Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2025-09-22 Iceberg, Trinoでのログ基盤構築と パフォーマンス最適化
Search
kamijin_fanta
September 22, 2025
Technology
850
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2025-09-22 Iceberg, Trinoでのログ基盤構築と パフォーマンス最適化
kamijin_fanta
September 22, 2025
More Decks by kamijin_fanta
See All by kamijin_fanta
2026-06-11 Iceberg Trinoログ基盤の 設計ポイント - Design Points for an Iceberg + Trino Log Platform
kamijin_fanta
0
6
2025-04-14 Data & Analytics 井戸端会議 Multi tenant log platform with Iceberg
kamijin_fanta
1
760
IoT向けストレージにTiKVを採用したときの話 / 2024-10-25 TiUG Meetup 3 Using TiKV as IoT storage
kamijin_fanta
0
180
TrinoとIcebergで ログ基盤の構築 / 2023-10-05 Trino Presto Meetup
kamijin_fanta
1
2.5k
Unicodeと符号化形式
kamijin_fanta
0
1.2k
Reactとフォームとスキーマバリデーション / React forms with Schema Validation
kamijin_fanta
0
2.7k
2020/05/25 さくらのクラウド向けツールを使いこなす
kamijin_fanta
3
380
2019-01-24 業務でのOSSとの関わり方
kamijin_fanta
7
5k
関数型言語で始めるネットワークプログラミング
kamijin_fanta
0
1.2k
Other Decks in Technology
See All in Technology
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
160
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
ADDF - ループエンジニアリングするフレームワークを作ったら/I Didn't Set Out to Build Loop Engineering, But ADDF Did
fruitriin
0
110
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
2
3.4k
KiCAD講習会②
tutcreators
0
110
Claude Code 珍プレー好プレー
shinyasaita
0
310
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
370
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.5k
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
9
5.5k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.5k
デジタル・デザイン:次の50年を描く「進化する青写真」
y150saya
0
850
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
1
310
Featured
See All Featured
So, you think you're a good person
axbom
PRO
2
2.1k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Fireside Chat
paigeccino
42
4k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
The Invisible Side of Design
smashingmag
301
52k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Mind Mapping
helmedeiros
PRO
1
280
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Transcript
Iceberg, Trinoでのログ基盤構築と パフォーマンス最適化 2025-09-22 Tadahisa Kamijo Apache Iceberg Meetup Japan
#3
自己紹介 上條 忠久 Kamijo Tadahisa • さくらインターネット株式会社 クラウド事業本部 テクノロジー室 •
ソフトウェアエンジニアとしてサービス開発・運用 ◦ Go, TypeScript, Python, Kotlin ◦ Linux, Nomad, Ansible, Prometheus, React • 今日は大阪から参加
ログ基盤概要 • 現在社内各チームで監視基盤が個別に構築運用されている ◦ Prometheus, Elastic Stack, Loki, etc… ◦
社内向けログ基盤を提供することで、運用レベルの底上げ・運用コスト削減を目的 ◦ OSS運用なども行ったが、マルチテナント提供・ライセンス体系の問題 ◦ Trino+Icebergの構成で開発を開始 • 2023年からパブリックサービス化を目指して開発開始 ◦ アプリケーション・OS・ミドルウェアから出力される、システムログの保管場所として開発 ◦ Trino, Iceberg, 社内のオブジェクトストレージ等を組み合わせてスクラッチ開発 ◦ デジタル庁のガバメントクラウドの要件に含まれ、 2025年度末までの完成を目指す
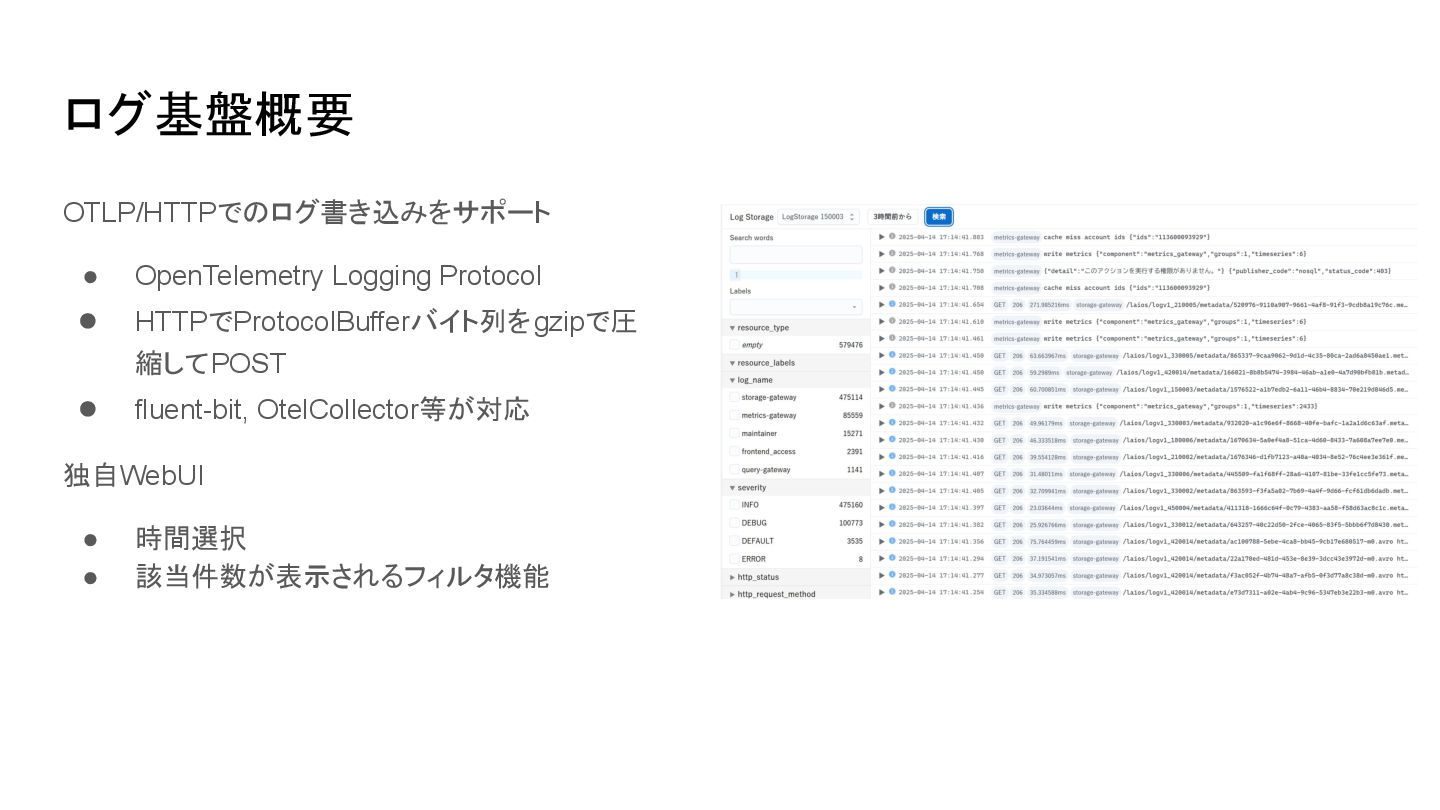
ログ基盤概要 OTLP/HTTPでのログ書き込みをサポート • OpenTelemetry Logging Protocol • HTTPでProtocolBufferバイト列をgzipで圧 縮してPOST •
fluent-bit, OtelCollector等が対応 独自WebUI • 時間選択 • 該当件数が表示されるフィルタ機能
Apache Iceberg overview • ストレージフォーマット ◦ ビッグデータ・データレイク構築 ◦ 仕様とデータを読み書きする低レイヤーライブラリ (Java,Python)の提供
◦ クエリエンジンTrino, Presto, Spark, Hive, Flink, Impala, 他から同じデータを参照 • Netflix→Apache Software Foundation • 機能 ◦ 高い信頼性: Seriallizable isolation, Snapshot, Atomic mutation ◦ 費用対効果の高いストレージ : Object Storage, Parquet ◦ パフォーマンス最適化 : Partitioning, Clustering, CoW/MoR切り替え ◦ スキーマ変更: Schema Evolution, Table, Partitioning
ログ基盤でのIceberg • テナント毎にテーブルを分ける ◦ データ削除の容易さ ◦ 性能分離・メンテナンスの容易さ ◦ 暗号化の要求 •
時間でパーティション・ソート ◦ 検索対象のファイルを減らす ◦ パーティション毎に課金メトリクスを取りたい CREATE TABLE log_tenant_1234 ( timestamp TIMESTAMP(6), insert_id VARCHAR, labels MAP(VARCHAR, VARCHAR ), level VARCHAR, -- DEBUG, INFO, WARN, ERROR message VARCHAR ) WITH ( partitioning = ARRAY[ 'day(timestamp)' ], sorted_by = ARRAY[ 'timestamp' ] ); (実際は大量のフィールドが定義されています )
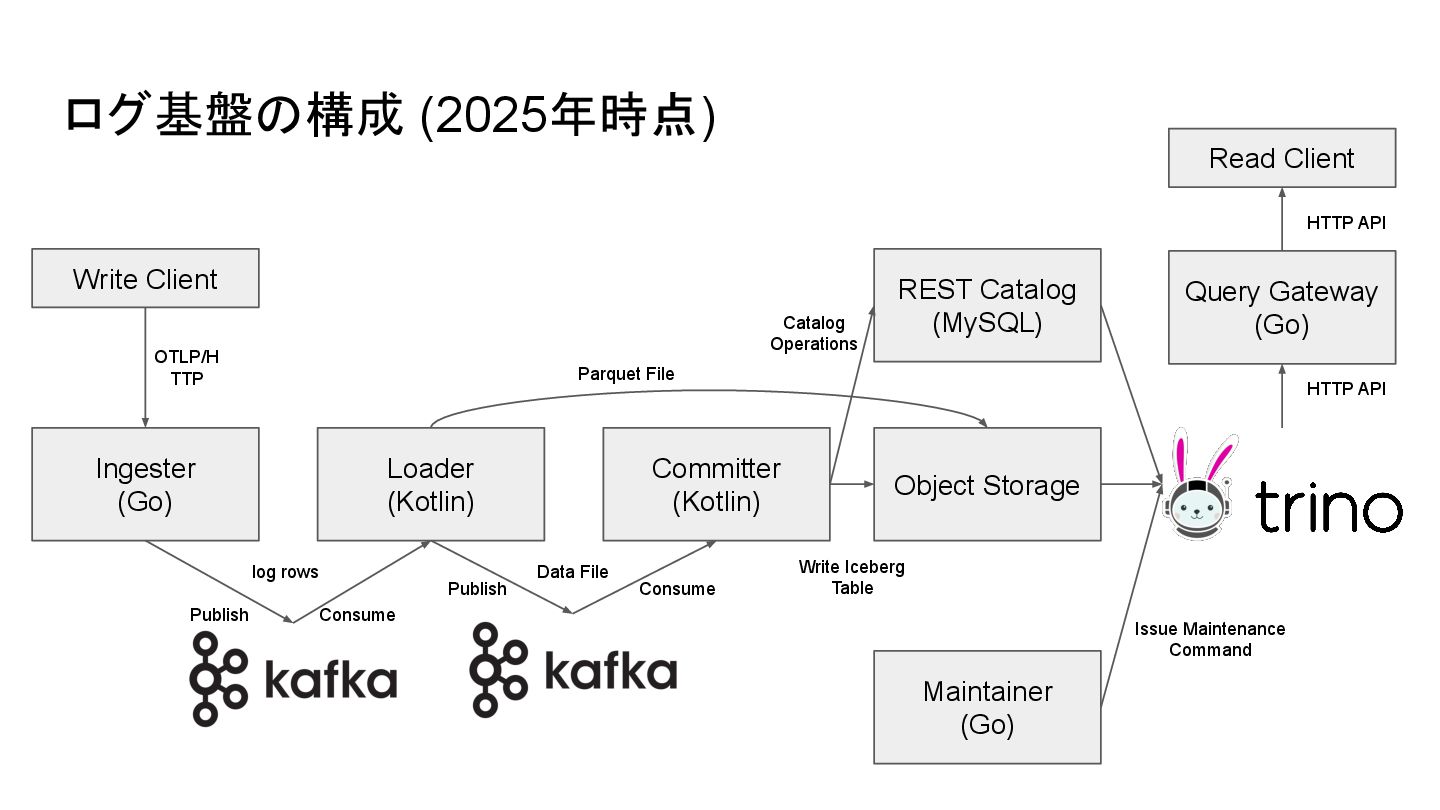
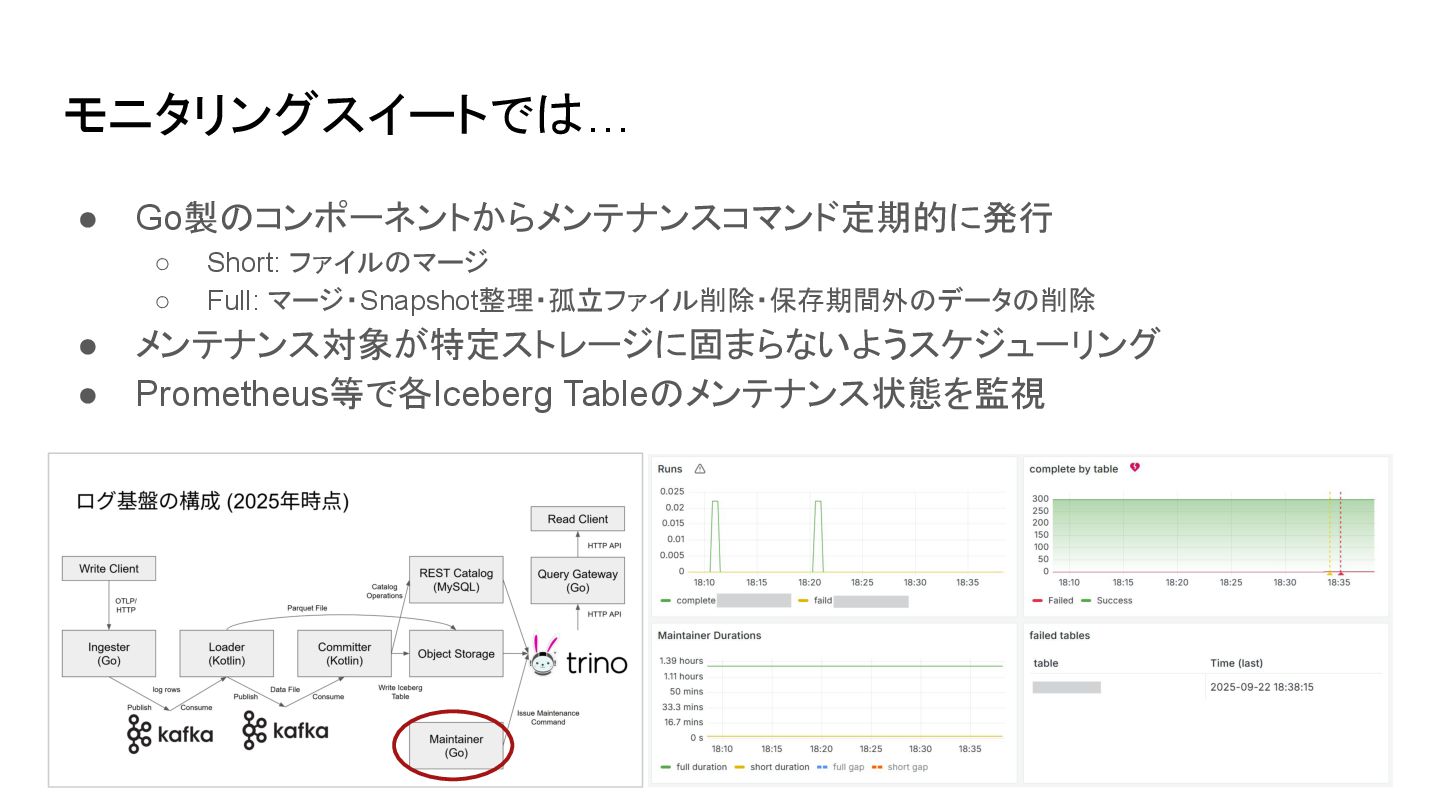
ログ基盤の構成 (2025年時点) Write Client Ingester (Go) Committer (Kotlin) Object Storage
REST Catalog (MySQL) Query Gateway (Go) Maintainer (Go) OTLP/H TTP Publish Consume Write Iceberg Table Catalog Operations Issue Maintenance Command HTTP API Read Client HTTP API Loader (Kotlin) Publish Consume Parquet File Data File log rows
Iceberg Internal • Icebergの仕組みをざっくりと解説 • 目的 ◦ パフォーマンスの特性を理解する ◦ Java
Clientを直接利用することが出来る ◦ テーブル構造のデバッグを行うことが出来る • 用語の揺れが割と有るので許して欲しい ◦ コード・仕様書・ファイル名で名前が違ったりする
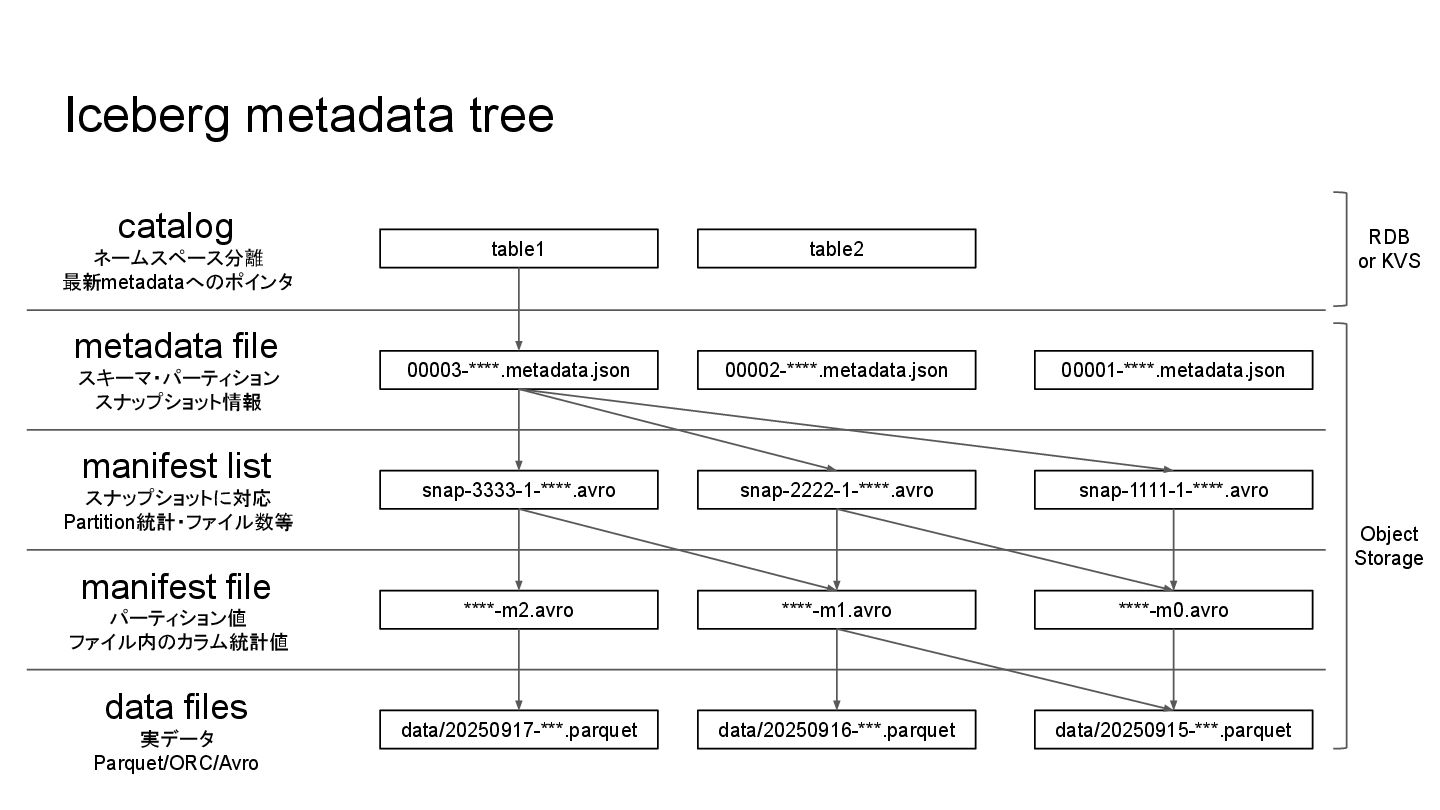
Internal - Layout • データの階層構造 ◦ catalog ◦ metadata file
◦ manifest list ◦ manifest file ◦ data files • CatalogはDBに保存 • その他はS3等に保存 ◦ AWS S3, Google GCS, Hadoop ◦ メタデータ・実データを低コスト・スケーラビリ ティが高いストレージに保存可能 $ tree /mnt/s3/default/t1 . |-- data | |-- 20230928_101505_00007_k5eys-54e49815-ddcf-48b7-9596-ba766979a688.parquet | |-- 20231002_083351_00006_jpegd-d2a1e1ac-1bef-4fab-981c-98c86462c630.parquet | `-- 20231002_083432_00010_jpegd-7c0bd2af-85a5-44a4-a179-82c9a1965139.parquet `-- metadata |-- 00000-1afbaa09-8ed5-4868-9952-02fdd22ccbd6 .metadata.json |-- 00001-5e8fc4c9-962c-4958-a134-ab1a13bfea99 .metadata.json |-- 00002-704c029e-e5c8-46ca-9ea1-7187930be895 .metadata.json |-- 733ba142-1754-4330-ad61-59f58bfd1d71 -m0.avro |-- 733ba142-1754-4330-ad61-59f58bfd1d71 -m1.avro |-- 7f9e5444-9486-4172-aade-288819b03d49 -m0.avro |-- snap-1463702341869305305-1-e07c019a-2f9b-4eab-94b1-38f083598652.avro |-- snap-4566183149179530475-1-b3e2bfc0-0b45-477f-9d38-e2c445eda04c.avro `-- snap-7319754993849090227-1-7f9e5444-9486-4172-aade-288819b03d49.avro
Internal - catalog • 主な役割 ◦ メタデータの格納位置の保持 ◦ トランザクションの提供 •
バックエンド選択肢 ◦ MySQL, PostgreSQL, SQLite (jdbc) ◦ Hive Metastore, Glue, Snowflake ◦ DynamoDB ◦ REST API mysql> SHOW CREATE TABLE iceberg_tables; CREATE TABLE iceberg_tables ( catalog_name varchar NOT NULL, -- example: rest_backend table_namespace varchar NOT NULL, -- example: default table_name varchar NOT NULL, -- example: t1 metadata_location varchar DEFAULT NULL, -- example: s3://bucket/.../00001-.....metadata.json previous_metadata_location varchar DEFAULT NULL, -- example: s3://bucket/.../00000-.....metadata.json PRIMARY KEY ( catalog_name,table_namespace,table_name ) );
Internal - metadata file • テーブル構造の保持 ◦ スキーマ・パーティション・ソート ◦ 途中で変更された際は複数定義される
• スナップショットの保持 ◦ 利用可能なスナップショット一覧 ◦ manifest listのパスの記録 $ jq '.' \ /mnt/s3/default/t1/metadata/00001-.....metadata.json { "schemas": [...], "partition-specs" : [...], "sort-orders" : [...], "snapshots": [ { "snapshot-id" : 1463702341869305300 , "manifest-list" : "s3://bucket/.../metadata/snap-1463...8652.avro" , ... }, { "snapshot-id" : 8429213630642387000 , "parent-snapshot-id" : 1463702341869305300 , "manifest-list": "s3://bucket/.../metadata/snap-8429...ef78.avro", ... } ], ... }
Internal - manifest list • 含まれるパーティションの値・範囲 • manifestへの参照 $ avrocat
\ /mnt/s3/default/t1/metadata/snap-8429...ef78.avro \ | jq '.' { "manifest_path": "s3://bucket/.../metadata/a2c1...-m0.avro", "manifest_length" : 6683, "partition_spec_id" : 0, "content": 0, "sequence_number" : 2, "min_sequence_number" : 2, "added_snapshot_id" : 8429213630642387000 , "added_data_files_count" : 1, "existing_data_files_count" : 0, "deleted_data_files_count" : 0, "added_rows_count" : 1, "existing_rows_count" : 0, "deleted_rows_count" : 0, "partitions": { "array": [] } } { "manifest_path" : ...
Internal - manifest file • 実データファイルへの参照 • 統計情報 ◦ 値の上限・下限・値の数・Null数・NaN数
• memo ◦ status: 1=ADDED, 2=DELETED $ avrocat \ /mnt/s3/default/t1/metadata/a2c1...-m0.avro \ | jq '.' { "status": 1, "snapshot_id" : { "long": 8429213630642387000 }, "data_file" : { "file_path": "s3://bucket/default/t1/data/2023...a688.parquet", "file_format" : "PARQUET", "lower_bounds" : { "array": [ { "key": 1, "value": "\u0001" }, { "key": 2, "value": "\u0002" } ] }, "upper_bounds" : { "array": [ { "key": 1, "value": "\u0001" }, { "key": 2, "value": "\u0002" } ] }, "value_counts" : { ... }, ... } } { "status": ...
Internal - data files • 実際に書き込まれた値 • フォーマットはユーザが指定可能 ◦ Parquet,
ORC, Avro $ pqrs cat \ /mnt/s3/default/t1/data/2023...a688.parquet {a: 1, b: 2}
Iceberg metadata tree catalog metadata file manifest list manifest file
data files 00001-****.metadata.json 00002-****.metadata.json 00003-****.metadata.json snap-3333-1-****.avro snap-2222-1-****.avro snap-1111-1-****.avro ****-m2.avro ****-m1.avro ****-m0.avro data/20250917-***.parquet data/20250916-***.parquet data/20250915-***.parquet table1 table2 ネームスペース分離 最新metadataへのポインタ スキーマ・パーティション スナップショット情報 スナップショットに対応 Partition統計・ファイル数等 パーティション値 ファイル内のカラム統計値 実データ Parquet/ORC/Avro Object Storage RDB or KVS
Internal - file layout Partition無し Partition有り $ tree example/ example/
|-- data | |-- c1= 1 | | |-- c2_month= 2023-01 | | | `-- 20231002_100950_00021_jpegd-346ffc2d-5e11-473e-bf51-30d0898bfdc8.parquet | | `-- c2_month= 2023-02 | | `-- 20231002_100950_00021_jpegd-4029a34f-c9b1-4512-9a2d-e30bc544a163.parquet | `-- c1= 2 | |-- c2_month= 2023-01 | | `-- 20231002_100950_00021_jpegd-02a4022b-c5c3-4367-85ae-fa22904bcdf2.parquet | `-- c2_month= 2023-02 | `-- 20231002_100950_00021_jpegd-391d3d88-af2e-4e63-ba48-f6be548d8243.parquet `-- metadata |-- 00000-da3c553c-0ddc-4b15-85db-0ba0faf757ab .metadata.json |-- 00001-31e284a9-429c-4fa0-a1b2-87499b41b0d4 .metadata.json |-- 00002-c0c18a49-da83-4997-bd78-886db53c53c8 .metadata.json |-- e4737012-26a8-452d-a9d8-17733150fd4c -m0.avro |-- snap-2797793416297343028-1-e4737012-26a8-452d-a9d8-17733150fd4c.avro `-- snap-7900299843327693345-1-4ddcd5de-0345-4fe3-946c-a2607c15bdb2.avro $ tree t1/ t1/ |-- data | |-- 20230928_101505_00007_k5eys-54e49815-ddcf-48b7-9596-ba766979a688.parquet | |-- 20231002_083351_00006_jpegd-d2a1e1ac-1bef-4fab-981c-98c86462c630.parquet | `-- 20231002_083432_00010_jpegd-7c0bd2af-85a5-44a4-a179-82c9a1965139.parquet `-- metadata |-- 00000-1afbaa09-8ed5-4868-9952-02fdd22ccbd6 .metadata.json |-- 00001-5e8fc4c9-962c-4958-a134-ab1a13bfea99 .metadata.json |-- 00002-704c029e-e5c8-46ca-9ea1-7187930be895 .metadata.json |-- 733ba142-1754-4330-ad61-59f58bfd1d71 -m0.avro |-- snap-1463702341869305305-1-e07c019a-2f9b-4eab-94b1-38f083598652.avro `-- snap-4566183149179530475-1-b3e2bfc0-0b45-477f-9d38-e2c445eda04c.avro Partitionを含む場合は、パーティション毎の ディレクトリ(prefix)が作成される
Performance • 概要 ◦ 実行計画は分散実行可能 ◦ ファイルはImmutableでキャッシュも可能 • 実行計画 ◦
manifest list/fileに値のヒントが含まれる ▪ パーティション値の範囲 ▪ 値の数・下限・上限・ Null数 ◦ メタ情報だけでフィルタできる場合も多く Scan量を削減可能
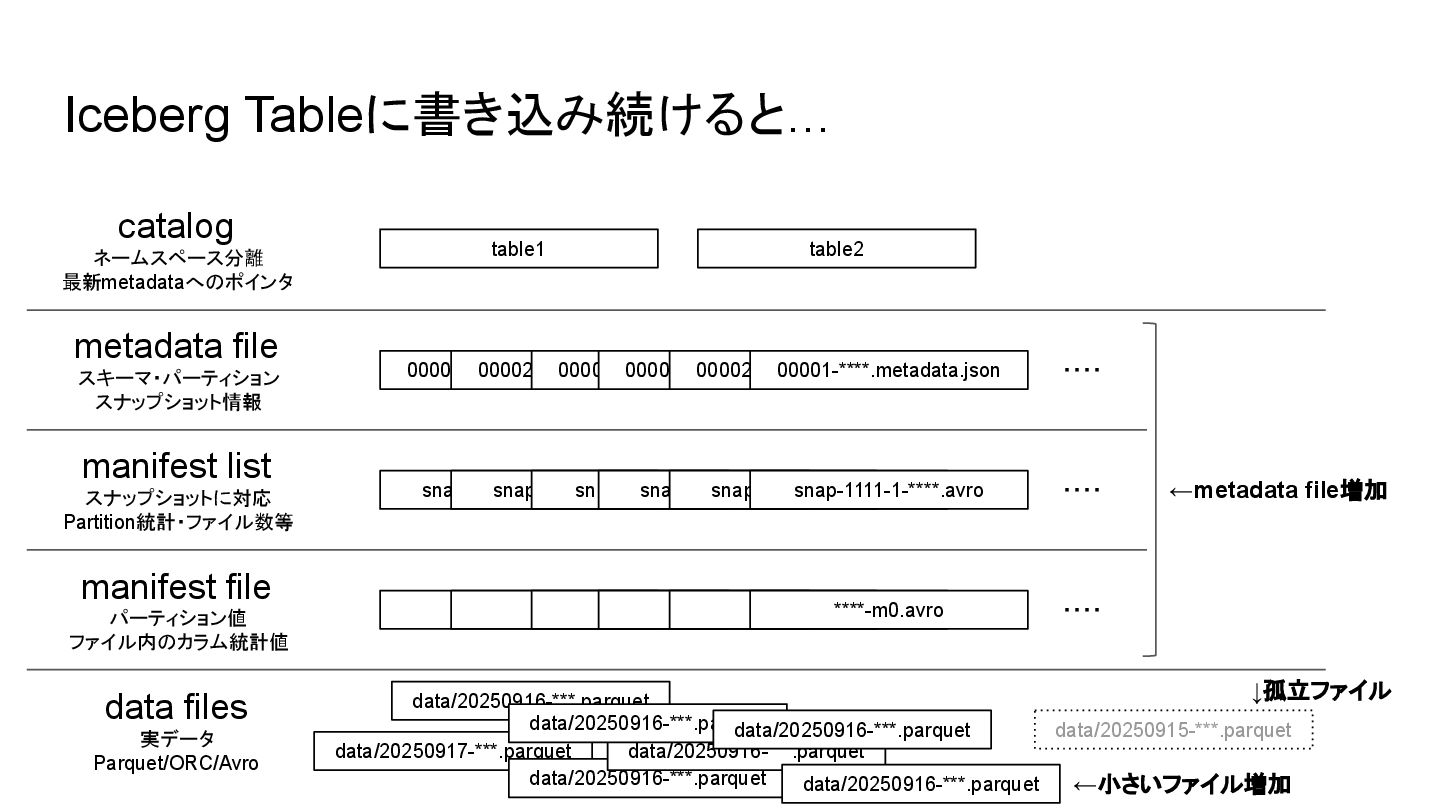
Iceberg Tableに書き込み続けると… catalog metadata file manifest list manifest file data
files 00003-****.metadata.json snap-3333-1-****.avro snap-2222-1-****.avro snap-1111-1-****.avro ****-m2.avro ****-m1.avro ****-m0.avro data/20250917-***.parquet data/20250916-***.parquet data/20250915-***.parquet table1 table2 ネームスペース分離 最新metadataへのポインタ スキーマ・パーティション スナップショット情報 スナップショットに対応 Partition統計・ファイル数等 パーティション値 ファイル内のカラム統計値 実データ Parquet/ORC/Avro ・・・・ 00002-****.metadata.json 00001-****.metadata.json 00003-****.metadata.json 00002-****.metadata.json 00001-****.metadata.json ←metadata file増加 snap-3333-1-****.avro snap-2222-1-****.avro snap-1111-1-****.avro ・・・・ ****-m2.avro ****-m1.avro ****-m0.avro ・・・・ data/20250916-***.parquet data/20250916-***.parquet data/20250916-***.parquet data/20250916-***.parquet data/20250916-***.parquet ↓孤立ファイル ←小さいファイル増加
Iceberg Tableに書き込み続けると… • Dataファイル(Parquet)数の増加 ◦ スキャンする際に開くファイルが増える ◦ HTTPリクエスト数等のオーバーヘッド増加 • 不要なDataファイル数の増加
◦ ストレージ容量圧迫 • スナップショット数の増加 ◦ metadataファイルの肥大化 ◦ Query/InsertのCPU/RAM消費量増加・レイテンシ増加 • metadataファイルの増加 ◦ metadata/ 配下のファイル数が増え、 ListObjectsが遅くなる ◦ 各種最適化の時間増加
Maintenance • データファイルのマージ (高頻度) ◦ より大きい少ないファイルにマージすることで、プラン・スキャンの高速化 ◦ パーティション毎に実行可能 ◦ ALTER TABLE
example EXECUTE optimize(file_size_threshold => '100MB'); • スナップショットの削除 (低頻度) ◦ 古いスナップショット・データを削除 ◦ ALTER TABLE example EXECUTE expire_snapshots(retention_threshold => '7d'); • 孤立したファイルの削除 (低頻度) ◦ ジョブの失敗などで発生するファイルを削除 ◦ ALTER TABLE example EXECUTE remove_orphan_files(retention_threshold => '7d'); • 古いメタデータの削除 (コミットごと) ◦ write.metadata.delete-after-commit.enabled=true (2025年1月 Trino 469からサポート)
モニタリングスイートでは… • Go製のコンポーネントからメンテナンスコマンド定期的に発行 ◦ Short: ファイルのマージ ◦ Full: マージ・Snapshot整理・孤立ファイル削除・保存期間外のデータの削除 •
メンテナンス対象が特定ストレージに固まらないようスケジューリング • Prometheus等で各Iceberg Tableのメンテナンス状態を監視
まとめ Iceberg, Trinoでのログ基盤構築とパフォーマンス最適化 • さくらインターネットのモニタリングスイートはIceberg,Trinoで構築 • Icebergはメタデータをオブジェクトストレージに保存する ◦ Planの高速化・スケーラビリティのため •
Icebergは書き込みを続けるとパフォーマンス劣化する • TrinoではIceberg Tableのメンテナンス用のコマンドが提供されている • モニタリングスイートでは ◦ テナントごとにテーブルを分離 ◦ Trinoコマンドを定期的に呼び出してパフォーマンスを維持
宣伝 技術コミュニティに大阪 Blooming Campを会場提供します 大阪駅から雨でも濡れずに行けます 配信機材等も用意しています 検索「さくらインターネット 大阪 会場提供」
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}