Martin Čech, John Chilton, Dave Clements, Nate Coraor, Jeremy Goecks, Sergey Golitsynskiy, Qiang Gu, Björn Grüning, Sam Guerler, Mo Heydarian, Jennifer Hillman-Jackson, Vahid Jalili, Delphine Lariviere, Alexandru Mahmoud, Anton Nekrutenko, Helena Rasche, Luke Sargent, Nicola Soranzo, Marius van den Beek Taylor Lab at JHU: Boris Brenerman, Min Hyung Cho, Peter DeFord, Max Echterling, Nathan Roach, Michael E. G. Sauria, German Uritskiy AnVIL: Anthony Philippakis, Vincent Carey, Josh Denny, Kyle Ellrott, Jeremy Goecks, Robert Grossman, Ira Hall, Jennifer Hall, Kasper Hansen, Jeff Leek, Daniel MacArthur, Martin Morgan, Anton Nekrutenko, Benedict Paten, Mike Schatz, Levi Waldron, and many others! Funding: NHGRI U41 HG006620 (Galaxy), NHGRI U24 HG010263 (AnVIL), NCI U24 CA231877 (Galaxy Federation), NSF DBI 0543285, DBI 0850103 (Galaxy on US cyberinfrastructure) +Collaborators: Dave Hancock and the Jetstream group, Ross Hardison and the VISION group, Victor Corces, Karen Reddy, Johnston, Kim, Hilser, and DiRuggiero labs (JHU Biology), Battle, Goff, Langmead, Leek, Schatz, Timp labs (JHU Genomics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
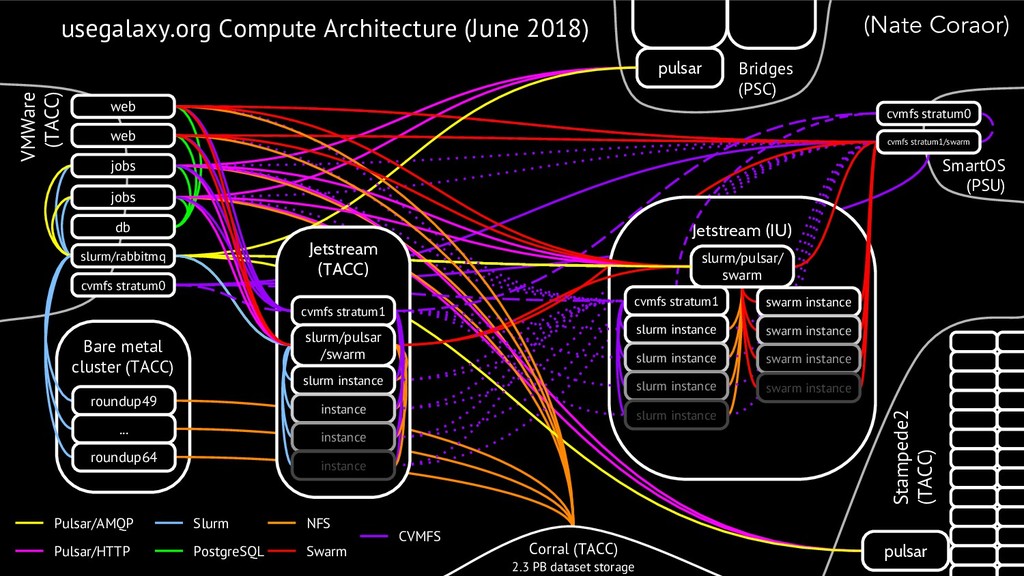{kind=link}
{kind=link}
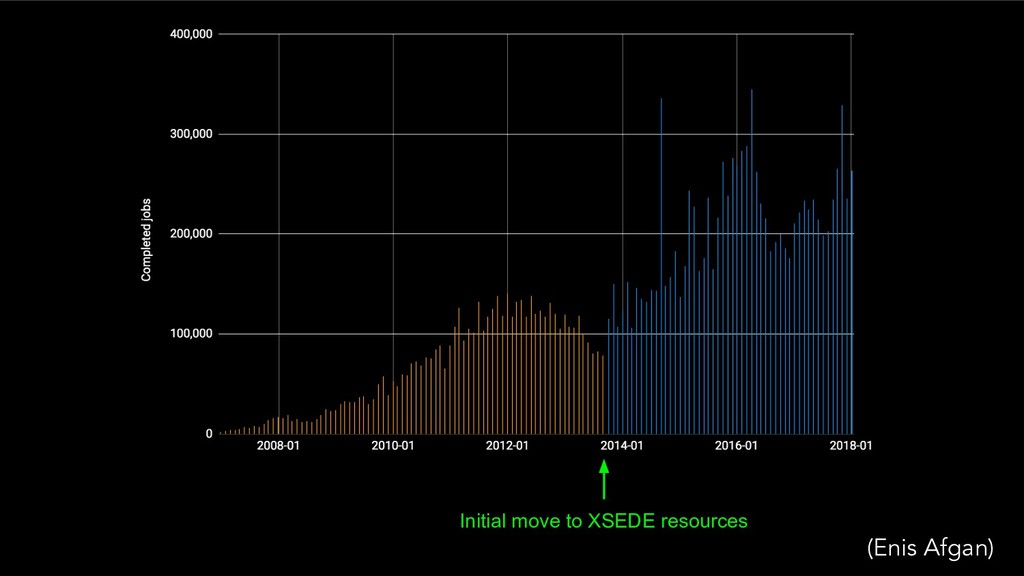{kind=link}
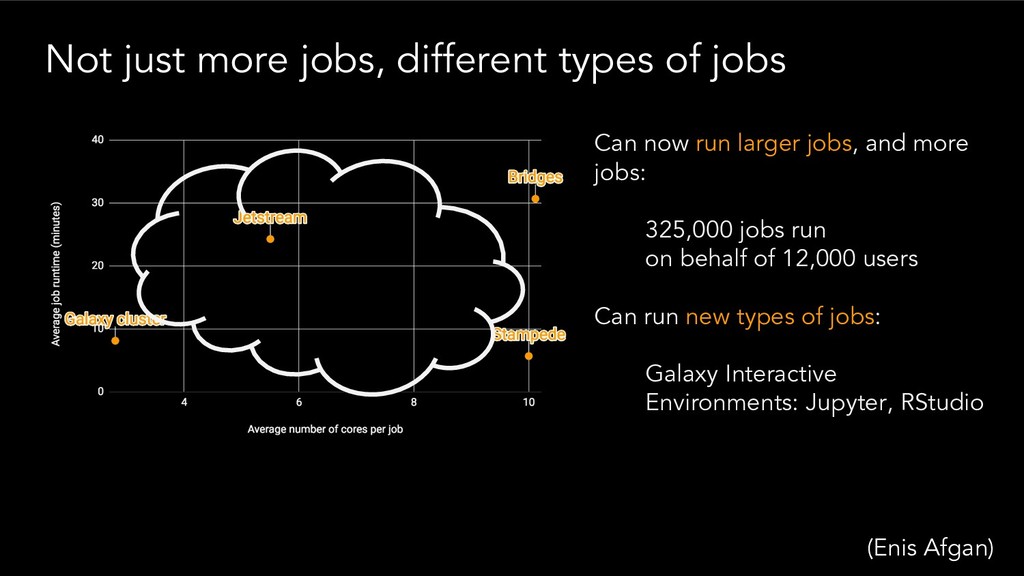{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
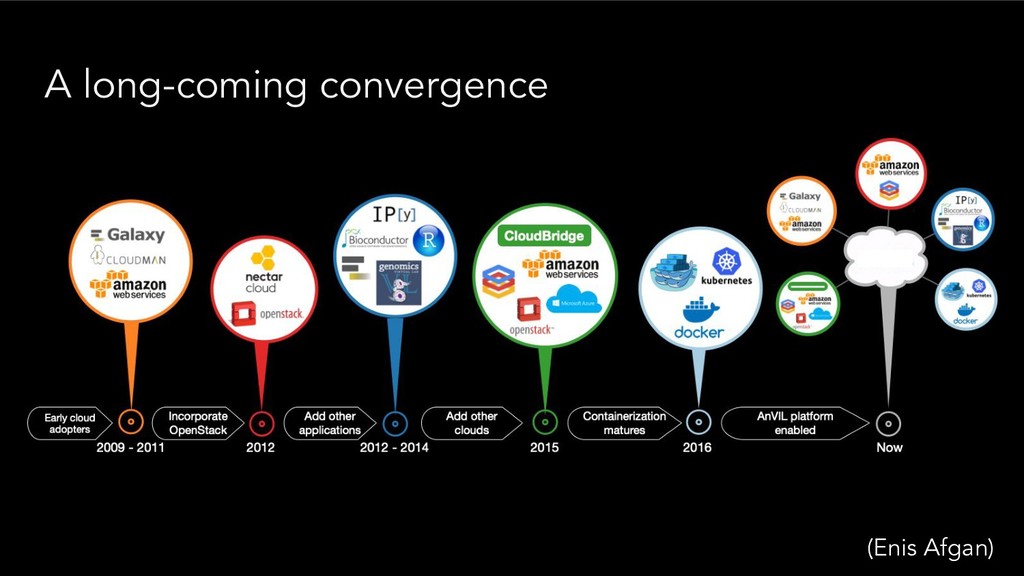{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}