Translation Models. Kalchbrenner and Blunsom, EMNLP 2013 • On the Properties of Neural Machine Translation: Encoder–Decoder Approaches . Cho et al., SSST 2014 • Neural Machine Translation in Linear Time. Kalchbrenner et al., arXiv 2016 • Convolutional Encoders for Neural Machine Translation. Lamb and Xie, 2016 ◦ (https://cs224d.stanford.edu/ reports/LambAndrew.pdf) • Encoding Source Language with Convolutional Neural Network for Machine Translation. Meng et al., ACL 2015 • Context-dependent Translation selection using Convolutional Neural Network. Tu et al., ACL-IJCNLP 2015 • Edinburgh neural machine translation systems for wmt 16. Sennrich et al., WMT16 2016 • Schwenk 2014 ◦ (http://www-lium. univ-lemans.fr/ ̃schwenk/cslm_joint_ paper/) • A Simple, Fast, and Effective Reparameterization of IBM Model 2. Dyer et al., ACL 2013 18
{kind=link}
{kind=link}
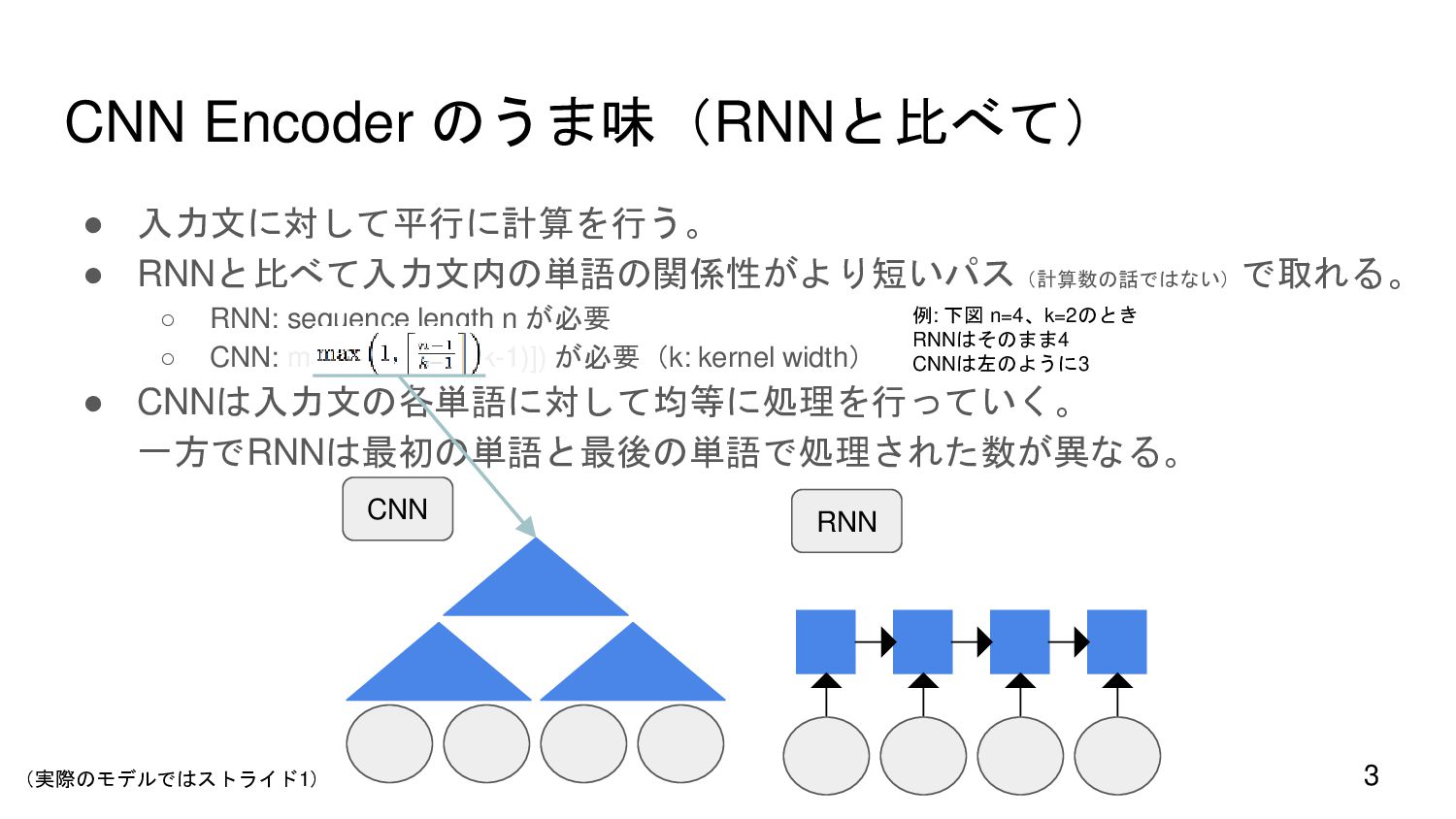{kind=link}
{kind=link}
{kind=link}
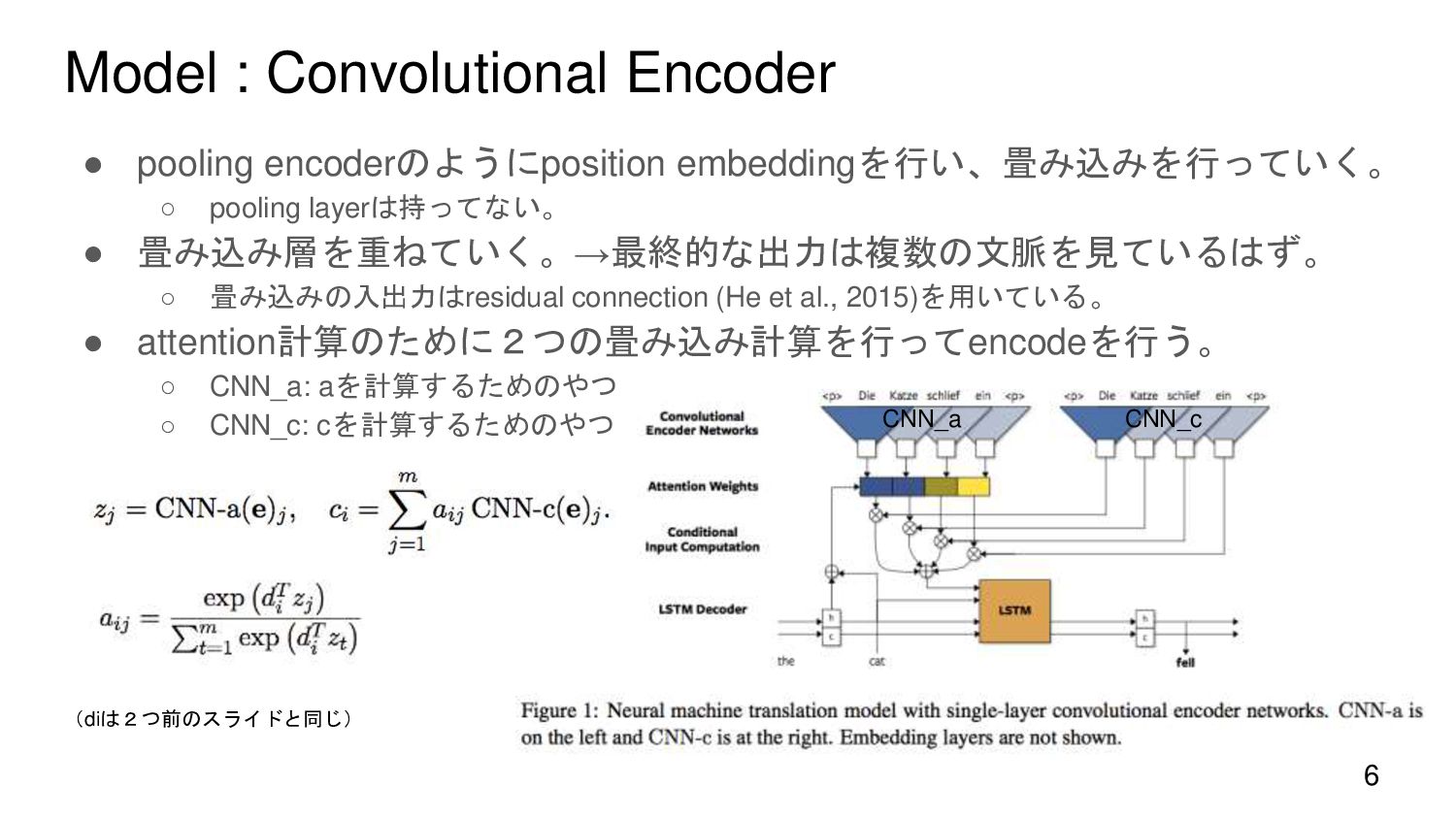{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
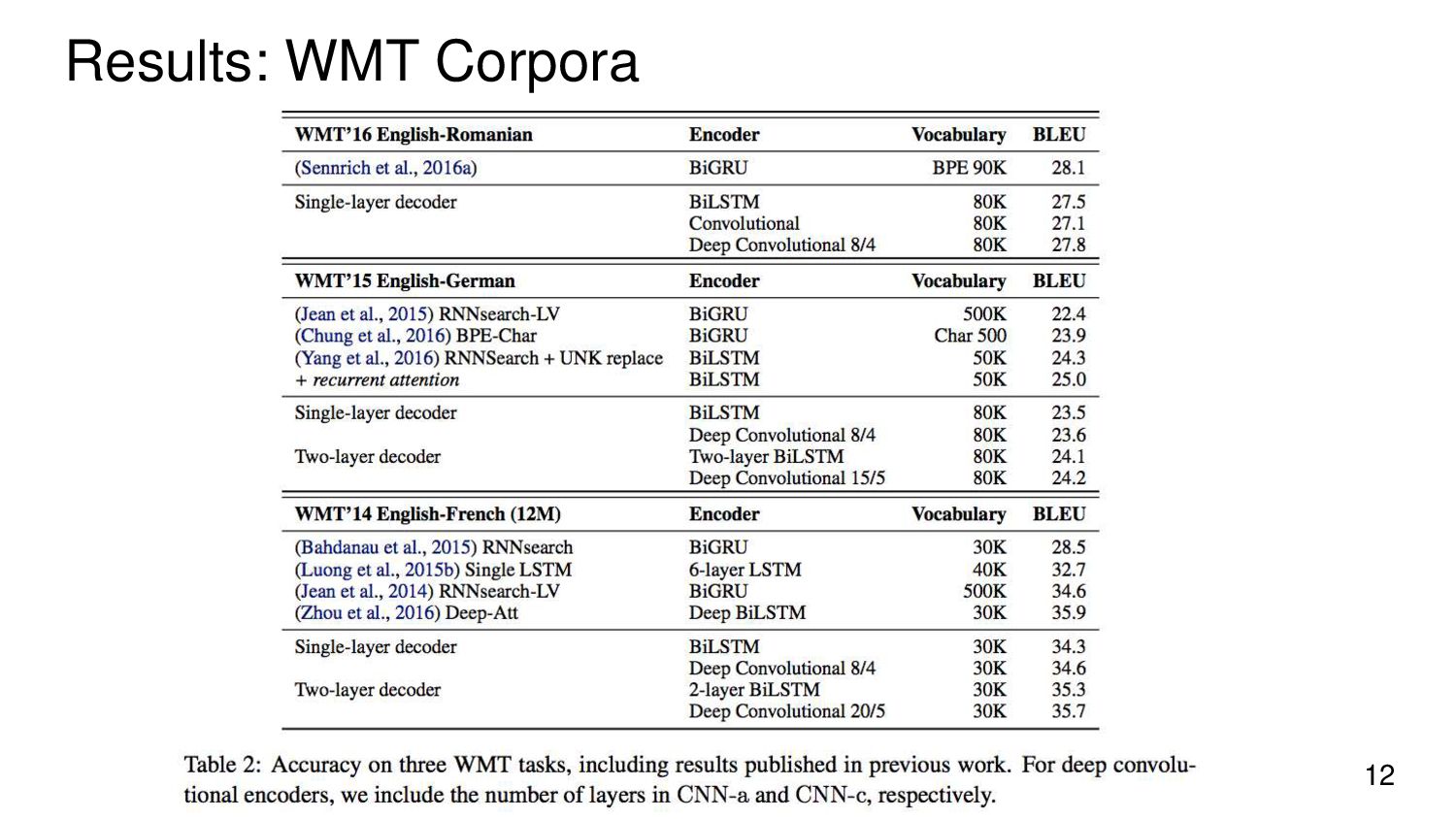{kind=link}
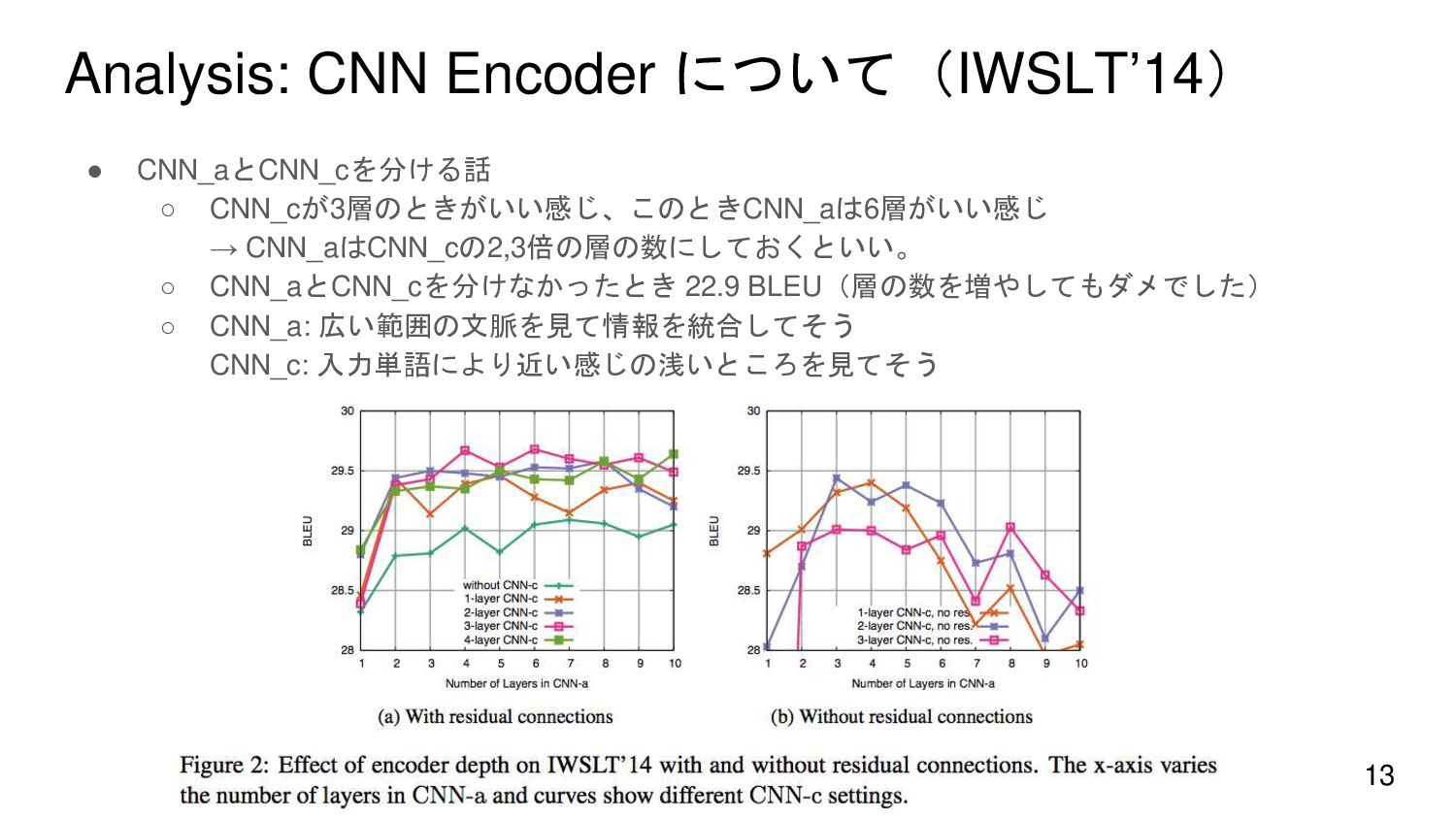{kind=link}
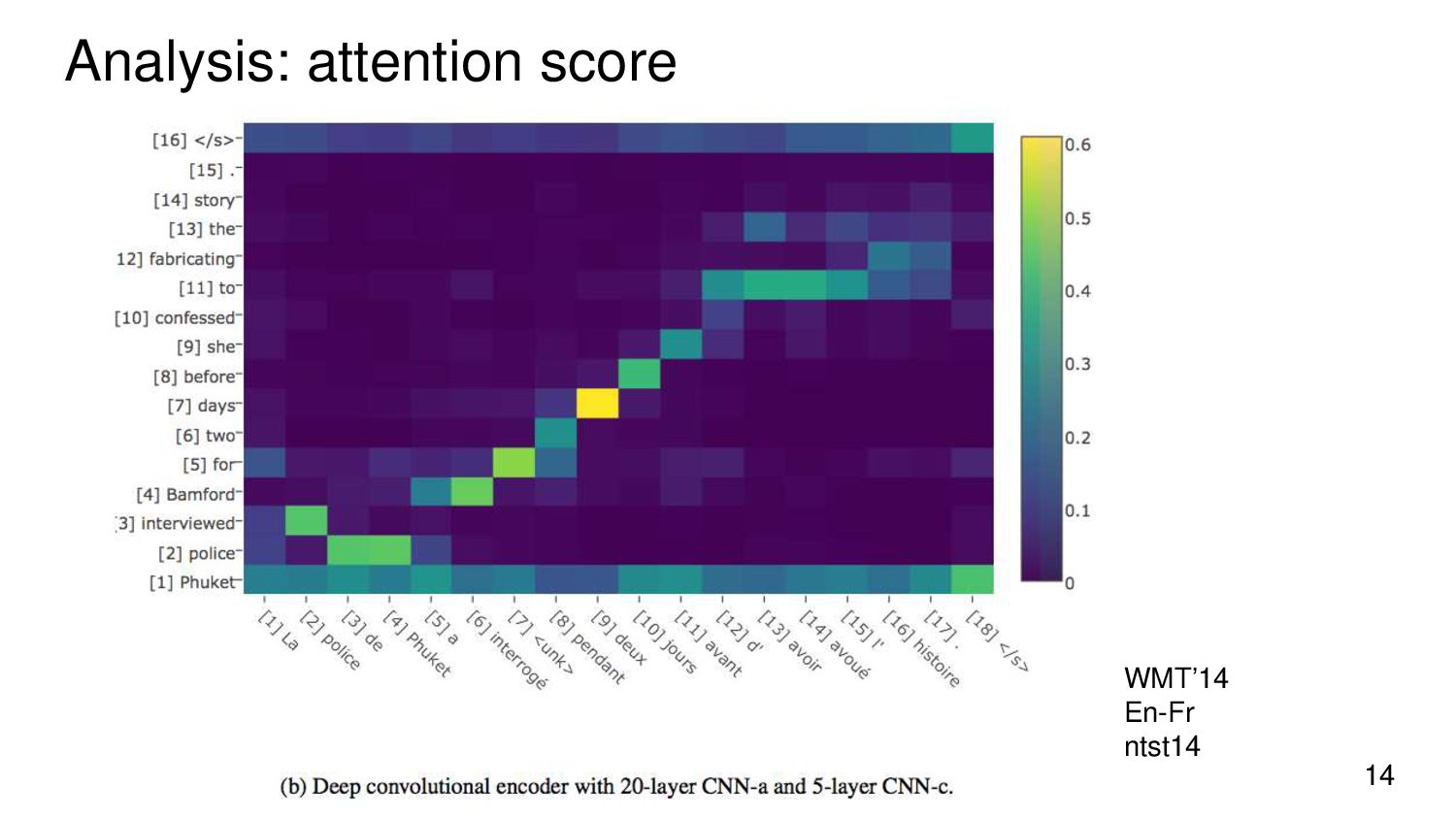{kind=link}
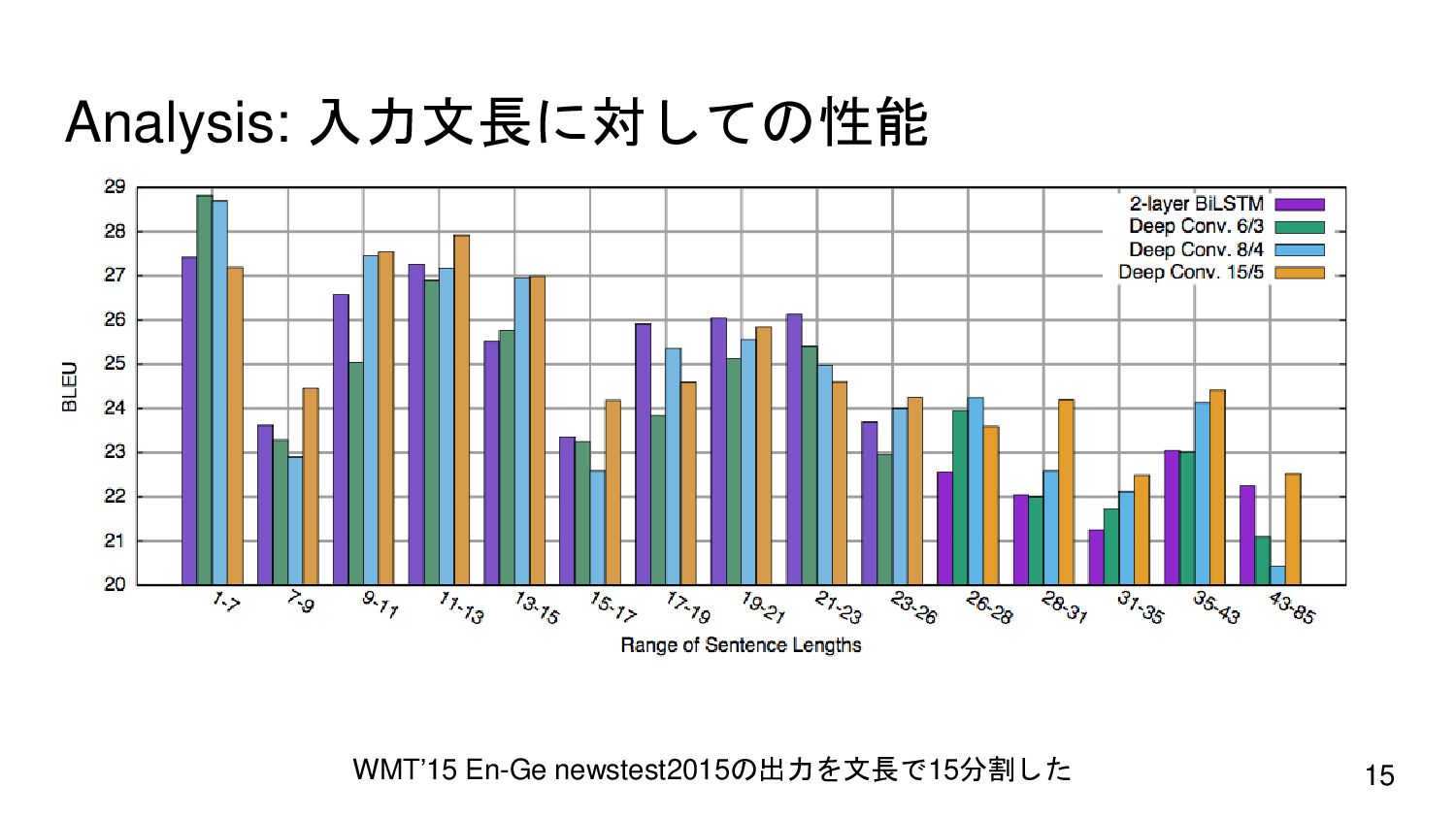{kind=link}
{kind=link}
{kind=link}
{kind=link}