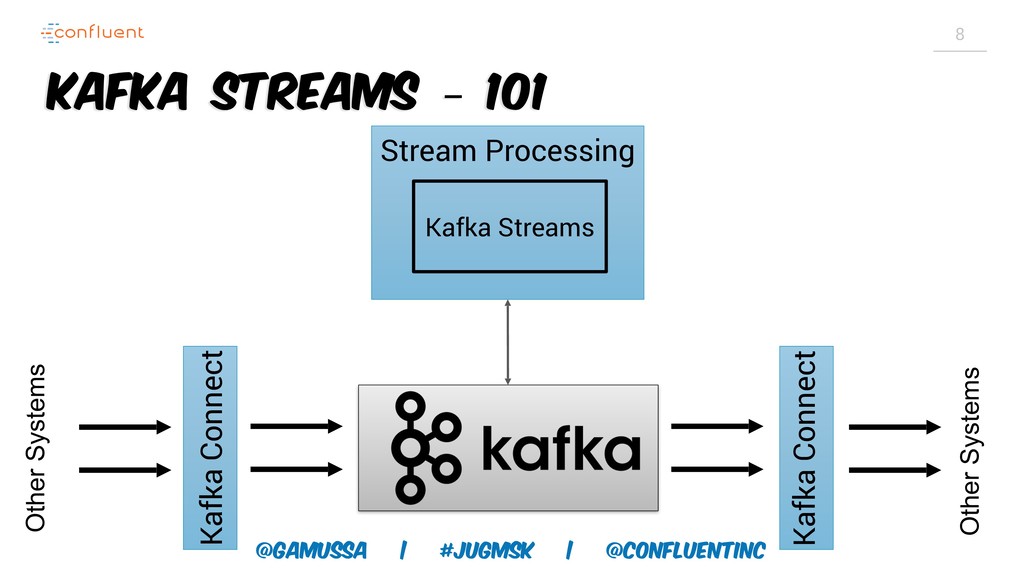
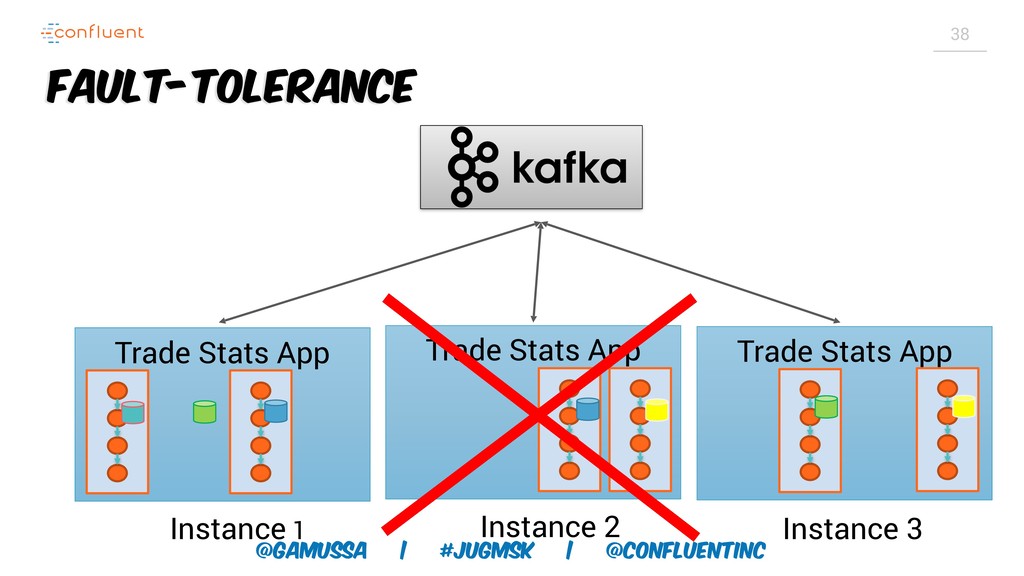
Рост популярности Apache Kafka как потоковой платформы, потребовал пересмотра традиционного подхода к распределенной обработке данных. Kafka Streams позволяет разрабатывать приложения без каких-либо кластеров. Подход «кластер на коленке» позволяет начать разработку и не задумываться о том, сможем ли мы потом масштабироваться (spoiler alert: Сможем!).
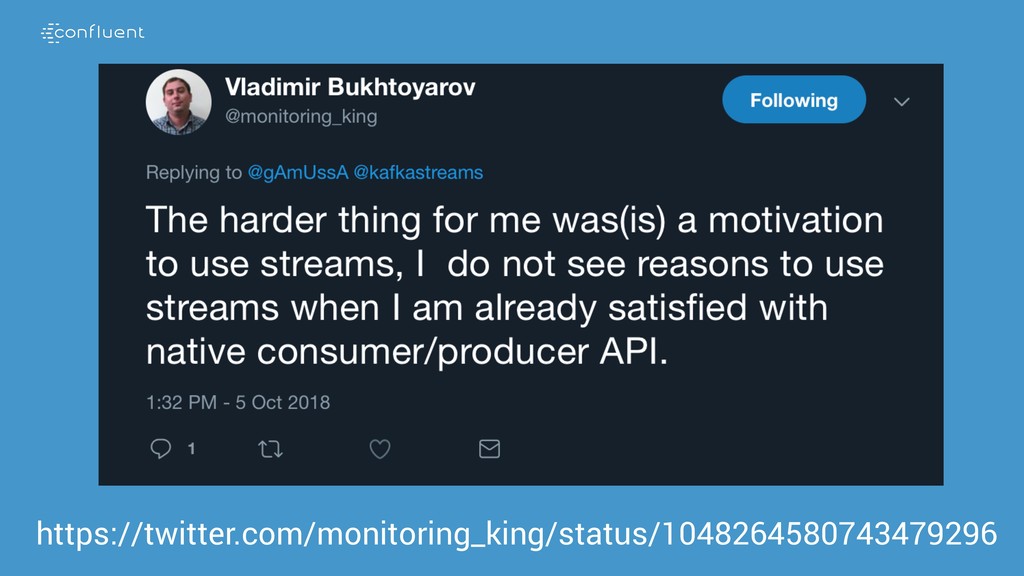
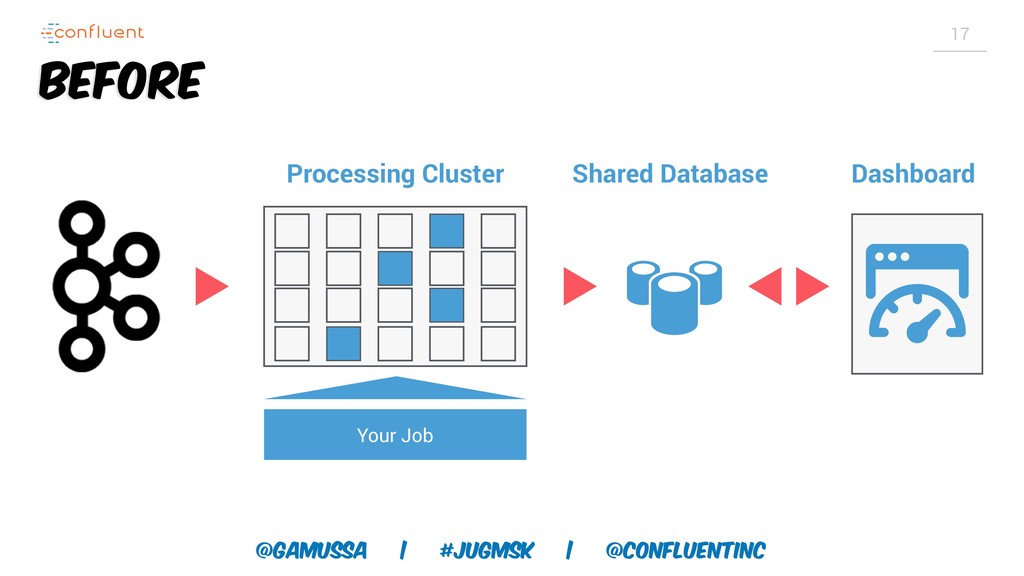
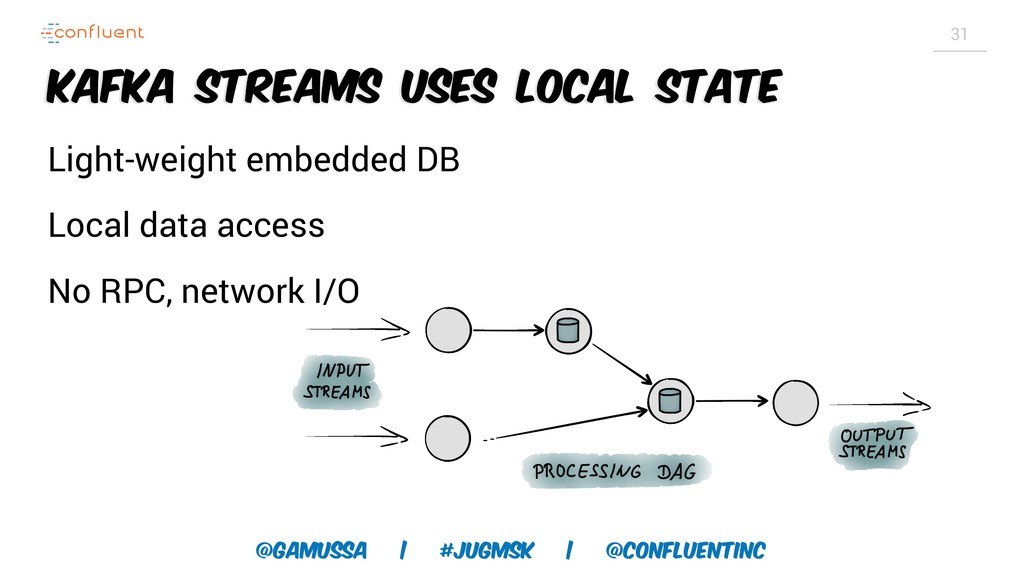
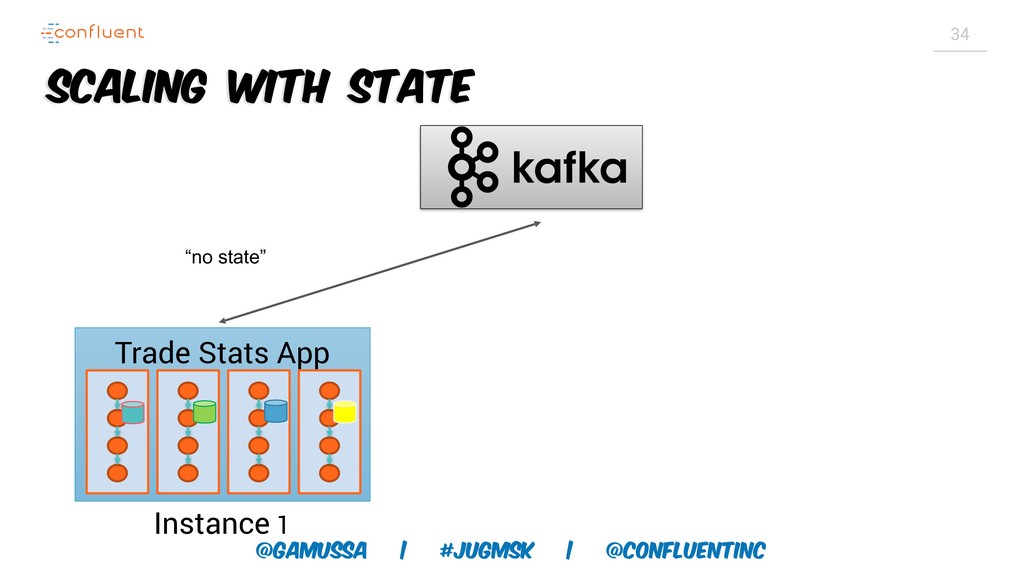
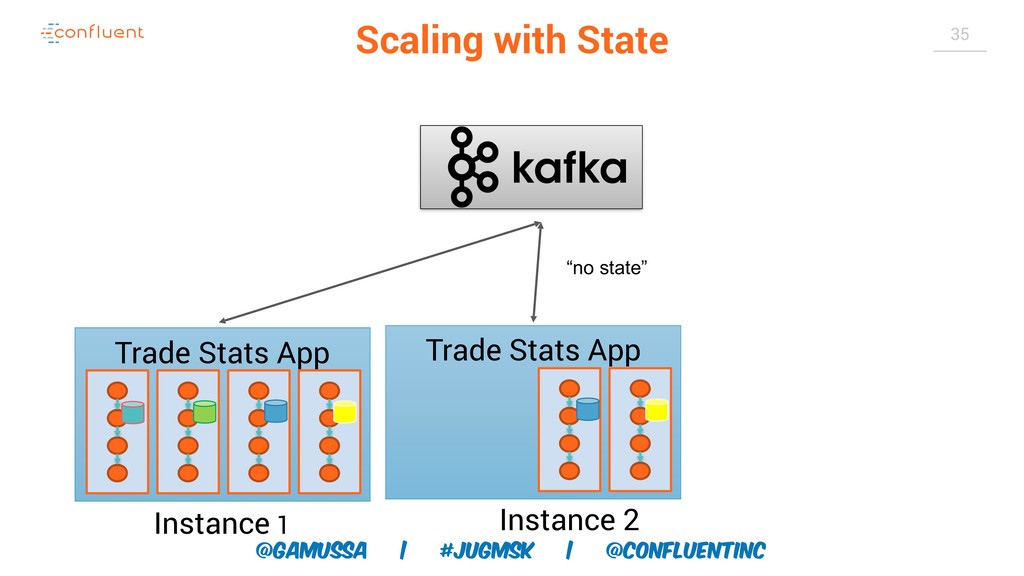
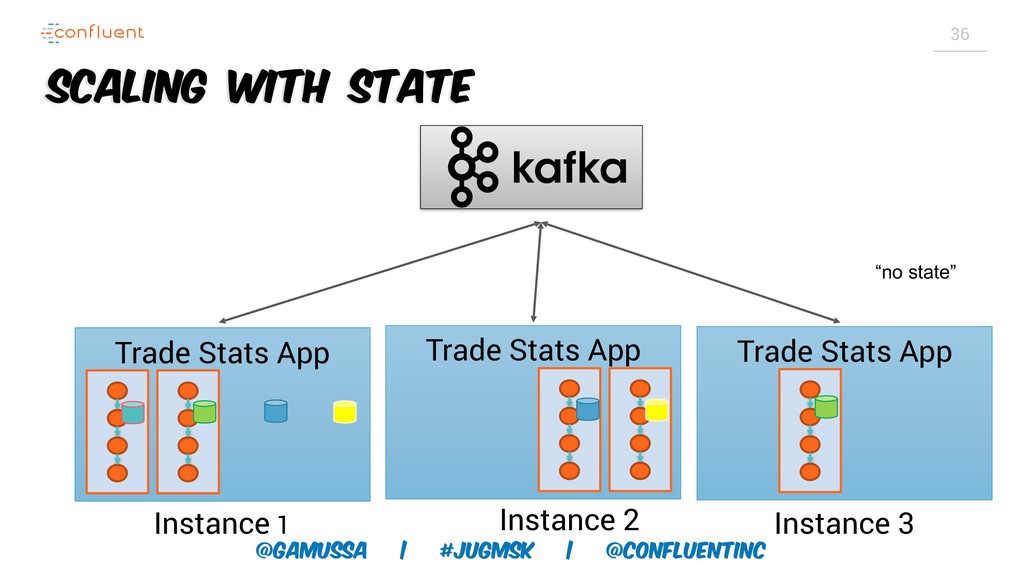
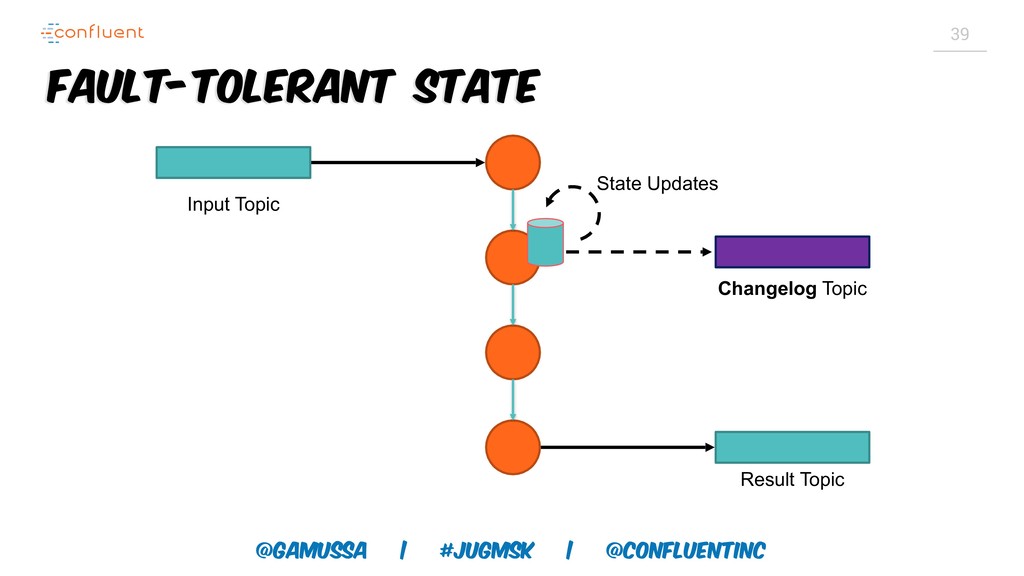
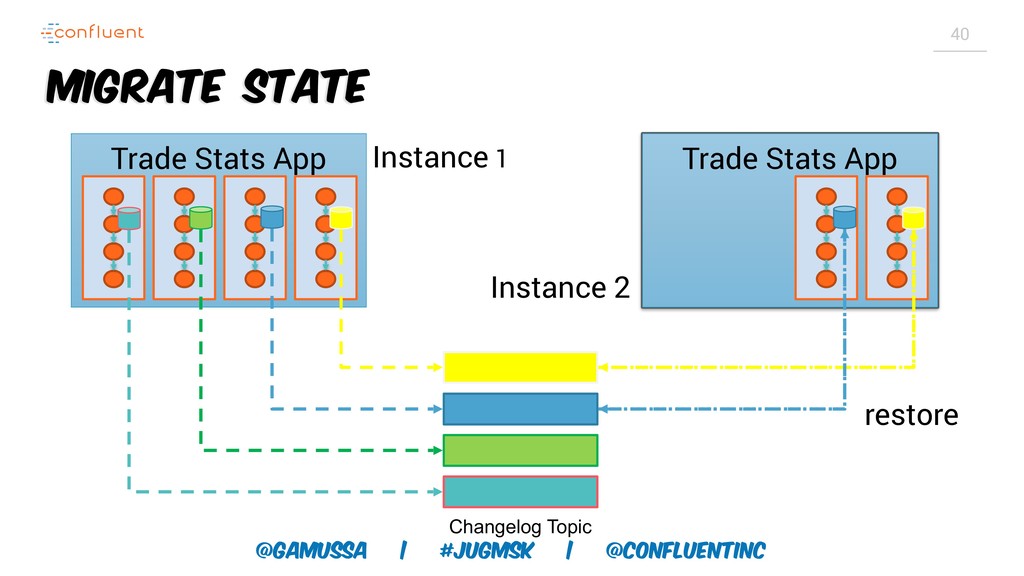
А слабо выкинуть традиционную базу данных для хранения результатов и промежуточного состояния?
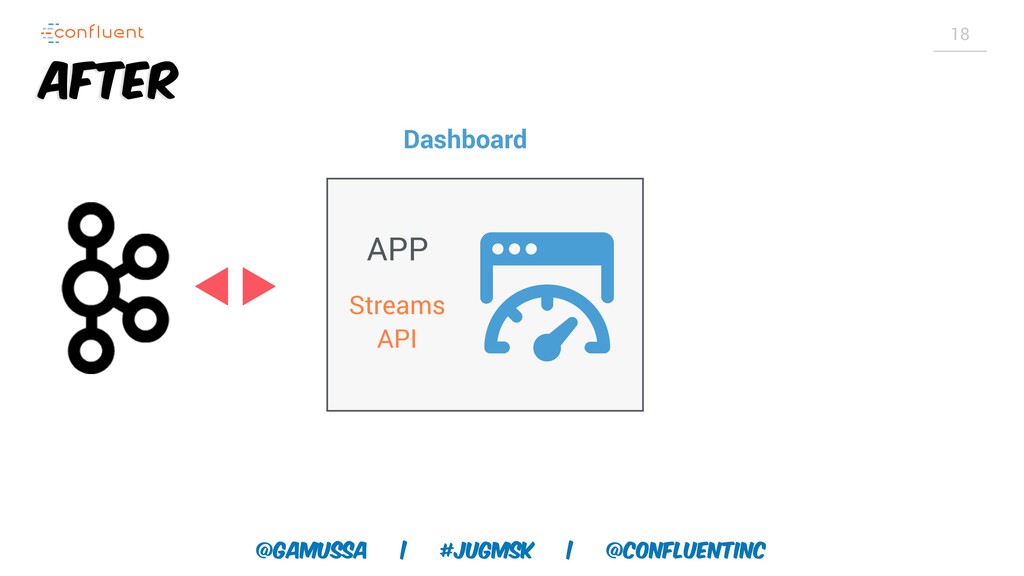
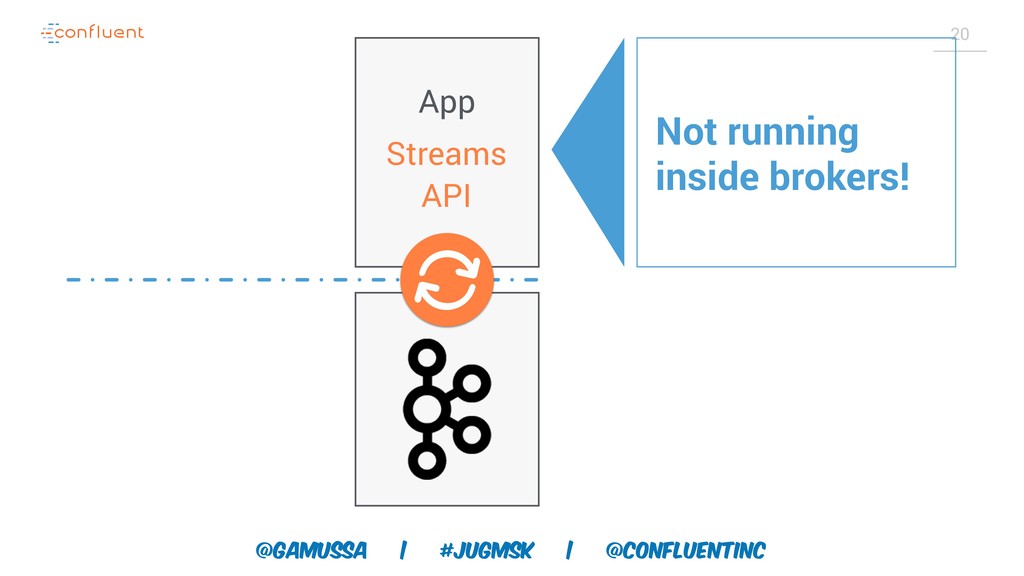
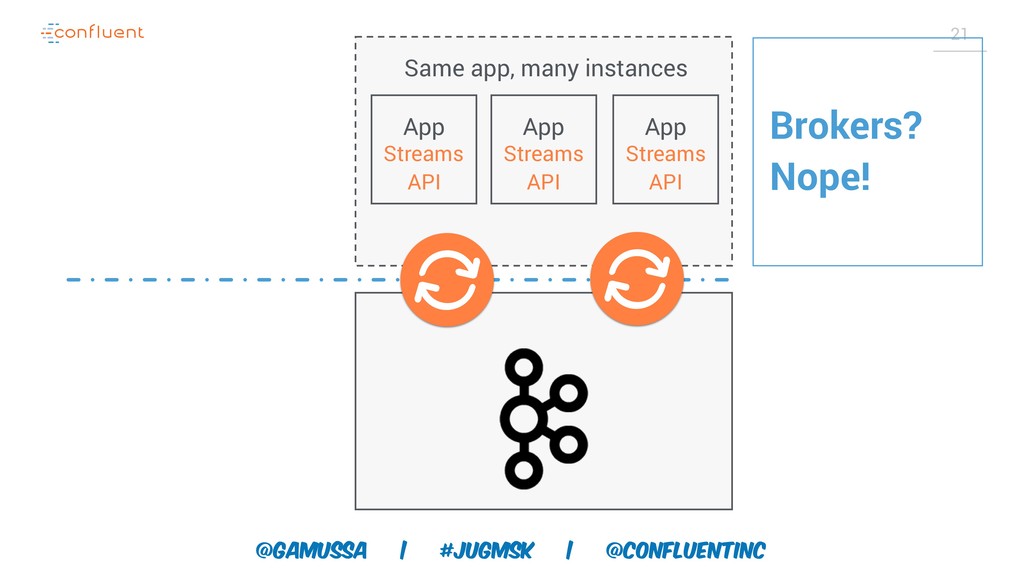
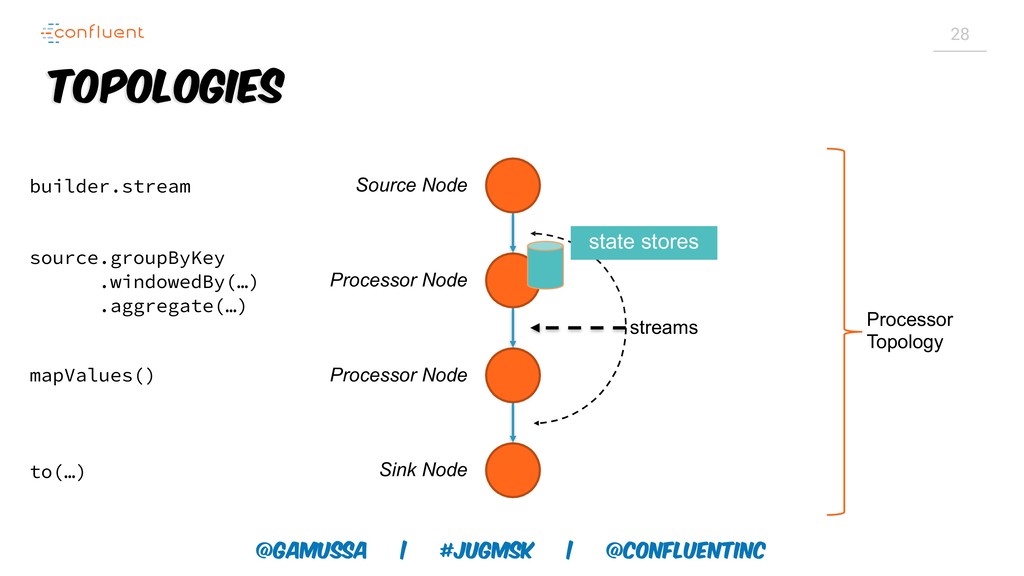
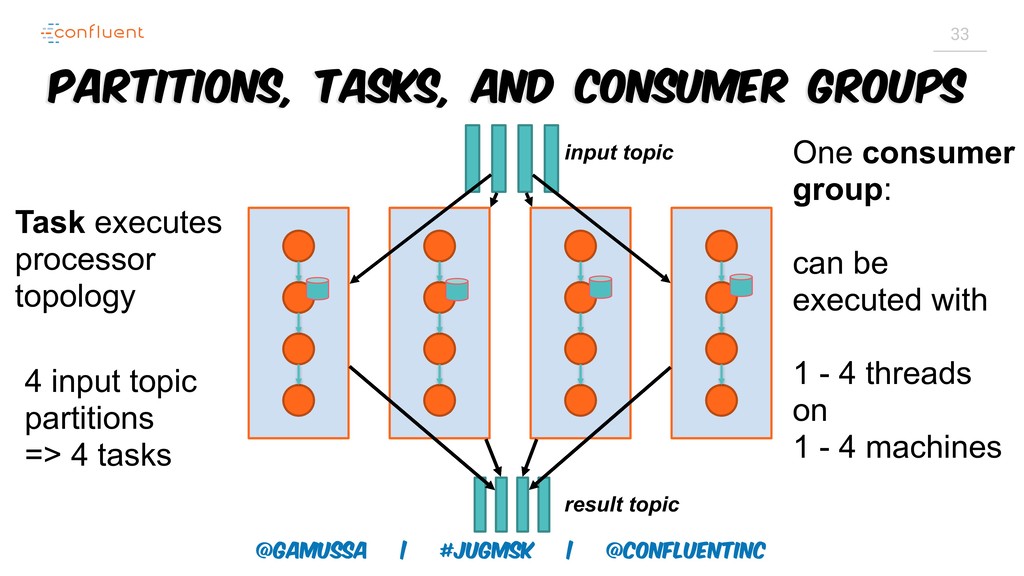
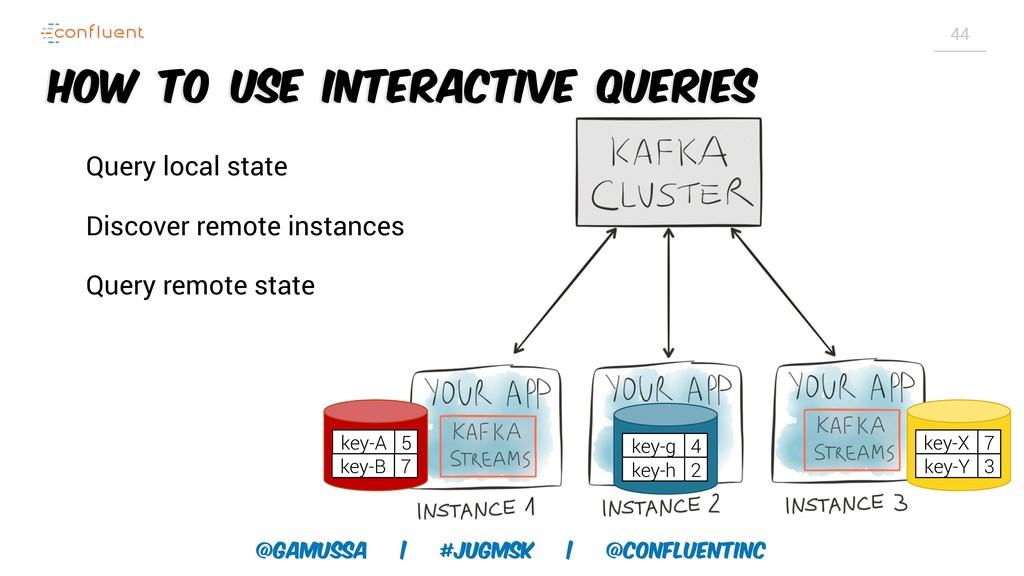
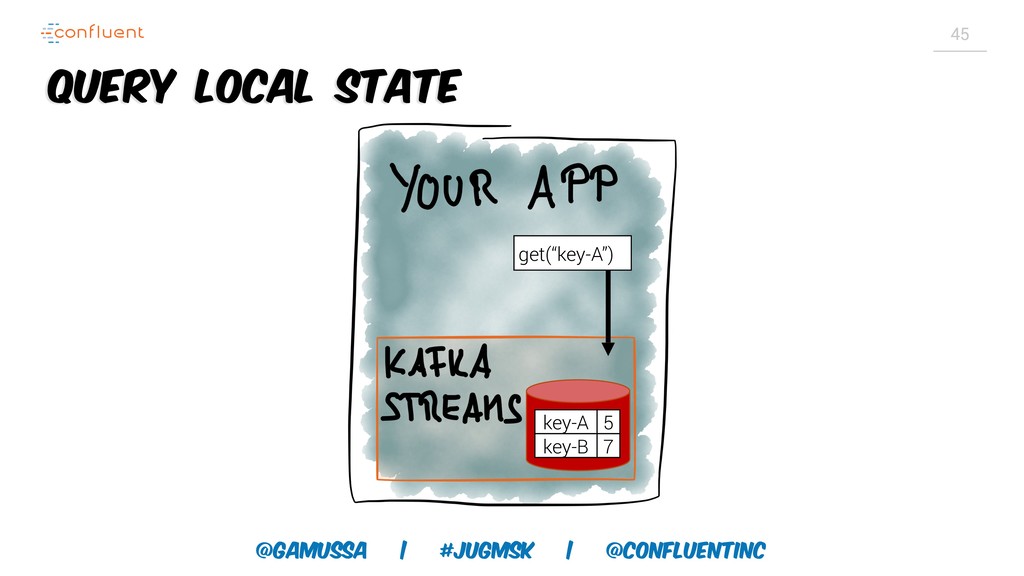
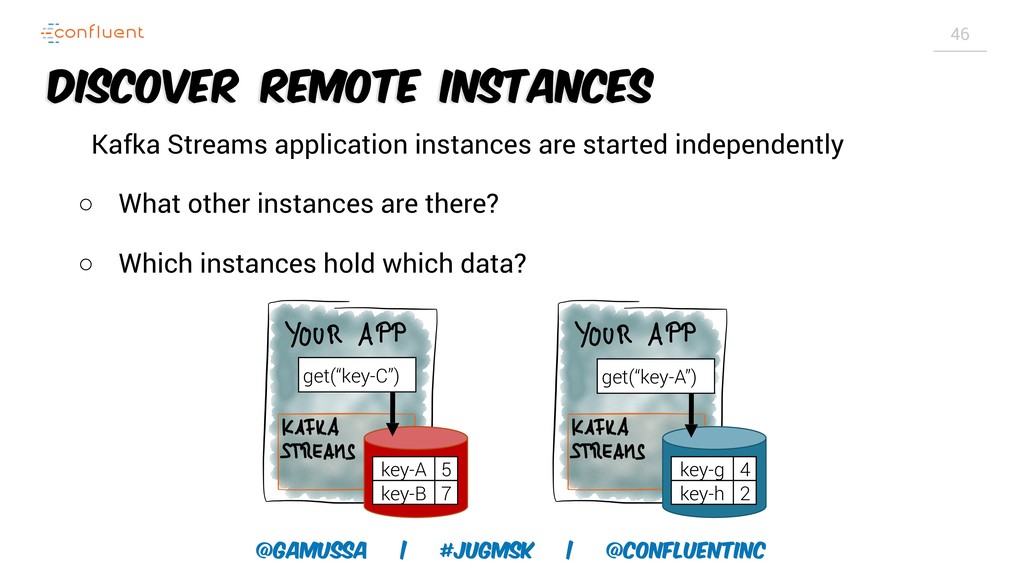
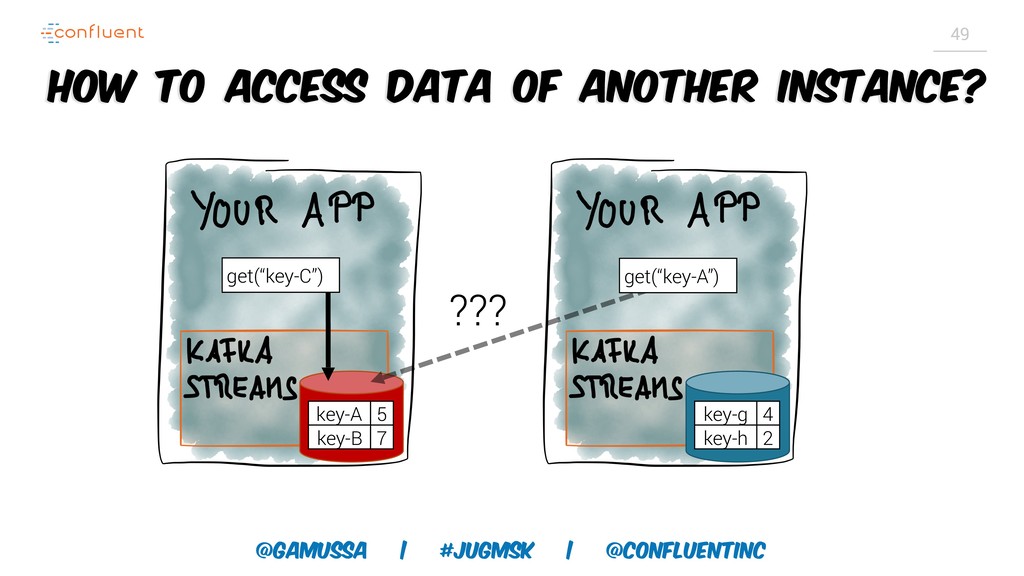
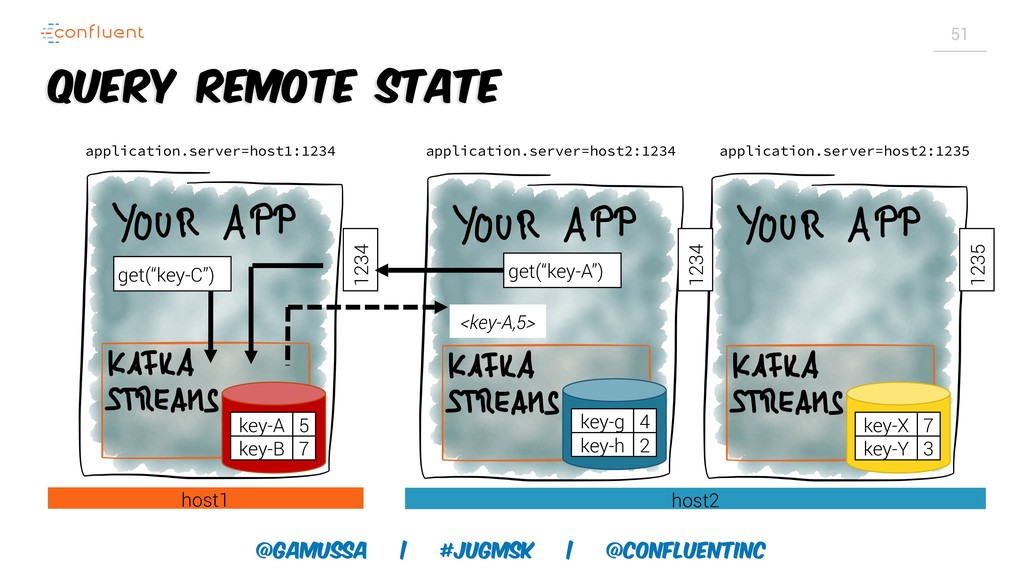
Доклад про Interactive Queries — часть API Kafka Streams, которая позволяет получить доступ к состоянию приложения без использования традиционных хранилищ — БД, кэшей и тп. Как такой подход позволяет упростить архитектуру для использования Kafka Stream в микросервисах.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@ @gamussa | #jugmsk | @ConfluentINc Thanks! @gamussa [email protected] We](https://files.speakerdeck.com/presentations/e456c21f90cd473497475d127e4dc5ab/slide_57.jpg){kind=link}
{kind=link}