , Φsσ2) • Data Augmentation (Tanner and Wong, 1987) 2 Imputation according to the PCA model using the set of M parameters xmiss ij ← N(ˆ xij , ˆ σ2) 21 / 37
References Multiple imputation with Bayesian PCA (Audigier et al., 2015) Data augmentation • a Gibbs sampler • simulate ψ, Xmiss|Xobs from (I) Xmiss|Xobs, ψ : imputation (P) ψ|Xobs, Xmiss : draw from the posterior • convergence checked by graphical investigations For Bayesian PCA: • initialisation: ML estimate for ˜ X • for in 1...L (I) Given ˜ X, xmiss ij ← N(˜ xij , ˆ σ2) (P) ˜ xij ← N s ˆ Φs x(s) ij , ˆ σ2 s ˆ Φs ) I−1 22 / 37
References MI methods for continuous data Generally based on normal distribution: • JM: XI×K : xi. ∼ N (µ, Σ) (Honaker et al., 2011) 1 Bootstrap rows: X1, . . . , XM EM algorithm: (µ1, Σ1), . . . , (µM , ΣM ) 2 Imputation: xm i. drawn from N (µm, Σm) • FCS: N µXk |X(−k) , ΣXk |X(−k) (Van Buuren, 2012) 1 Bayesian approach: (βm, σm) 2 Imputation: stochastic regression xm ij drawn from N X(−k) βm, σm 23 / 37
References Properties for BayesMIPCA A MI method based on a Bayesian treatment of the PCA model advantages • captures the structure of the data: good inferences for regression coefficient, correlation, mean • a dimensionality reduction method: (I < K or I > K, low or high percentage of missing values) • no inversion issue: strong or weak relationships • a regularization strategy improving stability remains competitive if: • the low rank assumption is not verified • the Gaussian assumption is not true 26 / 37
References 1 Introduction 2 Single imputation based on principal component methods 3 Multiple imputation for continuous data with PCA 4 Multiple imputation for categorical data with MCA 5 Conclusion 27 / 37
References Multiple imputation for categorical data using MCA MI for categorical data is very challenging for a moderate number of variables • estimation issues • storage issues 28 / 37
References Multiple imputation for categorical data using MCA MI for categorical data is very challenging for a moderate number of variables • estimation issues • storage issues MI with MCA 1 Variability on the parameters of the imputation model ˆ UI×S , ˆ Λ1/2 S×S , ˆ VK×S 1 , . . . , ˆ UI×S , ˆ Λ1/2 S×S , ˆ VK×S M → A non-parametric bootstrap approach 2 Add a disturbance on the MCA prediction ˆ Xm = ˆ Um ˆ Λ1/2 m ˆ Vm 28 / 37
References Properties MCA address the categorical data challenge by • requiring a small number of parameters • preserving the essential data structure • using a regularisation strategy MIMCA can be applied on various data sets • small or large number of variables/categories • small or large number of individuals 30 / 37
References MI methods for categorical data • Log-linear model (Schafer, 1997) • Hypothesis on X = (xijk )i,j,k : X|ψ ∼ M (n, ψ) log(ψijk ) = λ0 + λA i + λB j + λC k + λAB ij + λAC ik + λBC jk + λABC ijk 1 Variability of the parameter ψ: Bayesian formulation 2 Imputation using the set of M parameters • Latent class model (Si and Reiter, 2013) • Hypothesis:P (X = (x1, . . . , xK ); ψ) = L =1 ψ K k=1 ψ( ) xk 1 Variability of the parameters ψL and ψX : Bayesian formulation 2 Imputation using the set of M parameters • FCS: GLM (Van Buuren, 2012) or Random Forests (Doove et al., 2014; Shah et al., 2014) 31 / 37
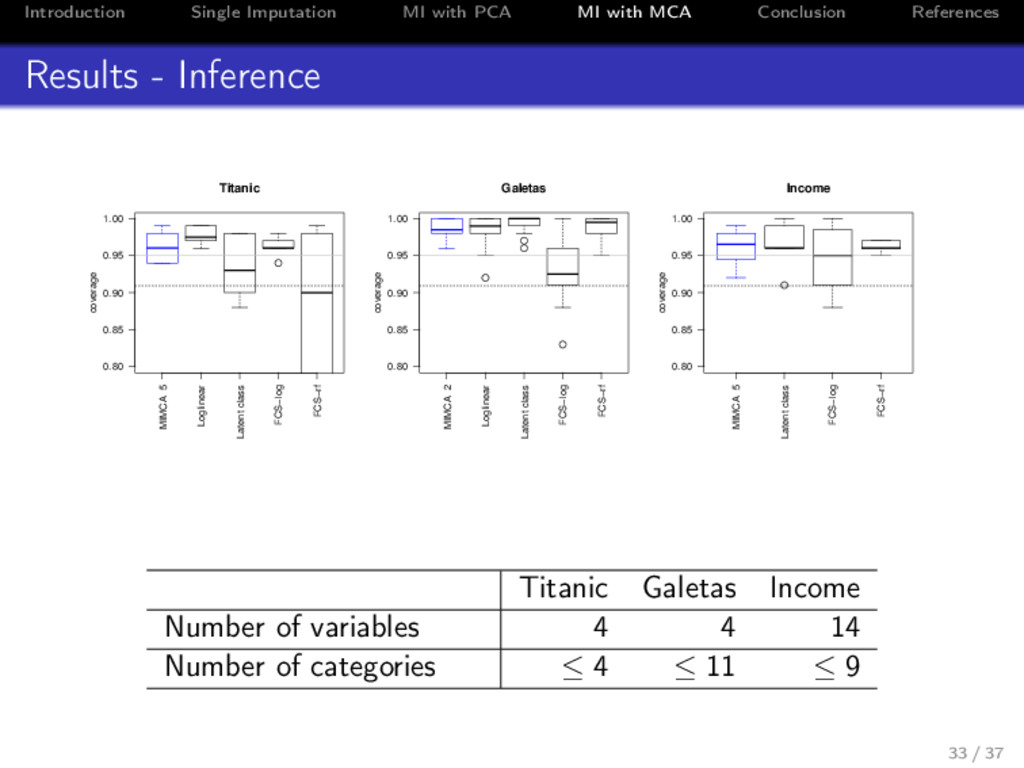
References Simulations from real data sets • Quantities of interest: θ = parameters of a logistic model • Simulation design (repeated 200 times) • the real data set is considered as a population • drawn one sample from the data set • generate 20% of missing values • multiple imputation using M = 5 imputed arrays • Criteria • bias • CI width, coverage • Comparison with : • JM: log-linear model, latent class model • FCS: logistic regression, random forests 32 / 37
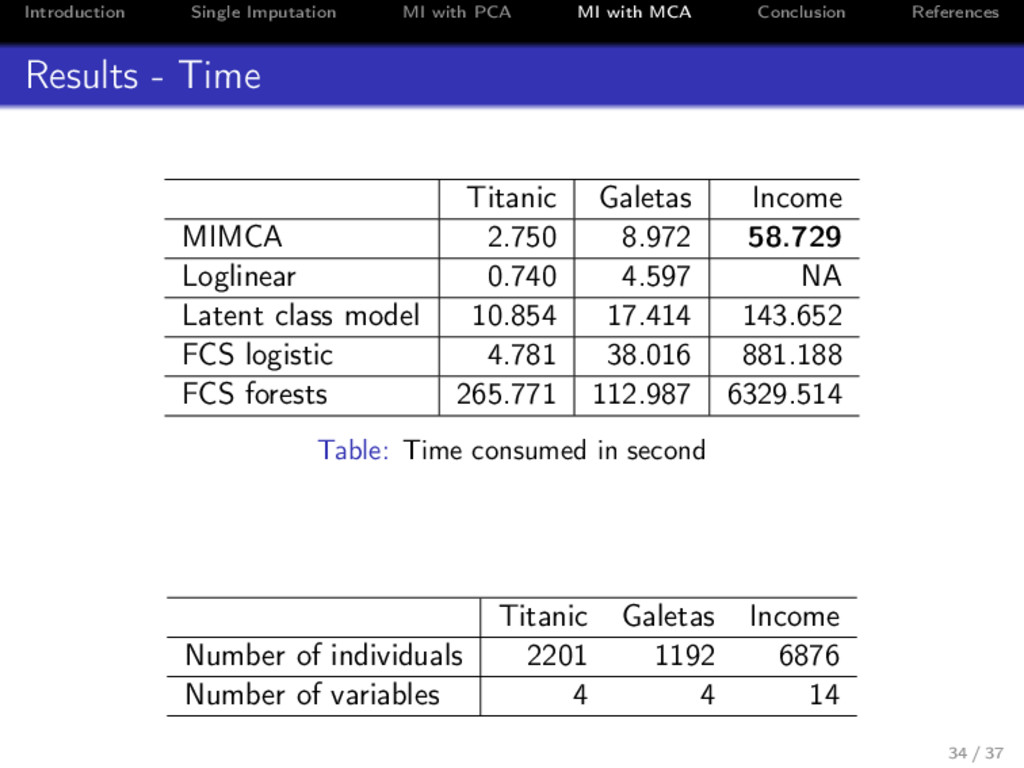
References Results - Time Titanic Galetas Income MIMCA 2.750 8.972 58.729 Loglinear 0.740 4.597 NA Latent class model 10.854 17.414 143.652 FCS logistic 4.781 38.016 881.188 FCS forests 265.771 112.987 6329.514 Table: Time consumed in second Titanic Galetas Income Number of individuals 2201 1192 6876 Number of variables 4 4 14 34 / 37
References Conclusion MI methods using dimensionality reduction method • captures the relationships between variables • captures the similarities between individuals • requires a small number of parameters Address some imputation issues: • can be applied on various data sets • provide correct inferences for analysis model based on relationships between pairs of variables Available in the R package missMDA 35 / 37
References Perspectives To go further: • require a modelisation effort when categorical variables occur • for a deeper understanding of the methods • for an extension of the current methods • for a MI method based on FAMD → some lines of research: • link between CA and log-linear model • link between log-linear model and general locator model • uncertainty on the number of dimensions S 36 / 37
References References I V. Audigier, F. Husson, and J. Josse. MIMCA: Multiple imputation for categorical variables with multiple correspondence analysis. Statistics and Computing, 2015a. Minor revision. V. Audigier, F. Husson, and J. Josse. Multiple imputation for continuous variables using a bayesian principal component analysis. Journal of Statistical Computation and Simulation, 2015b. V. Audigier, F. Husson, and J. Josse. A principal component method to impute missing values for mixed data. Advances in Data Analysis and Classification, pages 1–22, 2014. In press. D. B. Rubin. Multiple Imputation for Non-Response in Survey. Wiley, New-York, 1987. J. L. Schafer. Analysis of Incomplete Multivariate Data. Chapman & Hall/CRC, London, 1997. 37 / 37
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}