Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介: Guiding neural machine translation with r...
Search
Satoru Katsumata
December 10, 2023
Research
65
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介: Guiding neural machine translation with retrieved translation pieces
首都大 小町研 NAACL 2018 読み会
Satoru Katsumata
December 10, 2023
More Decks by Satoru Katsumata
See All by Satoru Katsumata
論文紹介: Word-node2vec
katsumata420
0
79
論文紹介: How Contextual are Contextualized Word Representations?
katsumata420
0
59
論文紹介: Incorporating Syntactic and Semantic Information in Word Embeddings using Graph Convolutional Networks
katsumata420
0
53
論文紹介: Exploiting Monolingual Data at Scale for Neural Machine Translation
katsumata420
0
53
論文紹介: Deep Neural Machine Translation with Linear Associative Unit
katsumata420
0
76
論文紹介: A convolutional encoder model for neural machine translation
katsumata420
0
110
論文紹介: Lexically constrained decoding for sequence generation using grid beam search
katsumata420
0
200
論文紹介: Memory-augmented Neural Machine Translation
katsumata420
0
71
論文紹介: Bi-Directional Block Self-Attention for Fast and Memory-Efficient Sequence Modeling
katsumata420
0
110
Other Decks in Research
See All in Research
「AIとWhyを深堀る」をAIと深堀る
iflection
0
520
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
160
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
390
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
580
Claude Code × autoresearch 実践
mathbullet
0
210
COMETAを用いたデータ民主化運動の歴史
sazimai
0
120
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
570
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
240
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
310
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
380
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
310
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
Featured
See All Featured
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
The Curse of the Amulet
leimatthew05
2
13k
Deep Space Network (abreviated)
tonyrice
0
230
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
The agentic SEO stack - context over prompts
schlessera
0
850
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Side Projects
sachag
455
43k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
BBQ
matthewcrist
89
10k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Transcript
Guiding Neural Machine Translation with Retrieved Translation Pieces Jingy Zhang,
Masao Utiyama, Eiichro Sumita, Graham Neubig and Satoshi Nakamura (NAACL 2018) 紹介: 小町研 M1 勝又 智
概要 • Neural Machine Translation(の test )のお話 • decode する際に、対訳コーパスから手がかり(’Translation
Pieces’)を持って来 て、それを考慮して翻訳する手法 • narrow domain な設定で BLEU が 6 points 上昇 • 嬉しみポイント - 既存の学習済みモデルに対して汎用的に使える - 学習コーパスに存在する低頻度表現を、普段の NMT より翻訳できる - 消費時間もそこまでは増えない 2
基本的なモデル構成とか Notation とか 翻訳モデル(Bahdanau et al., 2014) ↓ time step
t の時 各 time step ごとのやつを log とって足し込んで 出力文全体のものを作る↓↓↓ 3 : 入力文、長さ L : decoder hidden : previous output : context (↑ attention で求めたやつ) g () は変換するやつ、 詳しくはBahdanau et al., 2014 ここを Translation Pieces で調整する Neural Machine Translation by Jointly Learning to Align and Translate. Bahdanau et al., ICLR 2015
提案手法をざっくりと 次の 3 step で考える(論文中では 1-2 で1つ、3で 1つの構成) 1. 入力文に対応する言語対を対訳コーパス(学習データ)からとってくる
2. とってきたやつ(Retrieved src, tgt)から Translation Pieces (TP) をとってくる 3. この Translation Pieces を使用して decoding 4 src Retrieved: tgt word alignment 1-2 のイメージ図(赤字は input と Retrieved src 間の編集距離計算して、編集がなかった単語)
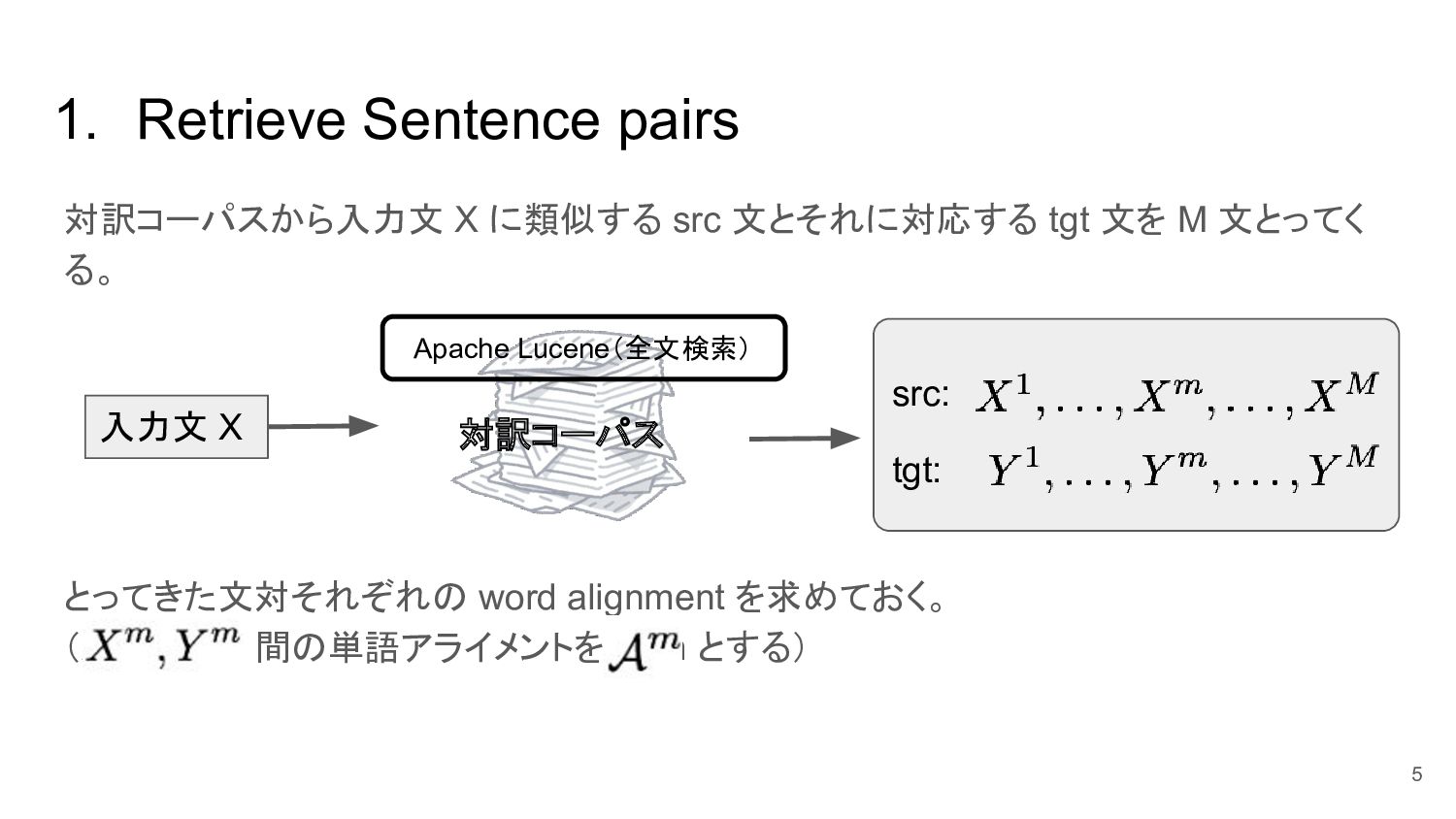
1. Retrieve Sentence pairs 対訳コーパスから入力文 X に類似する src 文とそれに対応する tgt
文を M 文とってく る。 とってきた文対それぞれの word alignment を求めておく。 (X^m, Y^m 間の単語アライメントを A^m とする) 5 入力文 X 対訳コーパス Apache Lucene(全文検索) src: tgt:
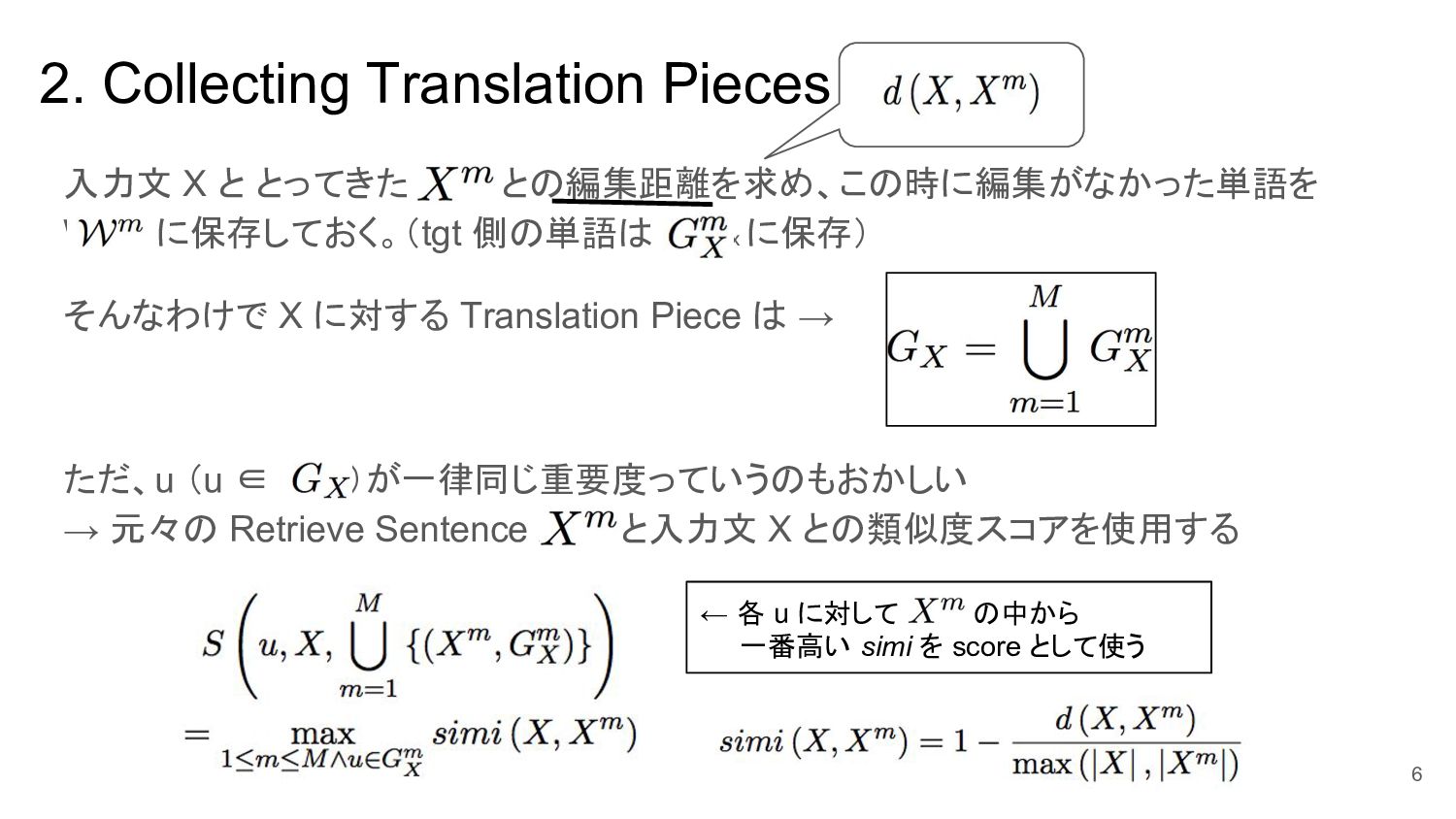
2. Collecting Translation Pieces 入力文 X と とってきた X^m との編集距離を求め、この時に編集がなかった単語を
W^m に保存しておく。(tgt 側の単語は G^m_x に保存) そんなわけで X に対する Translation Piece は → ただ、u (u ∈ G_x)が一律同じ重要度っていうのもおかしい → 元々の Retrieve Sentence X^m と入力文 X との類似度スコアを使用する 6 ← 各 u に対して X^m の中から 一番高い simi を score として使う
TP 集め; もう少し具体的に 7 src X^m Retrieved: tgt Y^m word
alignment X : 赤字の単語 (no edit word) ← G^m_x を求めるやつ 4-gram までやる A^m のsrc 側(赤字) がなくなったら次の i Translation Pieces は n-gram です。
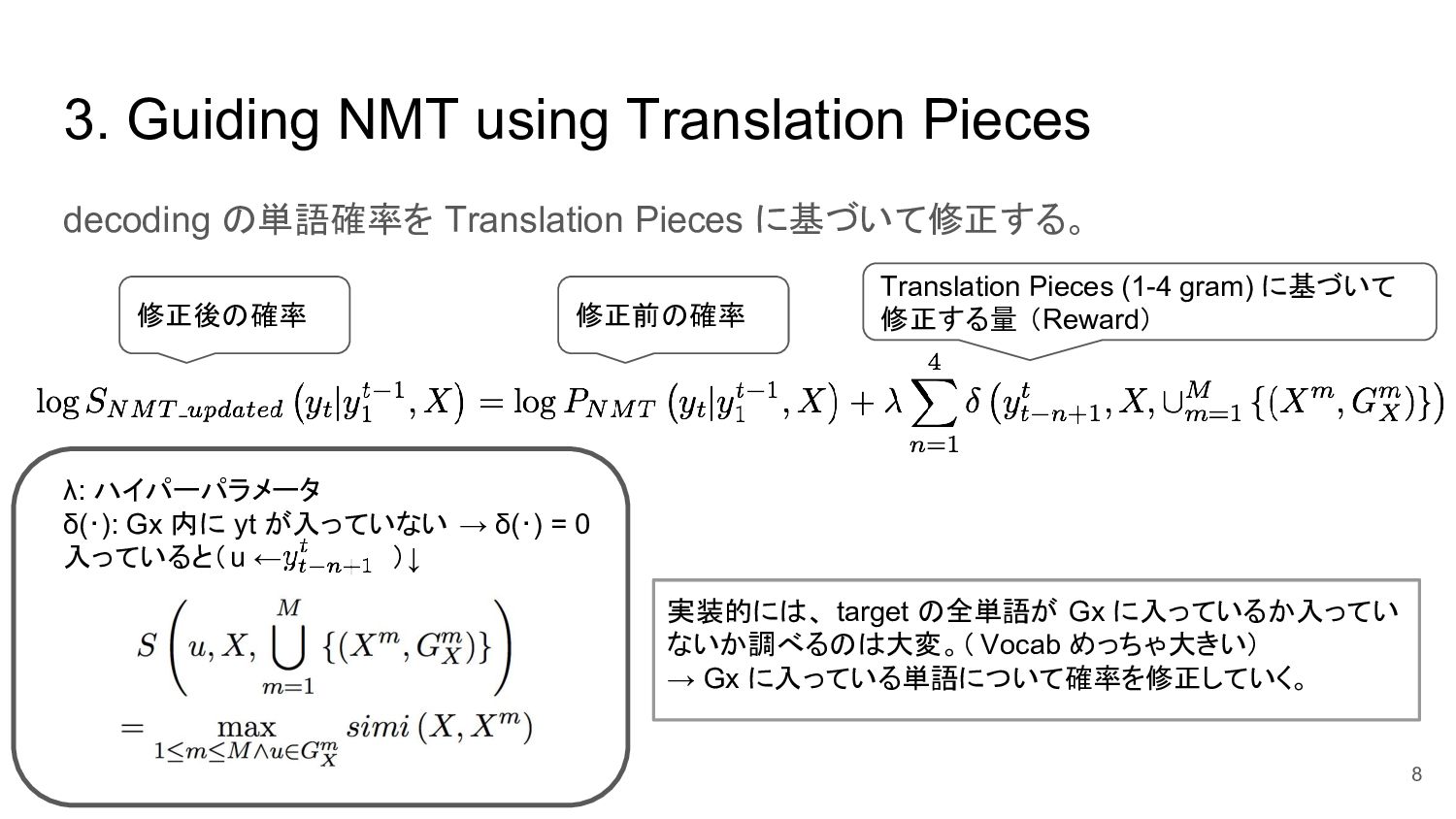
3. Guiding NMT using Translation Pieces decoding の単語確率を Translation Pieces
に基づいて修正する。 8 修正後の確率 修正前の確率 Translation Pieces (1-4 gram) に基づいて 修正する量 (Reward) λ: ハイパーパラメータ δ(・): Gx 内に yt が入っていない → δ(・) = 0 入っていると(u ← )↓ 実装的には、 target の全単語が Gx に入っているか入ってい ないか調べるのは大変。( Vocab めっちゃ大きい) → Gx に入っている単語について確率を修正していく。
Guiding NMT; もう少し詳しく 9 ← y_t を求めるやつ : Translation Pieces
と score が入ってる : Gx の 1-gram が入ってる → そこまでに出力したやつと next word の n-gram が Gx に入っていたら reward y_1 よりも後ろ行ったら終わり unigram Dx 内に n-gram がなかった ら終わり
翻訳実験: 設定 corpus: JRC-Acquis corpus (ver. 3.0) ↑ narrow domain
な設定(EU 加盟国の法関連) 方向: English-German、English-French and English-Spanish 提案手法特有パラメータ: Lucene で 100文とってくる。 Score に対する係数 λ は en-de と en-fr で1.5, en-es で1.0 その他: BPE 使用、word alignment に GIZA++ 使用 その他のパラメータ → 10
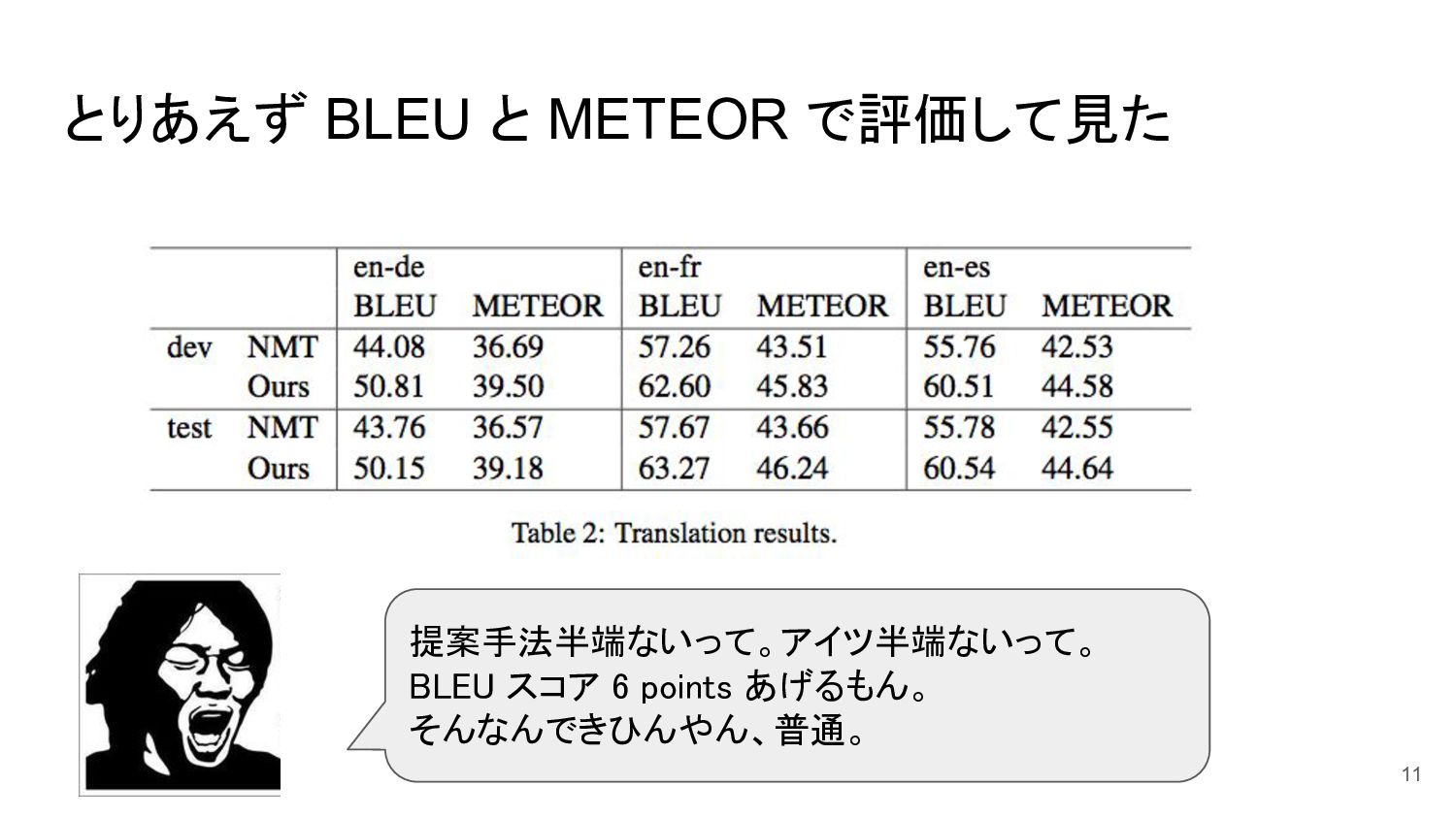
とりあえず BLEU と METEOR で評価して見た 11 提案手法半端ないって。アイツ半端ないって。 BLEU スコア 6
points あげるもん。 そんなんできひんやん、普通。
検索対象のデータと test データの類似度の影響 test sentence と training corpus (検索対象のデータ)の類似度を ↓とする。
この test sentence を corpus 全体にしたのが次の式。 この類似度尺度を用いて test set を半分にした。(高い方 : half-H、低い方: half-L) 12 ↓各カラムの上がり幅に注目 ↓
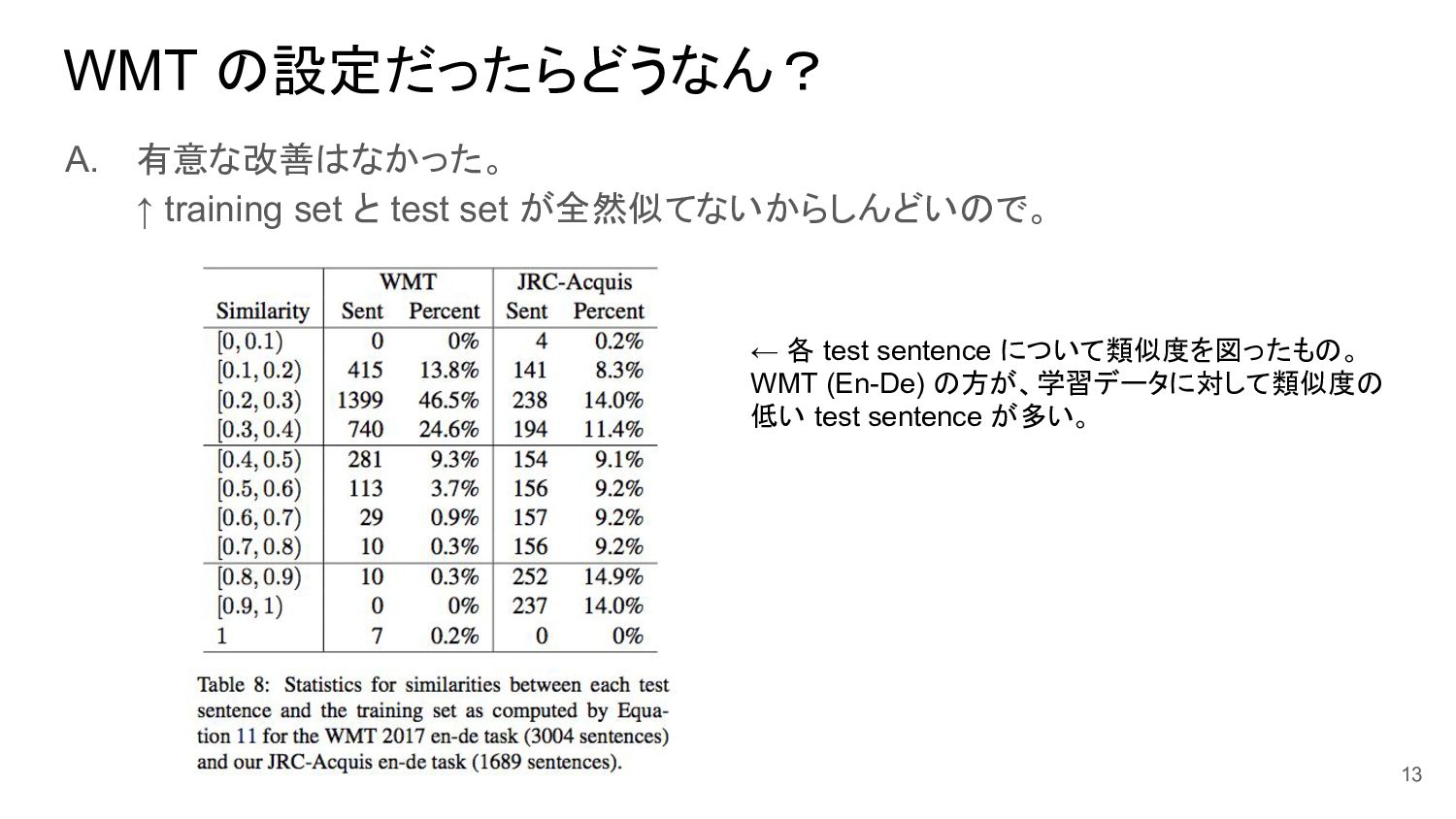
WMT の設定だったらどうなん? A. 有意な改善はなかった。 ↑ training set と test set
が全然似てないからしんどいので。 13 ← 各 test sentence について類似度を図ったもの。 WMT (En-De) の方が、学習データに対して類似度の 低い test sentence が多い。
実際どんな感じ? 14 赤: log NMT prob. 青: 共通する部分 緑: NMT
のみ 黄: proposed のみ とってきた文対はこれ以外にも当然存在してい ます。この文は simi score が 0.7。 緑と黄色を比較すると ... 通常の NMT に対して、 提案手法では最初の2単語を (ref に対して)正しく訳している。 → 実際 simi score を確認してみると、 NMT の出力した単語はそんなに高くない → reward をきっちり決めて、 それを元に翻訳を Guide することが大事
reward をガチる、ということ simi score を用いず、Gx に含まれていたら reward として 1 を、なかったら
0 を割り振 る実験をやって見た。 → あまり上がらなくなった。(それでもよくなっているが) 15 ← 思ったよりも下がらないなぁ、という印象 言語対によって差が異なるのがやや気になるかなぁ en-fr が 1番影響少なくて、次に en-es、で en-de → ドメインは一緒なので言語対ごとの単純な翻訳の難しさ がでてる?
低頻度表現の出力 提案手法は学習コーパスにおける低頻度 n-gram の出力に一役買いそう。 ↑ 通常 NMT は学習コーパス中の高頻度な n-gram を出力しがちであるが、
この手法だったら sentence similarity で reward を計算するので頻度の影響なし! 学習コーパス内に γ回出現した n-gram(1to4)が NMT と Prop でそれぞれ何回 正しく(表層的に一致する)翻訳ができたかを数えた。 → 低頻度 n-gram をより出力している! 16 γ = 1, en-de の場合 学習コーパスに 1回のみ出現す る n-gram は NMT の test set の翻訳全体で 3,193 回正しく出力され、 Prop では test set の翻訳全体で 5,433 回正しく出力された。 右に行くほど NMT と Prop の差が小さくなる(γ = 0 は除く)
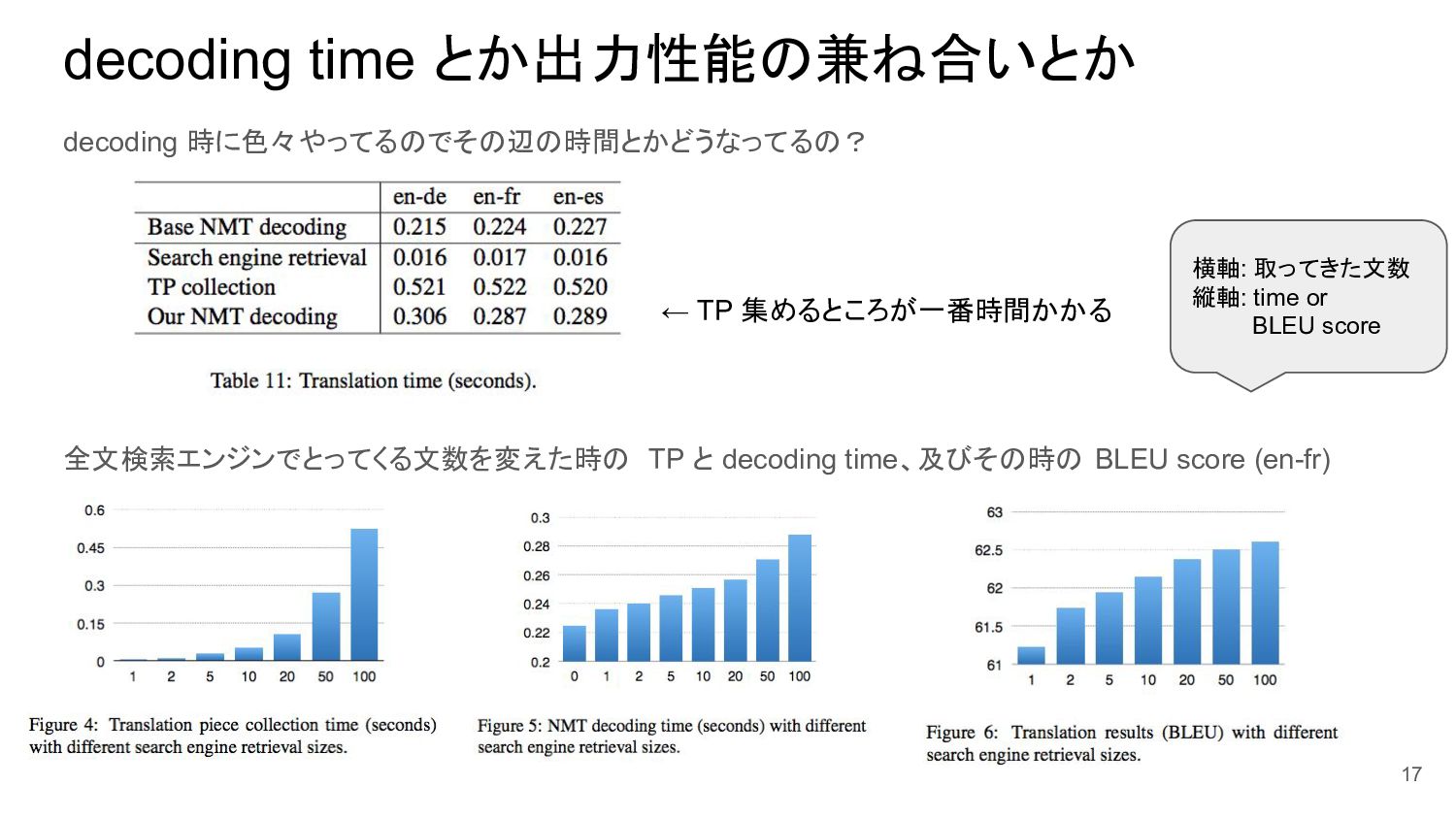
decoding time とか出力性能の兼ね合いとか decoding 時に色々やってるのでその辺の時間とかどうなってるの? 全文検索エンジンでとってくる文数を変えた時の TP と decoding time、及びその時の
BLEU score (en-fr) 17 ← TP 集めるところが一番時間かかる 横軸: 取ってきた文数 縦軸: time or BLEU score
まとめ • Translation Pieces を用いて NMT を Guide することで、 narrow
domain に効く手法を提案 - simple - effective - そこまで translation time を増やすわけではない - 学習に対して何かするのではなく、あくまで test decoding 時に用いる手法 • search engine で src に似た文対を持ってきて、そこから Translation Pieces を作成、翻訳時に reward を与える手法 • narrow domain の設定で 6 points (BLEU) の上昇を確認 18 個人的感想(ポエムのような何か) - 用例翻訳のような情報を用いて、 guide (≒ 弱 constrain) decoding を行う手法っぽさを感じる。 - 外部からの情報を入れるシリーズの一種に見えて、ただ、表層的な情報を入れるようにしていることで、 (Neural 的に情報を入れないことで、)学習コーパスに出現した微妙な言い回し( n-gram)を出力、というか 残すように誘導を行なっているっぽさ。 - 後、この手法、TP を選択するときに頻度を考慮していないことで低頻度 n-gram を出力するよう誘導して いて、NMT の頻度汚染問題にうまく立ち回ってるなぁって感想です。 - narrow domain とはいえ、6 points 上げるのはかっこいいなぁって。 (そりゃ大迫構文使いたくなるよなぁ)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}