for Fun and Profit Jo˜ ao Pedro Matos Teixeira Dias Supervisor: Hugo Sereno Ferreira, PhD Co-Supervisor: Rui Gon¸ calves, MSc July 17, 2016 Faculdade de Engenharia da Universidade do Porto
of the most disruptive innovations in trading. Marketing and advertising techniques are used to influence costumers’ behaviour, trying to increase sales and profits. • Recommendation systems are one of the used techniques. Data mining and machine learning techniques had been applied to e-commerce as a way to improve e-metrics. • Customer retention and engagement, click-trough rate, conversion rate, shopping cart abandonment rate, customer lifetime value. 2/17
learning providers in order for them to develop new algorithms and models to run on their websites. At an early stage, data scientists face some challenges: • Getting a grasp of the website’s structure and content; • Understanding the typical users’ behaviour (archetypical users); • Dealing with heterogeneous nature of the Web data; • Handling whether data is semi-structured or lacks structure at all; • Finding a good process for extracting and representing the data collected from the websites. 3/17
present on a given e-commerce website and usage log files; 2. A consistent and adaptable model that represents the website structure, content and users, establishing connections and relationships between the data (that could otherwise pass unnoticed); 3. A reduction of the need of developing and applying a different approach for each website, trying to reduce costs and resources. 4/17
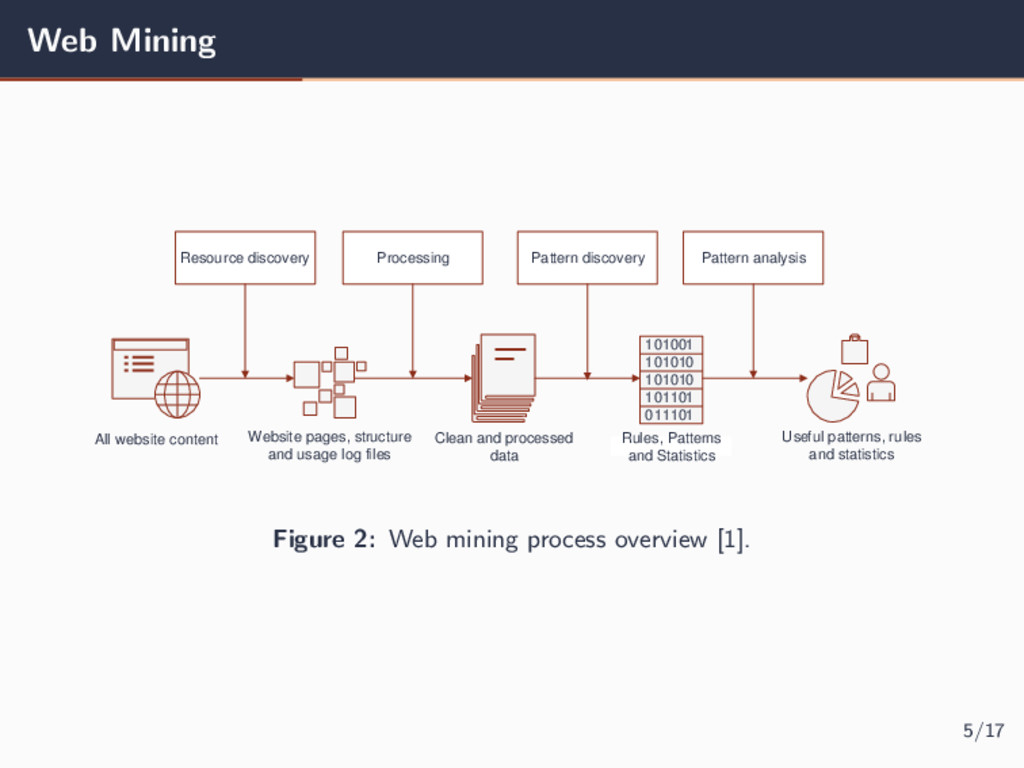
data 101001 101010 101010 101101 011101 Useful patterns, rules and statistics Rules, Patterns and Statistics Resource discovery All website content Website pages, structure and usage log files Figure 2: Web mining process overview [1]. 5/17
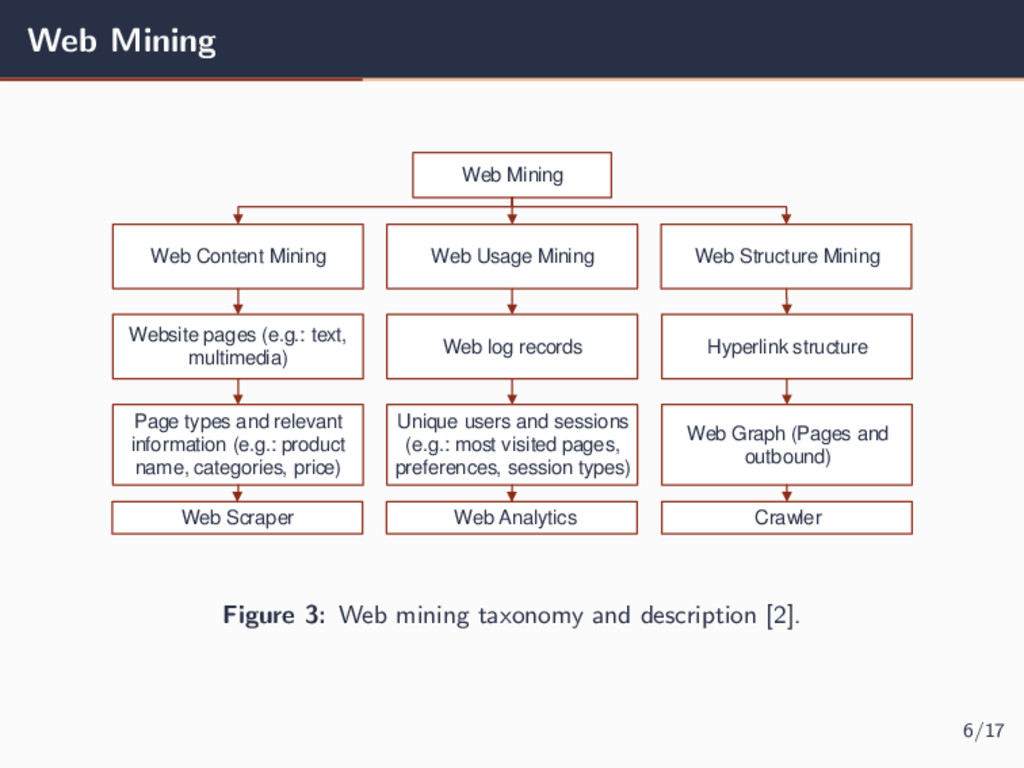
Web Usage Mining Website pages (e.g.: text, multimedia) Hyperlink structure Web log records Page types and relevant information (e.g.: product name, categories, price) Unique users and sessions (e.g.: most visited pages, preferences, session types) Web Graph (Pages and outbound) Web Scraper Crawler Web Analytics Figure 3: Web mining taxonomy and description [2]. 6/17
usage records; 2. Transform the collected data into structured data formats; 3. Categorise the website’s pages by page type and category; 4. Identify unique users and sessions and categorise the sessions into pre-defined types; 5. Establish new relationships between the different analysed data sources: • Website category tree; • Keyword-based user profiles; 6. Identify archetypical website users through clustering; 7. Build a coherent representation of the website structure, content and users as an information model. 8/17
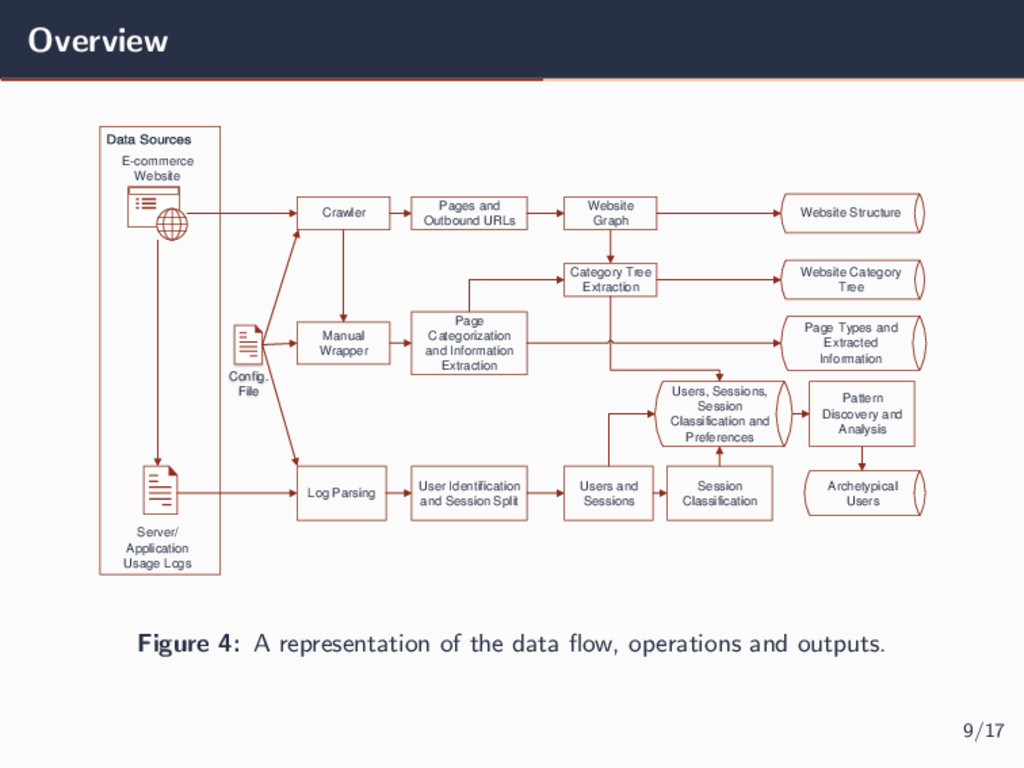
Usage Logs Website Graph Page Types and Extracted Information Page Categorization and Information Extraction User Identification and Session Split Category Tree Extraction Pages and Outbound URLs Users and Sessions Users, Sessions, Session Classification and Preferences Session Classification Pattern Discovery and Analysis Archetypical Users Config. File Website Structure Website Category Tree Figure 4: A representation of the data flow, operations and outputs. 9/17
Heterogeneity of the websites; • Semi-structured nature of the data. Approach used: • Scraper with manual approach; • Page categorization (Page Type and Page Category). Web Structure Mining Main challenges: • Spider traps; • URL extraction and canonicalization. Approach used: • Web Crawler. Web Usage Mining Main challenges: • Complex log formats and unavailable information. Approach used: • Uniformization of the log data; • Unique user and session identification; • Session categorization[6] (length, duration and mean time per page). 10/17
Information extracted from pages (Categories). Output: Tree structure with categories and sub-categories present in the website product catalogue. Keyword-based Profiles Sources: • User sessions; • Information extracted from pages (Categories and Page Types). Output: Information about pages visited by category and by type in user profiles. 11/17
our user profile database, we proceed to apply the k-means clustering algorithm. • Keyword-based user profiles clustering; • Session type based clustering. The result of the application of this algorithm gives us a set of clusters that contains users with similarities between them (e.g. preferences and session types). From this set of similar groups of users we can get a grasp of the archetypical website users. 12/17
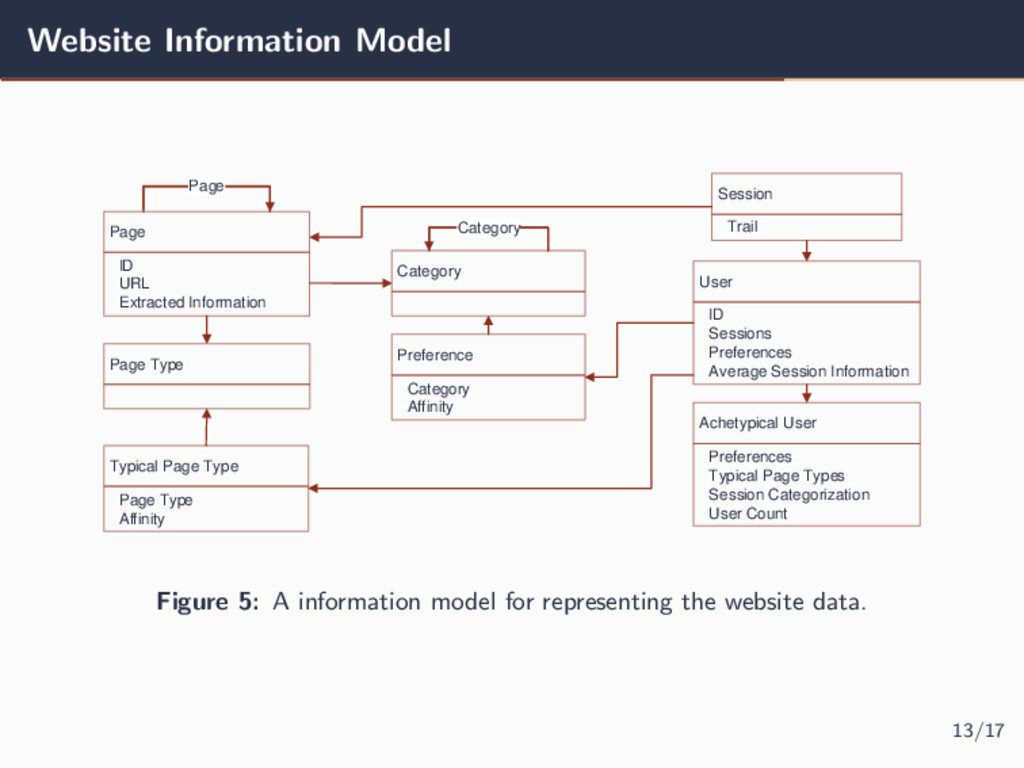
Sessions Session Trail Preference Category Preferences Average Session Information Typical Page Type Page Type Affinity Achetypical User Preferences Session Categorization Typical Page Types User Count ID Page Category Affinity Extracted Information Figure 5: A information model for representing the website data. 13/17
Sample usage data size: 1 000 000 events captured over aprox. 2 days and 17 hours. Captured at the application layer. Niche dedicated e-commerce website • Sample usage data synthetically generated with Fiddler Web Debugger. Mimics the web server logs format (plain text). 14/17
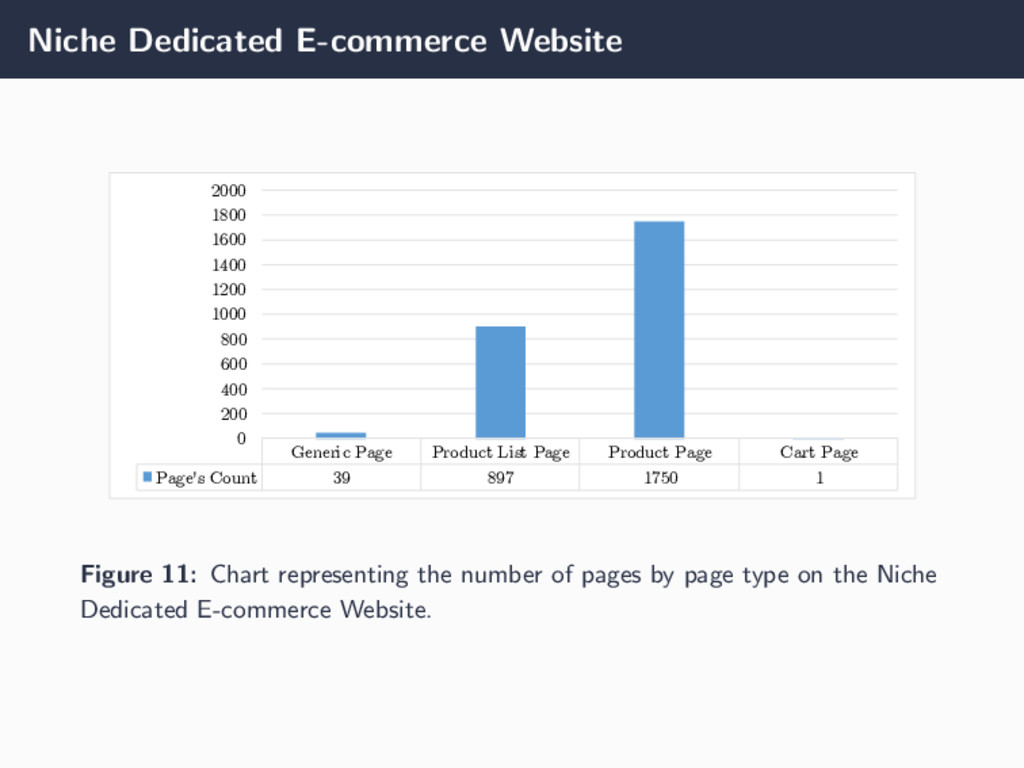
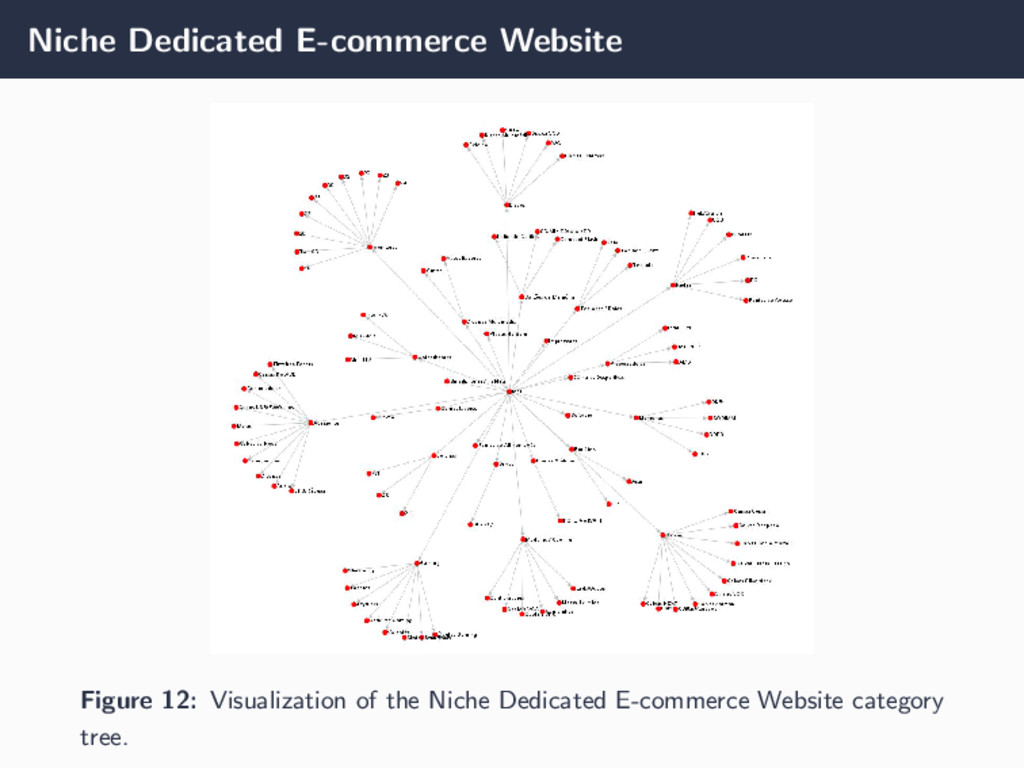
with 11 044 225 links; • Category tree with 1632 nodes; • 111 141 unique users with 135 056 sessions; • Average of 4.6 pages visited by user with an average session time of 125.07 seconds. • 5 user clusters resulted from clustering by preferences and 7 clusters resulted from clustering by session characteristics. Niche dedicated e-commerce website • 2687 crawled pages with 361 344 links; • Category tree with 128 nodes; • Synthetic data used to validate the proof-of-concept by providing certain input data (navigate over a defined set of pages) and check the output, comparing expected and obtained outputs. 15/17
techniques to the web and e-commerce is not new, with a lot of research being done in this field. The main contributions of this dissertation are: • An all-in-one process to collect and structure data from an e-commerce website’s content, structure and users. • Crossing of the data collected from diverse sources in order to find non-trivial relationships, enriching the process output. • An information model of the e-commerce website, containing the collected and structured information, including data resulted from crossing different sources and pattern discovery tasks. 16/17
we can consider the following improvements: • Improve the crawler implementing parallelism and/or prioritisation of the frontier; • Identify and differentiate static from dynamic hyperlinks; • Carry experiments with another kind of web scrapers (e.g. wrapper induction); • Increase the data crossings (e.g. cross content and usage data to get to know the favourite user brands or range of prices); • Apply different algorithms to finding and understand the archetypical website’s users (e.g. other cluster algorithms or other pattern discovery techniques); • Analyse the possibility of expanding this methodology beyond e-commerce websites, finding other user cases. 17/17
mining technology and its application in e-commerce. 2010 2nd International Conference on Computer Engineering and Technology, 7:V7–277–V7–280, 2010. Ahmad Siddiqui and Sultan Aljahdali. Web Mining Techniques in E-Commerce Applications. International Journal of Computer Applications, 69(8):39–43, may 2013. Djallel Bouneffouf. Towards user profile modelling in recommender system. arXiv preprint arXiv:1305.1114, 2013.
on personalized recommendation in e-commerce. In e-Business Engineering, 2008. ICEBE’08. IEEE International Conference on, pages 585–589. IEEE, 2008. Susan Gauch, Mirco Speretta, Aravind Chandramouli, and Alessandro Micarelli. User profiles for personalized information access. In The adaptive web, pages 54–89. Springer, 2007. Suchacka Gra˙ zyna and Grzegorz Chodak. Practical Aspects of Log File Analysis for E-Commerce. (61160), 2013.
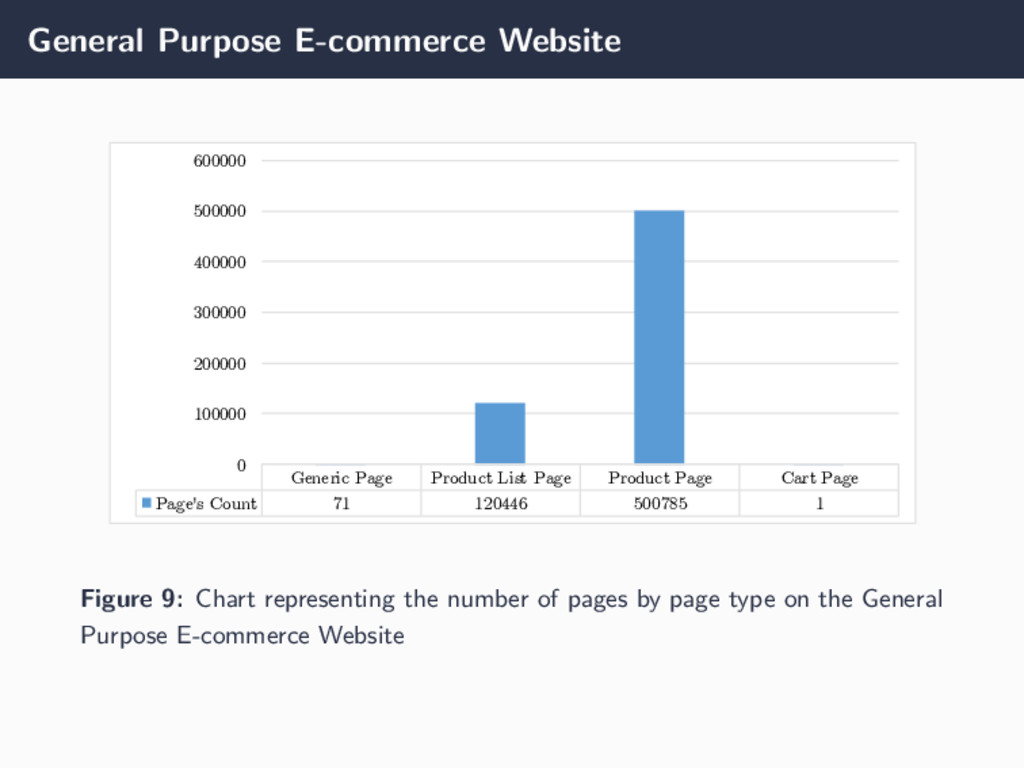
Page Cart Page Page's Count 71 120446 500785 1 0 100000 200000 300000 400000 500000 600000 Figure 9: Chart representing the number of pages by page type on the General Purpose E-commerce Website
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![User Profiling Key Components [3]: • User Background; • User](https://files.speakerdeck.com/presentations/06d526946ecc44929fad8f5d716eee95/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}