from severe gradient diffusion. ◦ due to the non-linear recurrent activations, which often make the optimization much more difficult. • we propose novel linear associative units (LAU). ◦ reduce the gradient path inside the recurrent units • experiment ◦ NIST task: Chinese-English ◦ WMT14: English-German English-French • analysis ◦ LAU vs. GRU ◦ Depth vs. Width ◦ about Length 2
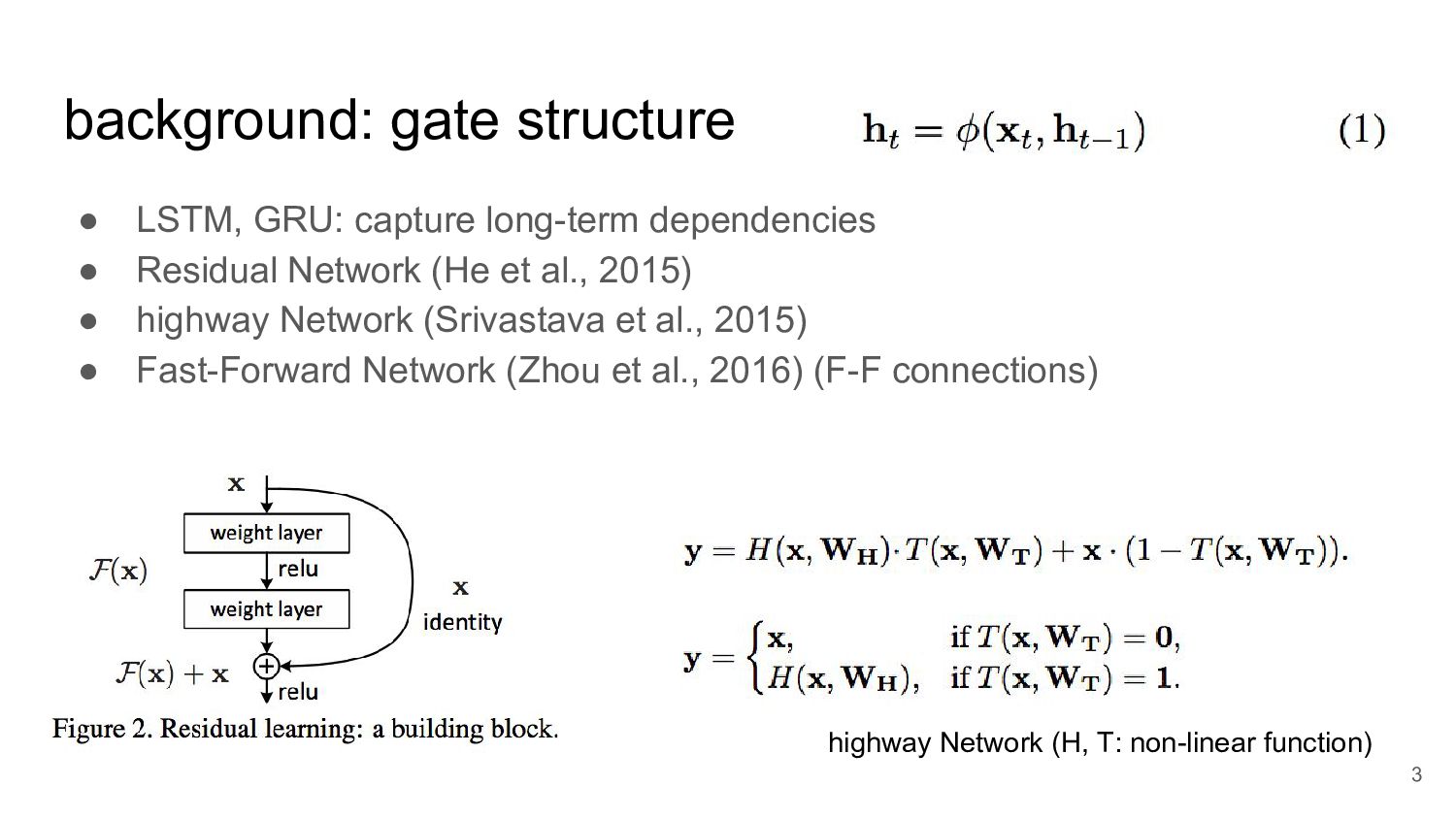
an additional linear transformation of the input. f_t and r_t express how much of the non-linear abstraction are preduced by the input x_t and previous hidden state h_t. g_t decides how much of the linear transformation of the input is carried to the hidden state. GRU 5
for input x_t to go to latter hidden state layers. This mechanism is very useful for translation where the input should sometimes be directly carried to the next stage of processing without any substantial composition or nonlinear transformation. ex. imagine we want to translate a rare entity name such as ‘Bahrain’ to Chinese. → LAU is able to retain the embedding of this word in its hidden state. Otherwise, serious distortion occurs due to lack of training instances. 6
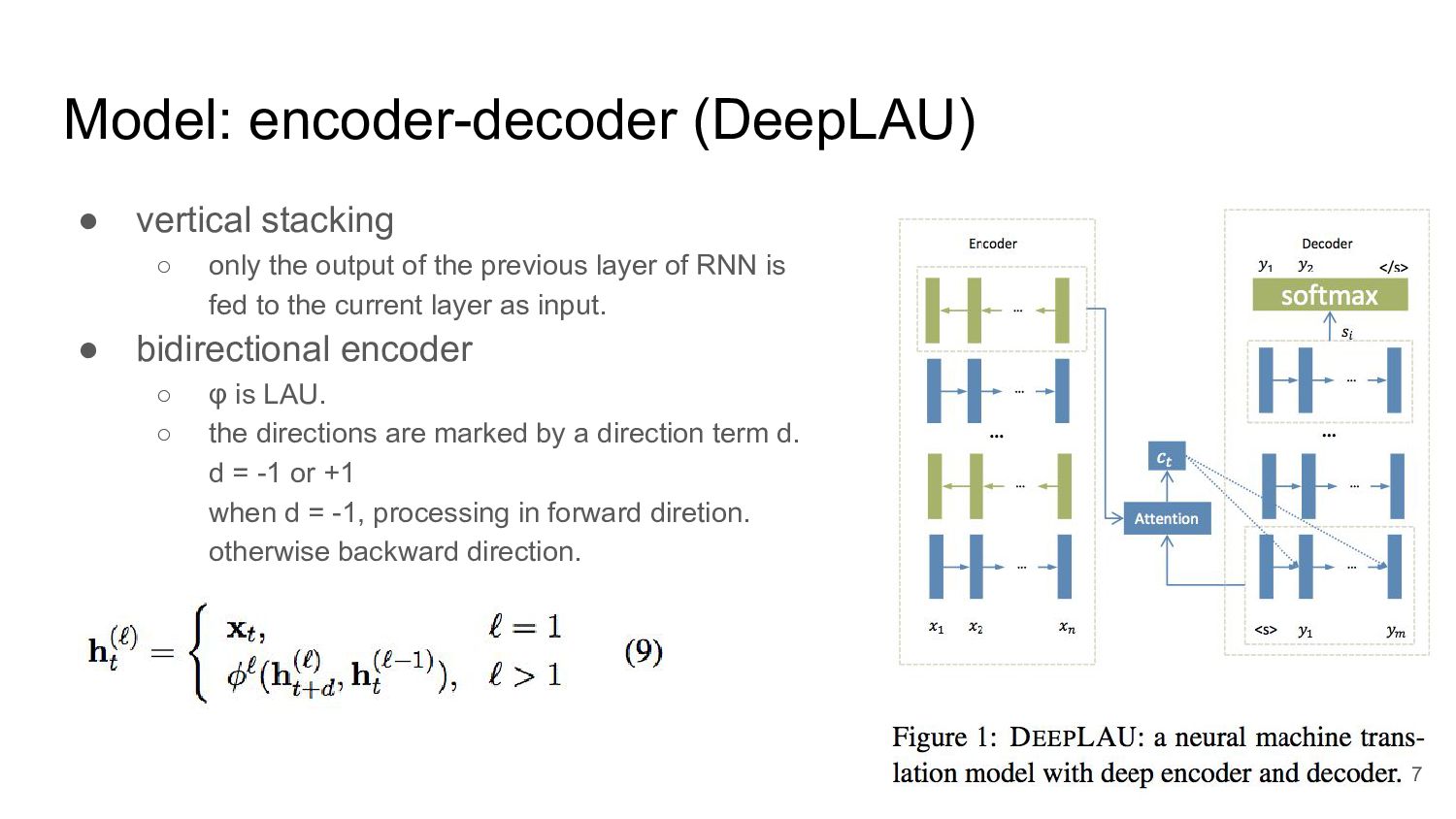
of the previous layer of RNN is fed to the current layer as input. • bidirectional encoder ◦ φ is LAU. ◦ the directions are marked by a direction term d. d = -1 or +1 when d = -1, processing in forward diretion. otherwise backward direction. 7
dependencies, they choose unusual bidirectional approach. • encoding ◦ an RNN layer processes the input sequence in forward direction. ◦ the output of this layer is taken by an upper RNN layer as input, processed in reverse direction. ◦ Formally, following Equation (9), they set d = (-1)^ℓ ◦ the final encoder consists of Lenc layers and produces the output 8
direction term d = -1. At the first layer, they use the following input: At inference stage, they only utilize the top-most hidden state s(Ldec ) to make the final predication with a softmax layer: yt-1 is the target word embedding 10
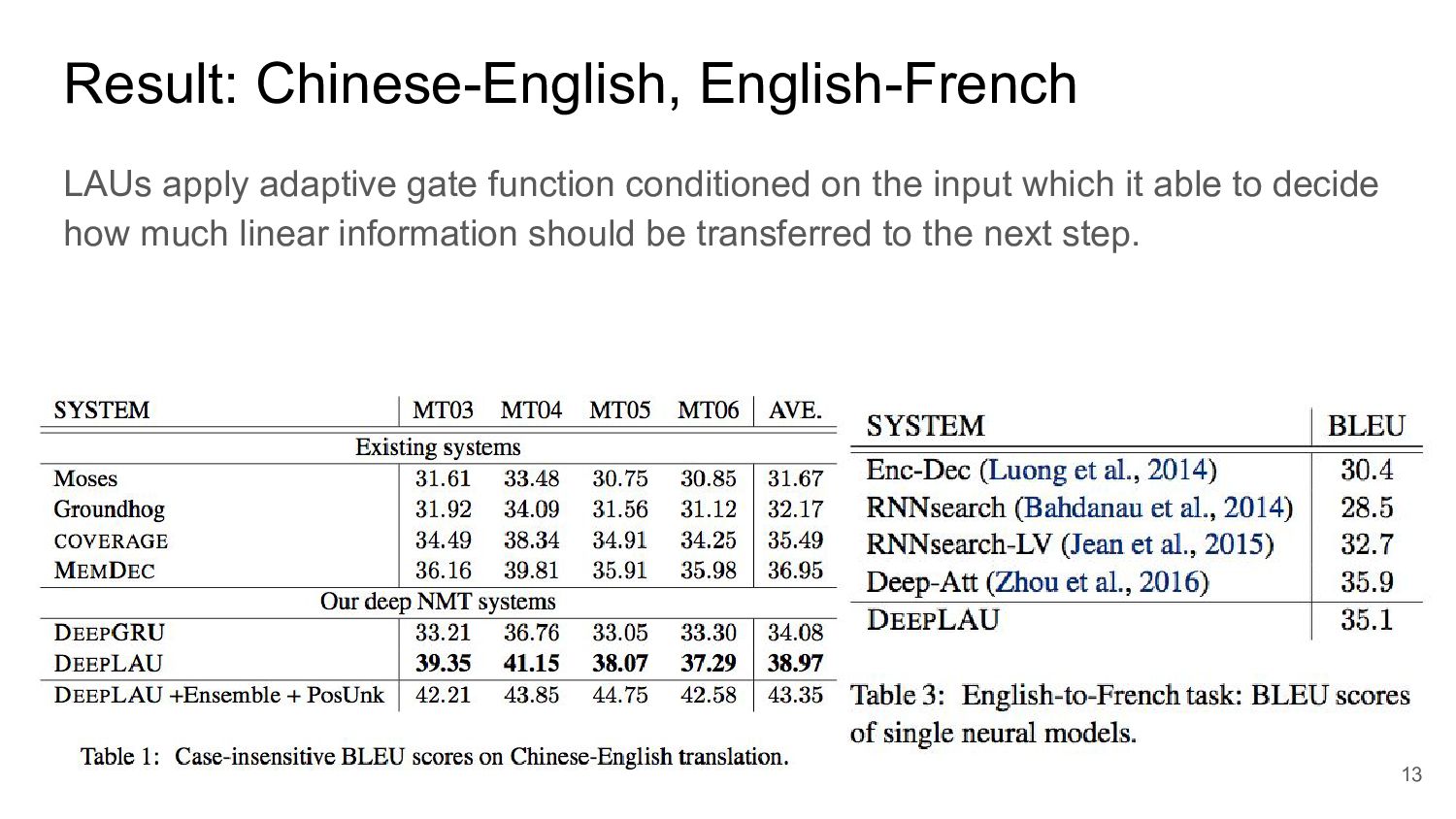
sents, 27.9M Chinese words and 34.5M English words ◦ dev: NIST 2002 (MT02) dataset ◦ test: NIST 2003 (MT03), NIST 2004 (MT04), NIST 2005 (MT05), NIST 2006 (MT06) • WMT14 English-German ◦ training: WMT14 training corpus 4.5M sents, 91M English words and 87M German words ◦ dev: news-test 2012, 2013 ◦ test: news-test 2014 • WMT14 English-French ◦ training: subset of WMT14 training corpus 12M sents, 304M English words and 348M French words ◦ dev: concatenation of news-test 2012 and news-test 2013 ◦ test: news-test 2014 11
states and ct are 512 size. ◦ optimizer: Adadelta ◦ batch size: 128 ◦ input length limit: 80 words ◦ beam size: 10 ◦ dropout rate: 0.5 ◦ layer: both encoder and decoder have 4 layers • settings of each experiment ◦ in Chinese-English and English-French, use the soruce and target vocab frequent 30k ◦ for English-German, use the source 120k and the target 80k in order of frequent 12
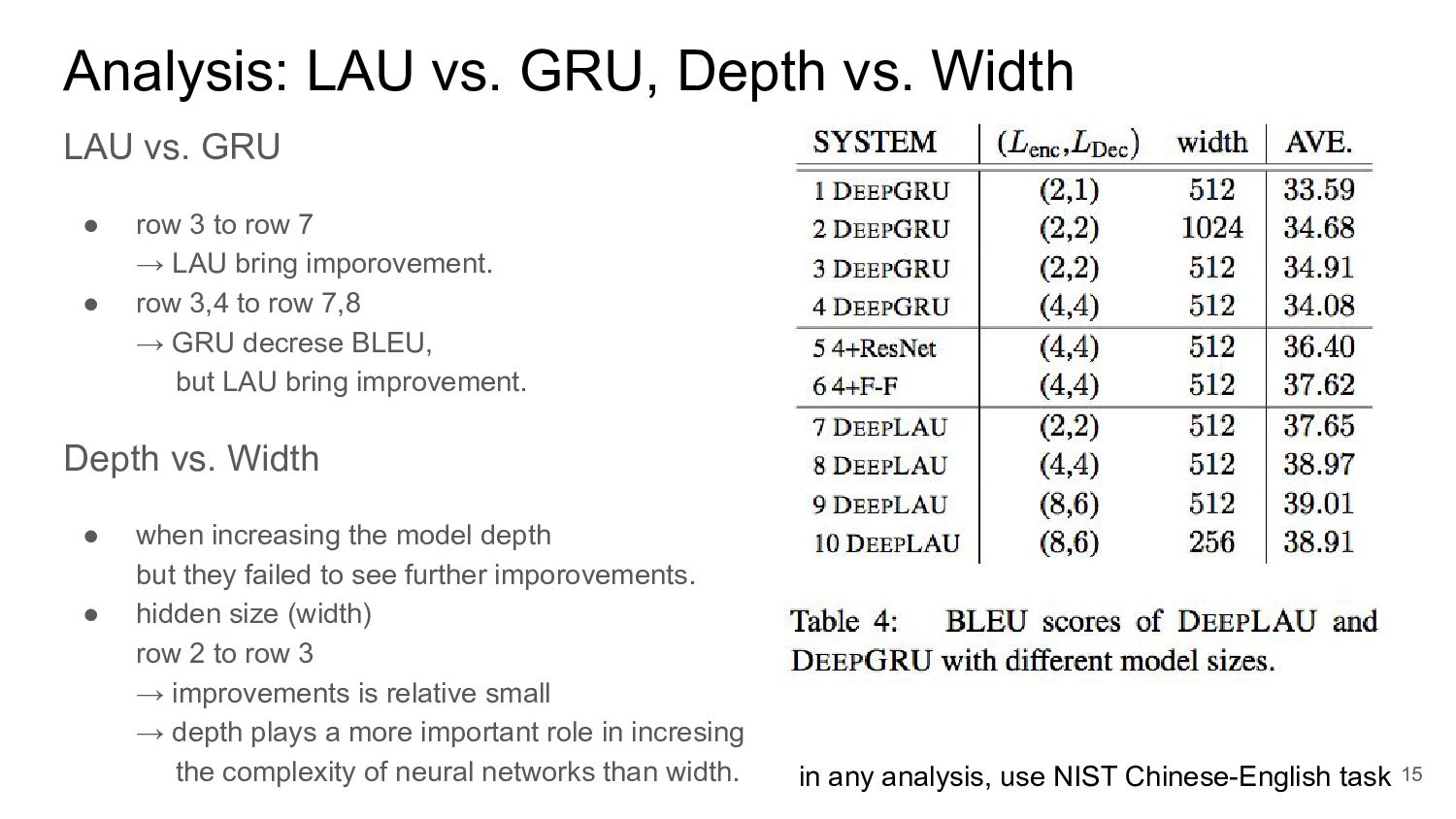
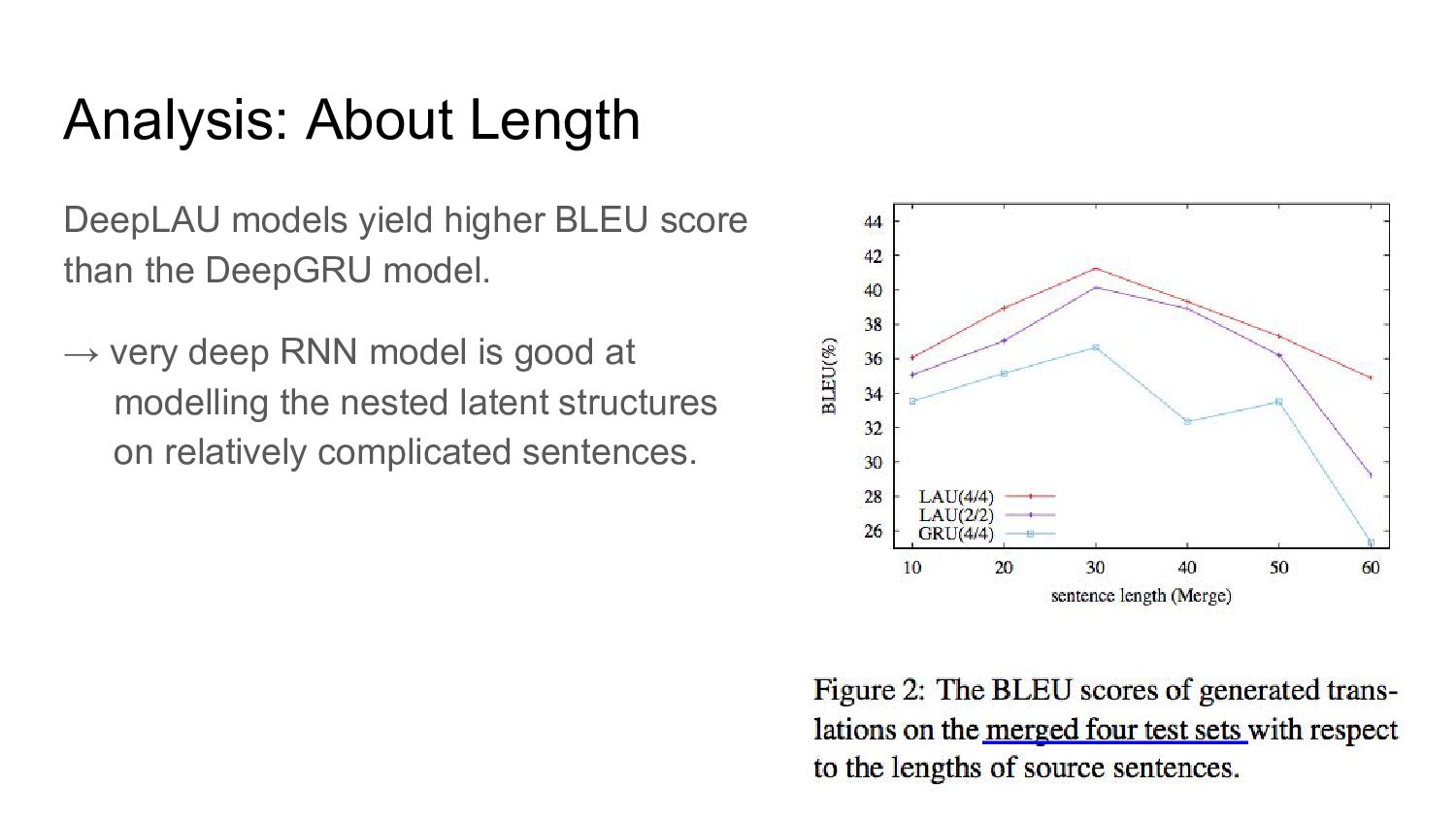
• row 3 to row 7 → LAU bring imporovement. • row 3,4 to row 7,8 → GRU decrese BLEU, but LAU bring improvement. Depth vs. Width • when increasing the model depth but they failed to see further imporovements. • hidden size (width) row 2 to row 3 → improvements is relative small → depth plays a more important role in incresing the complexity of neural networks than width. in any analysis, use NIST Chinese-English task 15
makes a fusion of both linear and nonlinear transformation. • LAU enable us to build a deep neural network for MT. • My feeling ◦ After all, is this model a non-recurrent deep or a recurrent deep? maybe, both are likely to be good… ◦ I was also interested in the weight of the model. So, I wanted them to mention about it. 17
2015 • Zhou et al. Deep Recurrent Models with Fast-Forward Connections for Neural Machine Translation arXiv • He et al. Deep residual learning for image recognition arXiv • Wu et al. Google’s neural machine translation system: Bridging the gap between human and machine translation arXiv 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}