say “the era of searching is ending and we’re entering in the era of discovery”. Difference between search and discovery is that when you’re searching you know what’re you looking for but during discovery, you never knew such wonderful thing existed and you stumble upon it with the help of algorithms and formulae perfectly customised to your interests, likes and dislikes. b. Chris Anderson said in “The Long Tail”: We’re leaving the age of information and entering the age of recommendations.
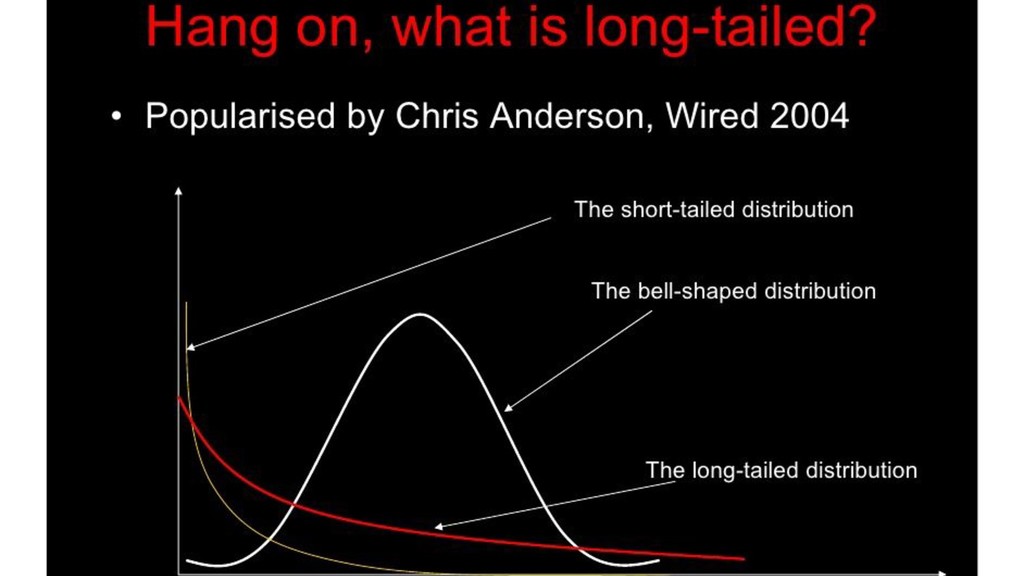
worlds has been called the long tail phenomenon . The vertical axis represents popularity (the number of times an item is chosen). The items are ordered on the horizontal axis according to their popularity. Physical institutions provide only the most popular items to the left of the vertical line, while the corresponding on-line institutions provide the entire range of items: the tail as well as the popular items.
best-seller “Into Thin Air” and “Touching the Void”- An extreme example of how the long tail, together with a well designed recommendation system can influence events is the story told by Chris Anderson about a book called Touching the Void. This mountain-climbing book was not a big seller in its day, but many years after it was published, another book on the same topic, called Into Thin Air was published. Amazon’s recommendation system noticed a few people who bought both books, and started recommending Touching the Void to people who bought, or were considering, Into Thin Air. Had there been no on-line bookseller, Touching the Void might never have been seen by potential buyers, but in the online world, Touching the Void eventually became very popular in its own right, in fact, more so than Into Thin Air
is a black box that analyses some set of users and shoes the items which a single user may like Examples: 1. Facebook- People You May Know. 2. Netflix: “Other Movies You Might Enjoy” 3. LinkedIn: “Jobs You May Interested In” 4. Amazon: “Customers who bought also bought this” 2. Non-Personalised : A non-personalised recommendation engine decides the popularity of a product by the number of likes or clicks, the main drawback is that it is same to all the users, irrespective of their interests. Example: Twitter’s “trending topic” comes under one of them.
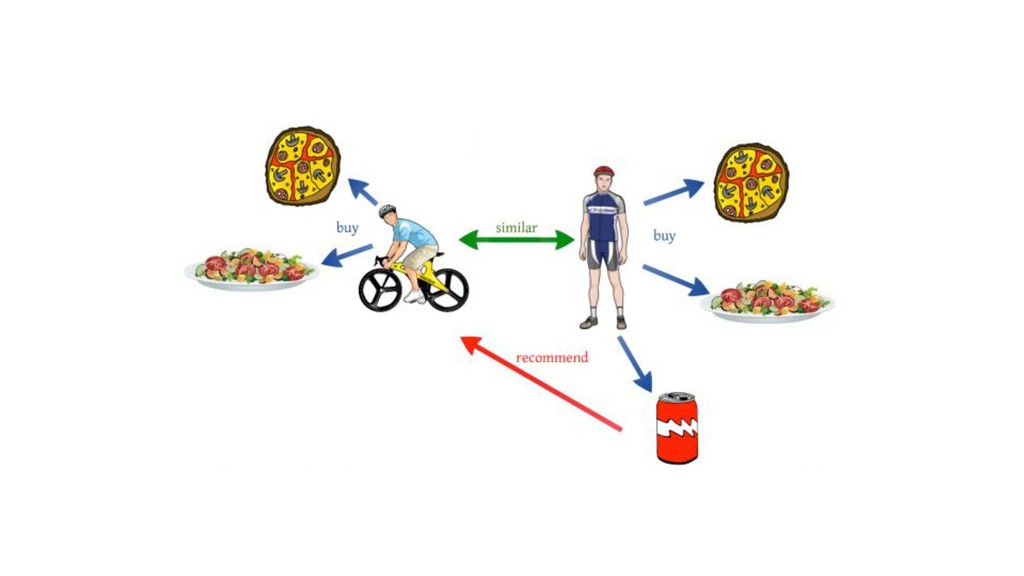
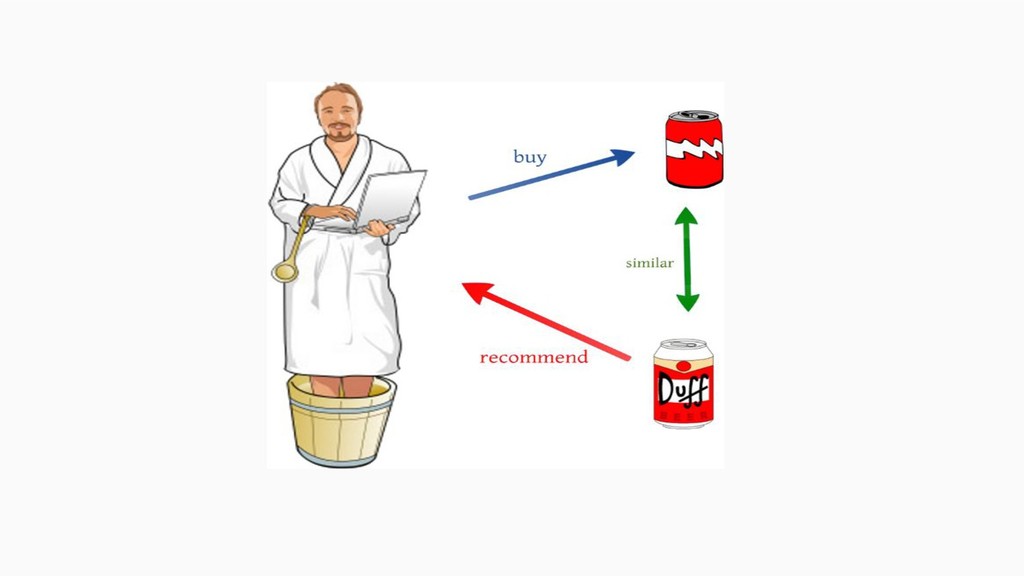
items recommended. For instance, if a Netflix user has watched many cowboy movies, then recommend a movie classified in the database as having the “cowboy” genre. • Collaborative filtering systems recommend items based on similarity measures between users and/or items. The items recommended to a user are those preferred by similar users. However, these technologies by themselves are not sufficient, and there are some new algorithms that have proven effective for recommendation systems.
what user might like by collecting and analyzing large amount of information on user's’ behavior, preferences and activities. 2. The underlying principle behind CF is that if A and B have fondness for a product X, then it is more likely that A would like the product Y liked by B than by any other random person’s view on the product Y. 3. Applications of CF typically involves large data sets. So far it is used in mineral exploration, financial data etc. 4. It is of 3 types: (a) Memory-based (b) Model-based ( c) Hybrid a. Memory: Uses user rating to compute similarity between users. b. Model: Models are developed using various data mining, ML algos to find the patterns based on training data. c. Hybrid: Combination of memory and model based CF for better results, although it is more expensive but used extensively like in Google news Recommender System.
between content of the items and the user profile. It becomes more accurate as the user gives away more information. 2. Also known as cognitive filtering. 3. The following issues should be taken care of while making such system: a. Terms to the items as well as the user can be assigned automatically or manually but if they’re being assigned automatically then there must be a method that should be able to extract those terms from the items. b. The terms have to be represented in such a way that the items and user can both be compared in a meaningful way. c. A learning algorithm that is able to learn the user profile based on clicked items and can make recommendations on the top of that. The learning algorithm techniques can be Relevance feedback, genetic algorithms, neural networks and Bayesian classifier techniques etc.
classes of entities, which we shall refer to as users and items. Users have preferences for certain items, and these preferences must be teased out of the data. The data itself is represented as a utility matrix, giving for each user-item pair, a value that represents what is known about the degree of preference of that user for that item. Values come from an ordered set, e.g., integers 1–5 representing the number of stars that the user gave as a rating for that item. We assume that the matrix is sparse, meaning that most entries are “unknown.” An unknown rating implies that we have no explicit information about the user’s preference for the item.
rate items. Movie ratings are generally obtained this way, and some online stores try to obtain ratings from their purchasers. Sites providing content, such as some news sites or YouTube also ask users to rate items. This approach is limited in its effectiveness, since generally users are unwilling to provide responses, and the information from those who do may be biased by the very fact that it comes from people willing to provide ratings. 2. We can make inferences from users’ behavior. Most obviously, if a user buys a product at Amazon, watches a movie on YouTube, or reads a news article, then the user can be said to “like” this item. Note that this sort of rating system really has only one value: 1 means that the user likes the item. Often, we find a utility matrix with this kind of data shown with 0’s rather than blanks where the user has not purchased or viewed the item. However, in this case 0 is not a lower rating than 1; it is no rating at all. More generally, one can infer interest from behavior other than purchasing. For example, if an Amazon customer views information about an item, we can infer that they are interested in the item, even if they don’t buy it.
that are similar because they belong to the same genre, than it is to detect that two users are similar because they prefer one genre in common, while each also likes some genres that the other doesn’t care for.
NetFlix sponsored a competition, offering a grand prize of $1M to the team that could improve their recommendations with 10% or more accuracy. The dataset given consists of over 100 million movie ratings. 2. The winning algorithm used an ensemble method of 107 different algorithmic approaches, blended into a single prediction. 3. The winning algorithm was never used by NetFlix saying “did not seem to justify the engineering effort needed to bring them into a production environment” in a blog post. Although they used two of algorithms used in winning entry to improve the accuracy by 8.43% of their recommendation engines. 4. This contest created a lot of research regarding the recommendation engines and revolutionised the predictive modelling domain due to its enormous cash prize. 5. This challenge proved that the right solution is never one algorithm or even hundred but the combination of a lot of algorithms in machine learning.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}