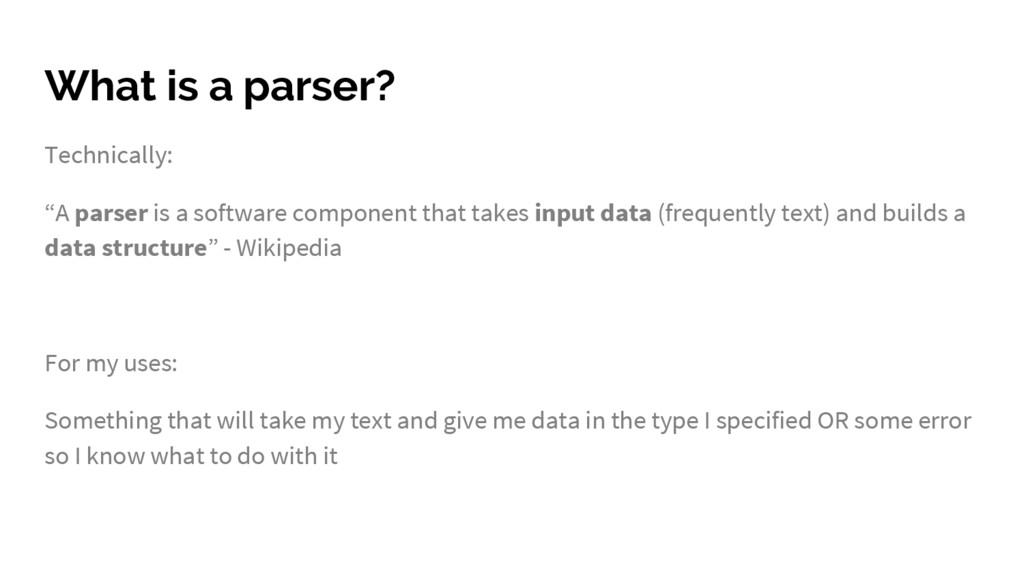
component that takes input data (frequently text) and builds a data structure” - Wikipedia For my uses: Something that will take my text and give me data in the type I specified OR some error so I know what to do with it
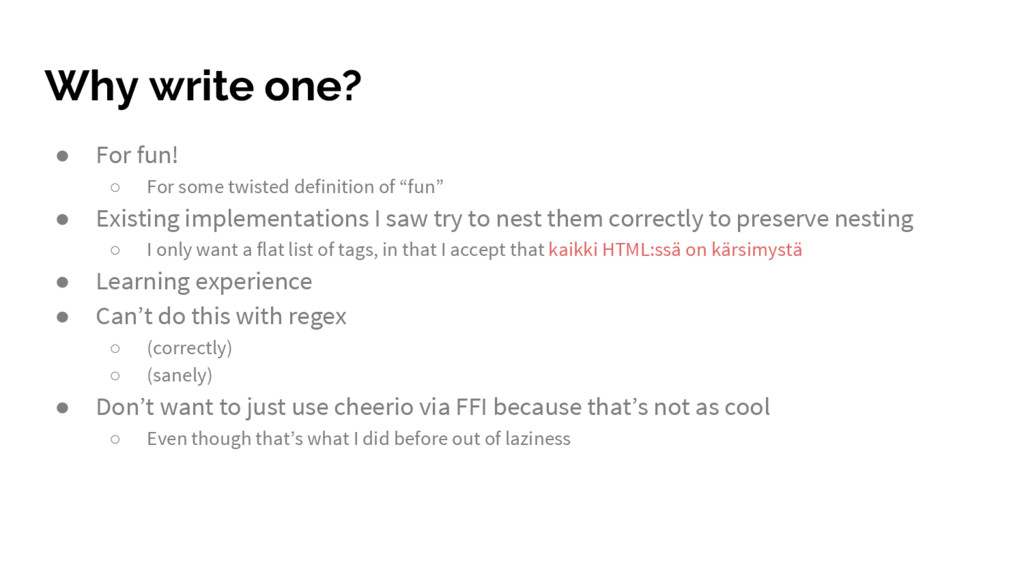
definition of “fun” • Existing implementations I saw try to nest them correctly to preserve nesting ◦ I only want a flat list of tags, in that I accept that kaikki HTML:ssä on kärsimystä • Learning experience • Can’t do this with regex ◦ (correctly) ◦ (sanely) • Don’t want to just use cheerio via FFI because that’s not as cool ◦ Even though that’s what I did before out of laziness
TagOpen TagName Attributes | TagSingle TagName Attributes | TagClose TagName | TNode String I really have no idea what the actual HTML spec names for these are newtype TagName = TagName String type Attributes = List Attribute data Attribute = Attribute Name Value newtype Name = Name String newtype Value = Value String
function or definition with no free variables.”) ◦ char :: Char -> Parser Char ◦ string :: String -> Parser String ◦ Etc. • A runner ◦ runParser :: forall a. Parser a -> String -> Either ParseError a • (Some other utilities that are useful but I don’t use for this project)
both whitespace and comments (I don’t need them!) • Recursively skip “spaces” (my grouping of those two) ◦ Purescript being strictly evaluated, this requires a trick called “fix” ▪ fix :: forall l. Lazy l => (l -> l) -> l ▪ Our Parser type comes with an instance for Lazy, so we’re good to go!
skip a comment and start over skipping spaces. If this fails, try the following: 2) Try to skip one or many whitespace characters and start over skipping spaces. If this fails, try the following: 3) There is no more to do. Return Unit. skipSpace :: Parser Unit skipSpace = fix \_ -> (comment *> skipSpace) <|> (many1 ws *> skipSpace) <|> pure unit where ws = satisfy \c -> c == '\n' || c == '\r' || c == '\t' || c == ' '
• It has basically any character • It ends with “-->” • I don’t care about the contents, I just need it parsed away comment :: Parser Unit comment = do string "<!--" manyTill anyChar $ string "-->" pure unit
block that I actually care about. lexeme :: forall p. Parser p -> Parser p lexeme p = p <* skipSpace I.e. for a given parser, I want to use it to parse my target and then snip off all of the trailing “spaces” Name: tag and attribute names can have just about any character in my lenient HTML, except for particles. validNameString :: Parser String validNameString = flattenChars <$> many1 (noneOf ['=', ' ', '<', '>', '/', '"']) flattenChars :: List Char -> String flattenChars = trim <<< fromCharArray <<< fromFoldable
is a flat List of Tags • Tags are separated by arbitrary amounts of space (and text nodes) • My HTML input might have leading spaces, so I should clear those • A Tag is going to be either an actual tag or a text node tags :: Parser (List Tag) tags = do skipSpace many tag tag :: Parser Tag tag = lexeme do tagOpenOrSingleOrClose <|> tnode
Doesn’t have an angle bracket in the front ◦ All text nodes that want to display an angle bracket require escaping? • Just about any text up until we see the opening of a tag can be considered part of the text node (i.e. an actual tag or comment block) tnode :: Parser Tag tnode = lexeme do TNode <<< flattenChars <$> many1 (satisfy ((/=) '<'))
• It could be a closing tag ◦ Close the tag by parsing out a slash ◦ Grab the name string ◦ Finalize by parsing out the closing angle bracket ◦ Return the closing tag • Otherwise, it’s an open tag or a single (“self-closing”??) tagOpenOrSingleOrClose :: Parser Tag tagOpenOrSingleOrClose = lexeme $ char '<' *> (closeTag <|> tagOpenOrSingle) closeTag :: Parser Tag closeTag = lexeme do char '/' name <- validNameString char '>' pure $ TagClose (TagName name)
name • Has zero to many attributes ◦ First need to answer what an attribute is • What is an “attribute”? ◦ Has a name ◦ Might have an equal sign if it has value ▪ We need to parse out =” ▪ Grab everything inside until the next quote ◦ Otherwise we can pretend it is attrib=”” ▪ As far as I know attribute :: Parser Attribute attribute = lexeme do name <- validNameString value <- (flattenChars <$> getValue) <|> pure "" pure $ Attribute (Name name) (Value value) where getValue = string "=\"" *> manyTill (noneOf ['"']) (char '"')
we can do this! • Get our name • Get our zero-to-many attributes • Then we need to figure out ◦ If it ends with angle bracket right away, then it’s a normal open tag ◦ If it ends with slash-angle bracket, then we know it’s a single/”self-closing” tag ◦ Otherwise I think it’s fair to fail the parser here and complain about broken HTML. tagOpenOrSingle :: Parser Tag tagOpenOrSingle = lexeme do tagName <- lexeme $ TagName <$> validNameString attrs <- many attribute <|> pure mempty let spec' = spec tagName attrs closeTagOpen spec' <|> closeTagSingle spec' <|> fail "no closure in sight for tag opening" where spec tagName attrs constructor = constructor tagName attrs closeTagOpen f = char '>' *> pure (f TagOpen) closeTagSingle f = string "/>" *> pure (f TagSingle)
we’re interested in, so we’re done writing our parser. We can add a few convenience functions just for our sake: parse :: forall a. Parser a -> String -> Either ParseError a parse p s = runParser p s parseTags :: String -> Either ParseError (List Tag) parseTags s = parse tags s
Comes with ◦ runTest (for the whole thing) ◦ Suite (identify your suite) ◦ Test (define test cases) ◦ assert/fail • Need utilities for ◦ Testing my parser, taking a parser and input string ◦ Testing for tags to be created from snippet of HTML • Then need to throw everything at it testParser p s expected = case parse p s of Right x -> do assert "parsing worked:" $ x == expected Left e -> failure $ "parsing failed: " <> show e expectTags str exp = case parseTags str of Right x -> do assert "this should work" $ x == exp Left e -> do failure (show e)
any format) parser in Purescript is fun • You don’t necessarily have to be an expert on FP crap to get started ◦ Functor, Applicative, Alternative, Monad, Monoid, Foldable, etc. were used here fairly transparently ◦ Why worry about abstract details when you know the concrete instantiation works? • Being able to model the right data structure in the beginning saves a whole lot of work ◦ E.g. what if our Tag type was just { type :: String, content :: { name :: String, attribute :: List String } }? This would allow us to display too many impossible states and be frustrating ▪ It’d be hard to work with ▪ And the compiler wouldn’t know hardly anything either • Repo here: https://github.com/justinwoo/purescript-lenient-html-parser Conclusions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}