A. Vyssotsky. Such systems must run continuously and reliably 7 days a week, 24 hours a day and must be capable of meeting wide service demands. Because the system must ultimately be comprehensive and able to adapt to unknown future requirements, its framework must be general, and capable of evolving over time.
på genskabelse af selvsamme ved fejl. Soft state, which can be regenerated at the expense of additional computation or file I/O, is exploited to improve performance; data is not durable.
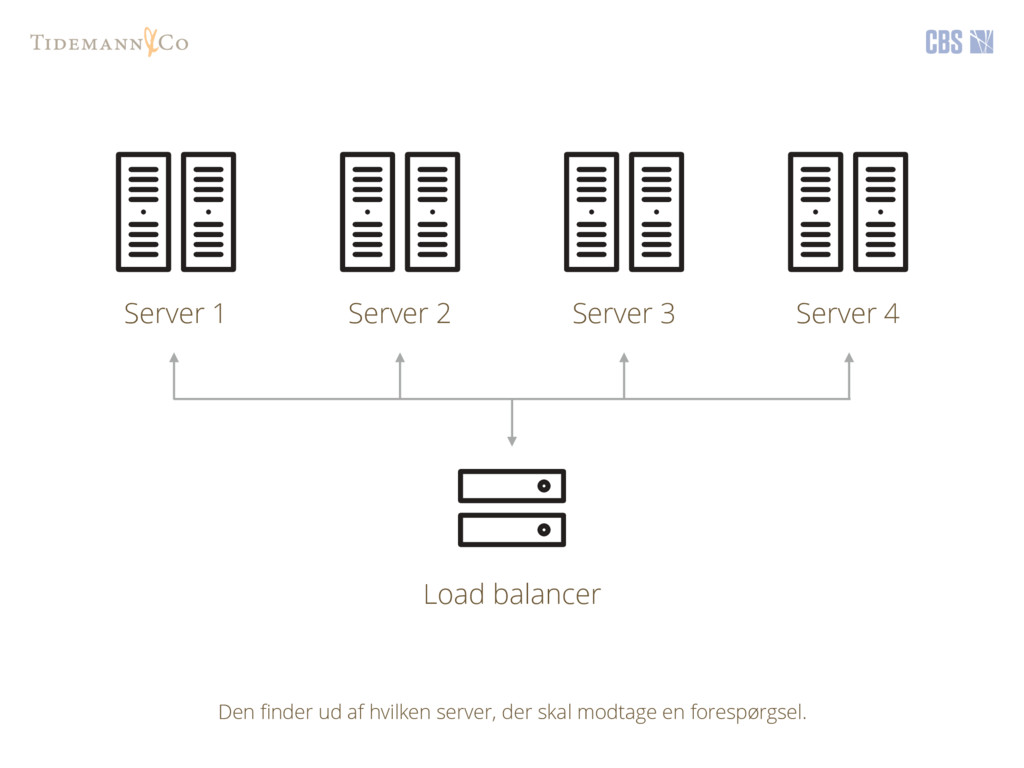
data flere forskellige steder og dermed gøre data tilgængeligt fra forskellige kilder. Det er evnen til at håndtere fejl, når tingene går ned. For det gør de - ofte!
den mest simple form for scheduling, hvor instruktioner afvikles i den rækkefølge, som de modtages i. Shortest-Remaining-Time afvikler instruktioner, der tager kortest tid, først. Det kan resultere i starvation af længerevarende processer. Round-Robin giver alle instruktioner en del af den samlede CPU- tid. Hvis en instruktion ikke når at blive færdig indenfor tidsrammen, så går turen videre til den næste.
operation called record append. In a traditional write, the client specifies the offset at which data is to be written. [..] In a record append, however, the client specifies only the data. GFS appends it to the file at least once atomically (i.e., as one continuous sequence of bytes) at an offset of GFS’s choosing [..]. This is similar to writing to a file opened in O_APPEND mode in Unix without the race conditions when multiple writers do so concurrently.
{kind=link}
![[email protected]. Skriv til mig, hvis I har brug for hjælp.](https://files.speakerdeck.com/presentations/e679d1f8707047e595c8760f5fccbe8a/slide_1.jpg){kind=link}
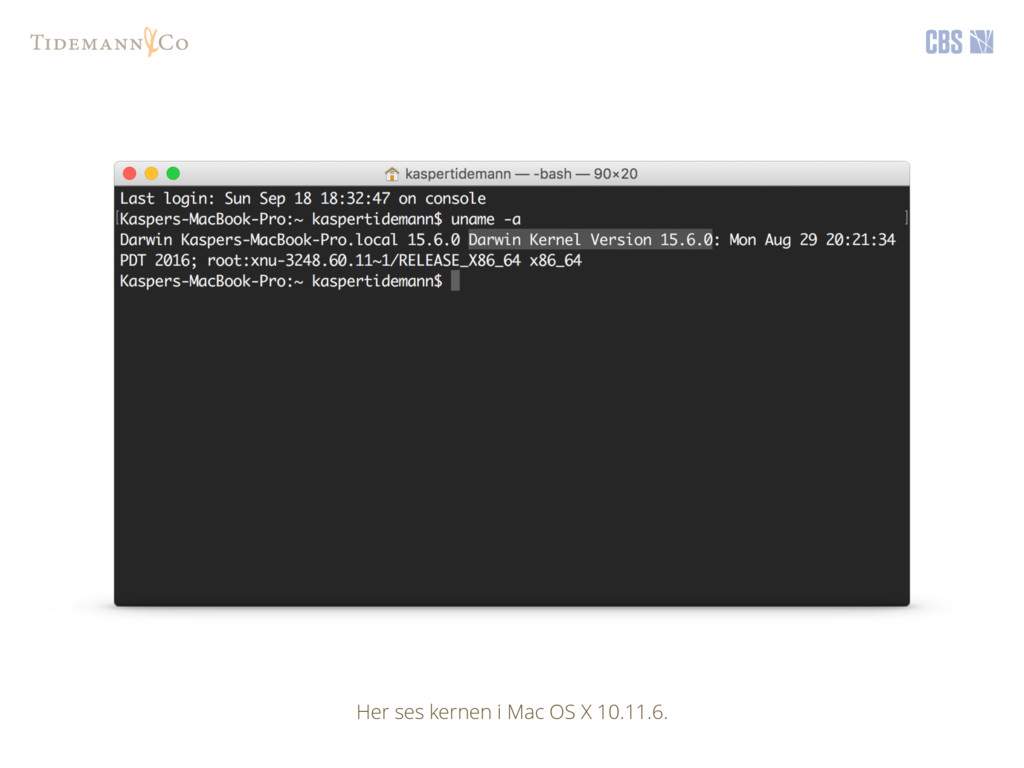{kind=link}
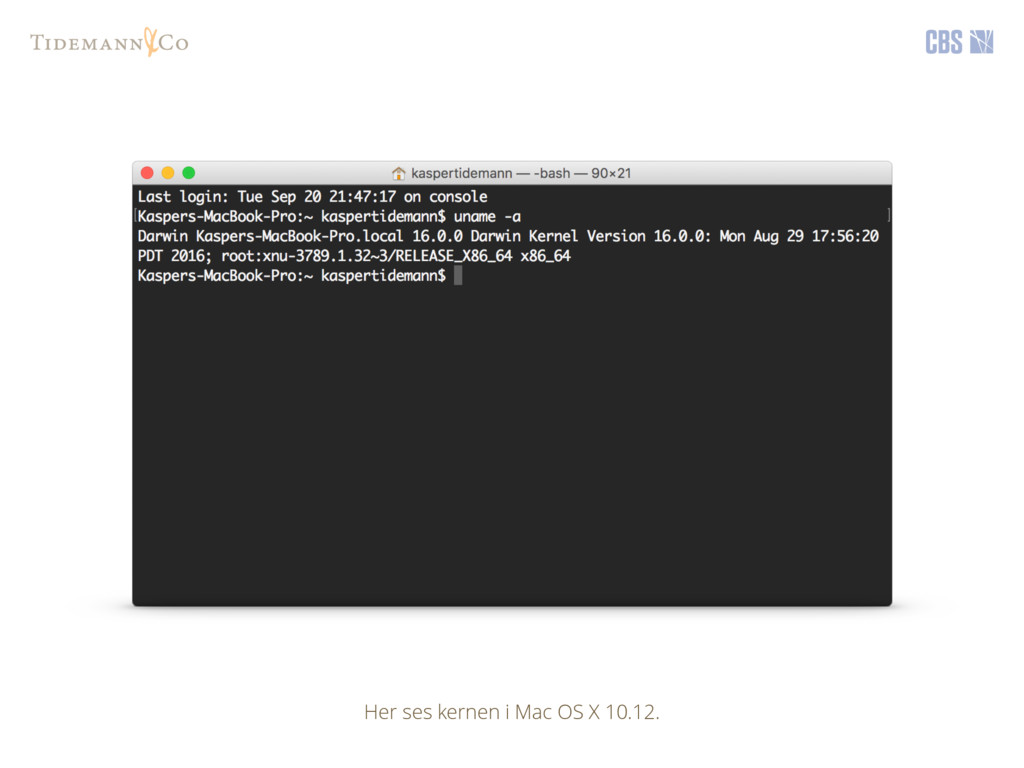{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
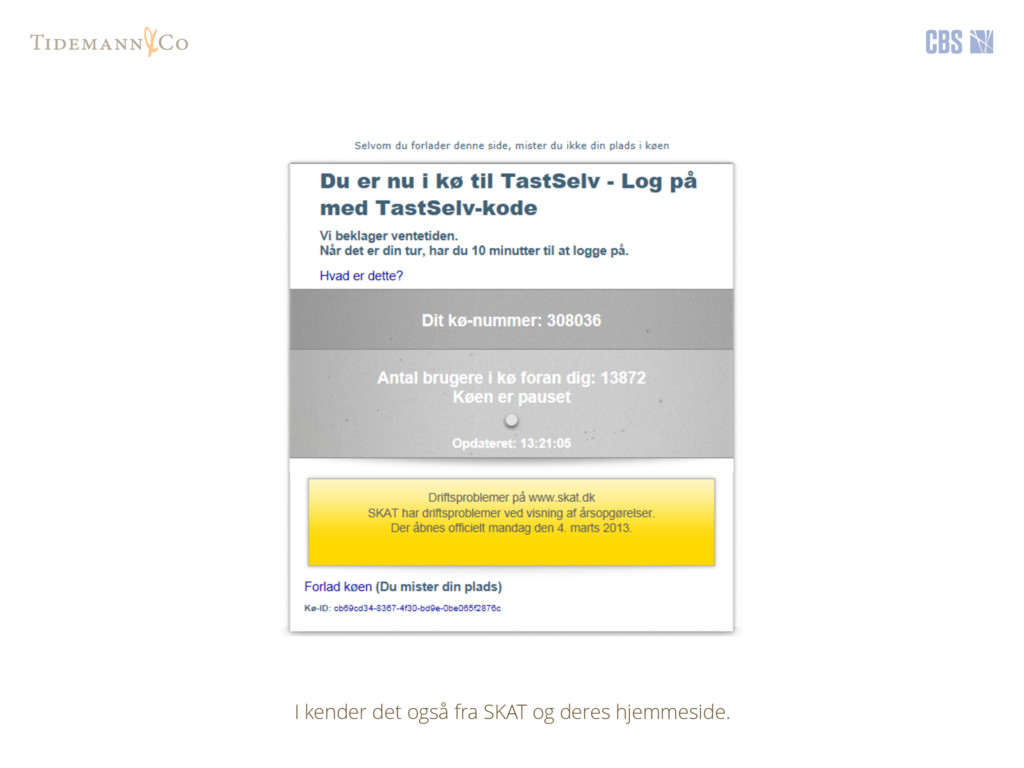{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
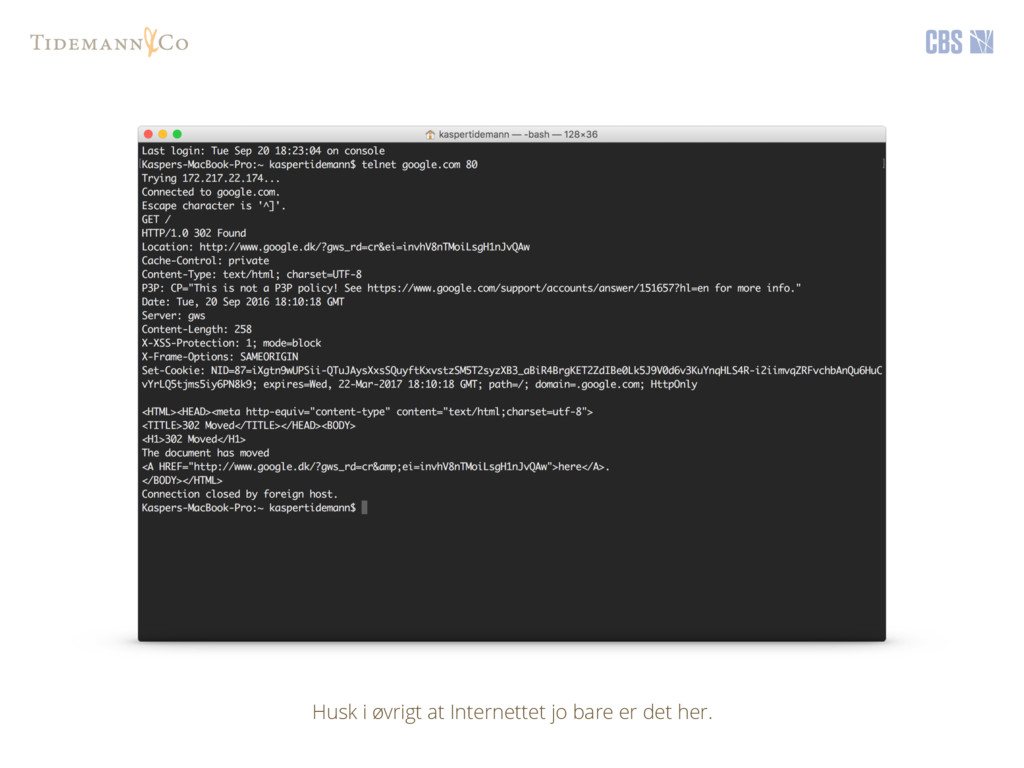{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}