which extends beam search to allow the inclusion of pre-specified lexical constraints. • They demonstrate the feasibility and flexibility of Lexically Constrained Decoding by conducting 2 experiments. ◦ Neural Interactive-Predictive Translation ◦ Domain Adaptation for Neural Machine Translation • Result ◦ GBS can provide large improvements in translation quality in interactive scenarios. ◦ even without any user input, GBS can be used to achieve significant gains in performance in domain adaptation scenarios. 2
natural language processing model is a sequence of text. → Especially, they focus on machine translation usecases.† ◦ such as Post-Editing (PE) and Interactive-Predictive MT • Their goal is to find a way to force the output of a model to contain such lexical constraints. • In this paper, they propose a decoding algorithm which allows the specification of subsequences to be present in a model’s output. 3 input model output (sequenc e) †: lexically constrained decoding is relevant to any scenario where a model is asked to generate a secuence given an input. (image description, dialog generation, abstractive summarization, question answering)
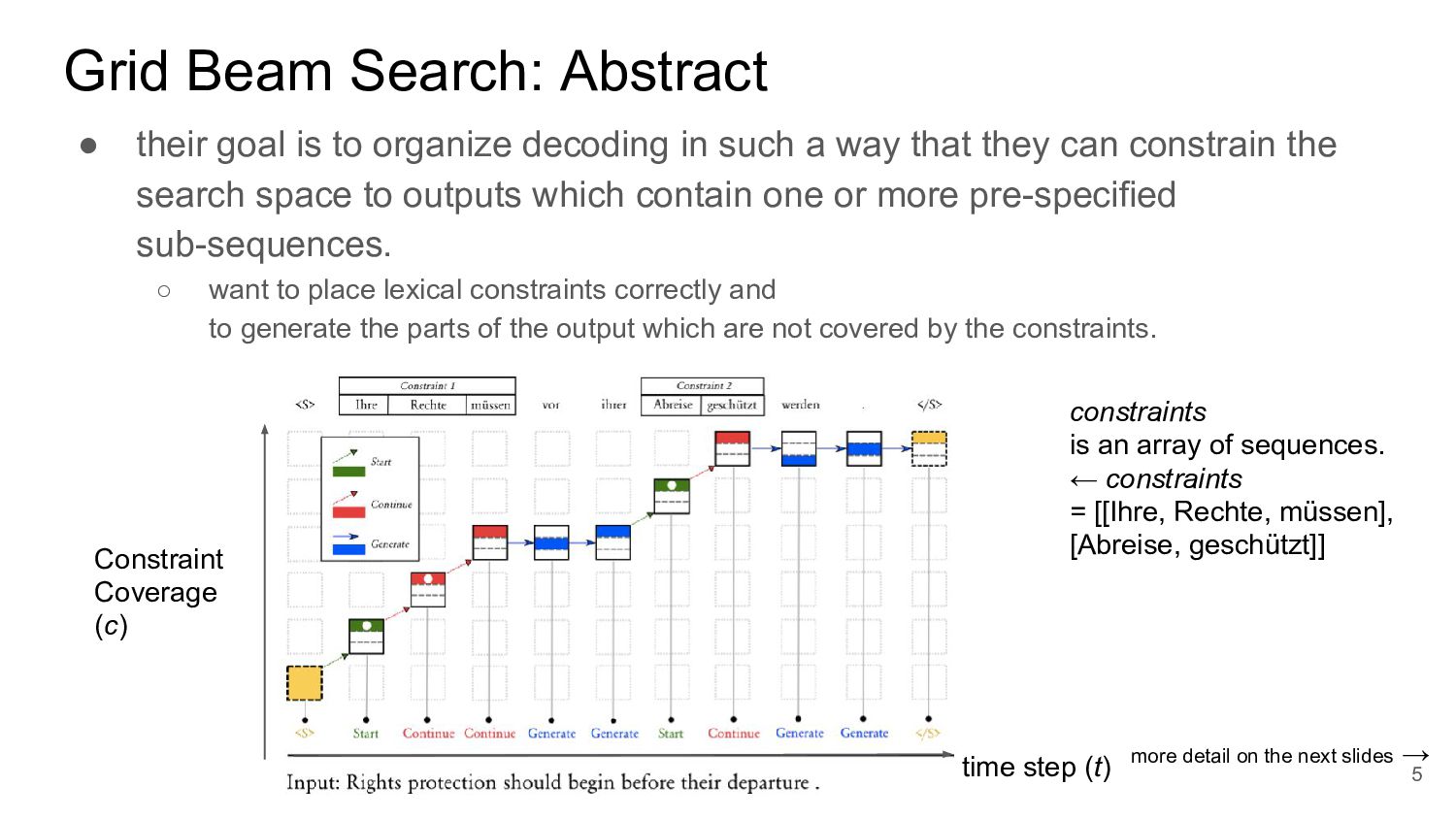
decoding in such a way that they can constrain the search space to outputs which contain one or more pre-specified sub-sequences. ◦ want to place lexical constraints correctly and to generate the parts of the output which are not covered by the constraints. 5 time step (t) Constraint Coverage (c) constraints is an array of sequences. ← constraints = [[Ihre, Rechte, müssen], [Abreise, geschützt]] more detail on the next slides →
in all constaints k: beam window size (this pseudo-code is for any model) 1. open hypotheses can either generate from the model’s distribution or start constraints 2. closed hypotheses can only generate the next token for in a currently unfinished constraint 1. open hypotheses (Grid[t-1][c]) may generate continuations from the model’s distribution 2. open hypotheses (Grid[t-1][c-1]) may start new constraints 3. closed hypotheses (Grid[t-1][c-1]) may continue constraints
(c) a colored strip inside a beam box represents an individual hypothesis in the beam’s k-best stack. Hypotheses with circles are closed, all other hypotheses are open. ← conceptual drawing
and closed hypotheses, → allow for arbitrary multi-token phrases in the search. • Each hypothesis maintains a coverage vector. ◦ ensure that constraints cannot be repeated in a search path (hypotheses which have already covered constrainti can only generate or start new constraints) • Discontinuous lexical constraints such as phrasal verbs in En or Ge ◦ it is easy to apply GBS by adding filters to the search ↓ 8 constraint ask <someone> out constraint1 ask constraint2 out constraint1 cannot be used before constraint0 there must be at least one generated token between the constraints. use 2 filters
handle arbitrary constraints. → there is a risk that constraints will contain unknown tokens. ◦ Especially in domain adaptation scenarios, some user-specified constraints are very likely to contain unseen tokens. → Use Subword Units. (maybe Byte Pair Encoding...) (In the experiments, they use this technique to ensure that no input tokens are unknown, even if a constraint contains words which never appeared in the training data.) 9
naive implementation of GBS is O(ktc). (standard time-based beam search is O(tk)) ↓ some consideration must be given to the efficiency of this algorithm • the beams in each column c of this Figure are independent. → GBS can be parallelized to allow all beams at each timestep to be filled simultaneously. • they find that the most time is spent computing the states for the hyp candidates. → by keeping the beam size small, they can make GBS significantly faster. 10
systems using our own implementation of NMT with attention over the source sequence (Bahdnau et al., 2014). ◦ bidirectional GRUs ◦ AdaDelta ◦ train all systems for 500,000 iterations, with validation every 5,000 steps, best single model from validation is used. ◦ use ℓ2 regularization (α = 1e^(-5)) ◦ Dropout is used on the output layers, rate is 0.5. ◦ beam size is 10. • corpus ◦ English-German ▪ 4.4M segments from the Europarl and CommonCrawl ◦ English-French ▪ 4.9M segments from the Europarl and CommonCrawl ◦ English-Portuguese ▪ 28.5M segments from the Europarl, JRC-Aquis and OpenSubtitles • subword ◦ they created a shared subword representation for each language pair by extracting a vocabulary of 80,000 symbols from the concatenated source and target data. 11
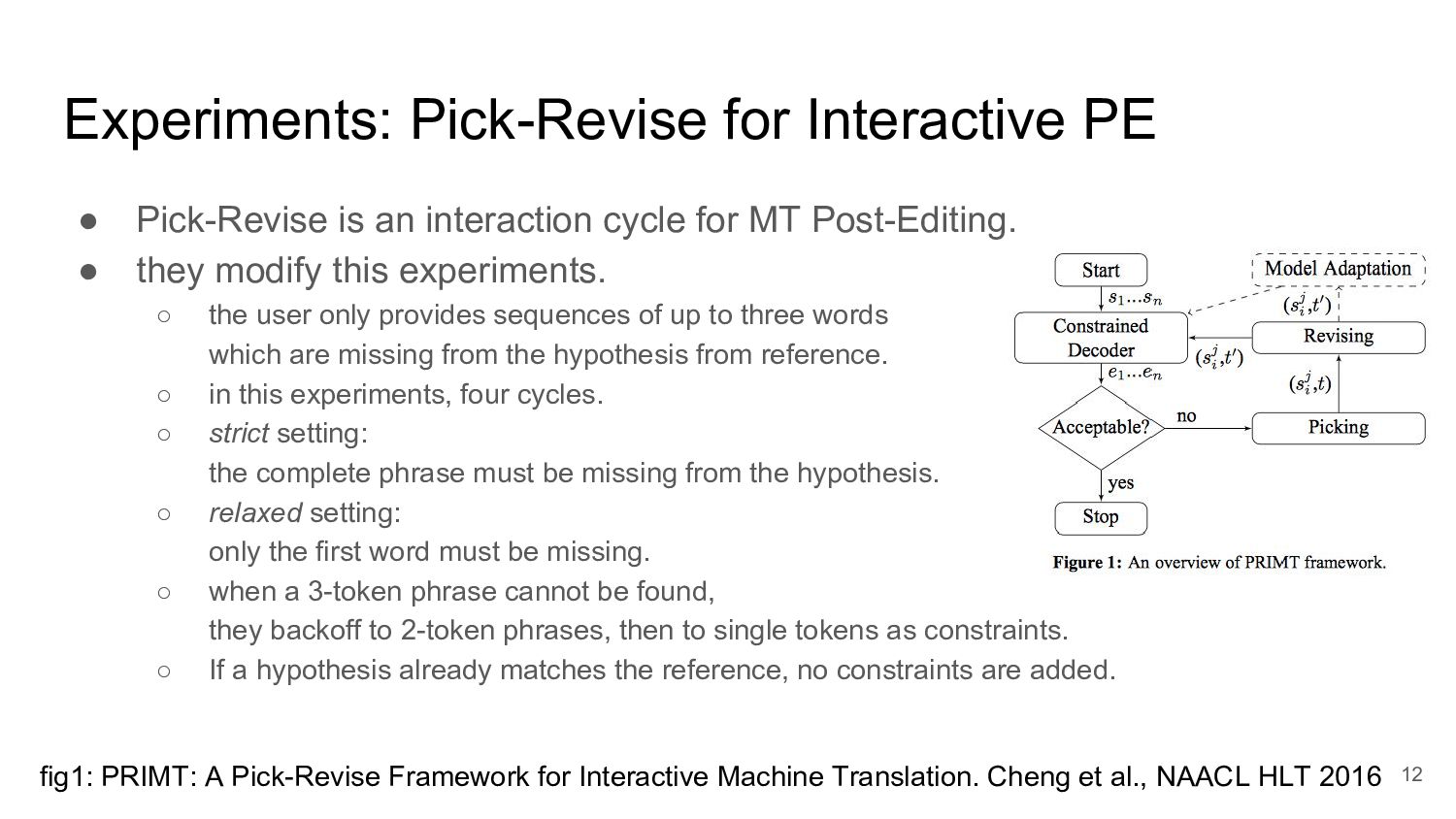
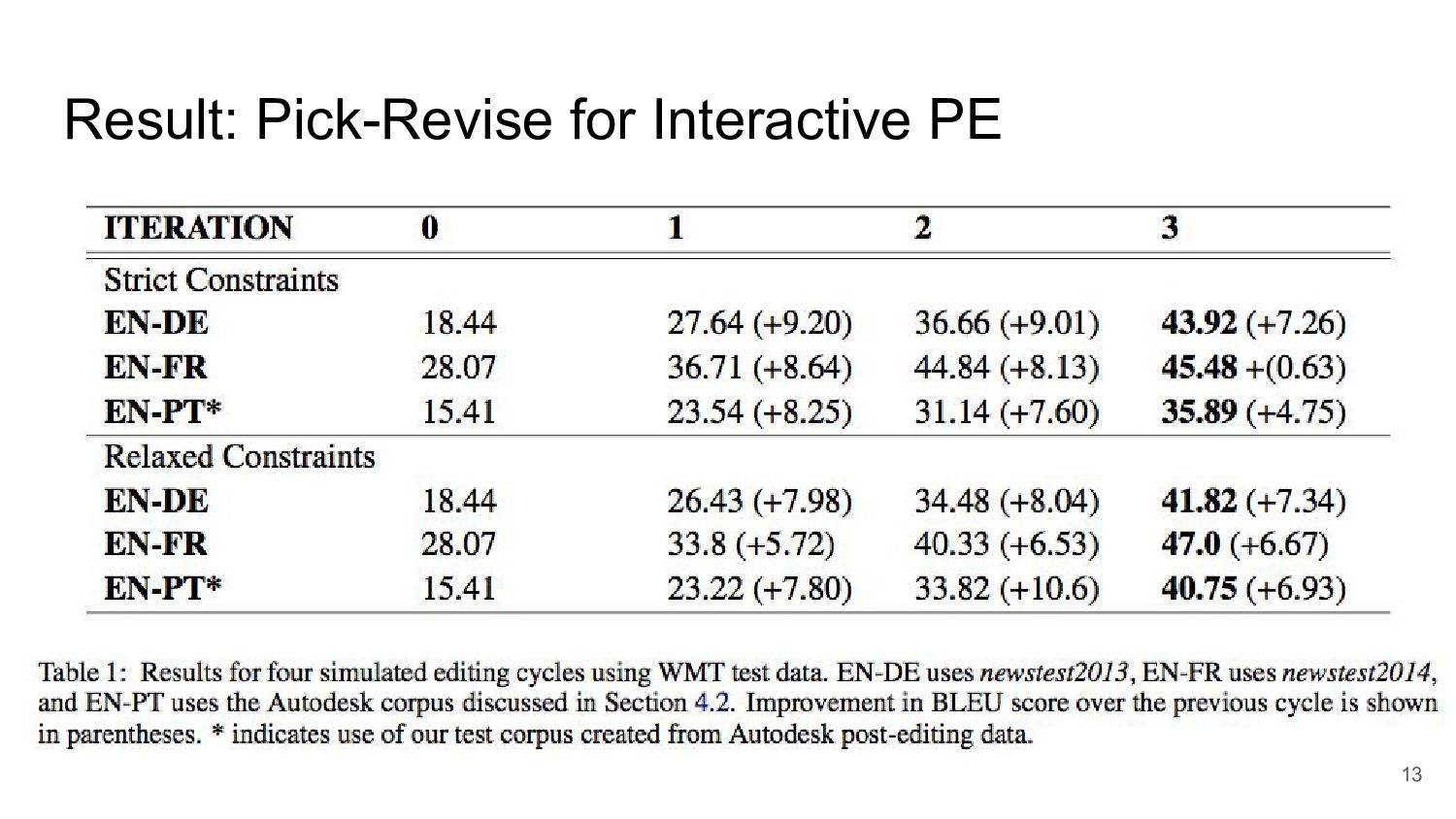
cycle for MT Post-Editing. • they modify this experiments. ◦ the user only provides sequences of up to three words which are missing from the hypothesis from reference. ◦ in this experiments, four cycles. ◦ strict setting: the complete phrase must be missing from the hypothesis. ◦ relaxed setting: only the first word must be missing. ◦ when a 3-token phrase cannot be found, they backoff to 2-token phrases, then to single tokens as constraints. ◦ If a hypothesis already matches the reference, no constraints are added. 12 fig1: PRIMT: A Pick-Revise Framework for Interactive Machine Translation. Cheng et al., NAACL HLT 2016
of domain-specific terminologies is common in real world applications of MT. → provide the term as constraints. • target domain data ◦ Autodesk Post-Editing corpus ↑ focused upon sofware localization, very dfferent from train data. • Extract Terminology ◦ devide the corpus into approximately 100,000 training sents, 1,000 test segments. automatically generate a terminology by computing PMI between source and target n-grams in training set. ◦ extract all n-grams from length 2-5 as terminology candidates. ◦ filter the candidates to only include pairs whose PMI is >= 0.9 and where both src and tgt occur in at least 5 times. → make the set of the terminology. 14 normarized to [-1, +1]
is caused by the placement of the terms by GBS, they evaluate the other inserting methods. ◦ randomly inserting terms to the baseline output ◦ prepending terms to the baseline output • even an automatically created terminology yield improvements. ◦ manually created domain terminologies are likely to lead to greater gains. 15 test set src tgt terminology phrase corrsponding phrase constraints for that segments add ↑ conceptual drawing for previous slide
SMT systems for specific usecases. (focusing on prefix and sufix) ◦ The largest body of work considers Interactive Machine Translation (IMT) • some attention has also been given to SMT decoding with multiple lexical constraints. (Cheng et al.,2016) ◦ their approach relies upon the phrase segmentation provided by the SMT system. ◦ the decoding algorithm can only make use of constraints that match phrase boundaries. In contrast, GBS approach decodes at the token level. • “To the best of our knowledge, ours is the first work which considers general lexically constrained decoding for any model which outputs sequences, without relying upon alignments between input and output, and without using a search organized by coverage of the input.” 17
incorporate arbitrary subsequences into the output of any model that generates output sequences token-by-token. • in interctive translation, user inputs can be used as constraints, generating a new output each time a user fixes an error. ◦ such a workflow can provide a large improvement in translation quality. • using a domain-specific terminology to generate target-side constraints ◦ a general domain model can be adapted to a new domain without anay retraining • future work ◦ evaluate GBS with models outside of MT, such as automatic summarization, image captioning or dialog generation ◦ introduce new constraint-aware models (via secondary attention mecanisms over lexical constraints) 18
University Participation to WAT 2016. Cromieres et al., WAT2016 • PRIMT: A Pick-Revise Framework for Interactive Machine Translation. Cheng et al., NAACL HLT 2016 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}