affair I can’t share it ain’t fair Haha I’m just playin’ ladies you know I love you. I know my love is true and I know you love me too Girl I’m down for whatever cause my love is true SONG A For a chance at romance I would love to enhance But everything I love has turned to a tedious task One day we gonna have to leave our love in the past I love my fans but no one ever puts a grasp SONG B
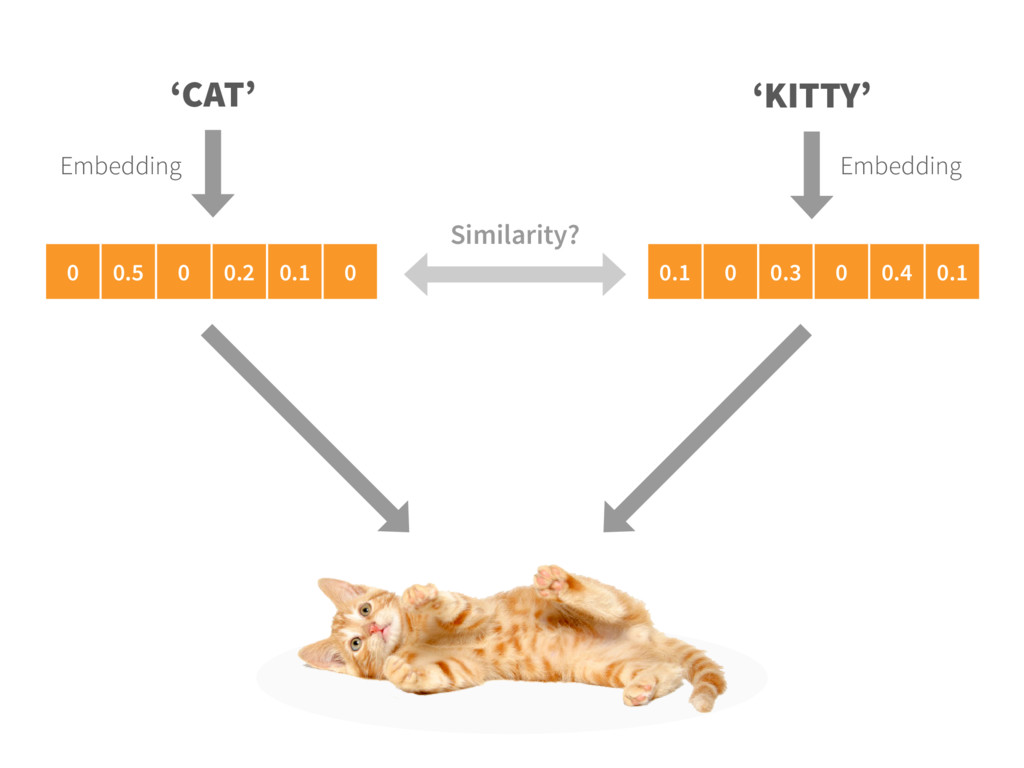
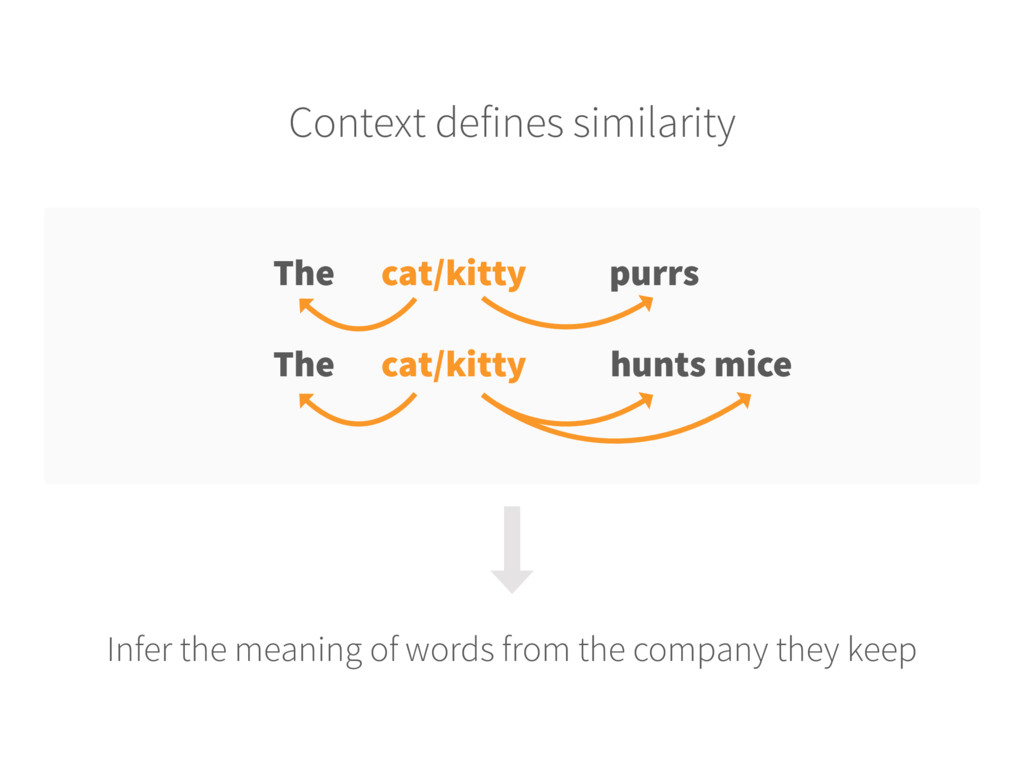
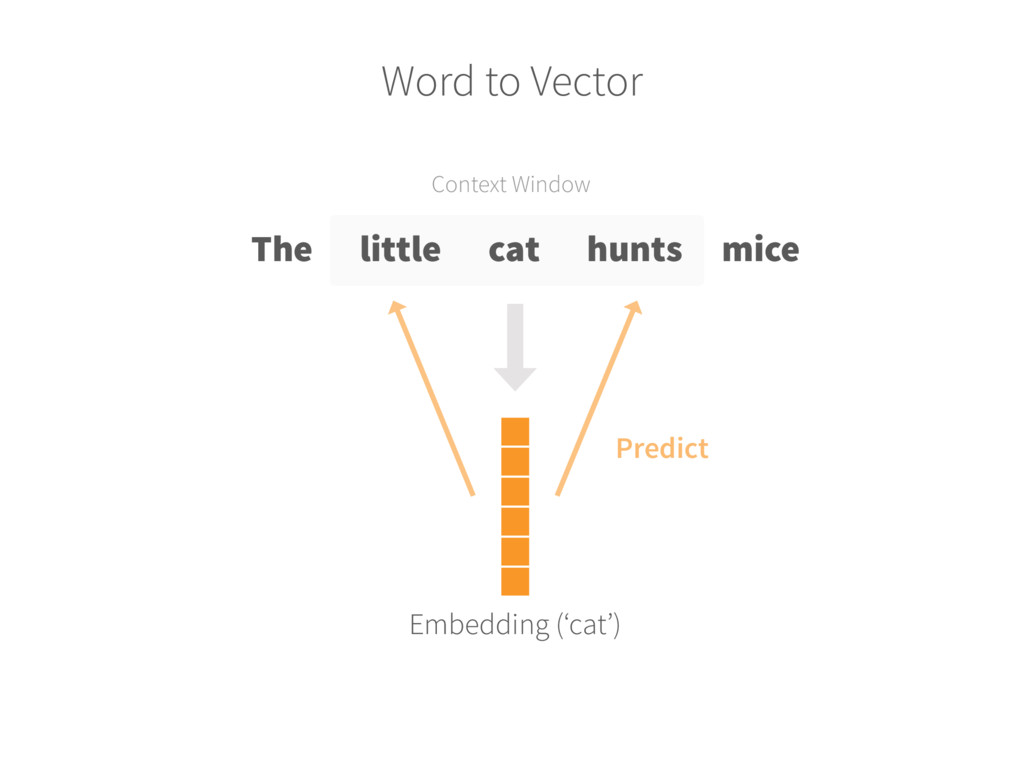
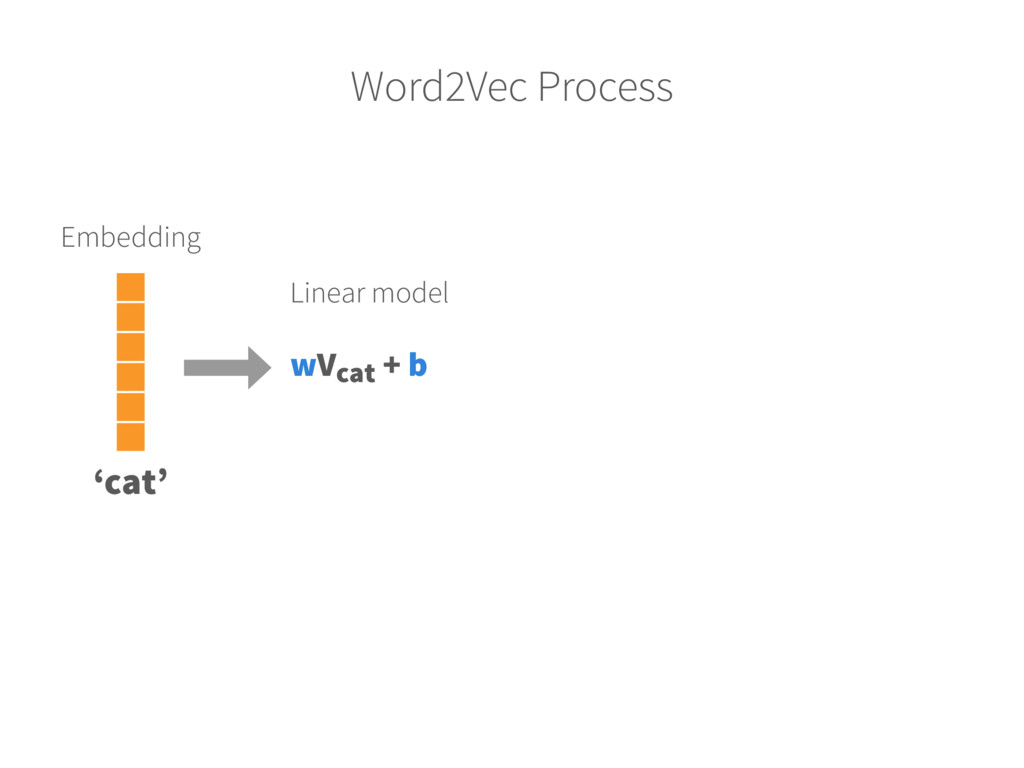
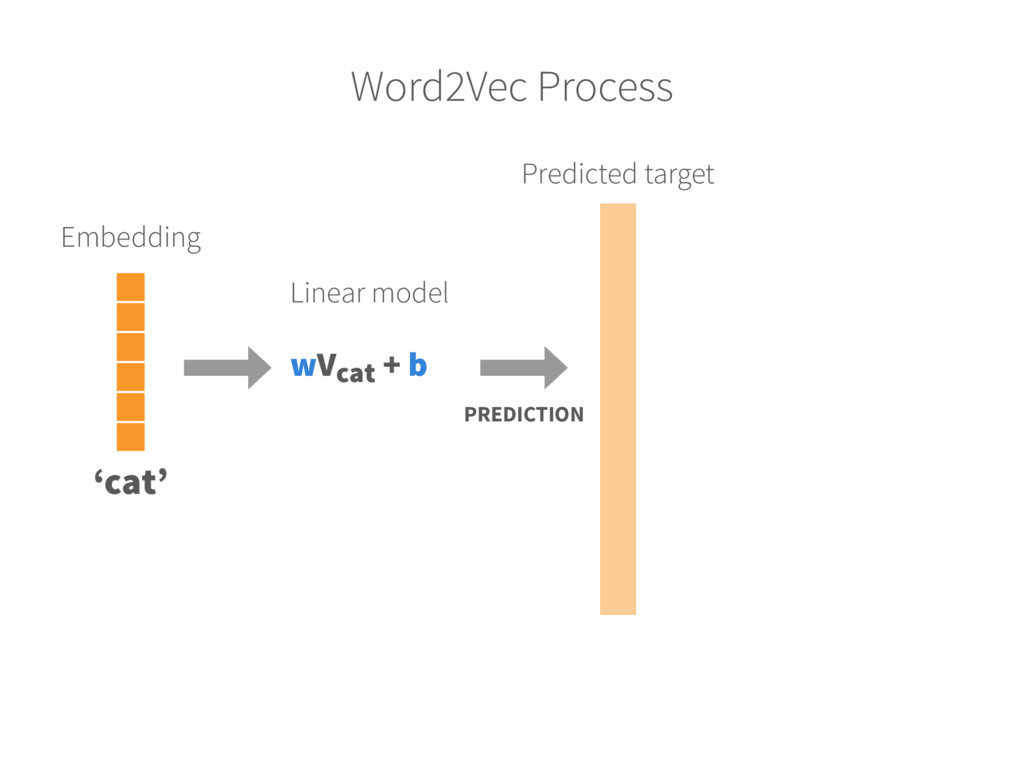
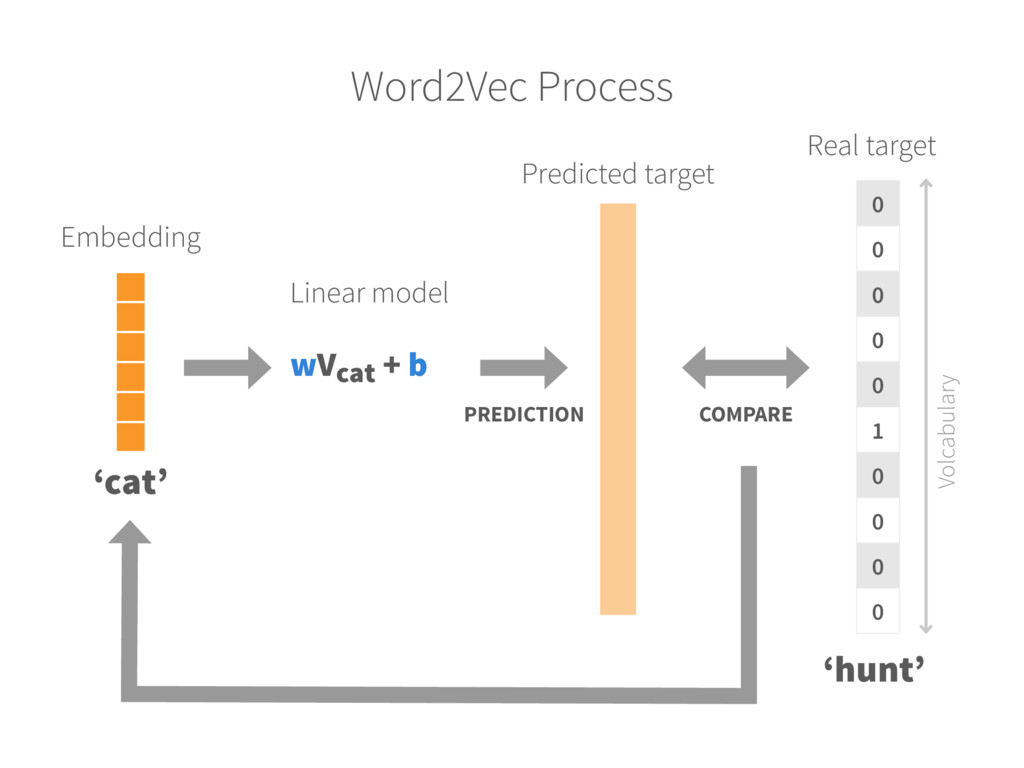
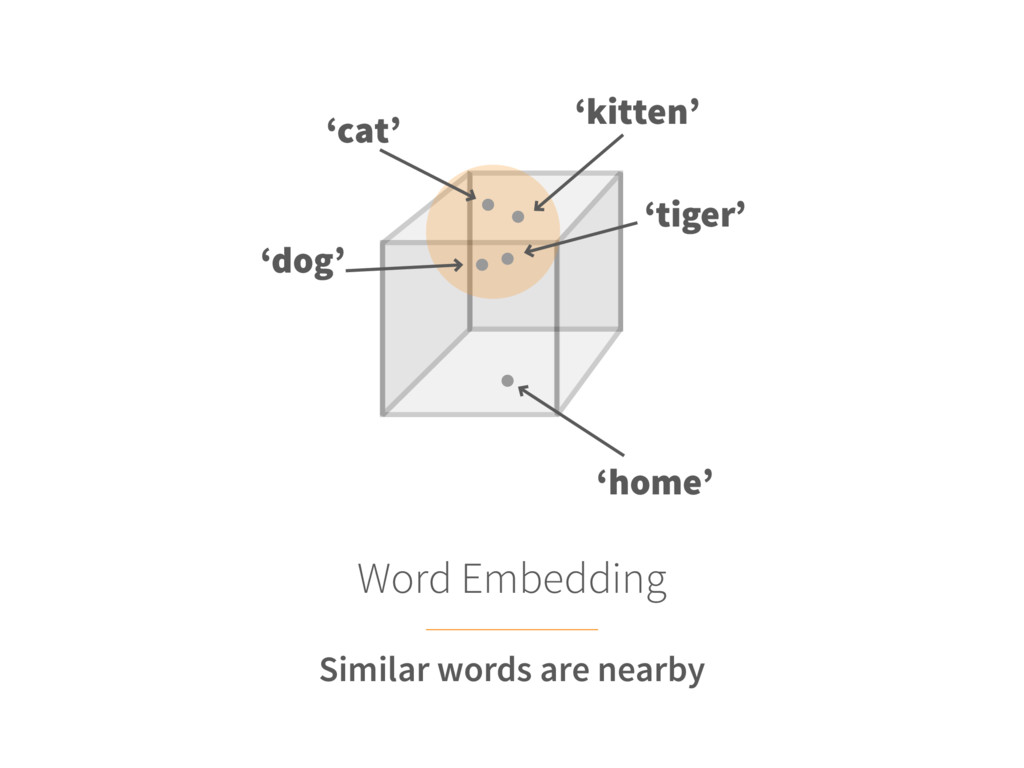
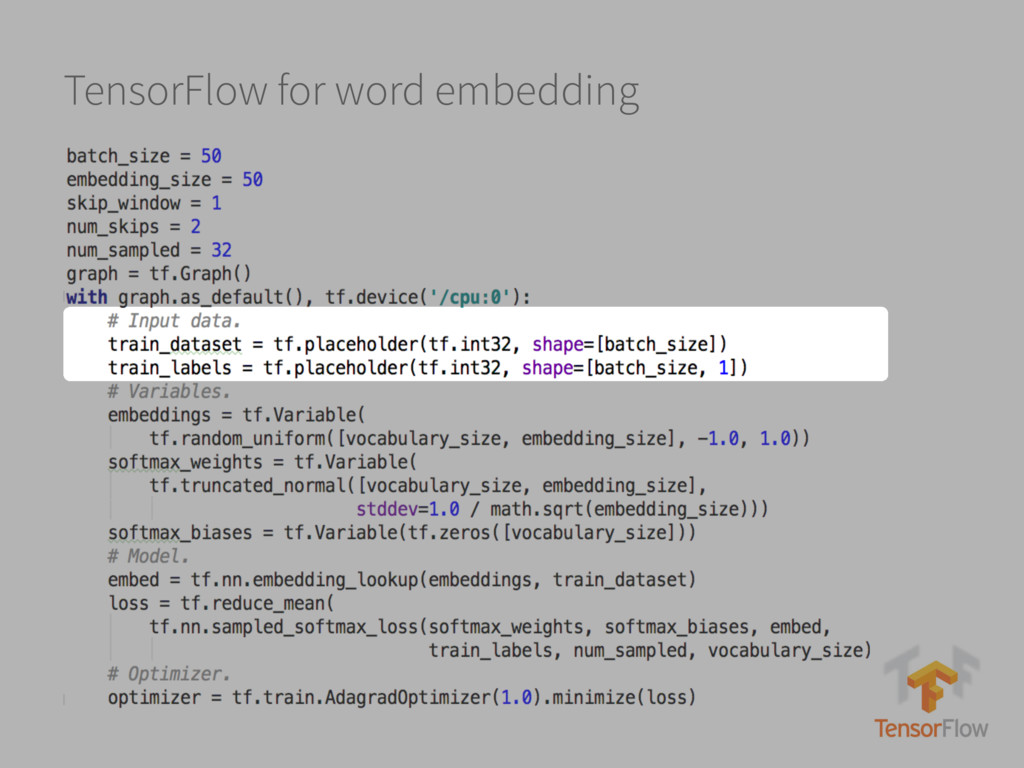
text 2. Randomly initialize embeddings Each word is mapped into a fixed-size embedding with random values 3. Set up prediction task For each word, pick a random word from the context and consider it as the target (label) INPUT WORD → TARGET WORD ‘Cat’ → ‘Hunt’ 4. Learn the embeddings Train a model (logistic classifier) to predict the target (neighbours of each word) Update the embedding
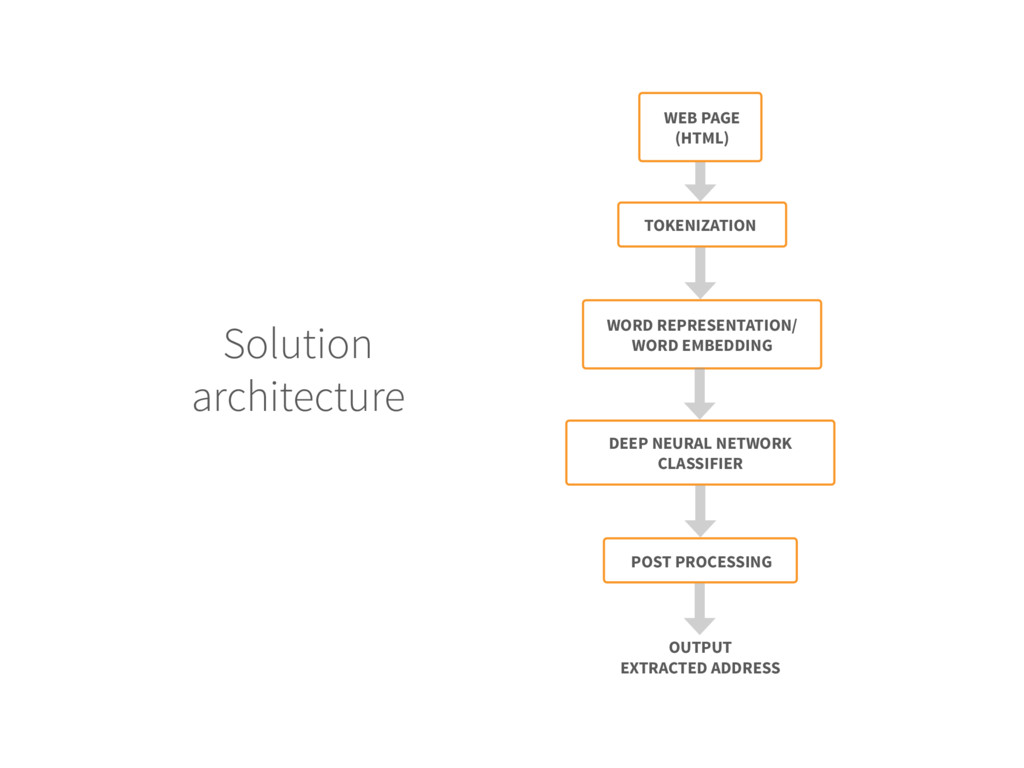
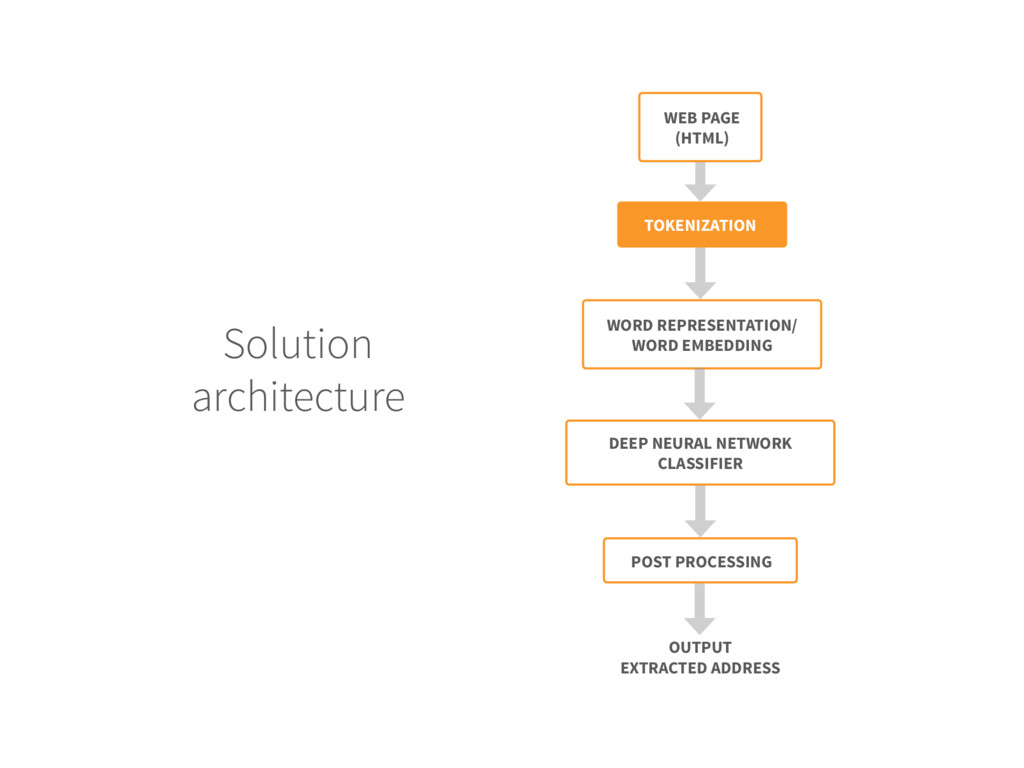
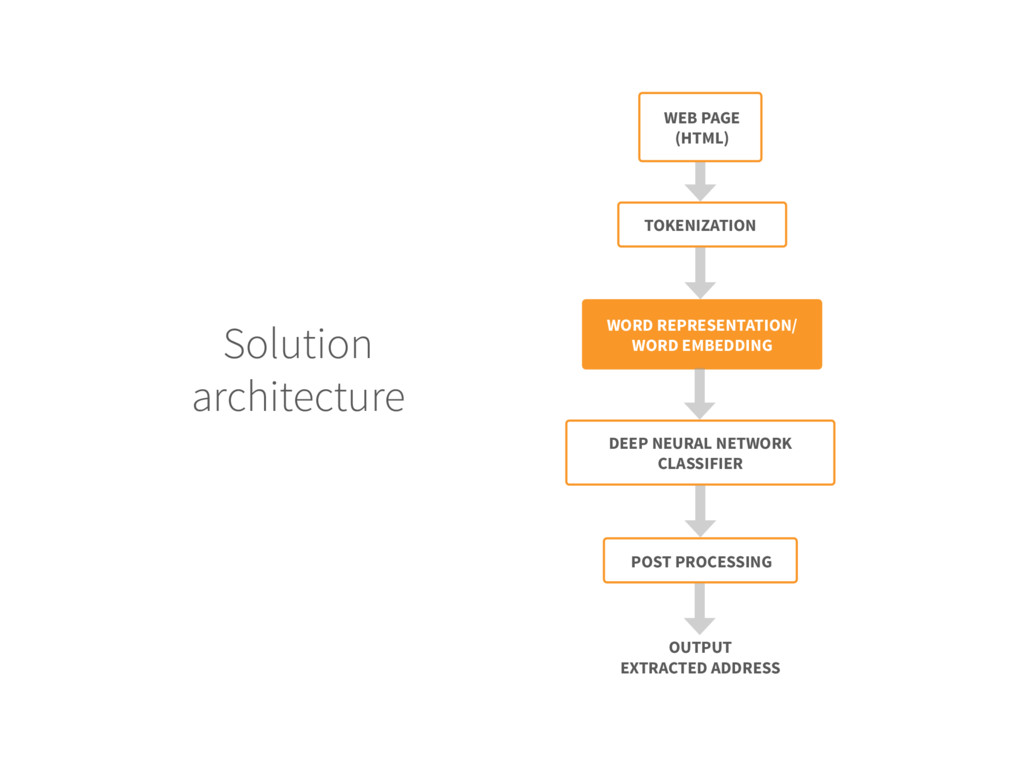
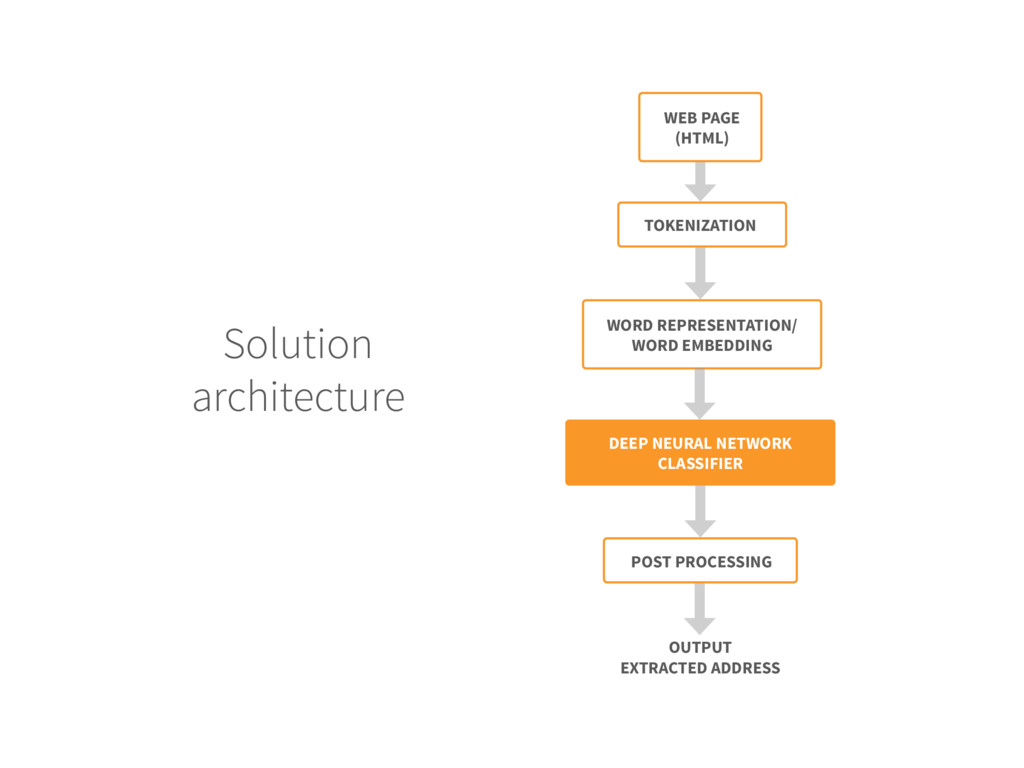
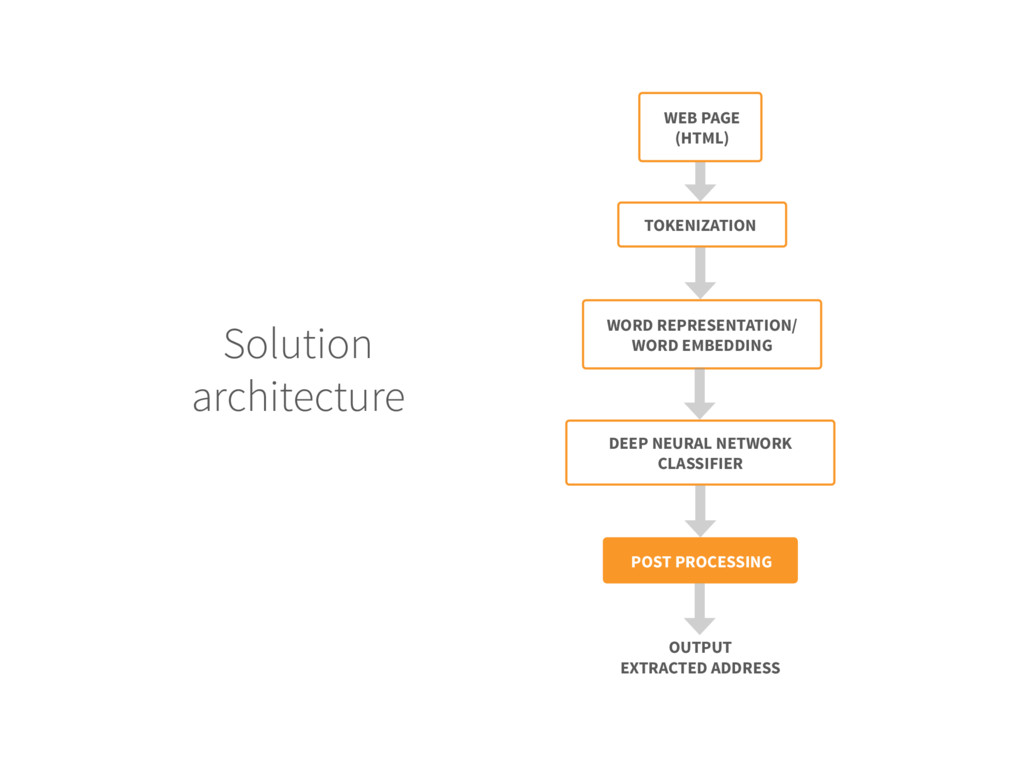
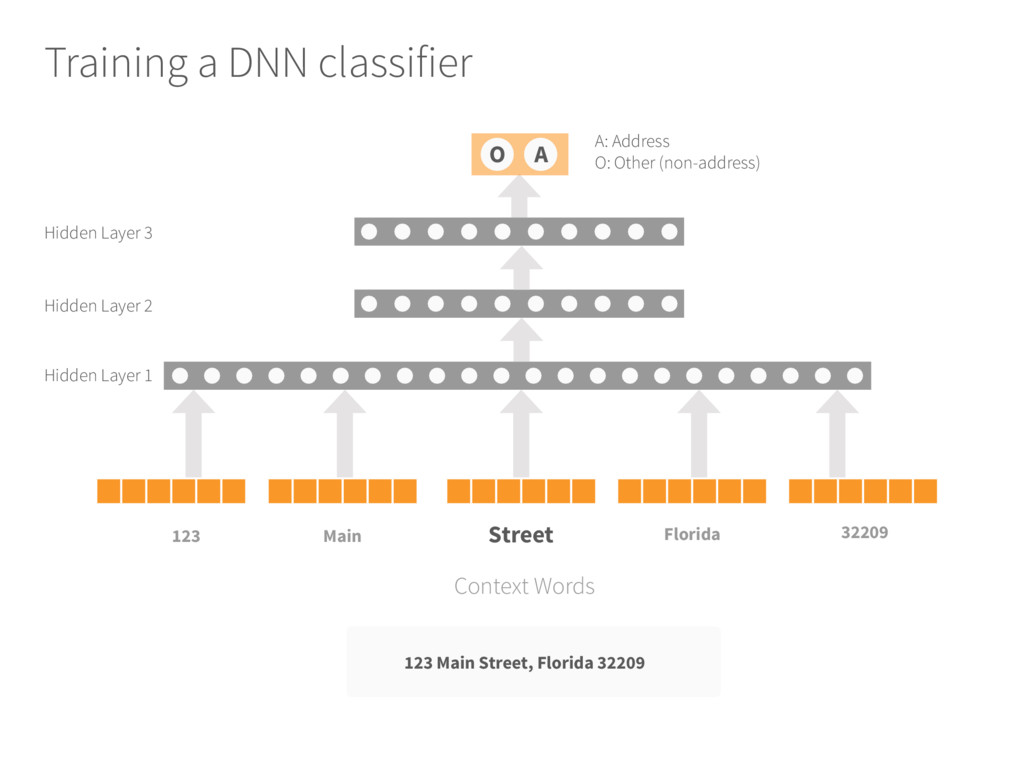
for each new web page do 3. The web page is pre-processed to remove the HTML tags, then tokenized 4. Each token (word) is replaced by its embedding vector 5. Create the DNN input by concatenating the embedding of the context 6. The DNN labels the central word of the context as A (ADDRESS) or O (OTHER) 7.Extract the sequence of tokens with A label 8.if the total number of tokens is within range then 9. Output the token block as extracted address 10.End if 11.End For Input: Trained DNN model and unlabeled web page Output: Extracted address
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}