and translate. Bahdanau et al., ICLR 2015 • Memory-enhanced decoder for neural machine translation. Wang et al., EMNLP 2016 • Incorporating structural alignment biases into an attentional neural translation model. Cohn et al., NAACL 2016 • Incorporating discrete translation lexicons into neural machine translation. Arthur et al., EMNLP 2016 • Addressing the rare word problem in neural machine translation. Luong et al., ACL 2015 • Towards zero unknown word in neural machine translation. Li et al., IJCAI 2016 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
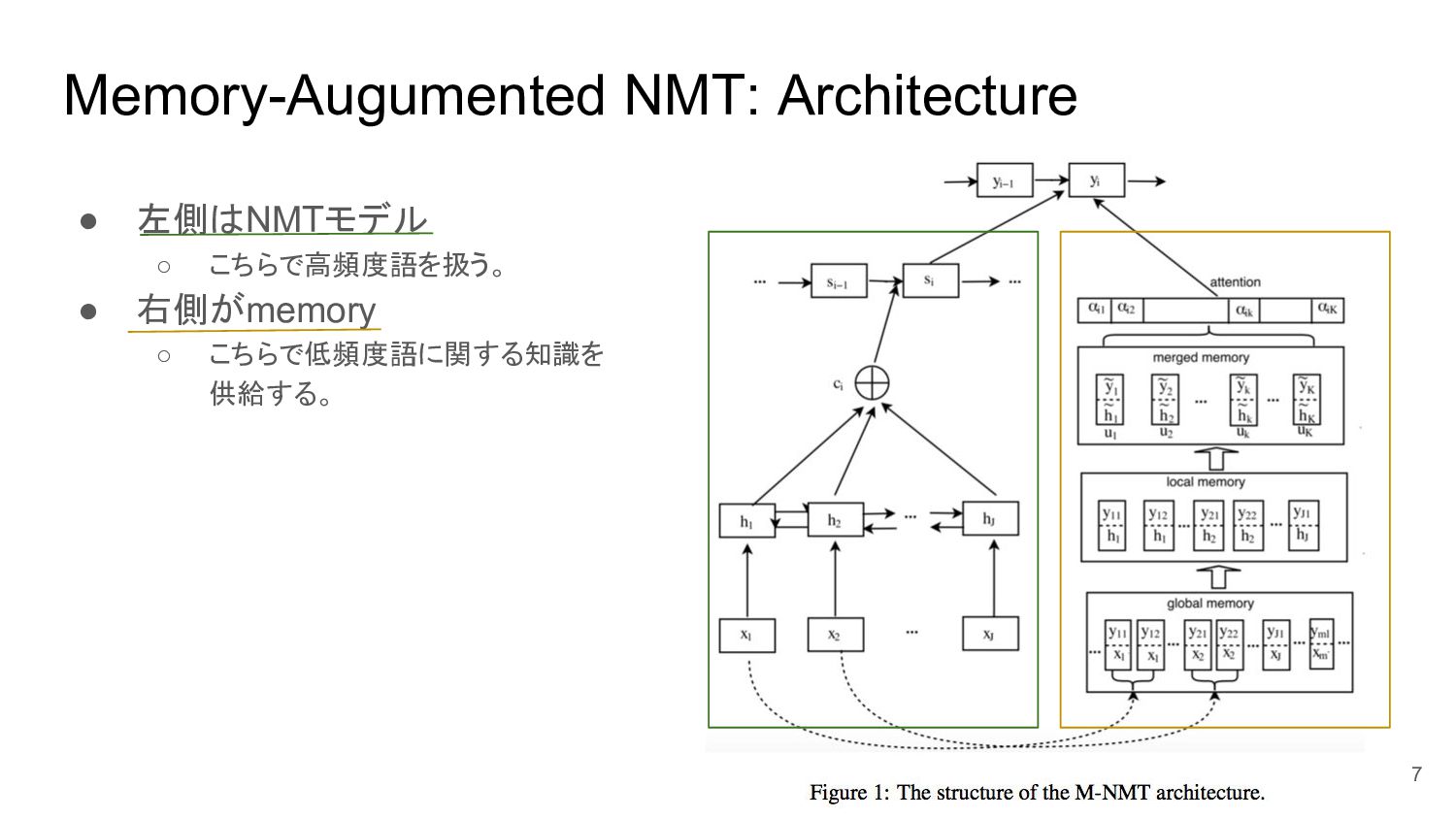{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
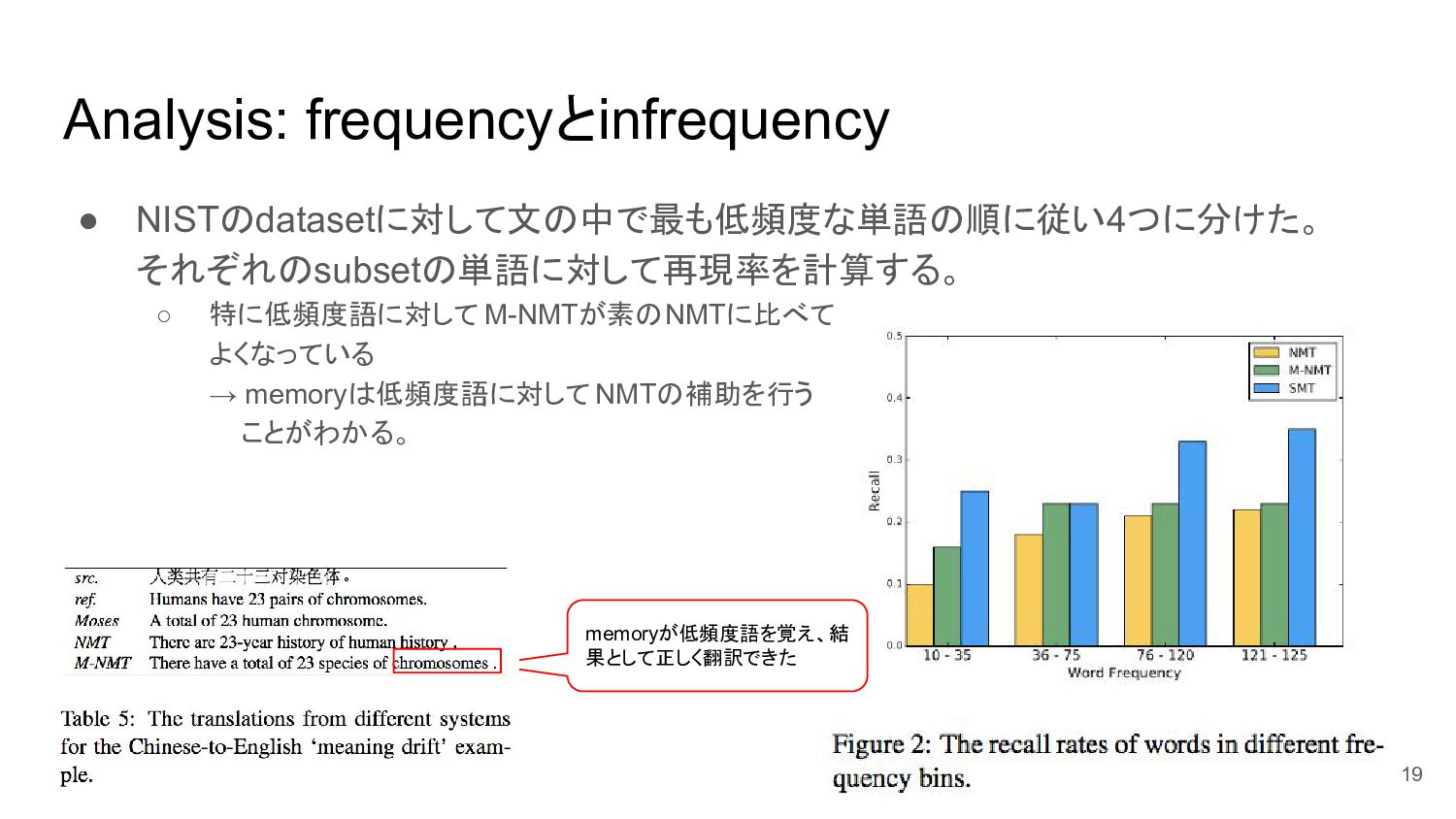{kind=link}
{kind=link}
{kind=link}