Доклад посвящен особенностям профилирования небольших участков кода, которые сильно влияют на характеристики всего приложения. Как быть, если профилируемый код выполняется 0.0001 секунды, но хочется его ускорить до 0.00005 секунды? Мы рассмотрим пределы Java-профилировщиков и как выжать максимум из штатного профилировщика Linux — perf. Далее посмотрим, какие аппаратные особенности процессоров помогут нам получать репрезентативный профиль еще быстрее. В конце будет рассказано о технологии Intel Processor Trace, которая позволяет сделать еще один шаг в точности профилирования и реконструировать выполнение участка программы.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
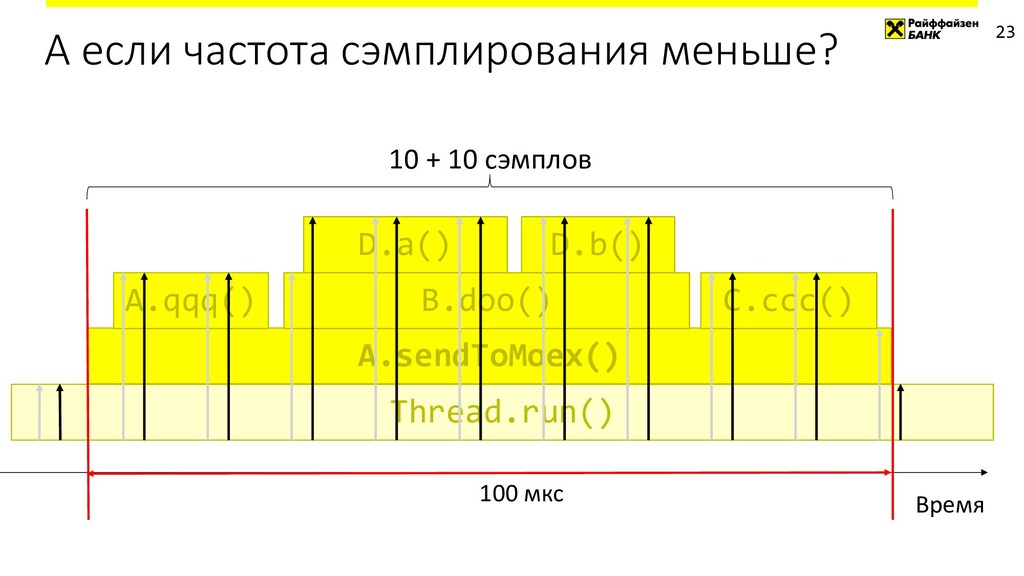{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
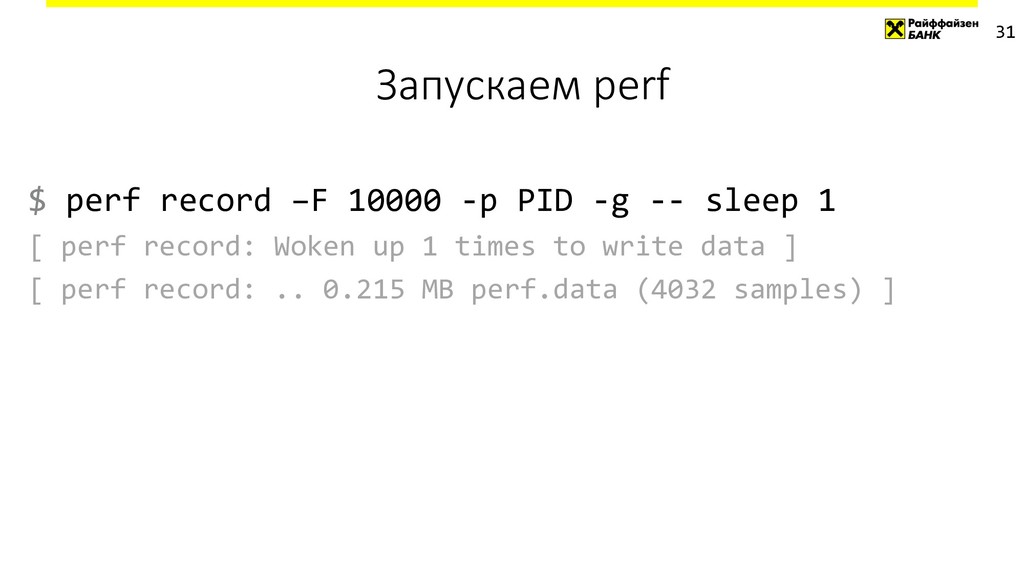{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
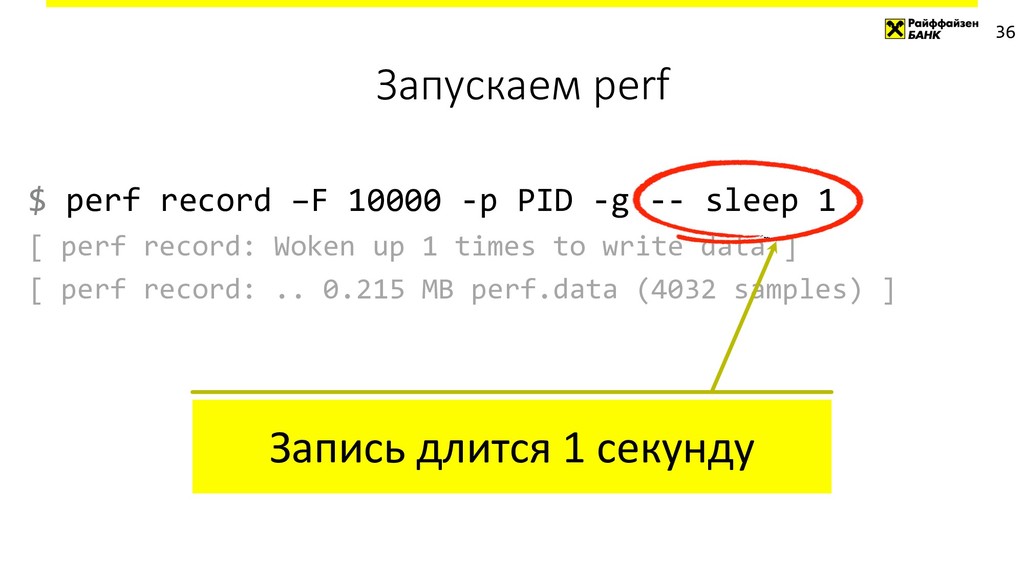{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![57 А тем временем в dmesg… [84430.412898] perf: interrupt took](https://files.speakerdeck.com/presentations/86282ba1f7884c419e53078d4c1943c8/slide_56.jpg){kind=link}
{kind=link}
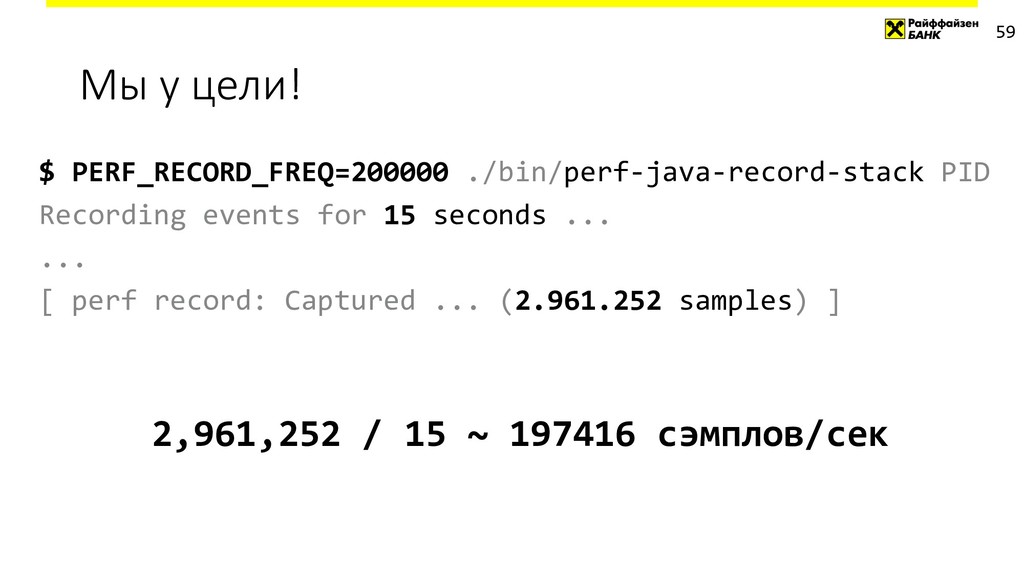{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
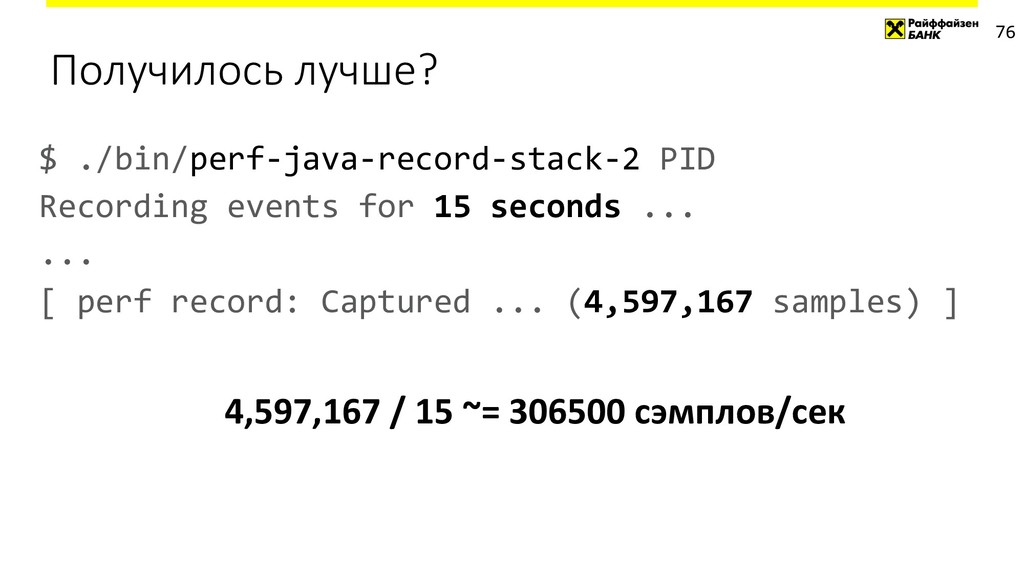{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
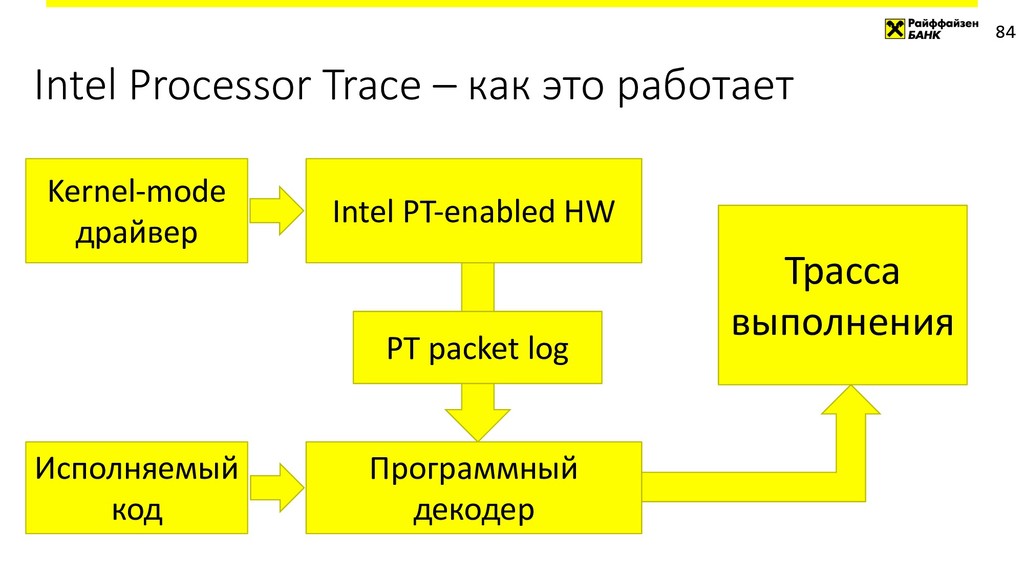{kind=link}
{kind=link}
{kind=link}
{kind=link}
![88 Попробуем запустить! class Test { public static void main(String[]](https://files.speakerdeck.com/presentations/86282ba1f7884c419e53078d4c1943c8/slide_87.jpg){kind=link}
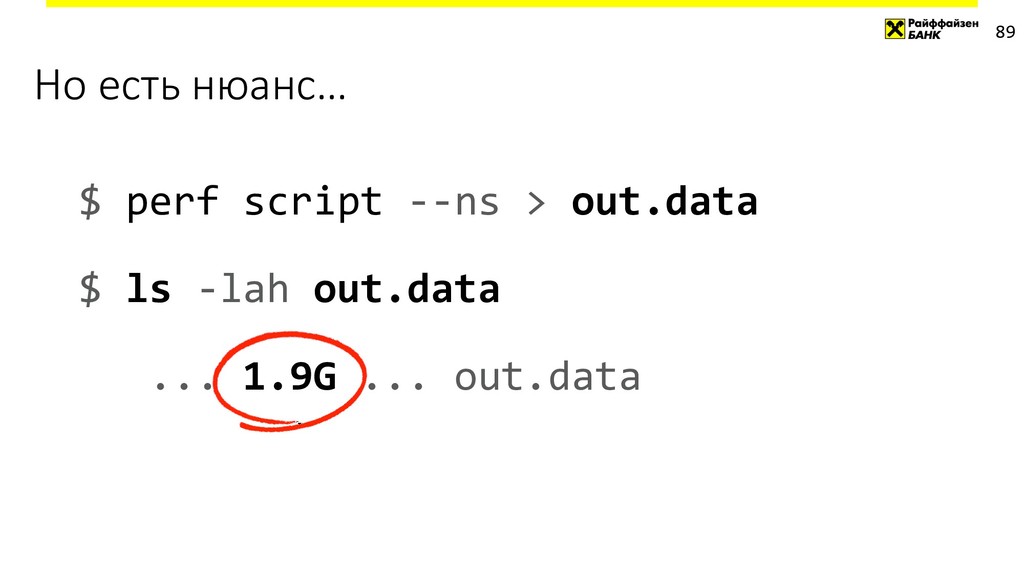{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
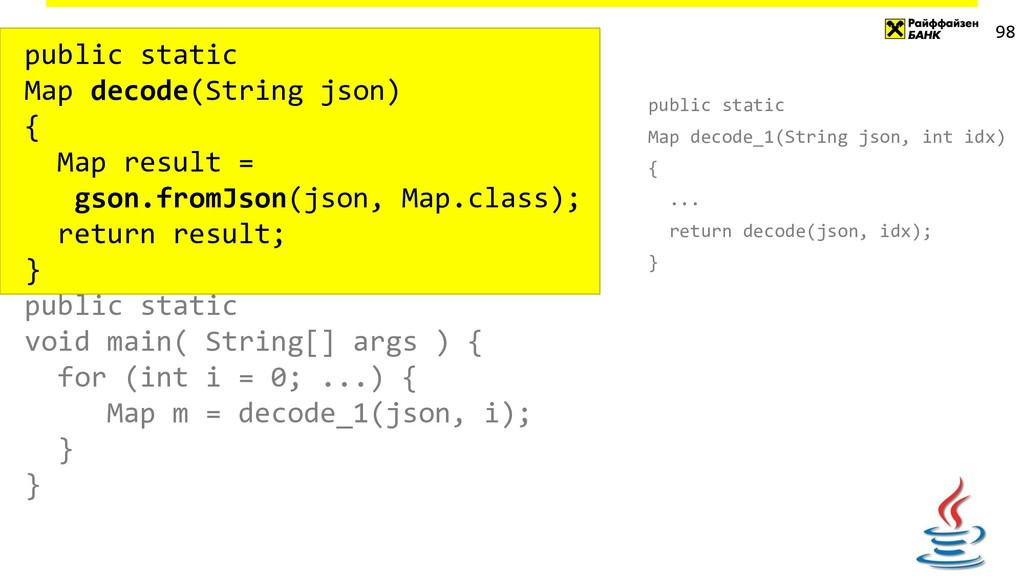{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![105 TOP в деталях 151080ns [ 8%] ...LinkedTreeMap->rebalance 155472ns [](https://files.speakerdeck.com/presentations/86282ba1f7884c419e53078d4c1943c8/slide_104.jpg){kind=link}
![106 TOP в деталях ... 151080ns [ 8%] ...LinkedTreeMap->rebalance 155472ns](https://files.speakerdeck.com/presentations/86282ba1f7884c419e53078d4c1943c8/slide_105.jpg){kind=link}
![107 TOP в деталях ... 151080ns [ 8%] ...LinkedTreeMap->rebalance 155472ns](https://files.speakerdeck.com/presentations/86282ba1f7884c419e53078d4c1943c8/slide_106.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] Q&A Sergey Melnikov Профилируем с точностью до инструкций и](https://files.speakerdeck.com/presentations/86282ba1f7884c419e53078d4c1943c8/slide_113.jpg){kind=link}