2022. Kakao Corp. All rights reserved. Redistribution or public display is not permitted without written permission from Kakao. 초거대모델 학습을 위한 이미지-텍스트 데이터셋 변민우 dylan.m 카카오브레인 if(kakao)2022
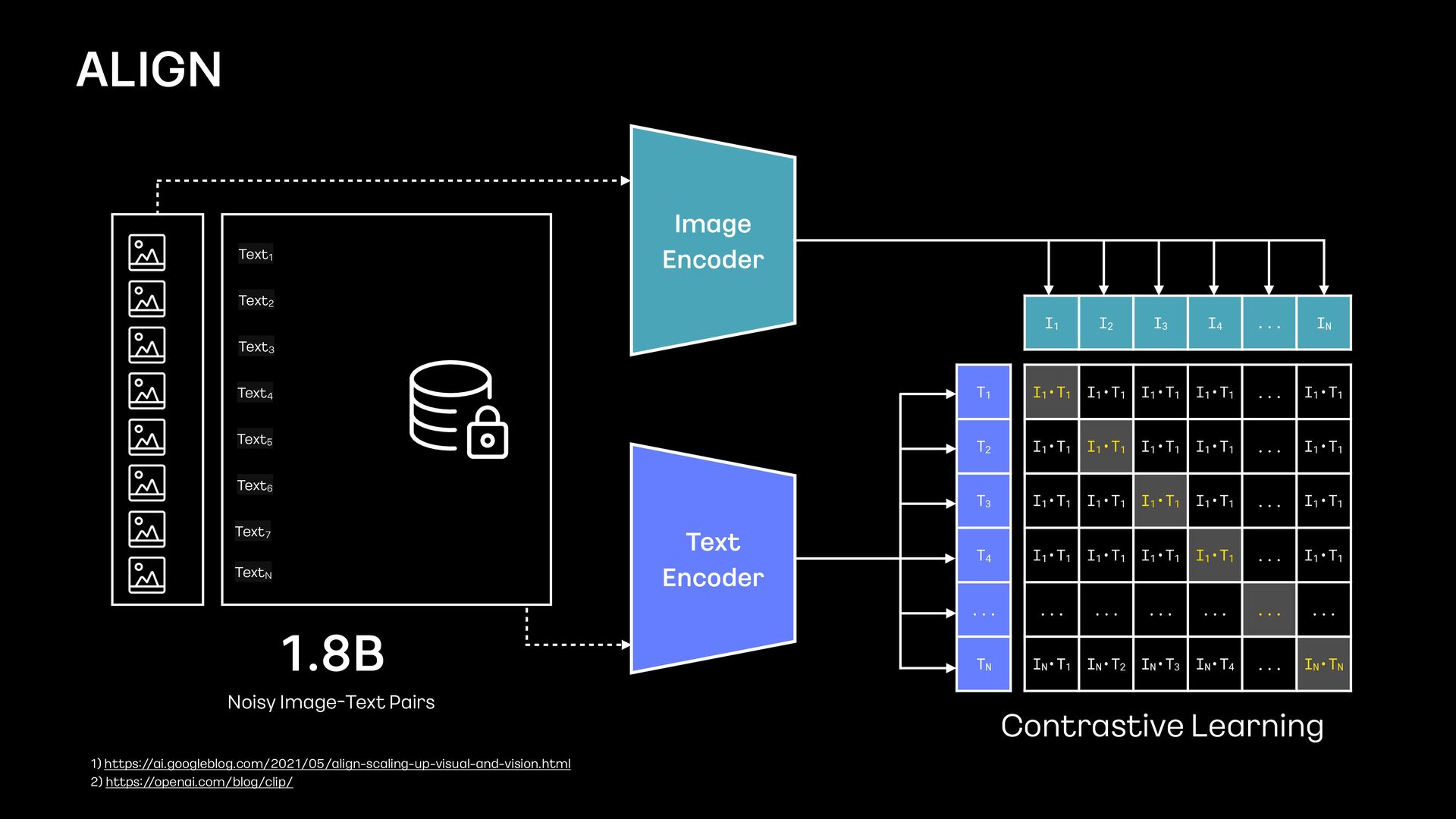
scaling - up - visual - and - vision.html 2) https:/ /www.microsoft.com/en - us/research/publication/ fl orence - a - new - foundation - model - for - computer - vision/ 1.8B Image - Text Pairs 900M Image - Text Pairs
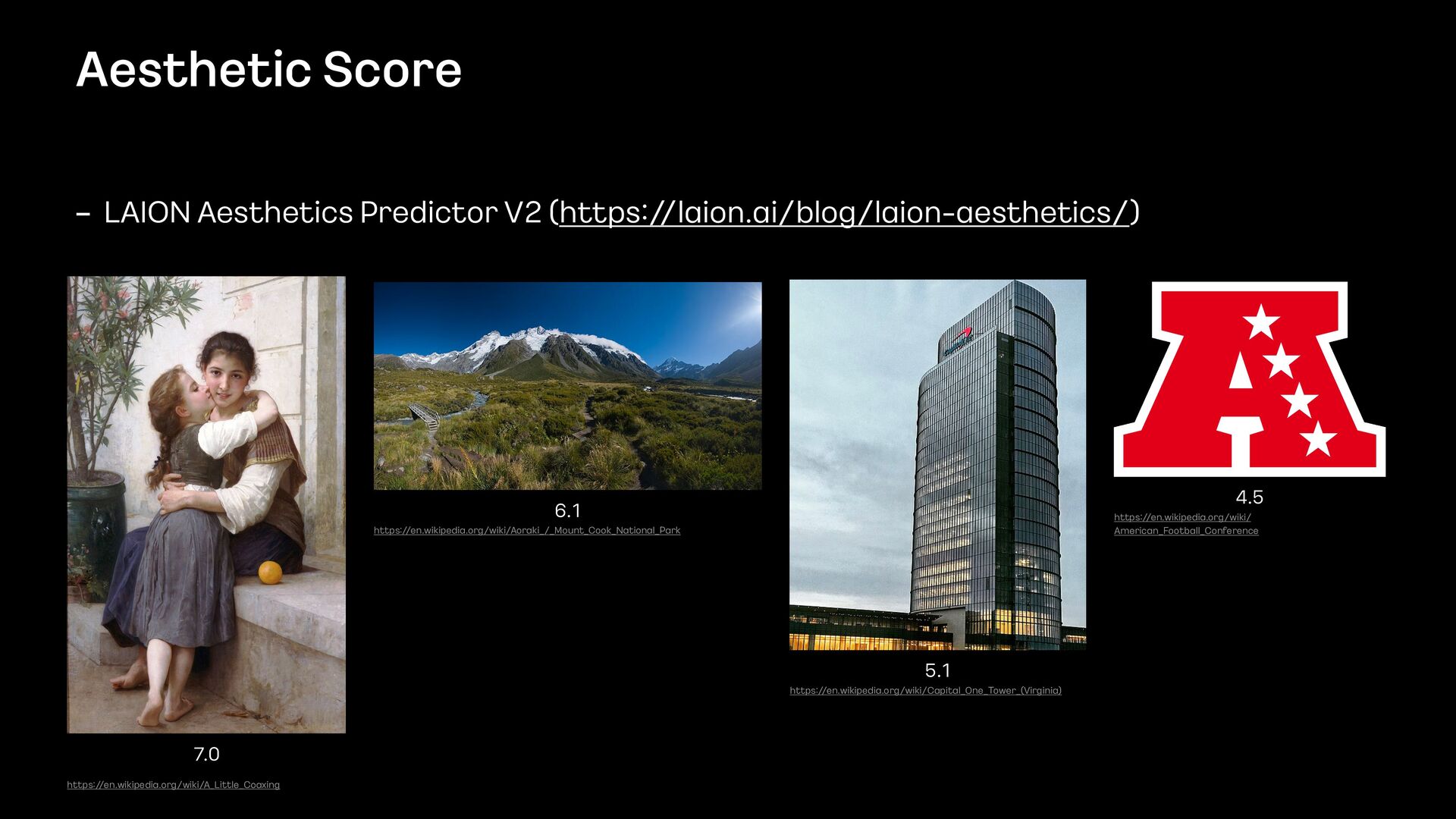
Travel to beautiful history https:/ /en.wikipedia.org/wiki/Gyeongbokgung Picasso in front of his painting https:/ /en.wikipedia.org/wiki/Pablo_Picasso A panoramic view of Mauritius Island https:/ /en.wikipedia.org/wiki/Mauritius Van Gogh's Starry Night Over the Rhône, 1888, oil on canvas https:/ /en.wikipedia.org/wiki/The_Starry_Night Various fruits arranged at a stall in the Municipal Market of São Paulo https:/ /en.wikipedia.org/wiki/Fruit
스크린리더를 통해 정보를 인식하도록 할 수 있습니다. 1) https:/ /en.m.wikipedia.org/wiki/Wikipedia:Manual_of_Style/Accessibility/Alternative_text_for_images <img src="//upload.wikimedia.org/wikipedia/commons/ thumb/0/0a/Jacques-Louis_David_017.jpg/170px-Jacques- Louis_David_017.jpg" alt="Painting of Napoleon Bonaparte in His Study at the Tuileries" decoding="async" width="170" height="280" class="thumbimage" data-file-width="1576" data-file-height="2596">
web crawl data that can be accessed and analyzed by anyone.” — Common Crawl1) 2,300억 웹 페이지 6.8 PiB 데이터 크기 3) 10년 총 수집기간 2) 1) Common Crawl, https:/ /commoncrawl.org/ 2) 2013년 ~ 2022년 8월 기준 3) 페비바이트(Pebibyte, PiB) — 1 PiB = 250 bytes = 1,125,899,906,842,624 bytes = 1024 TiB(테비바이트)
내에서 중복된 (pHash,Text) 샘플을 제거 - 해시값이 동일한 이미지에 대해 다른 텍스트 쌍이 존재할 수 있음. - 테스트 대상 외부 공개 데이터셋과 중복된 이미지 제거 - ImageNet-1K/21K - Flickr-30K - MS - COCO - CC-3M / CC-12M - 10번 이상 등장하는 텍스트가 포함된 샘플 모두 제거 - “Image of”, “photo of”, “jpeg”, … Deduplication 1) https:/ /www.hackerfactor.com/blog/index.php?/archives/432 - Looks - Like - It.html
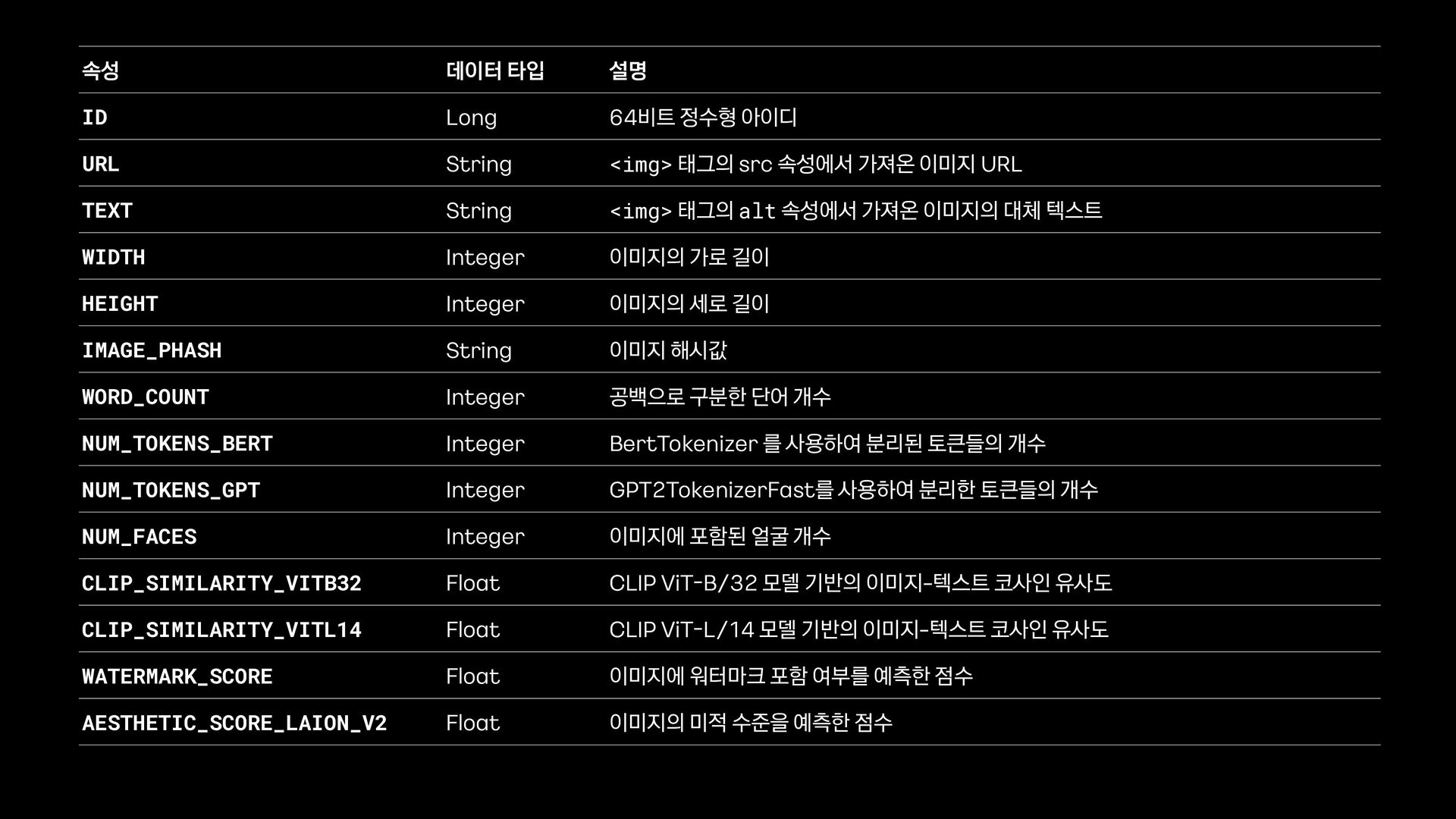
String <img> 태그의 src 속성에서 가져온 이미지 URL TEXT String <img> 태그의 alt 속성에서 가져온 이미지의 대체 텍스트 WIDTH Integer 이미지의 가로 길이 HEIGHT Integer 이미지의 세로 길이 IMAGE_PHASH String 이미지 해시값 WORD_COUNT Integer 공백으로 구분한 단어 개수 NUM_TOKENS_BERT Integer BertTokenizer 를 사용하여 분리된 토큰들의 개수 NUM_TOKENS_GPT Integer GPT2TokenizerFast를 사용하여 분리한 토큰들의 개수 NUM_FACES Integer 이미지에 포함된 얼굴 개수 CLIP_SIMILARITY_VITB32 Float CLIP ViT - B/32 모델 기반의 이미지-텍스트 코사인 유사도 CLIP_SIMILARITY_VITL14 Float CLIP ViT - L/14 모델 기반의 이미지-텍스트 코사인 유사도 WATERMARK_SCORE Float 이미지에 워터마크 포함 여부를 예측한 점수 AESTHETIC_SCORE_LAION_V2 Float 이미지의 미적 수준을 예측한 점수
String <img> 태그의 src 속성에서 가져온 이미지 URL TEXT String <img> 태그의 alt 속성에서 가져온 이미지의 대체 텍스트 WIDTH Integer 이미지의 가로 길이 HEIGHT Integer 이미지의 세로 길이 IMAGE_PHASH String 이미지 해시값 WORD_COUNT Integer 공백으로 구분한 단어 개수 NUM_TOKENS_BERT Integer BertTokenizer 를 사용하여 분리된 토큰들의 개수 NUM_TOKENS_GPT Integer GPT2TokenizerFast를 사용하여 분리한 토큰들의 개수 NUM_FACES Integer 이미지에 포함된 얼굴 개수 CLIP_SIMILARITY_VITB32 Float CLIP ViT - B/32 모델 기반의 이미지-텍스트 코사인 유사도 CLIP_SIMILARITY_VITL14 Float CLIP ViT - L/14 모델 기반의 이미지-텍스트 코사인 유사도 WATERMARK_SCORE Float 이미지에 워터마크 포함 여부를 예측한 점수 AESTHETIC_SCORE_LAION_V2 Float 이미지의 미적 수준을 예측한 점수
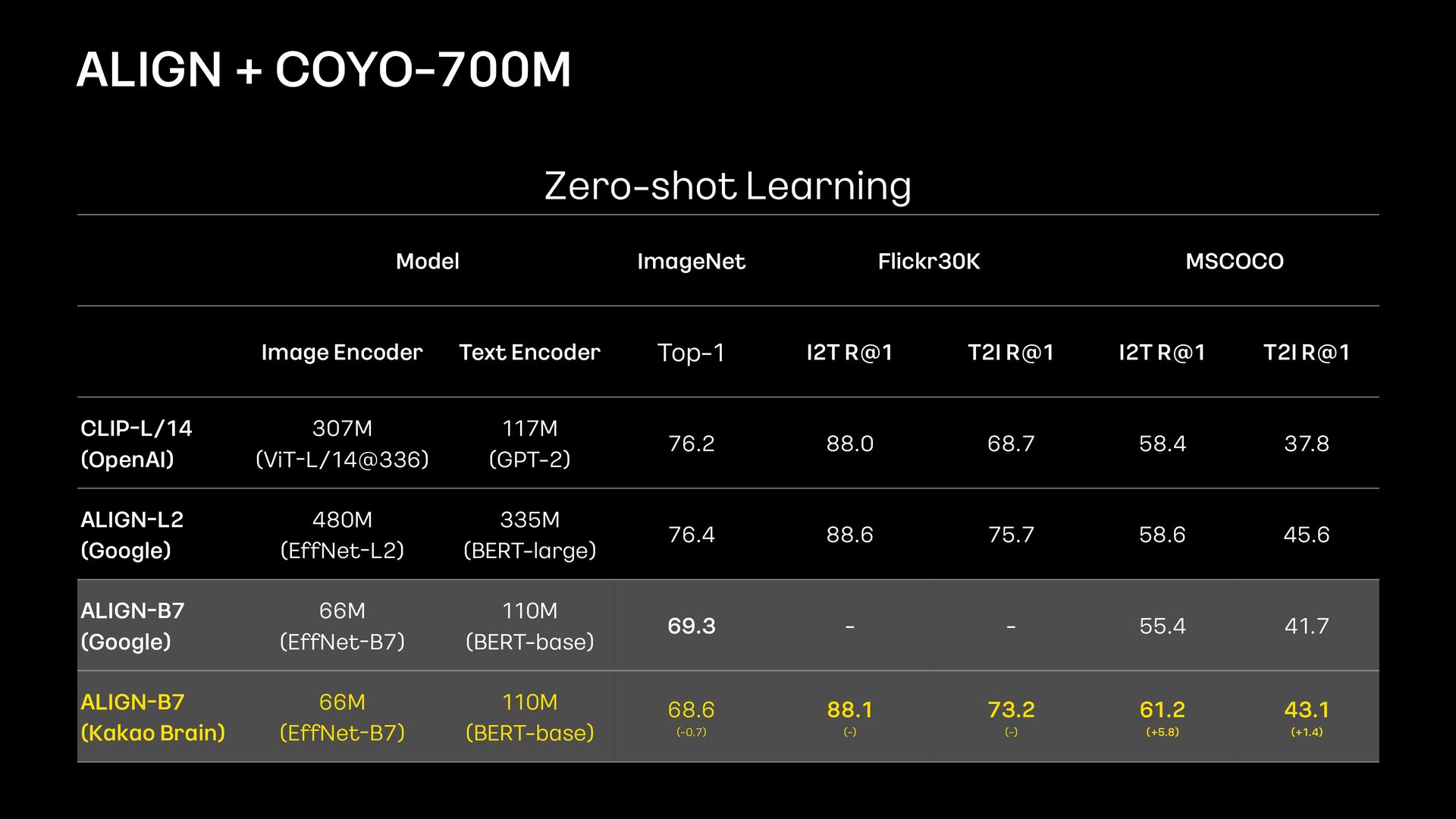
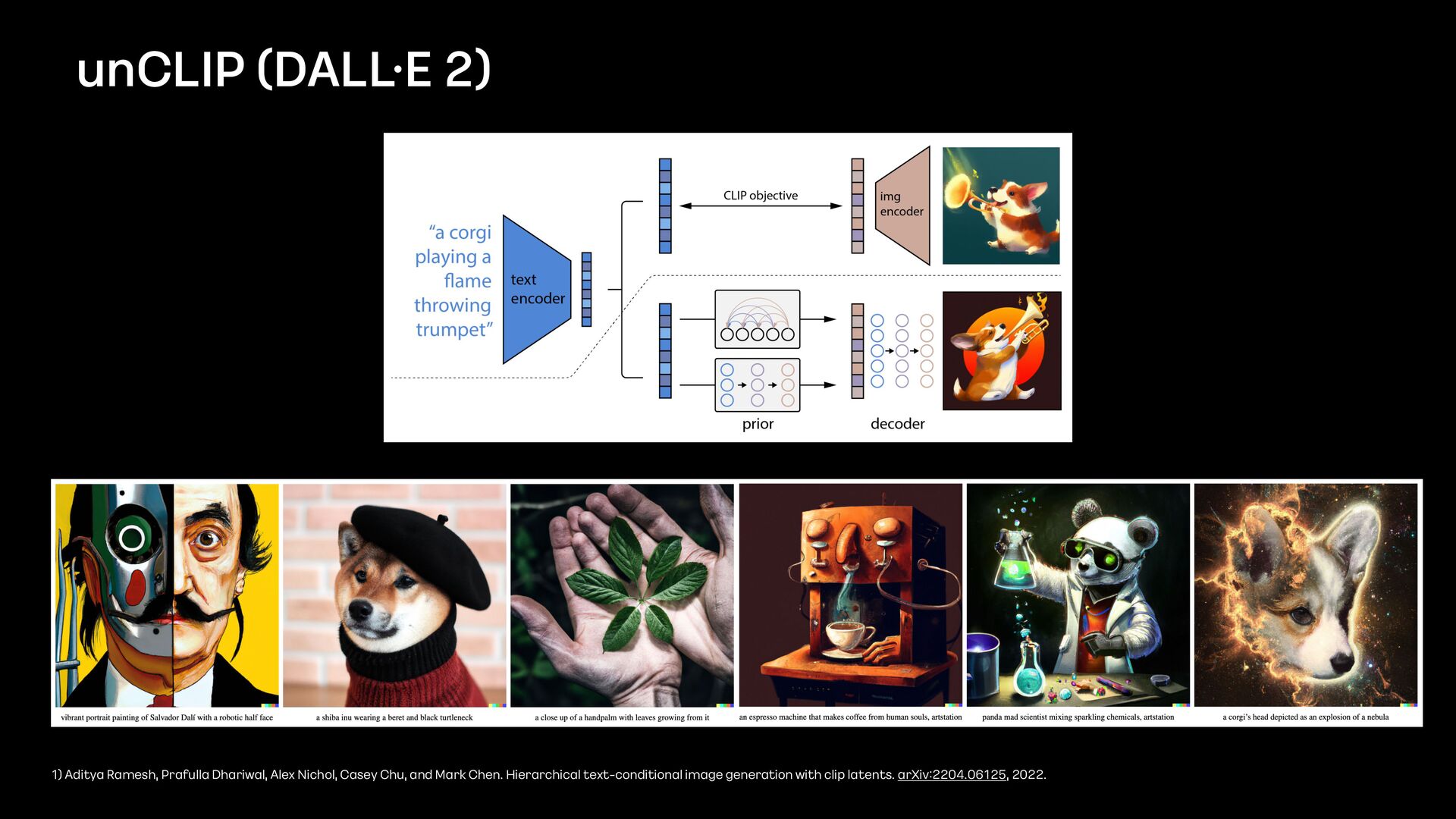
Image - Text Pairs 1) C. Jia, Y. Yang, Y. Xia, Y. - T. Chen, Z. Parekh, H. Pham, Q. V. Le, Y. Sung, Z. Li, and T. Duerig. Scaling up visual and vision - language representation learning with noisy text supervision. arXiv:2102.05918, 2021. 2) Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text - conditional image generation with clip latents. arXiv:2204.06125, 2022.
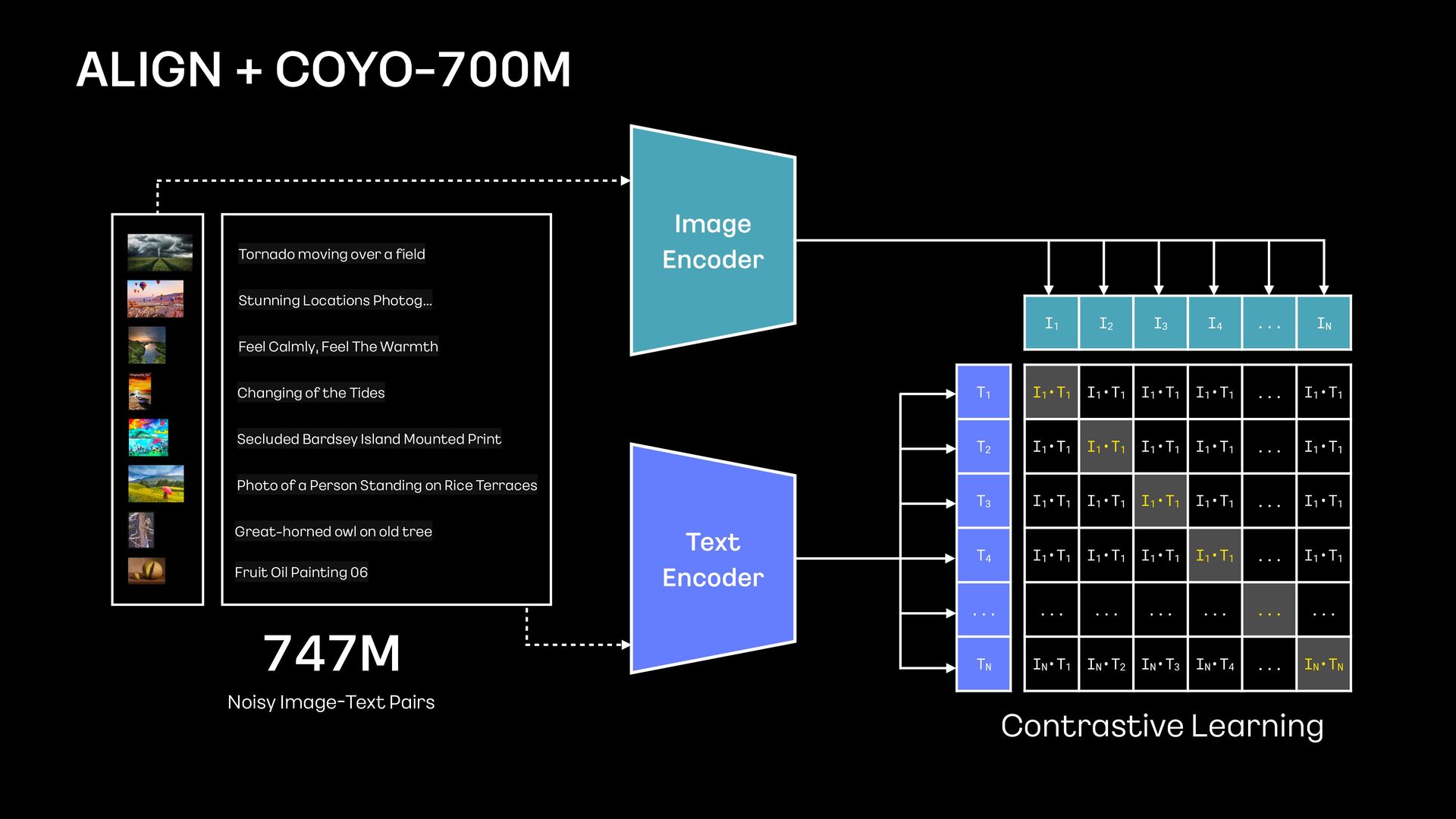
I1•T1 ... I1•T1 I1•T1 I1•T1 I1•T1 I1•T1 ... I1•T1 I1•T1 I1•T1 I1•T1 I1•T1 ... I1•T1 I1•T1 I1•T1 I1•T1 I1•T1 ... I1•T1 ... ... ... ... ... ... IN•T1 IN•T2 IN•T3 IN•T4 ... IN•TN I1 I2 I3 I4 ... IN T1 T2 T3 T4 ... TN 747M Noisy Image - Text Pairs Tornado moving over a fi eld Stunning Locations Photog… Feel Calmly, Feel The Warmth Changing of the Tides Secluded Bardsey Island Mounted Print Photo of a Person Standing on Rice Terraces Great - horned owl on old tree Fruit Oil Painting 06 Contrastive Learning
모델을 학습 - 더 자세한 내용은 다음 “카카오브레인의 텍스트 기반 이미지 생성 기술” 세션을 확인해주세요. unCLIP (DALL·E 2) Goryeo celadon in the shape of darth vader A pencil drawing of an astronaut riding a horse A high quality picture of a medieval knight with golden armor
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Watermark Score CNN RegNetY-16GF1) Watermark Score [0.0, 1.0] Watermark](https://files.speakerdeck.com/presentations/6db6a52d5c5649d4a138ba5dd5440f7a/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}