Andrew Rula, Dave Bernick, Jonathan Lawson, Kristian Cibulskis, Namrata Gupta, Rob Title, Eric Banks, RIch Silva University of Chicago Robert Grossman, Abby George, Garrett Rupp, Zac Flamig University of California Santa Cruz Benedict Paten, Denis Yuen, Brian O’Connor, Charles Overbeck, Kevin Osborn, Louise Cabansay, Natalie Perez, Stefan Kuhn, Walt Shands Vanderbilt Robert Carroll, Lakhan Swamy, Kristin Wuichet Washington University Ira Hall, Adam Coffman, Allison Reieir, Haley Abel, Jason Walker Johns Hopkins James Taylor, Jeff Leek, Kasper Hansen, Enis Afgan, Alexandru Mahmoud, Sergey Golitsynskiy, Jenn Vessio, John Muschelli, Mo Heydarian Penn State University Anton Nekrutenko, John Chilton, Nate Coraor, Marten Cech Oregon Health & Sciences University Jeremy Goecks, Kyle Ellrott, Brian Walsh, Luke Sargent, Vahid Jalili Roswell Park Cancer Institute Martin Morgan, Nitesh Turaga Harvard Vincent Carey, BJ Stubbs, Shweta Gopaulakrishnan City University of New York Levi Waldron, Sehyun Oh, Ludwig Geistlinger Acknowledgements: AnVIL Team
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
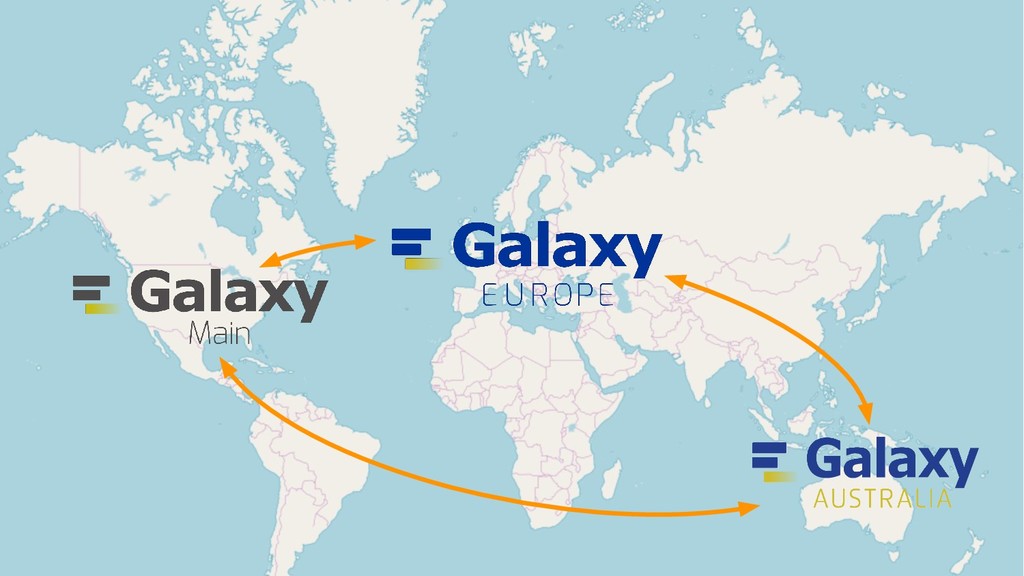{kind=link}
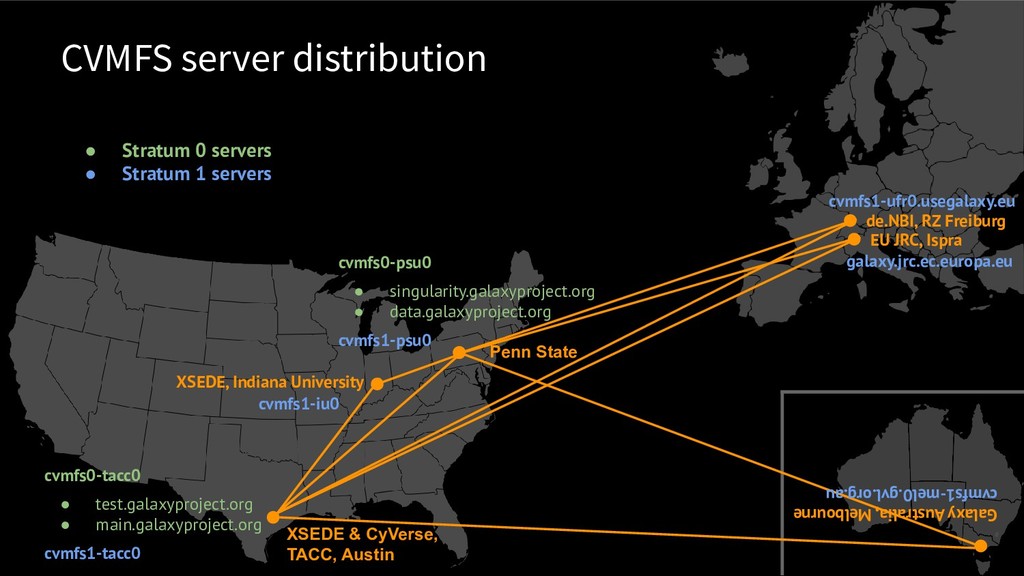{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
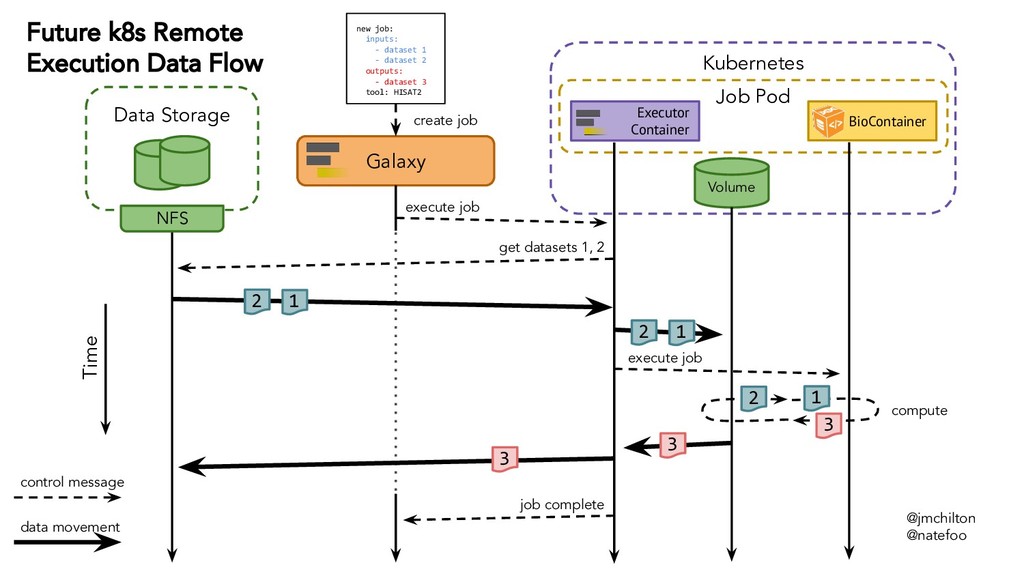{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}