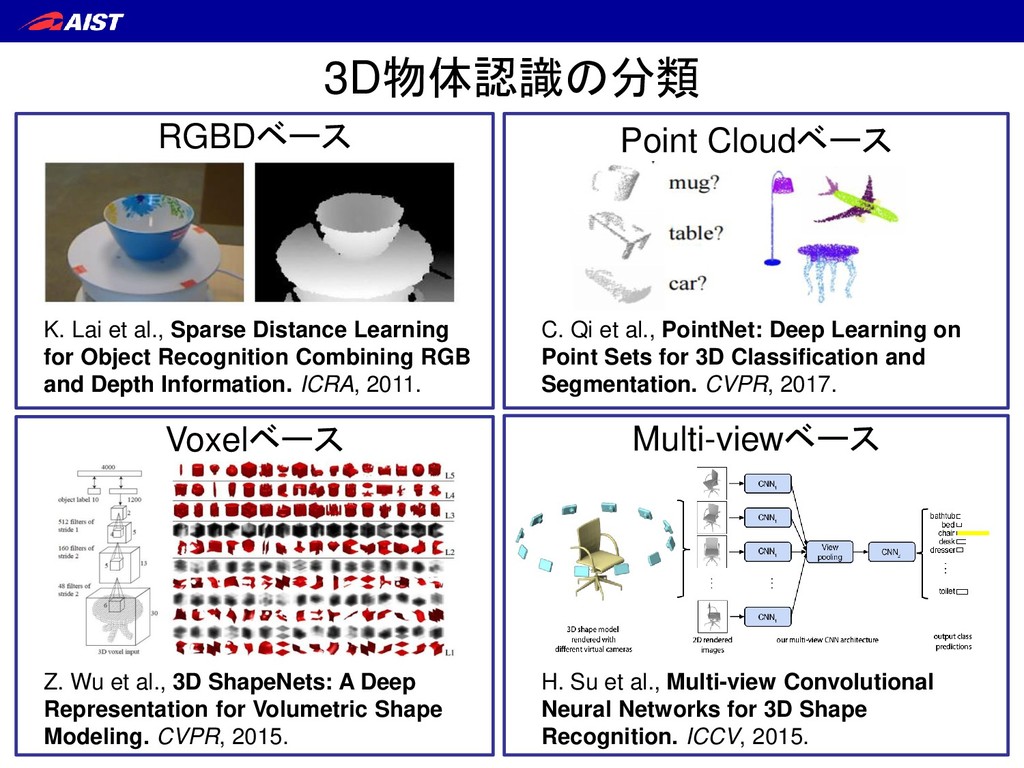
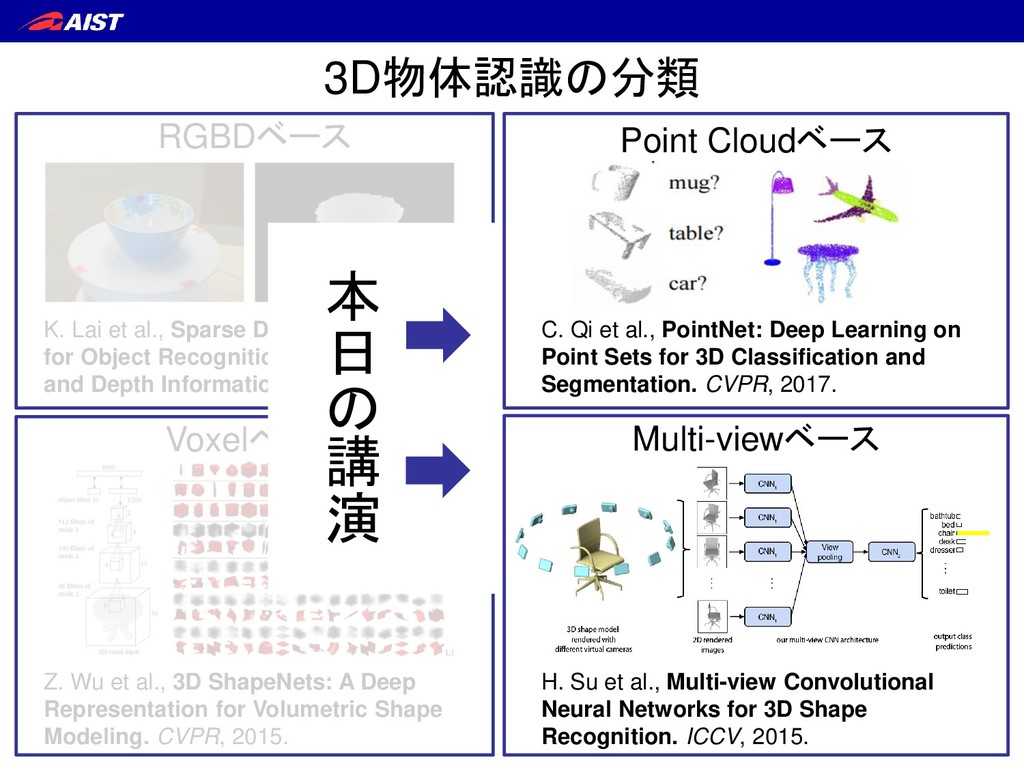
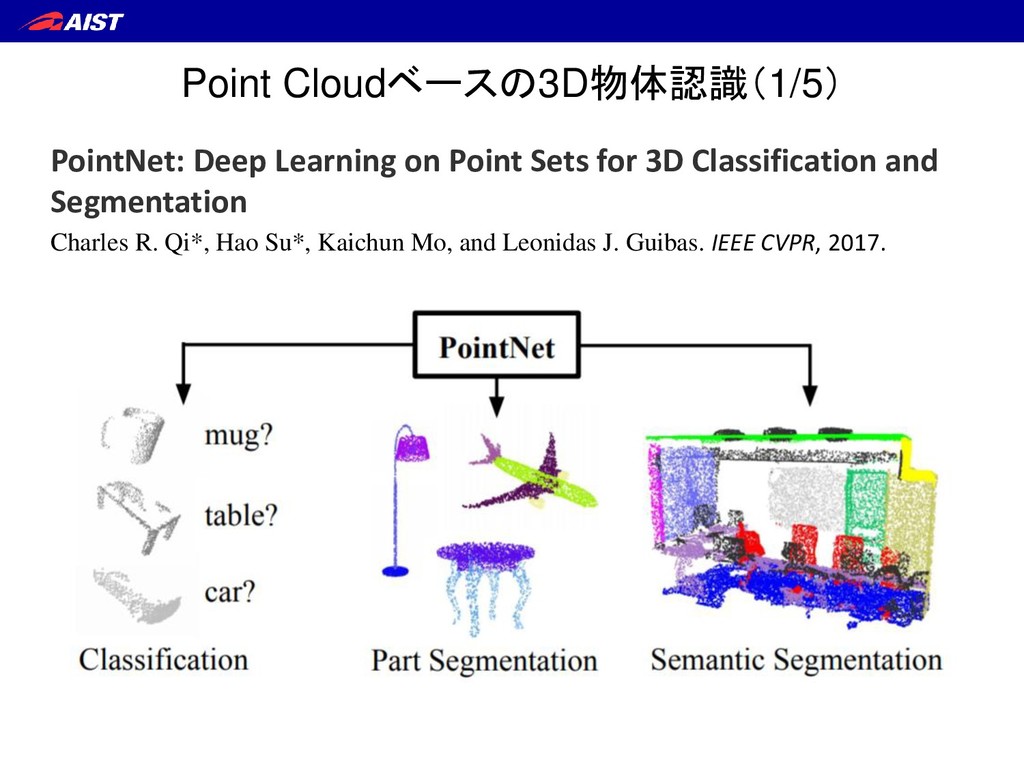
Sparse Distance Learning for Object Recognition Combining RGB and Depth Information. ICRA, 2011. C. Qi et al., PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. CVPR, 2017. Z. Wu et al., 3D ShapeNets: A Deep Representation for Volumetric Shape Modeling. CVPR, 2015. H. Su et al., Multi-view Convolutional Neural Networks for 3D Shape Recognition. ICCV, 2015.
Sparse Distance Learning for Object Recognition Combining RGB and Depth Information. ICRA, 2011. C. Qi et al., PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. CVPR, 2017. Z. Wu et al., 3D ShapeNets: A Deep Representation for Volumetric Shape Modeling. CVPR, 2015. H. Su et al., Multi-view Convolutional Neural Networks for 3D Shape Recognition. ICCV, 2015. 本 日 の 講 演
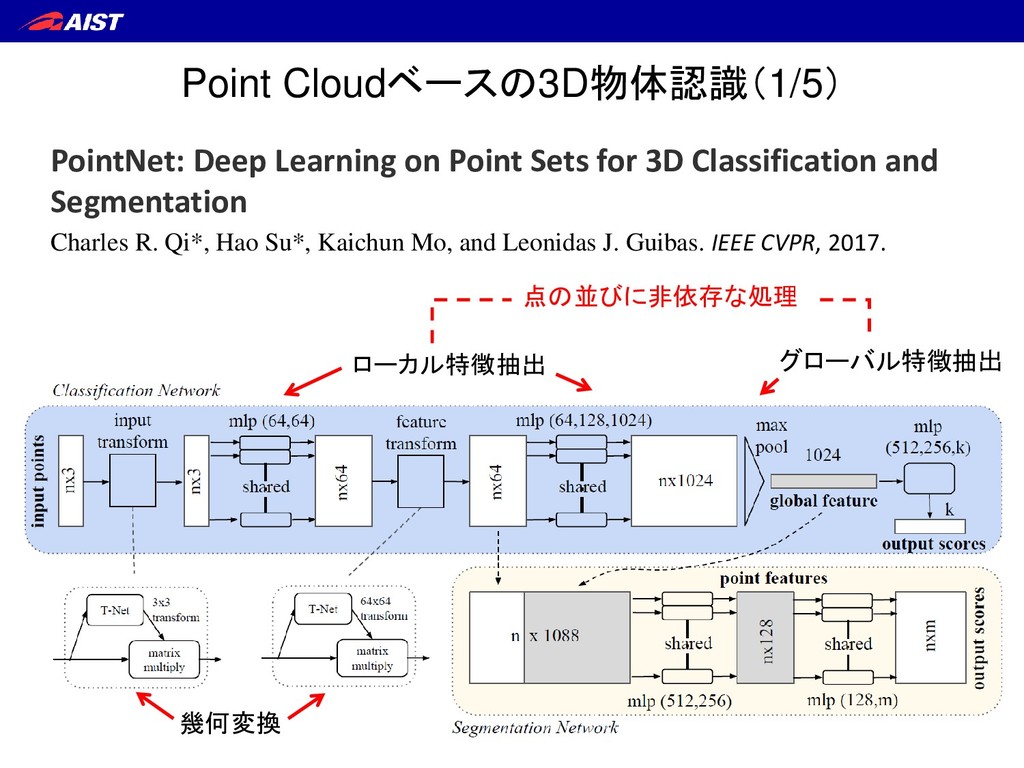
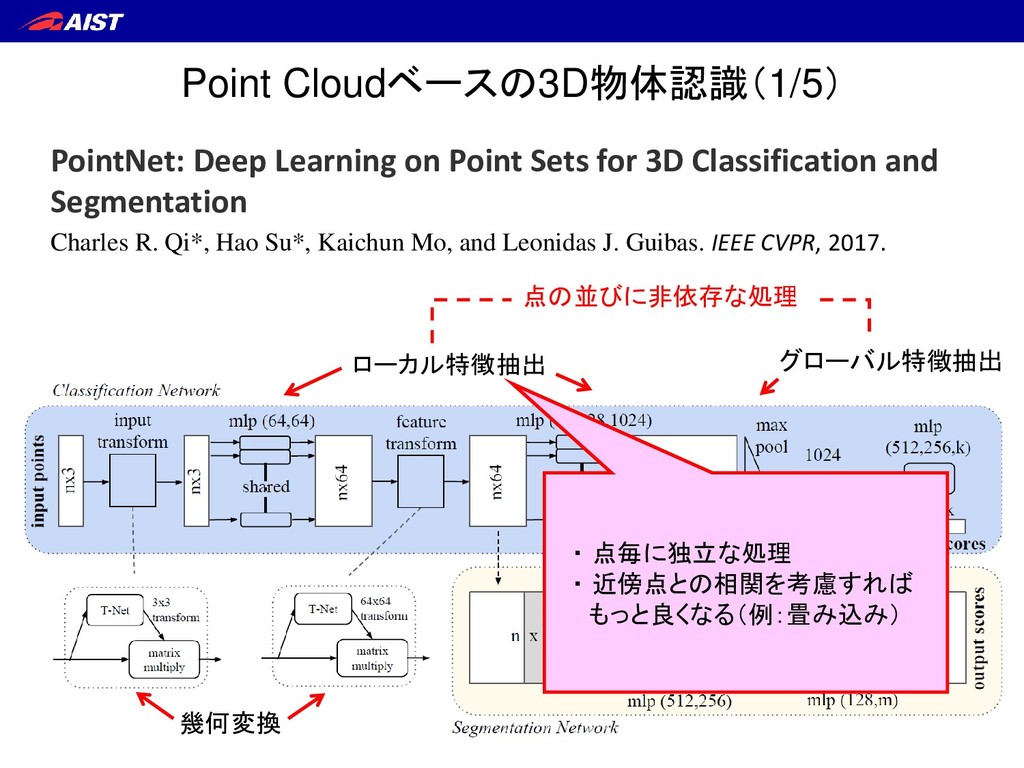
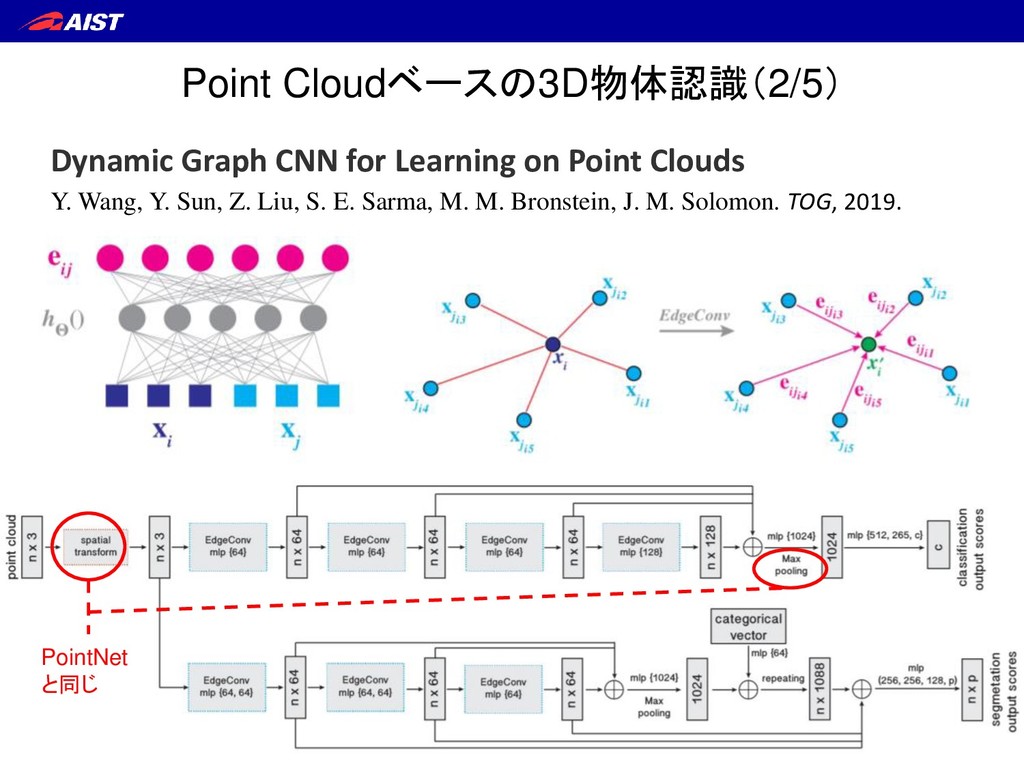
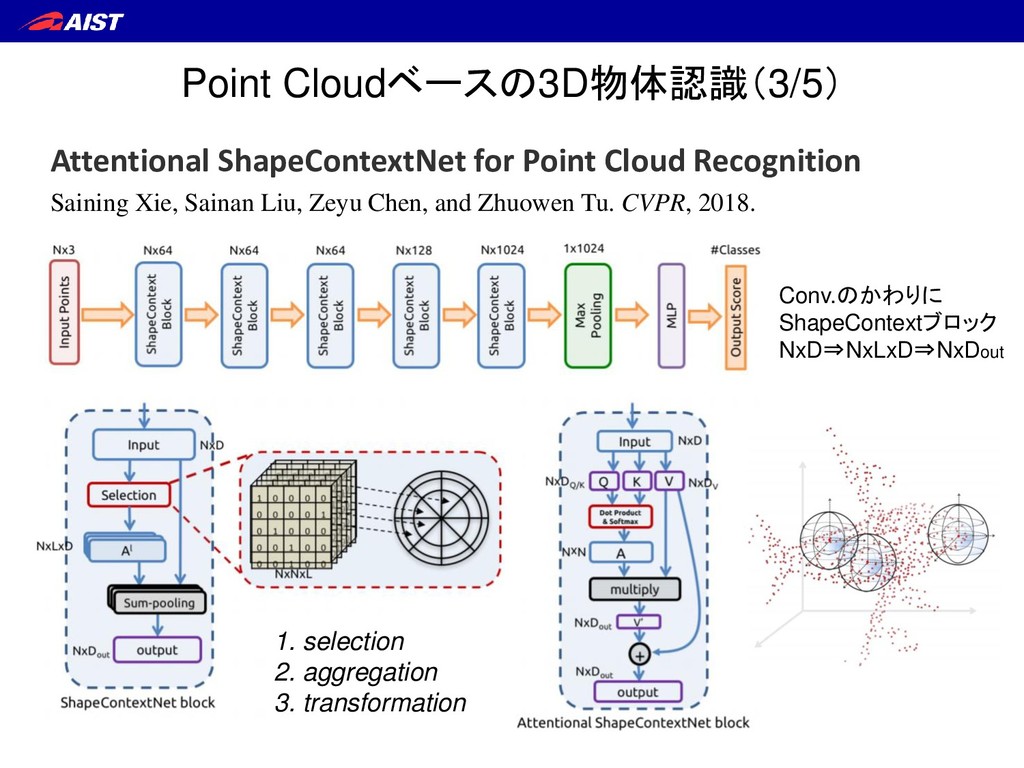
Sets for 3D Classification and Segmentation Charles R. Qi*, Hao Su*, Kaichun Mo, and Leonidas J. Guibas. IEEE CVPR, 2017. 点の並びに非依存な処理 ・ 点毎に独立な処理 ・ 近傍点との相関を考慮すれば もっと良くなる(例:畳み込み)
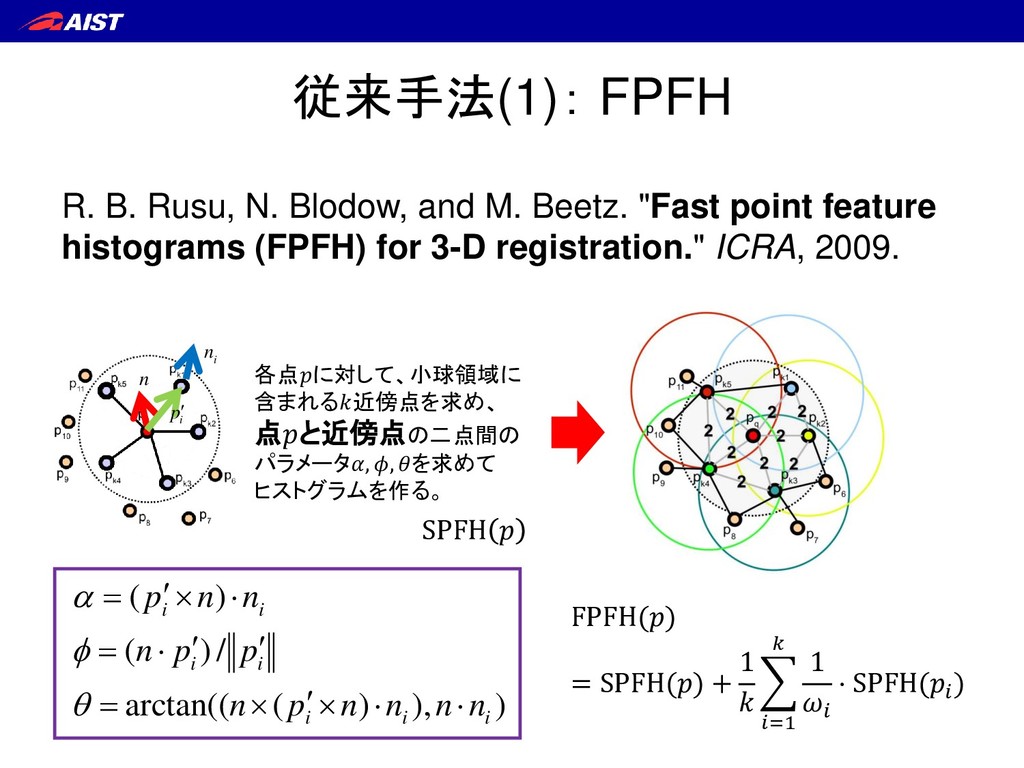
"Fast point feature histograms (FPFH) for 3-D registration." ICRA, 2009. i p n i n SPFH 各点に対して、小球領域に 含まれる近傍点を求め、 点と近傍点の二点間の パラメータ, , を求めて ヒストグラムを作る。 FPFH() = SPFH() + 1 =1 1 ⋅ SPFH( ) ) ), ) ( arctan(( / ) ( ) ( i i i i i i i n n n n p n p p n n n p = = =
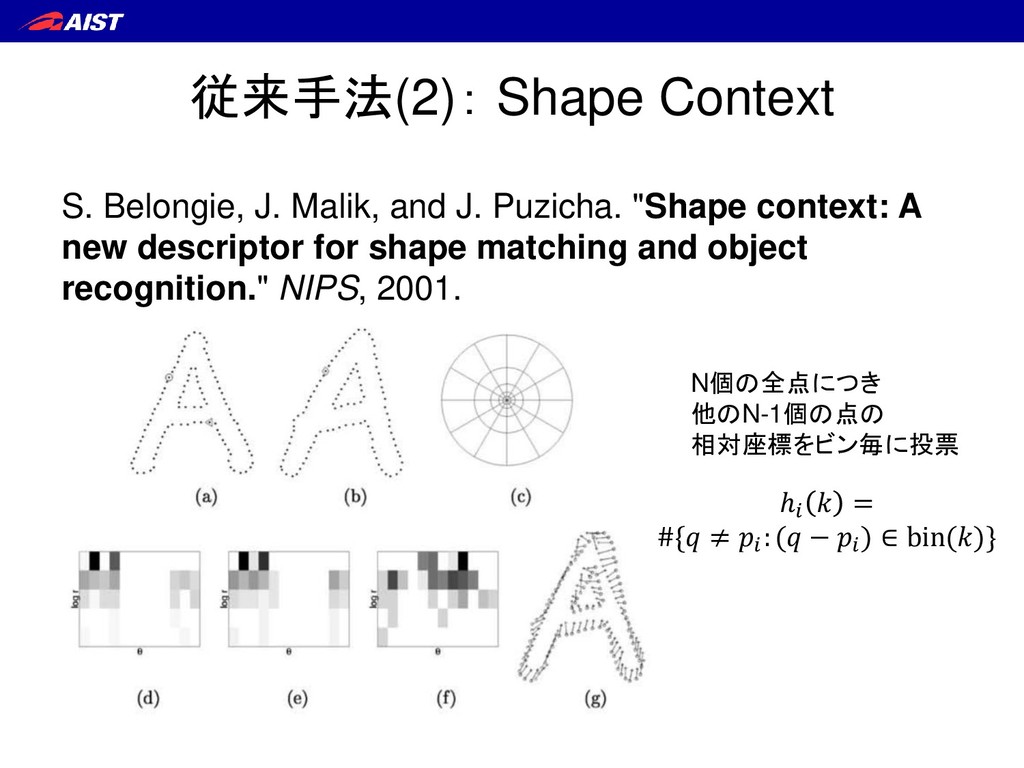
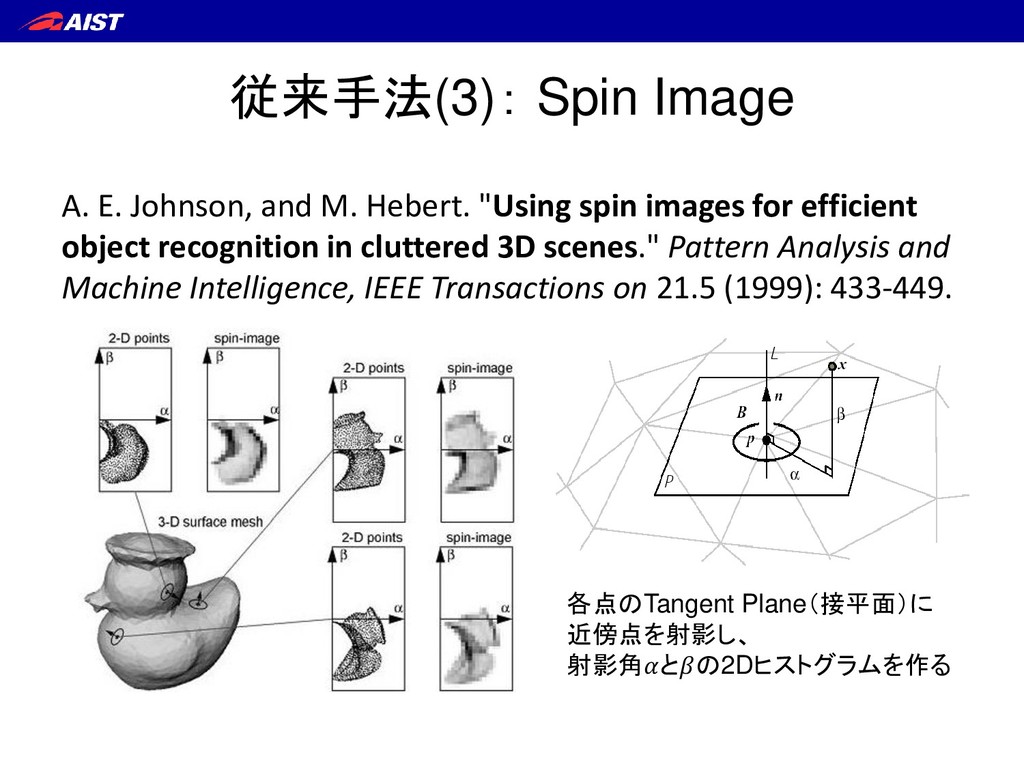
spin images for efficient object recognition in cluttered 3D scenes." Pattern Analysis and Machine Intelligence, IEEE Transactions on 21.5 (1999): 433-449. 各点のTangent Plane(接平面)に 近傍点を射影し、 射影角との2Dヒストグラムを作る
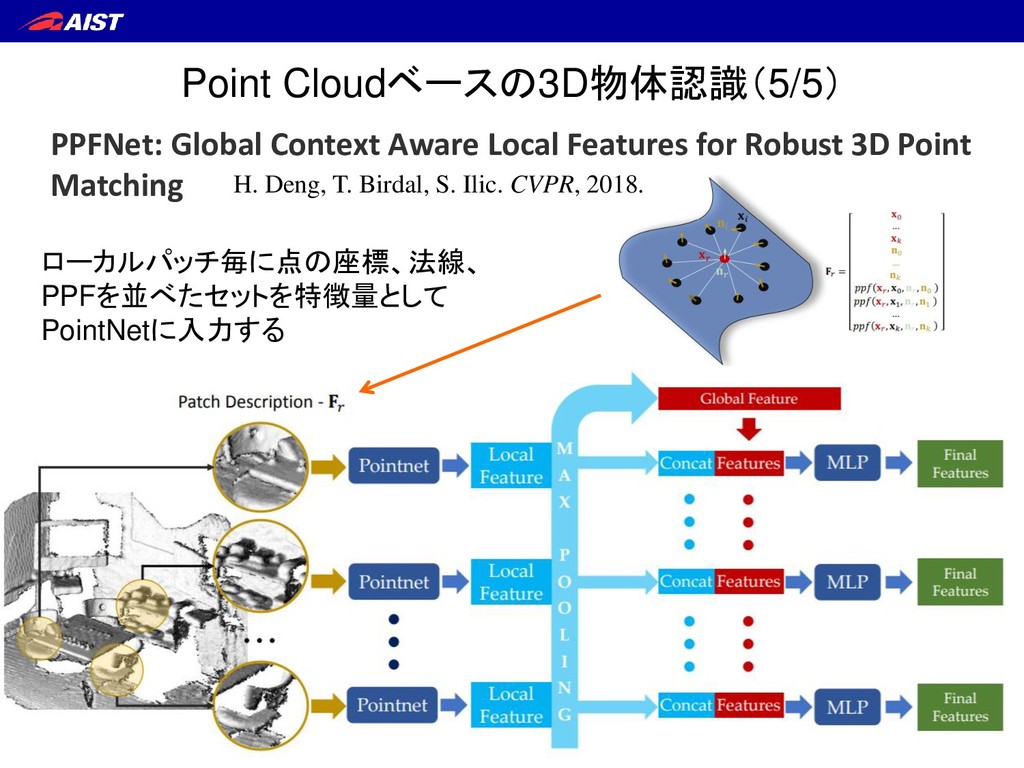
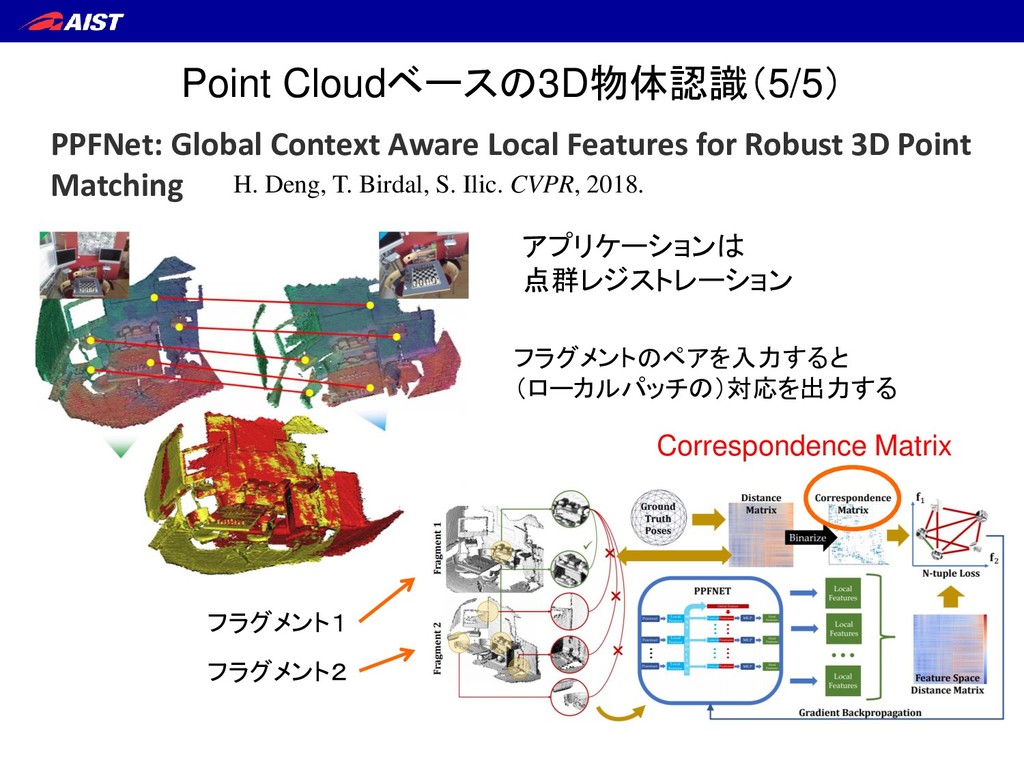
3D Point Matching H. Deng, T. Birdal, S. Ilic. CVPR, 2018. アプリケーションは 点群レジストレーション フラグメントのペアを入力すると (ローカルパッチの)対応を出力する Correspondence Matrix フラグメント1 フラグメント2
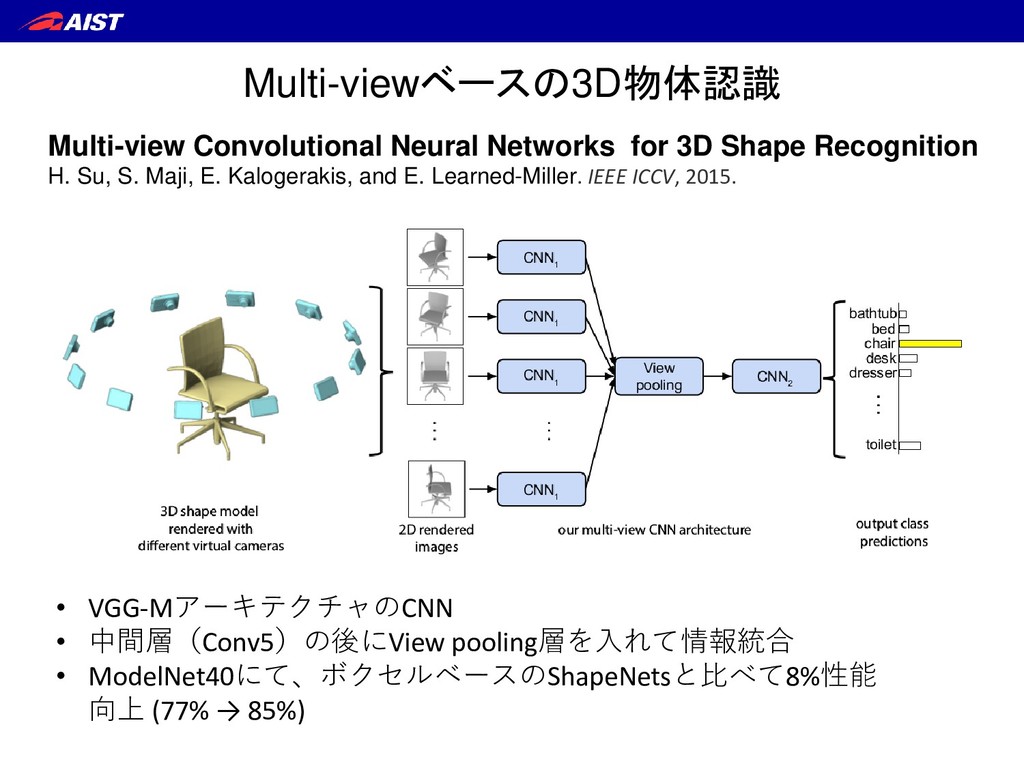
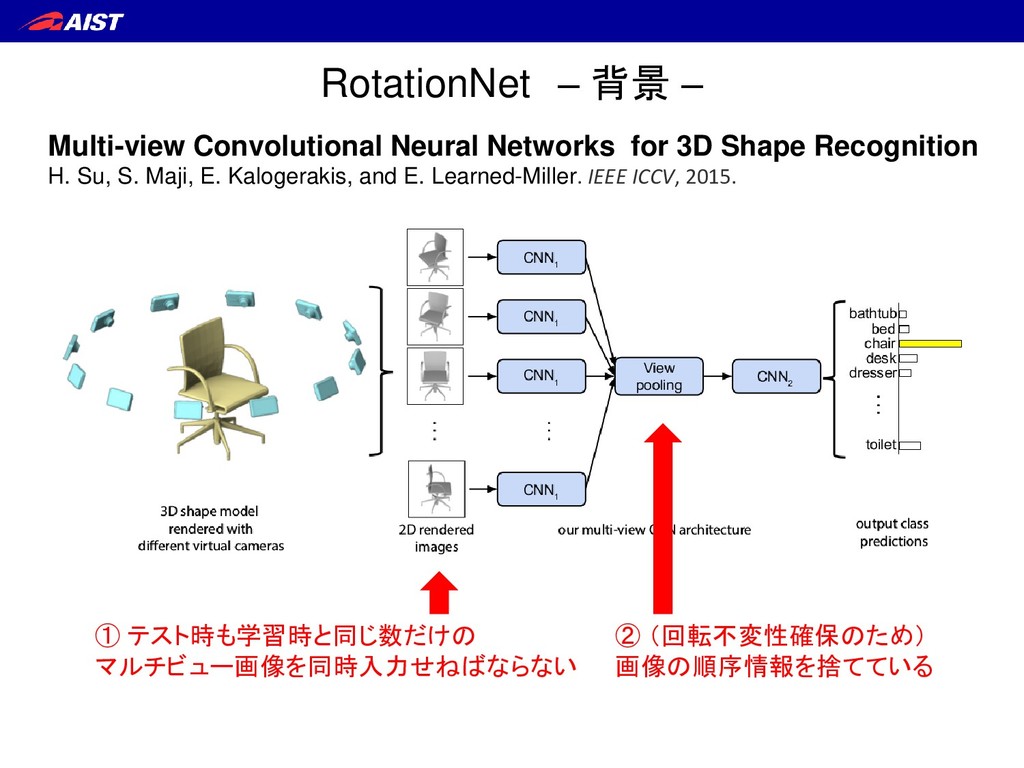
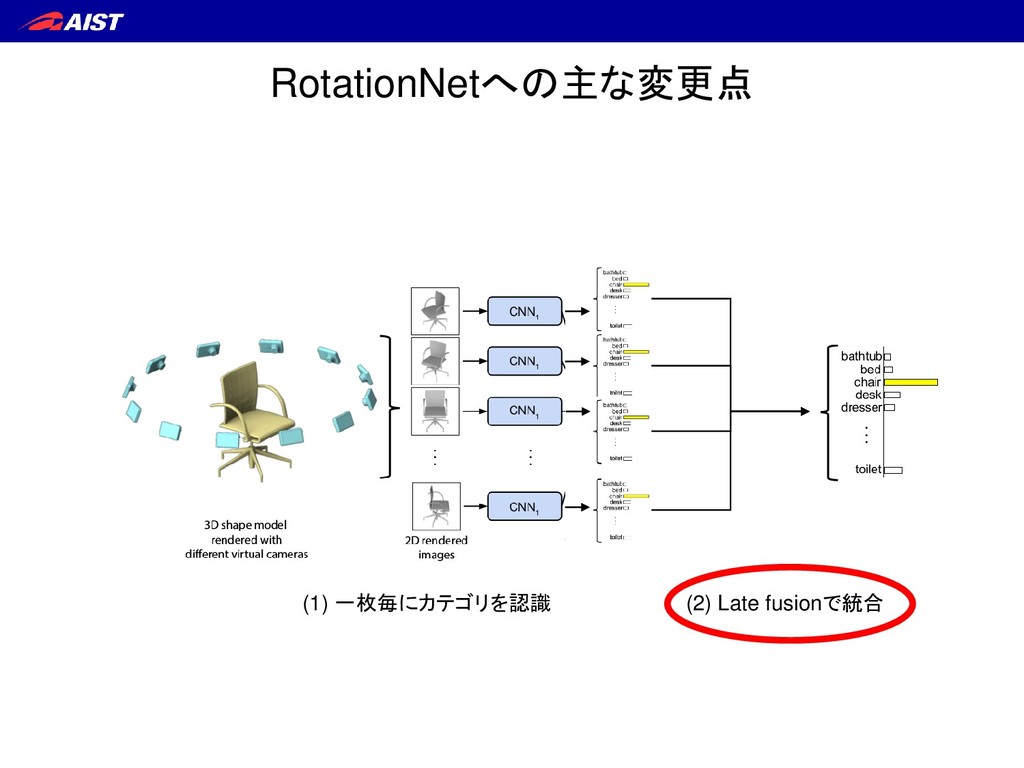
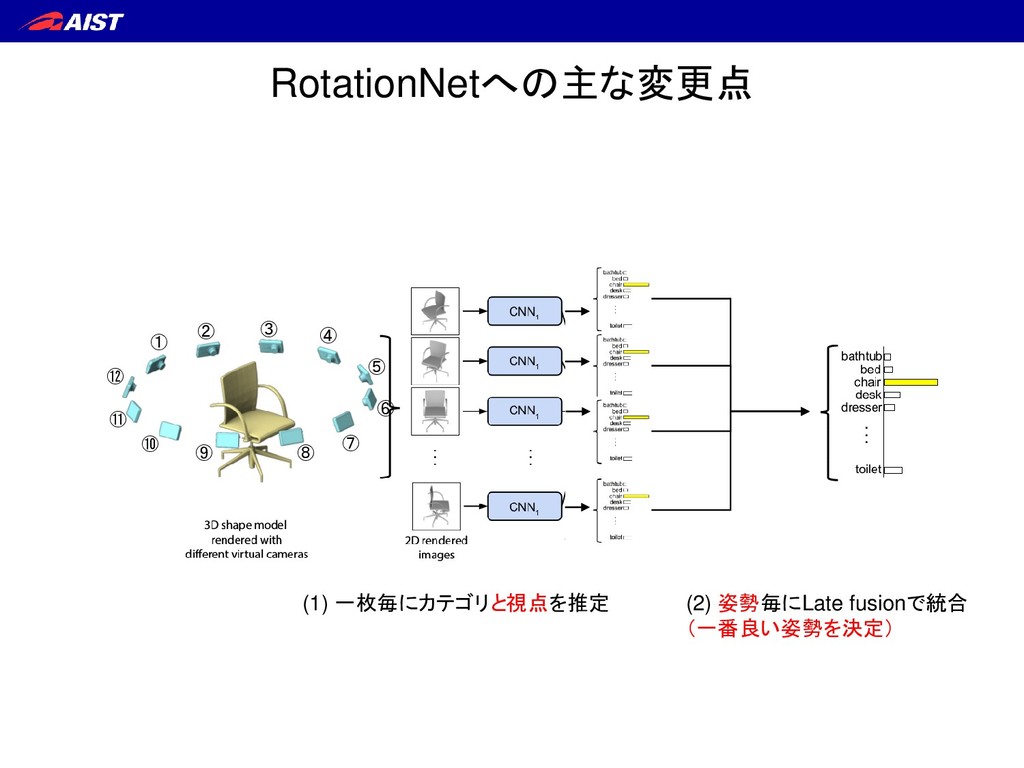
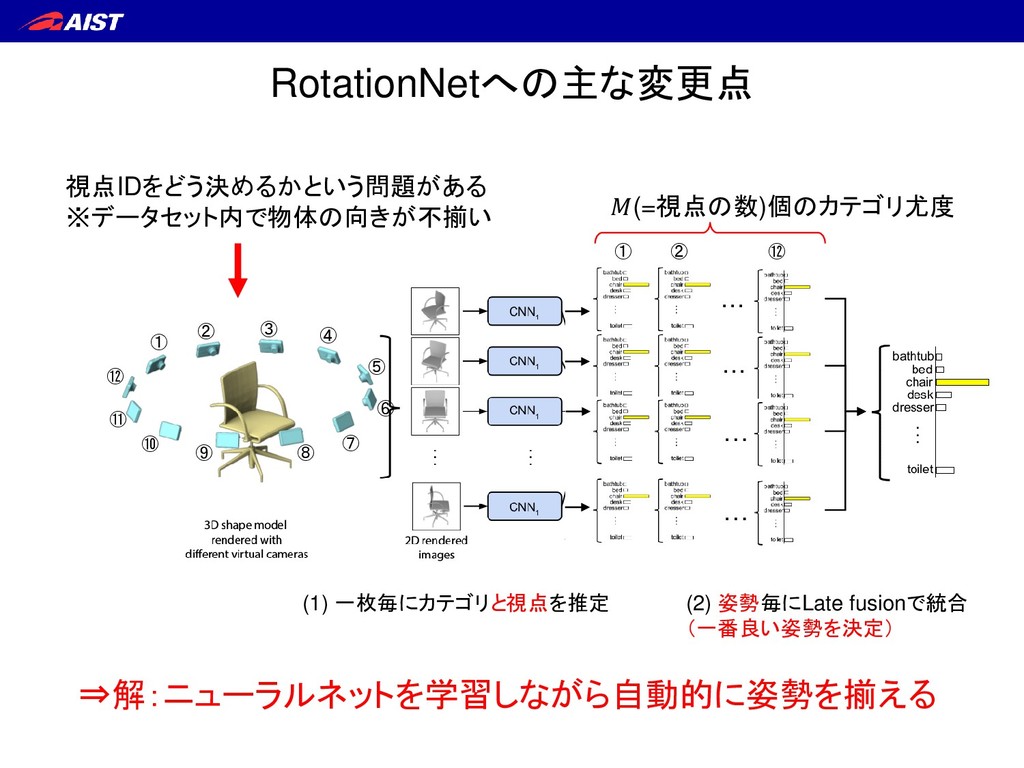
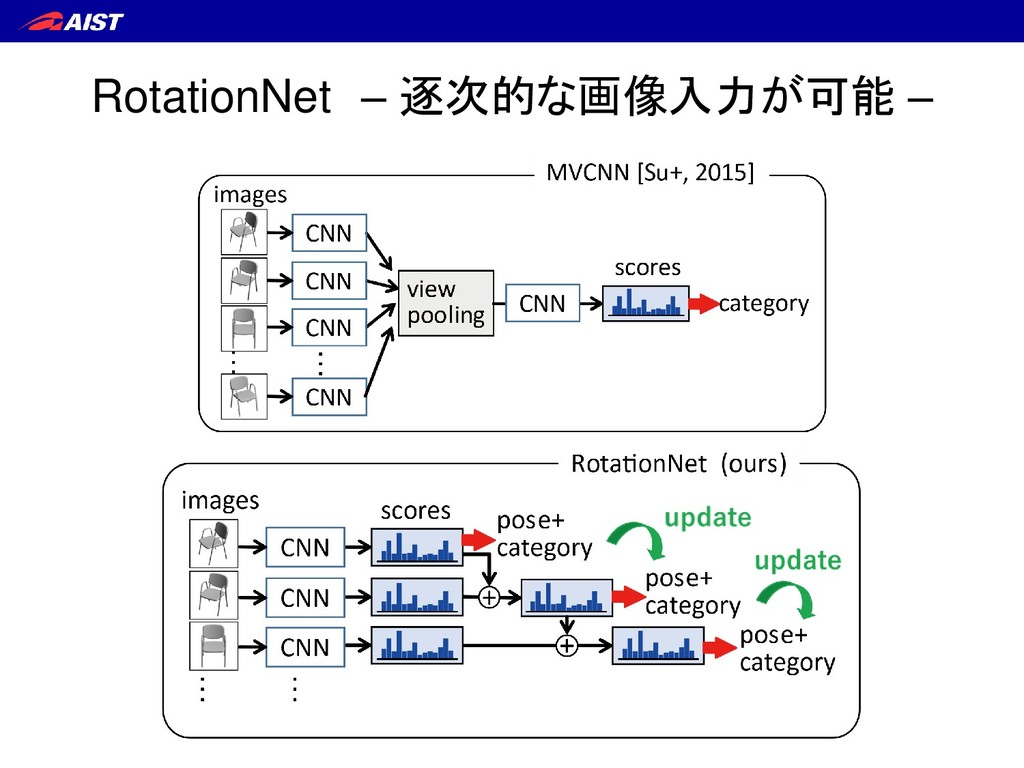
S. Maji, E. Kalogerakis, and E. Learned-Miller. IEEE ICCV, 2015. ① テスト時も学習時と同じ数だけの マルチビュー画像を同時入力せねばならない ② (回転不変性確保のため) 画像の順序情報を捨てている RotationNet – 背景 –
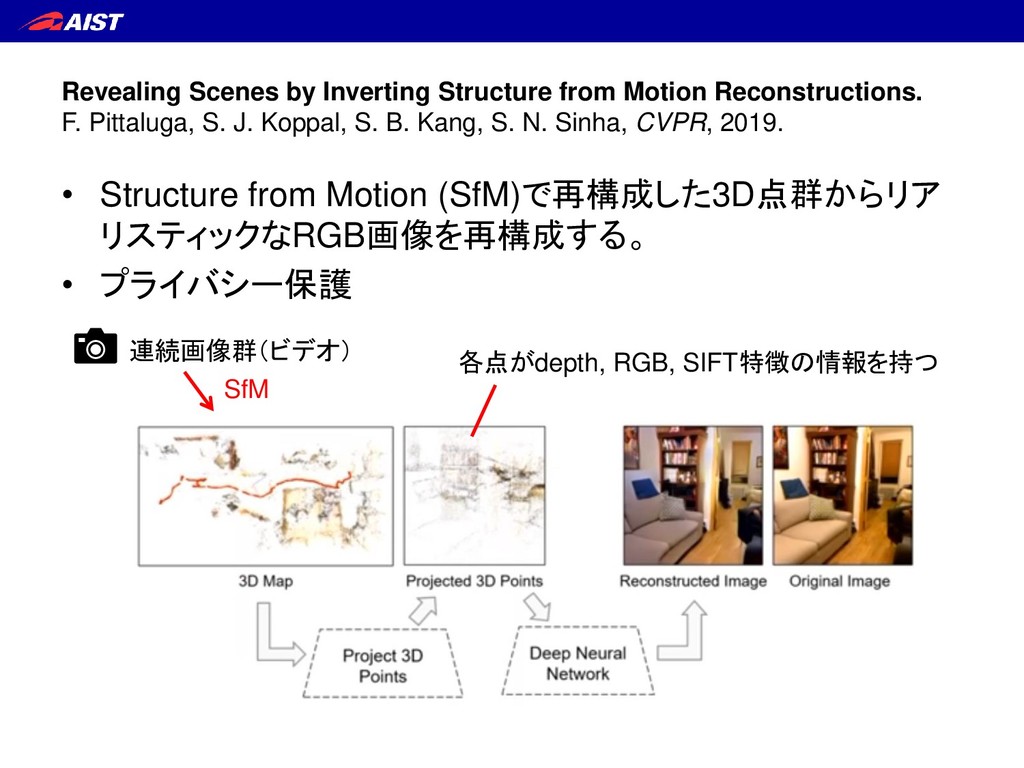
S. J. Koppal, S. B. Kang, S. N. Sinha, CVPR, 2019. • Structure from Motion (SfM)で再構成した3D点群からリア リスティックなRGB画像を再構成する。 • プライバシー保護 連続画像群(ビデオ) SfM 各点がdepth, RGB, SIFT特徴の情報を持つ
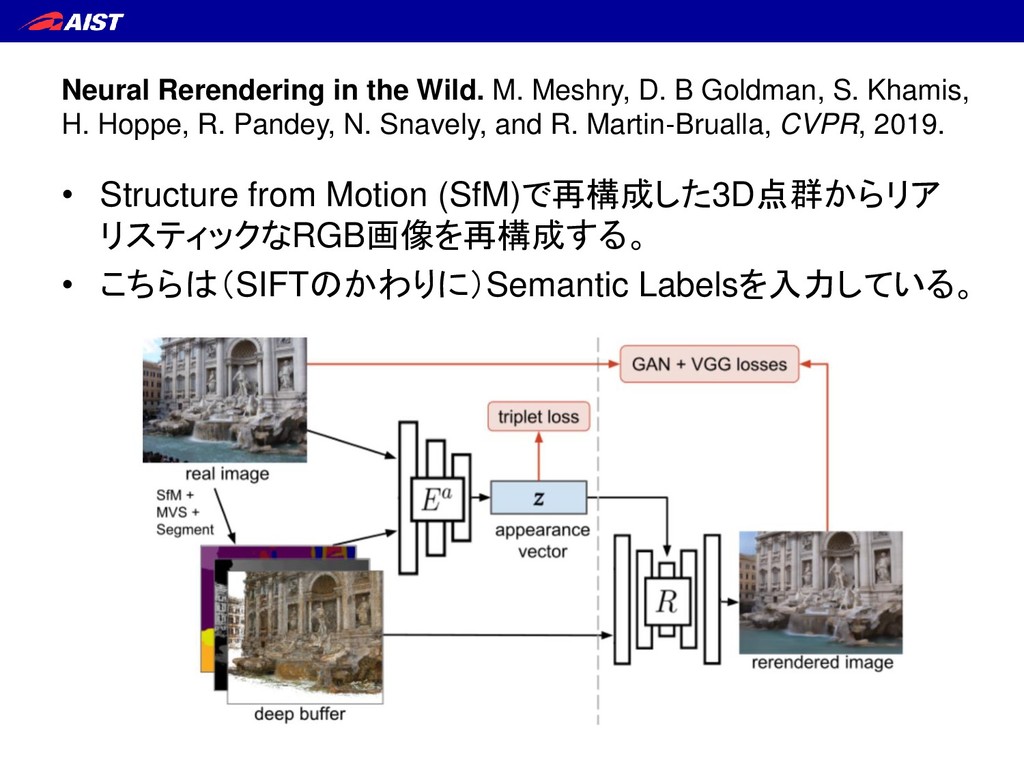
S. Khamis, H. Hoppe, R. Pandey, N. Snavely, and R. Martin-Brualla, CVPR, 2019. • Structure from Motion (SfM)で再構成した3D点群からリア リスティックなRGB画像を再構成する。 • こちらは(SIFTのかわりに)Semantic Labelsを入力している。
and Mapping (SLAM)、Registration、etc. ORB-SLAM2: an Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. R. Mur-Artal and J. D. Tardós, IEEE Trans. on Robotics, 2017.
Depth Learning from Unknown Cameras” – by Kazuyuki Miyazawa, AI R&D Researcher, DeNA https://www.slideshare.net/KazuyukiMiyazawa/depth-from-videos-in-the-wild- unsupervised-monocular-depth-learning-from-unknown-cameras-167891145
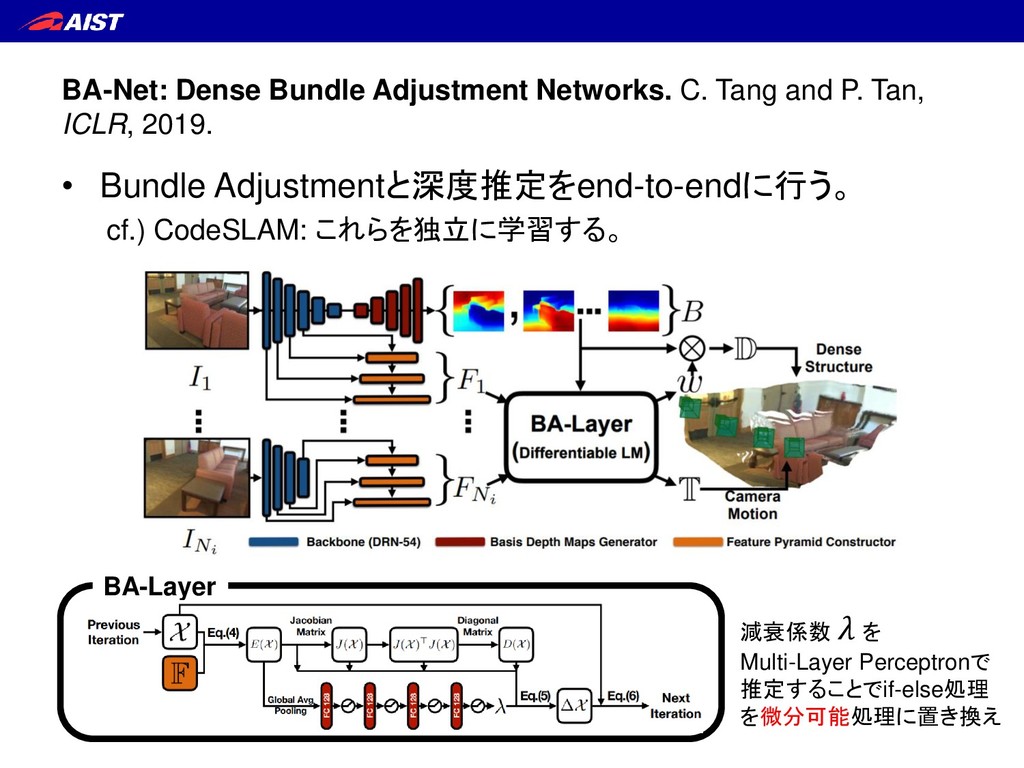
Visual SLAM (3D勉強会@関 東)” – by Mai Nishimura, Research Engineer at OMRON SINIC X https://www.slideshare.net/MaiNishimura2/banet-dense-bundle-adjustment- network-3d • “BA-Net: Dense Bundle Adjustment Network (3D勉強会 @関東)” – by Mai Nishimura, Research Engineer at OMRON SINIC X https://www.slideshare.net/MaiNishimura2/codeslam-learning-a-compact- optimisable-representation-for-dense-visual-slam-3d
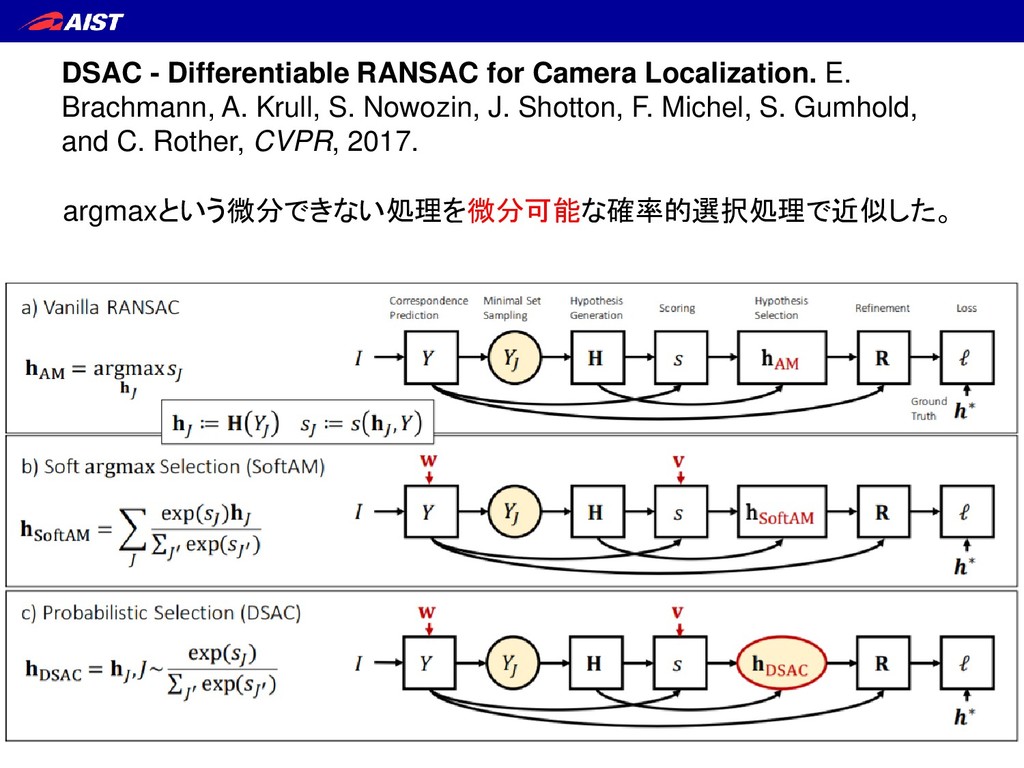
Krull, S. Nowozin, J. Shotton, F. Michel, S. Gumhold, and C. Rother, CVPR, 2017. • 全てのRGB画像の画素に対応する“Scene coordinates”を推定する。 ←CNNを使う • RANSAC DSACでカメラ位置姿勢を推定する。 微分可能レイヤー
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
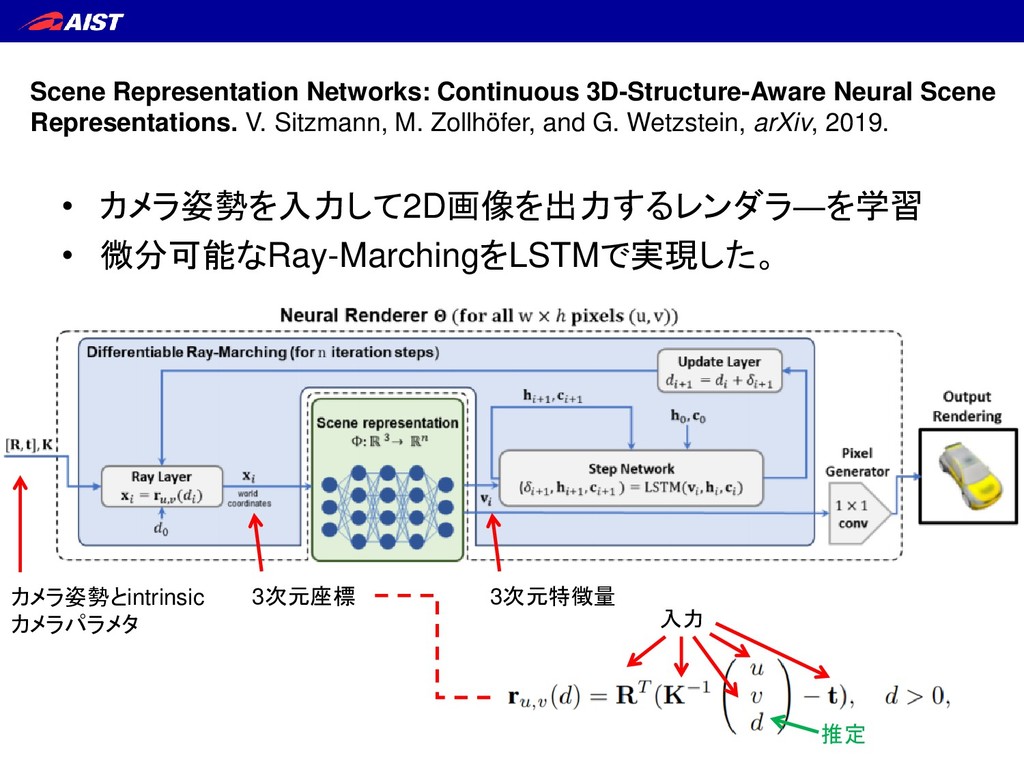{kind=link}
{kind=link}
{kind=link}
{kind=link}
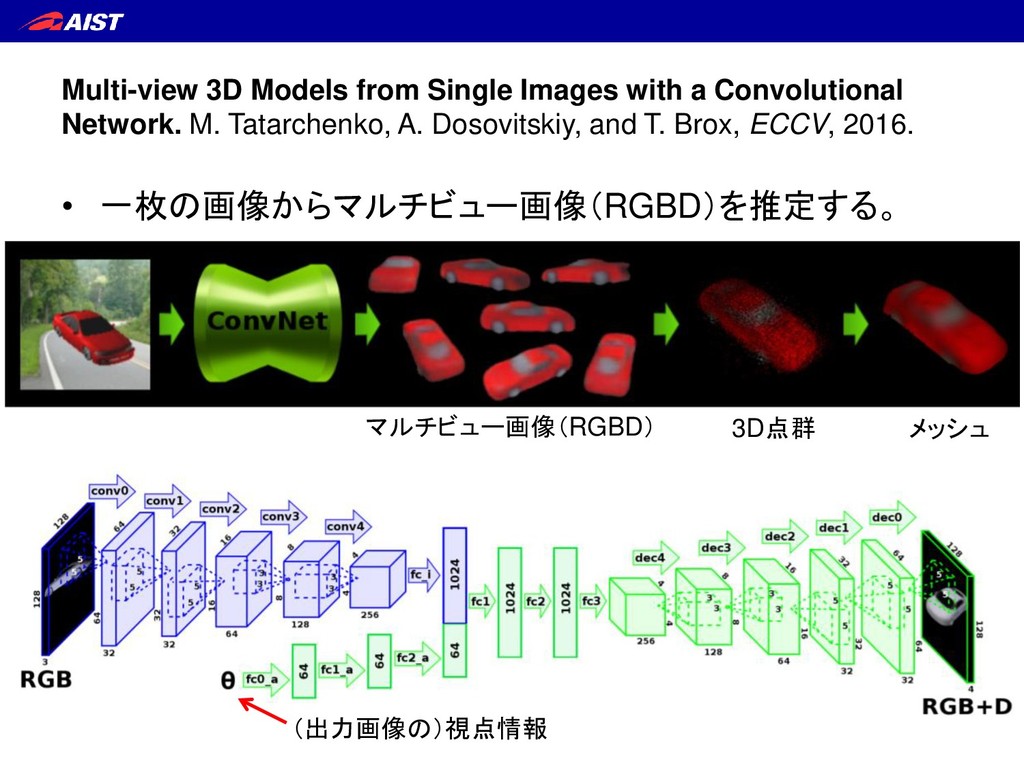{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}