• Natural language inference by tree-based convolution and heuristic matching. Mou et al., ACL 2016 • A Fast Unified Model for Parsing and Sentence Understanding. Bowman et al., ACL 2016 • Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. Conneau et al., EMNLP 2017 • DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding. Shen et al., arXiv 2017 • Reinforced mnemonic reader for machine comprehension. Hu et al., arXiv 2017 • Attention is all you need. Vaswani et al., NIPS 2017 • A structured self-attentive sentence embedding. Lin et al., ICLR 2017 • Learning natural language inference using bidirectional lstm model and inner-attention. Liu et al., arXiv 2016 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
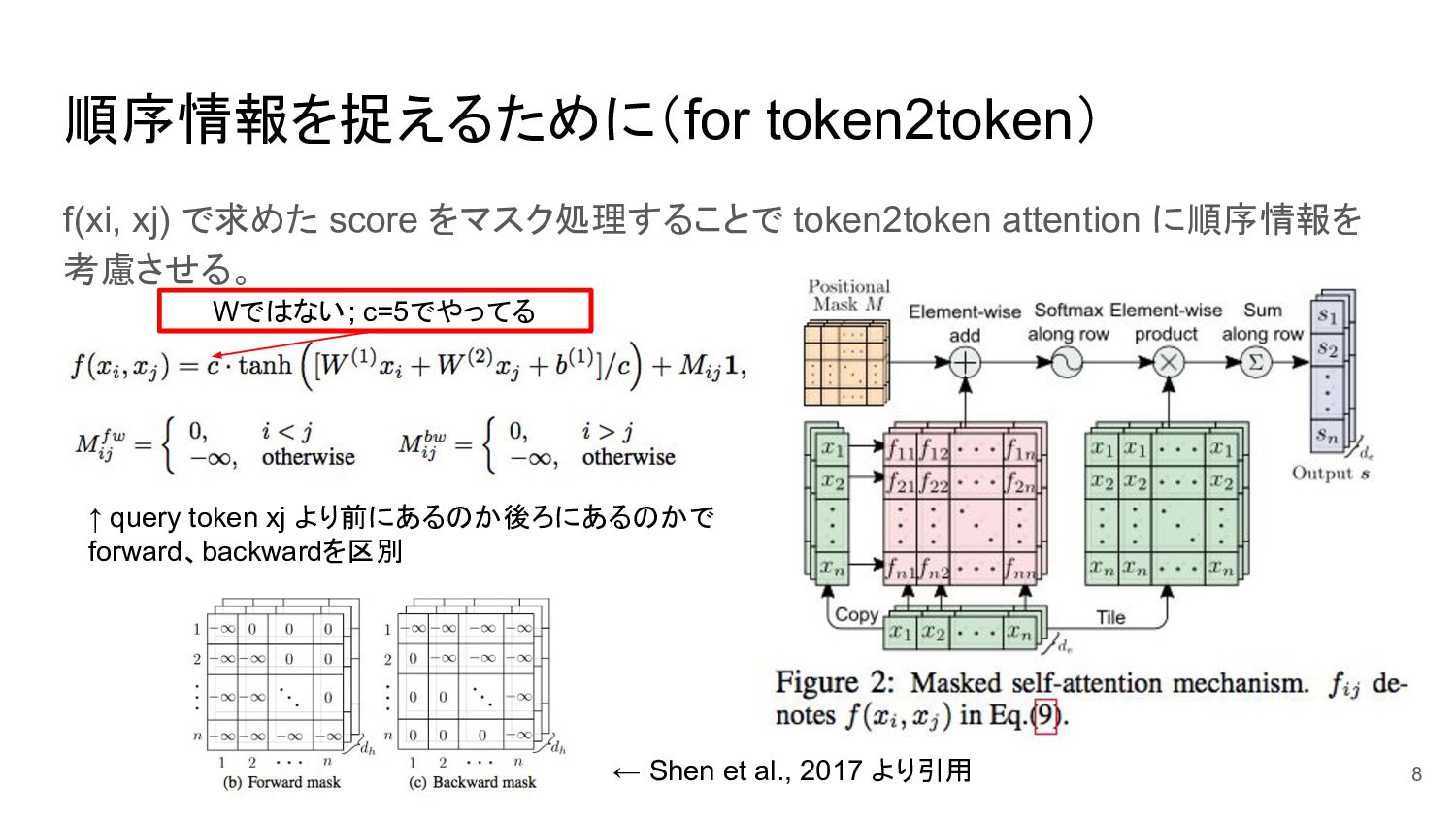{kind=link}
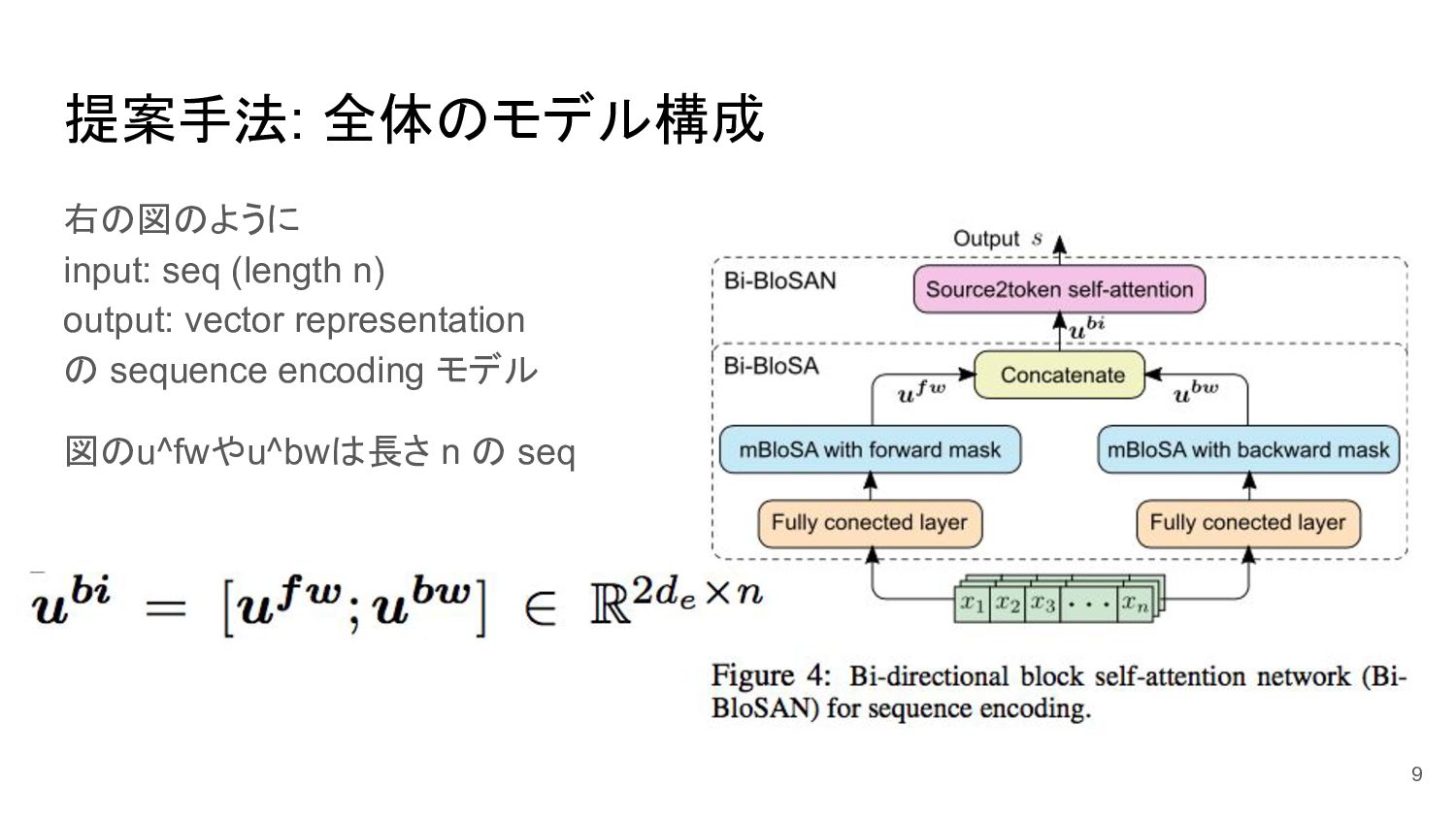{kind=link}
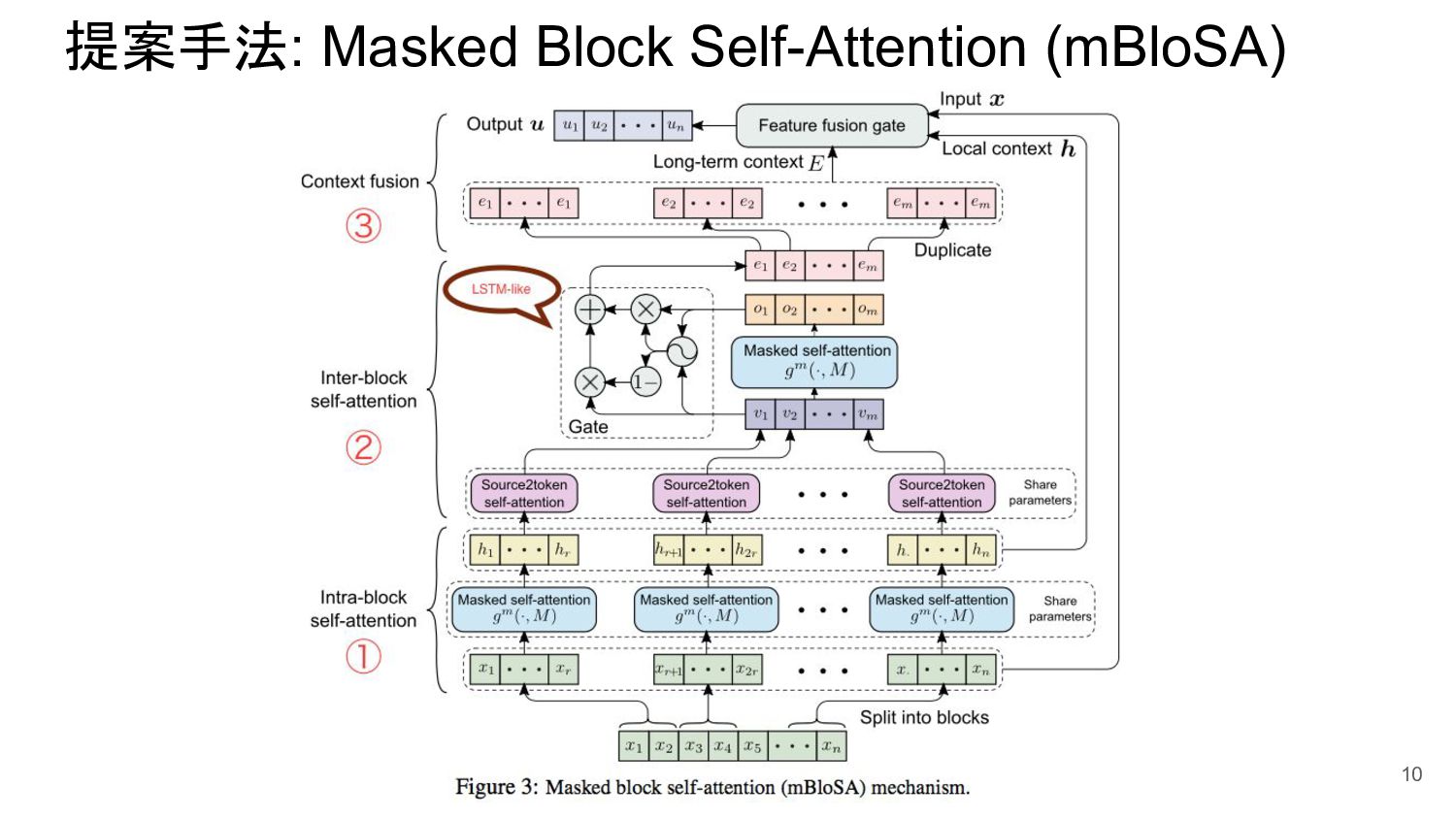{kind=link}
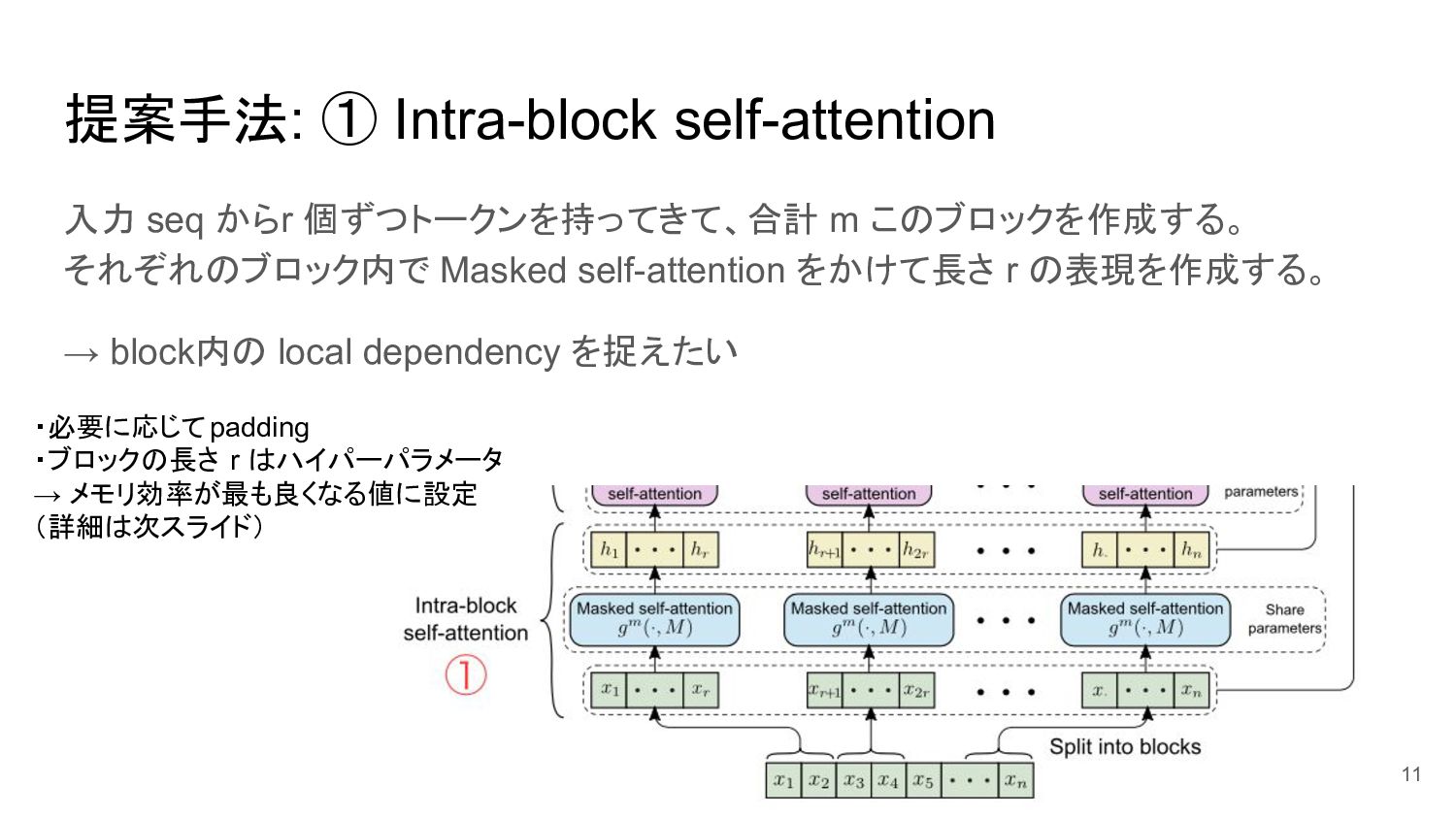{kind=link}
{kind=link}
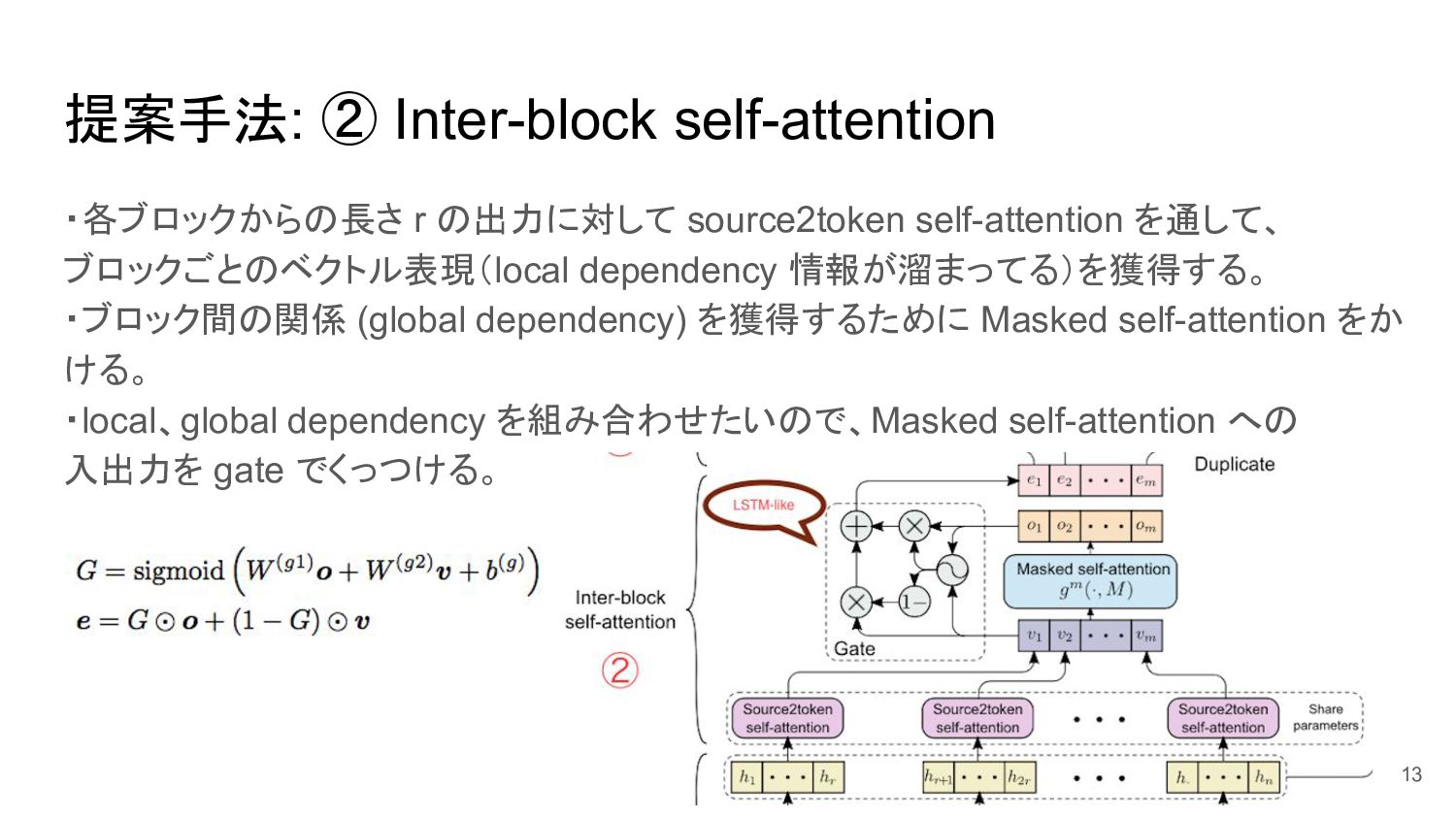{kind=link}
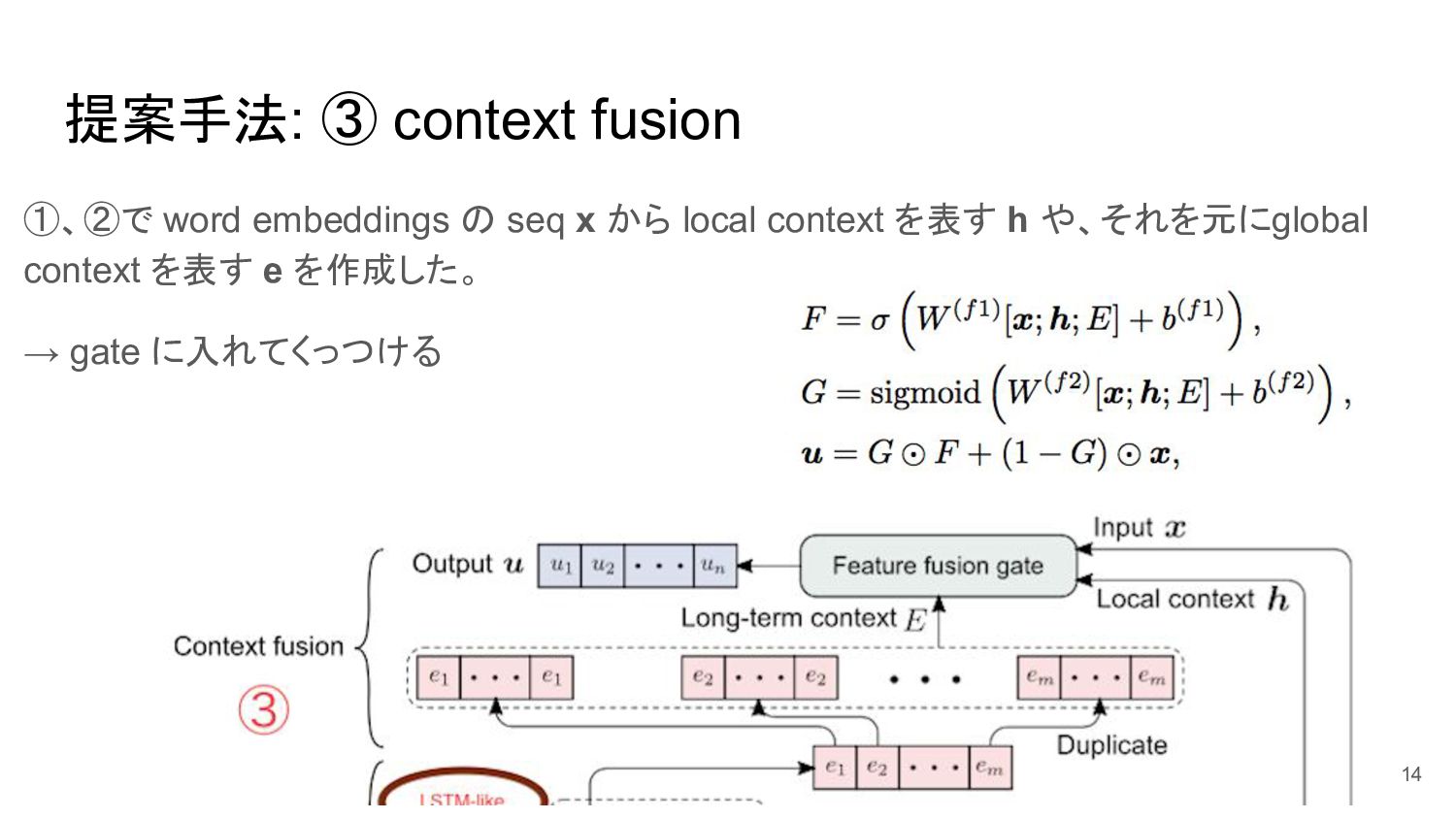{kind=link}
{kind=link}
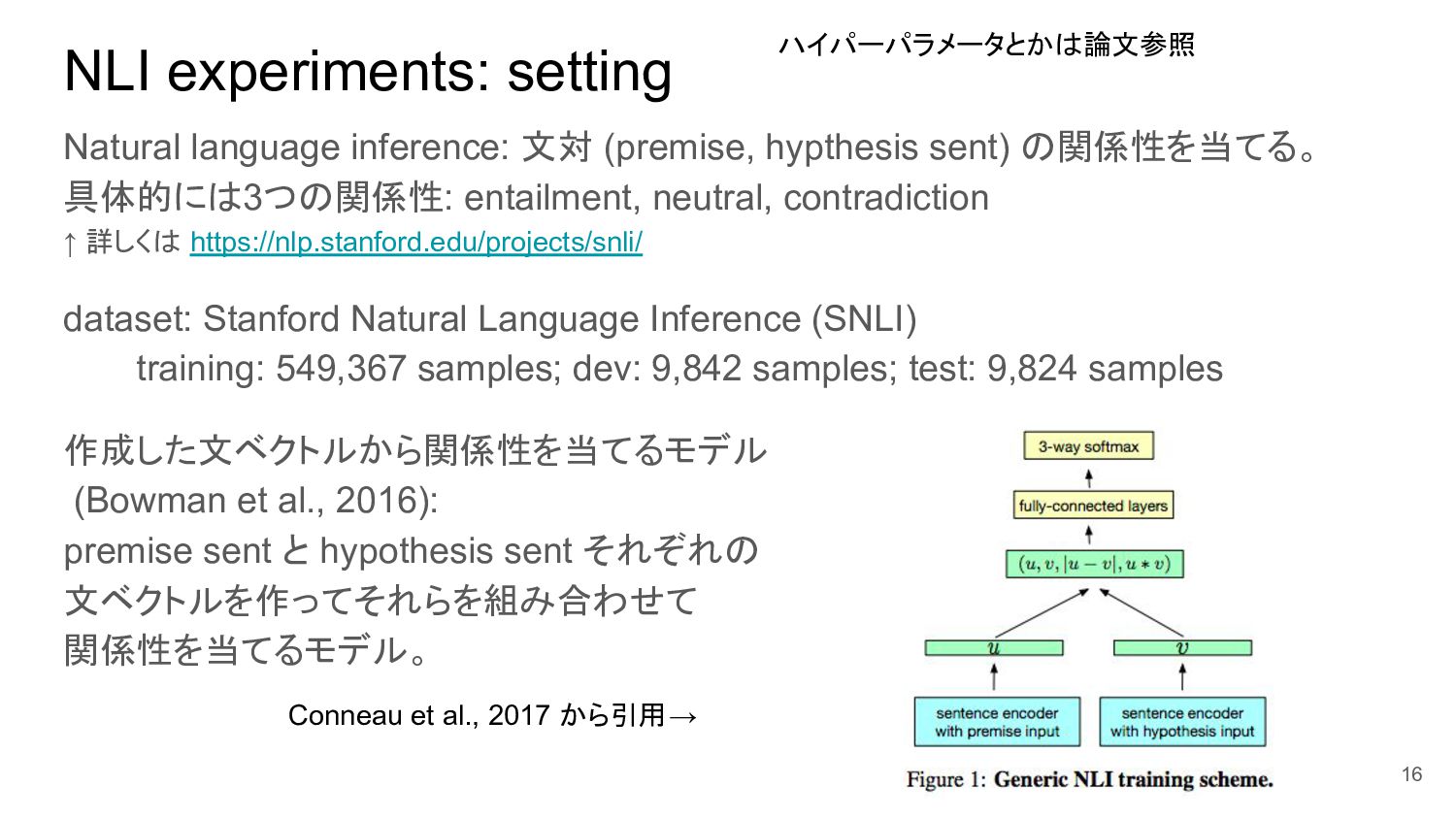{kind=link}
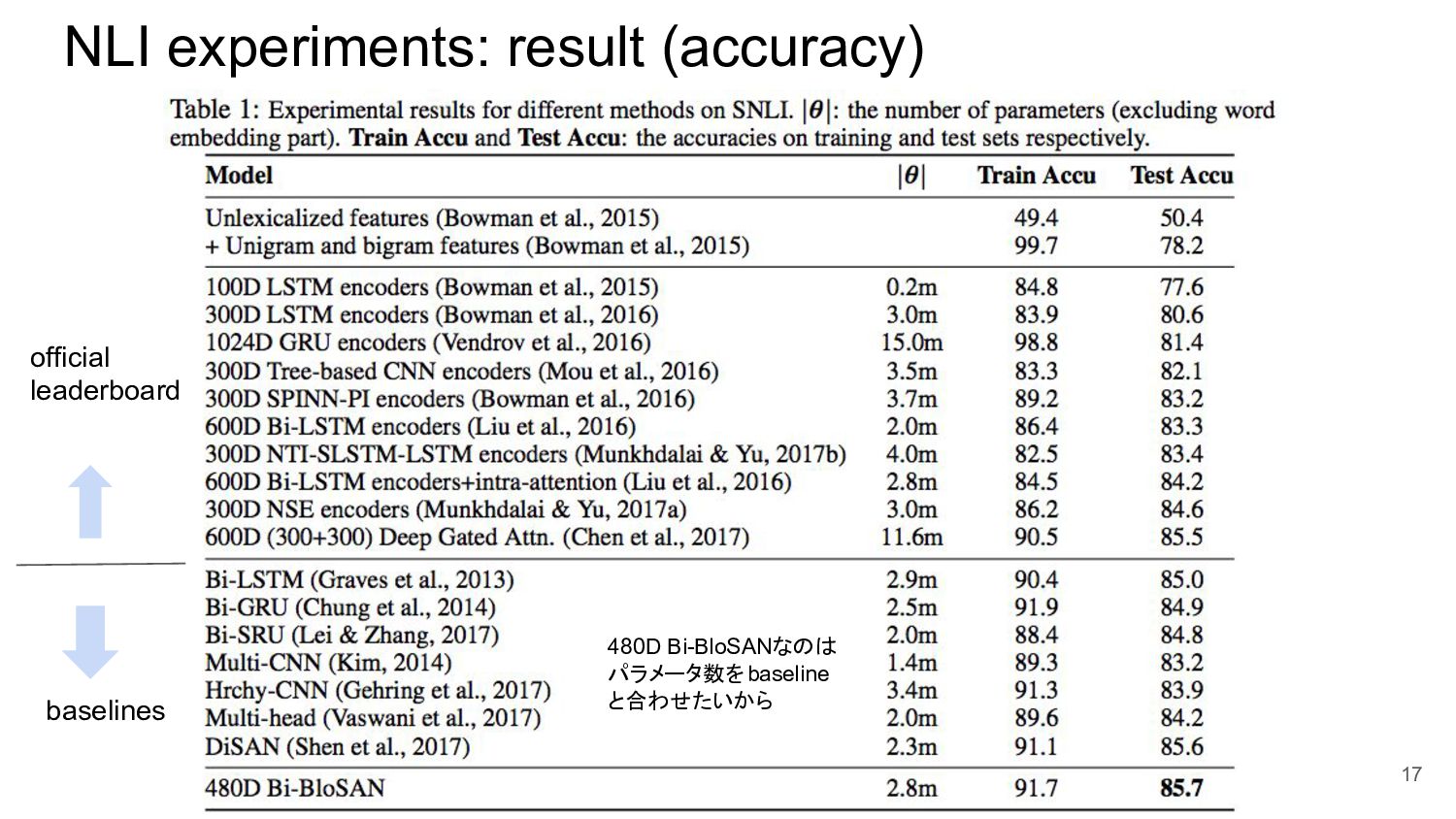{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}