• 統計モデル:ARIMA, SARIMA, Box-Jenkins法, VAR, GARCH 等
◦ 古典的手法を統計によって拡張、単純な構造で線形定常性データは精度が向上
◦ 得られたデータの解釈や「予測の外れ具合」への言及など様々な活用が可能に
• 状態空間モデル
◦ 古典的手法や統計手法のさらなる拡張
◦ 目に見えない「状態」を用いることで、時系列データをより柔軟にモデル化が可能
• 曲線フィッティング:prophet, 機械学習手法 等
◦ 膨大な計算量を短時間に行えることにより、古典的手法を拡張
◦ 例えば曲線による表現により特徴量設計が自動推定可能になるなど
• ニューラルネットワーク:LSTM 等
◦ 長期的な依存関係を学習することができるようになる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
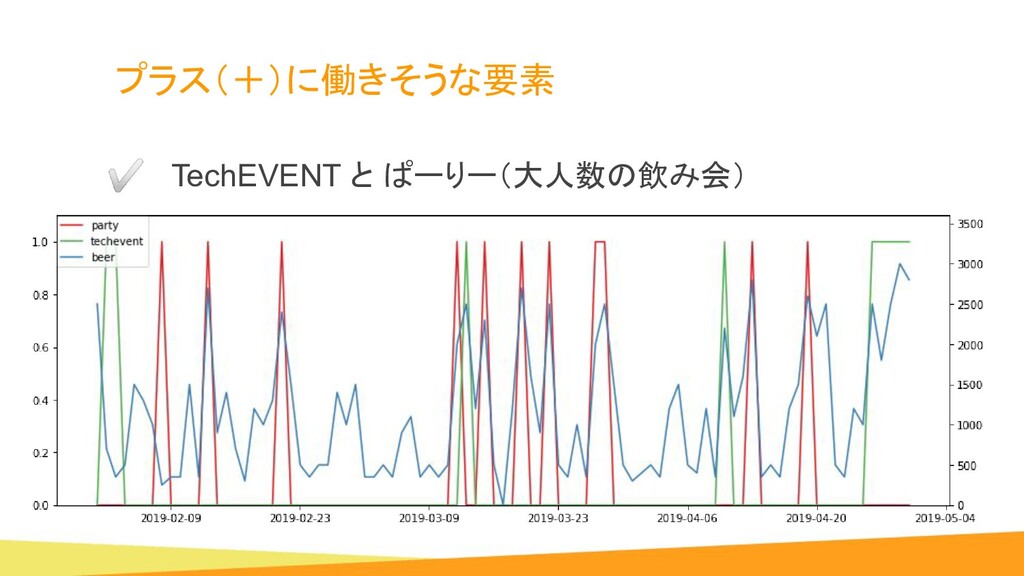{kind=link}
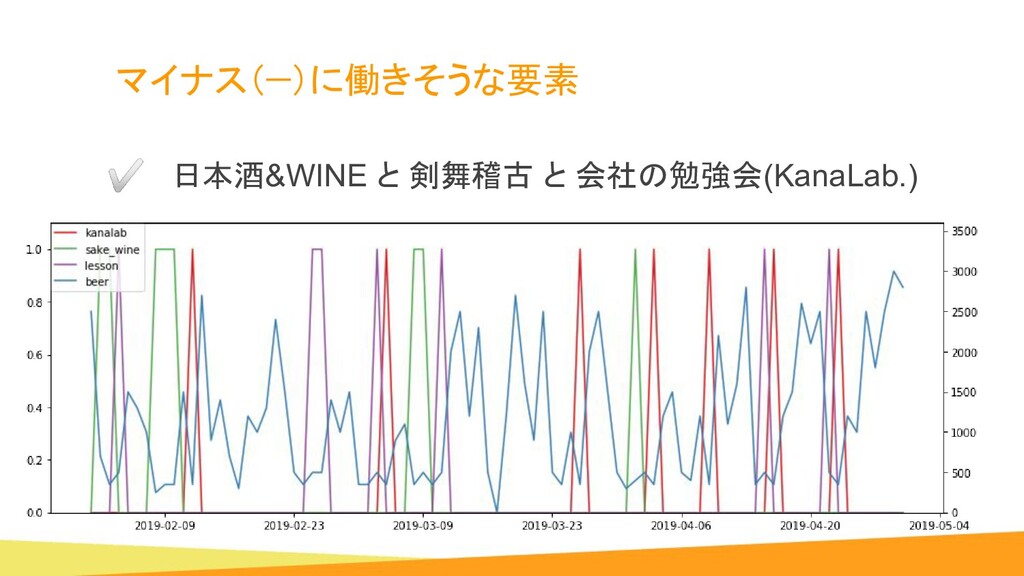{kind=link}
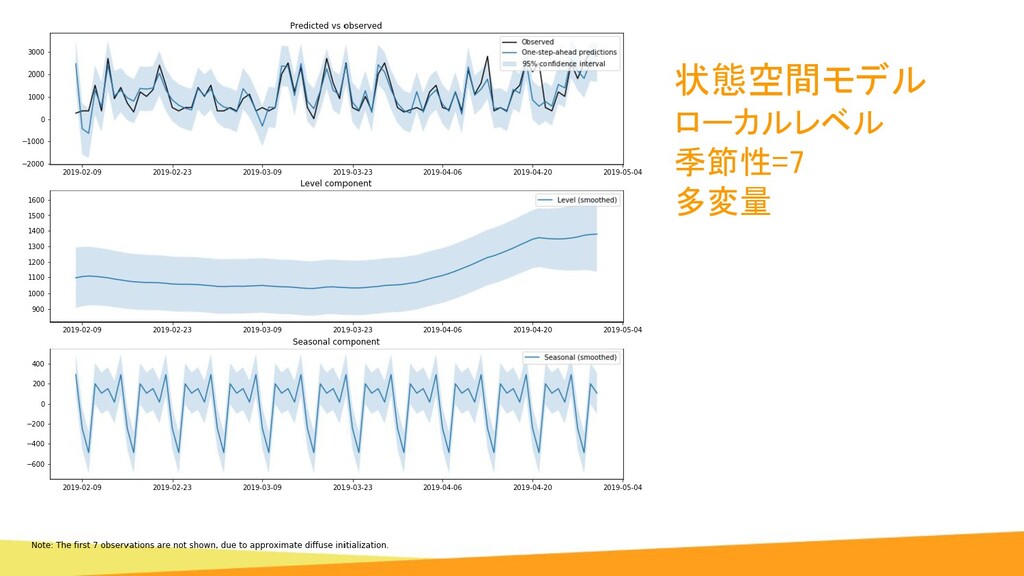{kind=link}
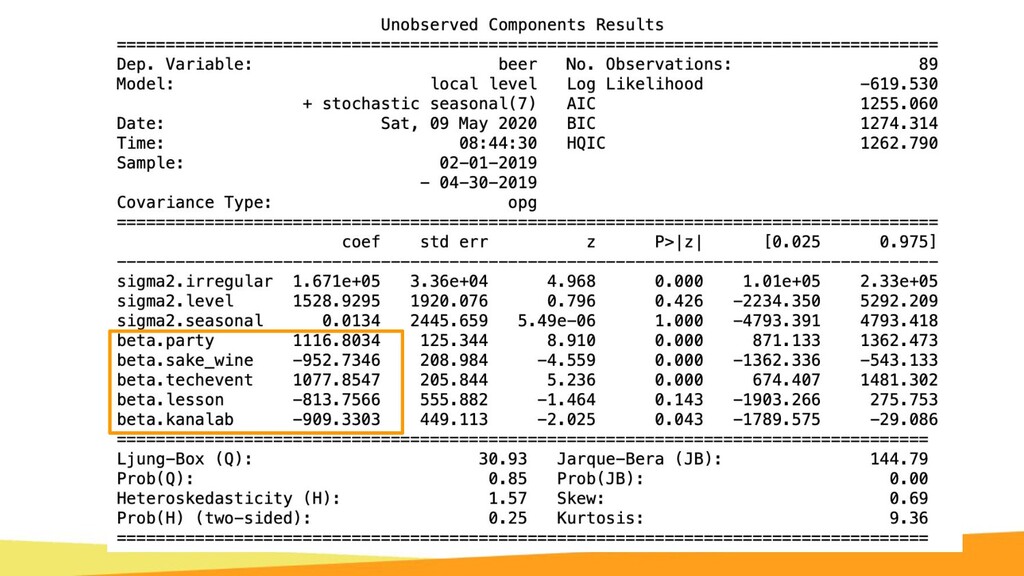{kind=link}
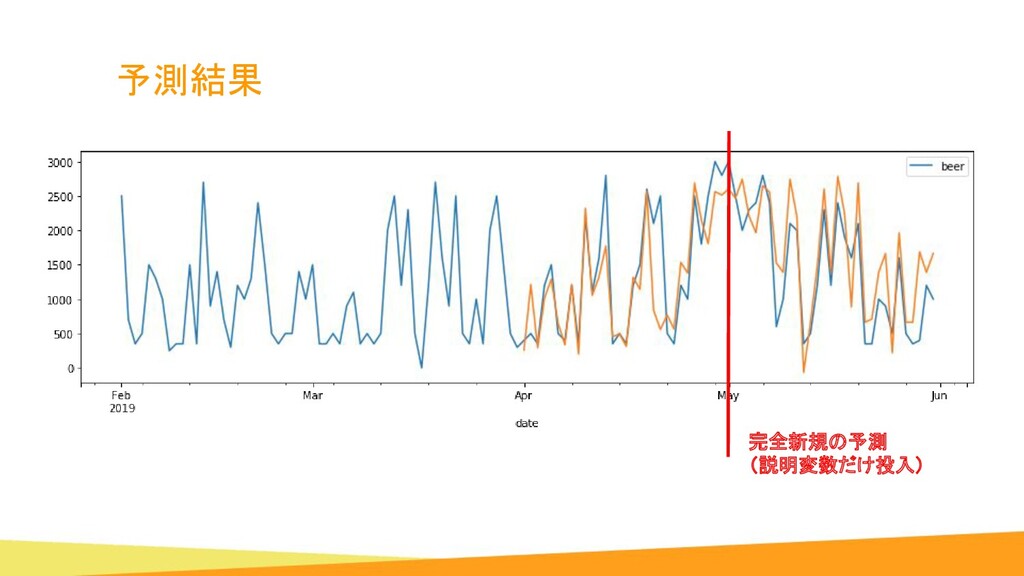{kind=link}
{kind=link}
{kind=link}
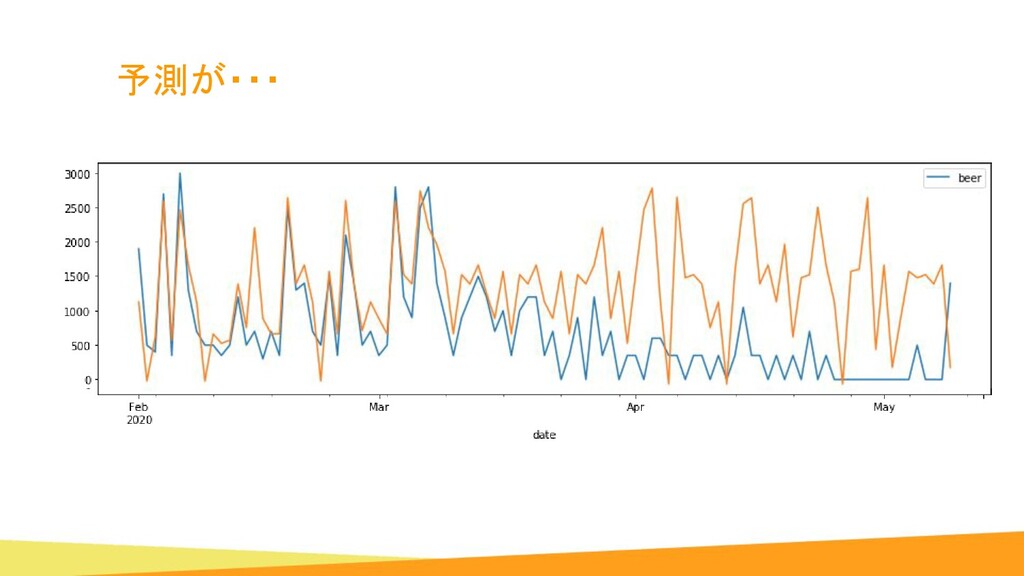{kind=link}
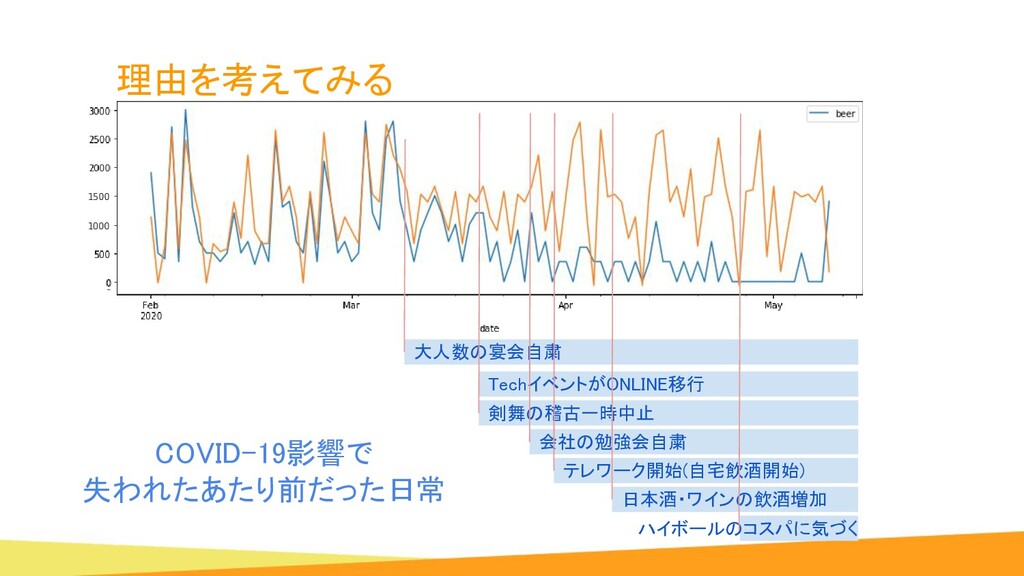{kind=link}
{kind=link}
{kind=link}
{kind=link}