Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Baseline Needs More Love: On Simple Word-Embedd...
Search
katsutan
April 08, 2019
Technology
250
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
文献紹介
長岡技術科学大学
勝田 哲弘
katsutan
April 08, 2019
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
260
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
240
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
Other Decks in Technology
See All in Technology
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
350
飲食店もAIで。レジ締めやハンディシステムをつくってる話 / Using AI for restaurant management
vtryo
0
240
Zoom2Youtube.Claude
kawaguti
PRO
1
160
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
950
NDIAS CTF 2026 問題解説会資料
bata_24
0
170
Fabricをフル活用する AI Agent Hub -製造業特化AIエージェントの設計
iotcomjpadmin
0
200
そのハーネス、本当に境界になっていますか? AIエージェント時代の実行環境設計【MEGU-Meet #4】
cscengineer
PRO
0
110
フルカイテン株式会社 エンジニア向け採用資料
fullkaiten
0
11k
プライバシー保護の理論と実践
lycorptech_jp
PRO
1
240
小さいから、全部わかる。— 常駐AI "xangi" のすすめ
sugupoko
0
260
最近評価が難しくなった
maroon8021
0
210
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
0
180
Featured
See All Featured
Color Theory Basics | Prateek | Gurzu
gurzu
0
380
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
Git: the NoSQL Database
bkeepers
PRO
432
67k
sira's awesome portfolio website redesign presentation
elsirapls
0
290
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
Facilitating Awesome Meetings
lara
57
7k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
170
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Transcript
Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated
Pooling Mechanisms Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), pages 440–450 Melbourne, Australia, July 15 - 20, 2018. 文献紹介: 長岡技術科学大学 勝田 哲弘
Abstract • Simple Word-Embedding-based Models (SWEMs)と word-embedding-based RNN/CNN modelsの比較 ◦
SWEMsが多くの場合で同等、優れた精度を示す • Parameter freeのpoolingを活用するモデル ◦ hierarchical pooling ◦ parameter数が少なく済む 2
Introduction • Word embeddingは各単語を固定長のベクトルとして表現し、可変長テキ ストのモデル化によく利用されている ◦ 加算などの簡易的なものからRNN、CNNなど • RNN、CNNはパラメータが多く、計算コストが高い •
SWEMは語順情報が明示的でない、計算コストは低い • 計算コストと表現力はトレードオフ 3
Introduction • 単語分散表現で実行される単純なpooling処理が自然言語処理にいつ、 なぜ有効なのかを調査する • 3つの異なるタスク(17のデータセット)で評価 4
Simple Word-Embedding Model (SWEM) パラメータを持たないモデル • Average-Pooling(一番単純なモデル) • Max Pooling(CNNでのmax-over-time
pooling に近い) • Hierarchical Pooling ◦ ウィンドウ幅nでavg-poolingを行い、その上にmax-pooling 5
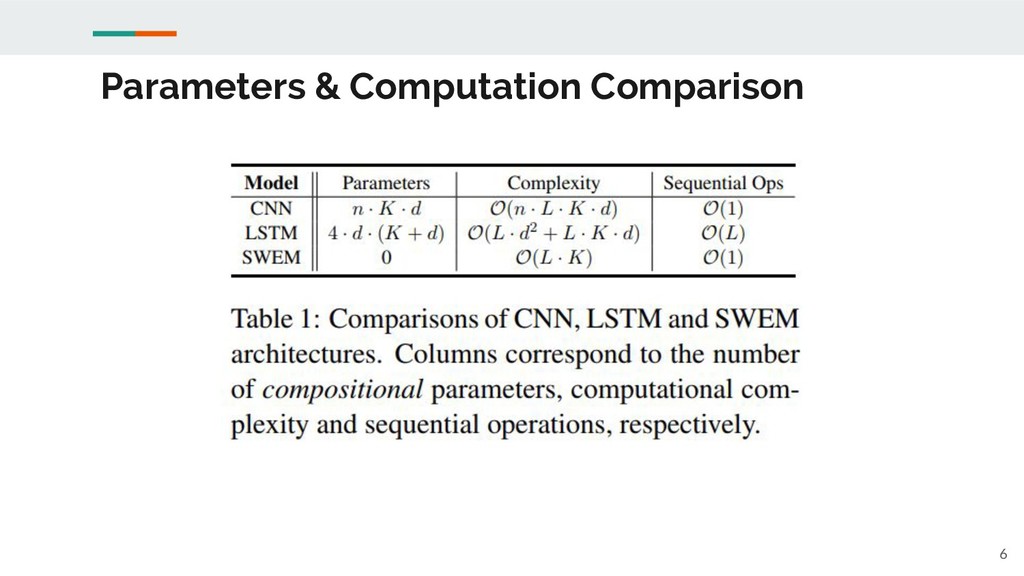
Parameters & Computation Comparison 6
Experiments • タスク: ◦ 文書分類(トピック分類、感情分類、オントロジー分類 ) ◦ テキストマッチング ◦ 文分類
◦ 17データセット • モデル ◦ GloVe ◦ MLP ◦ Adam 7
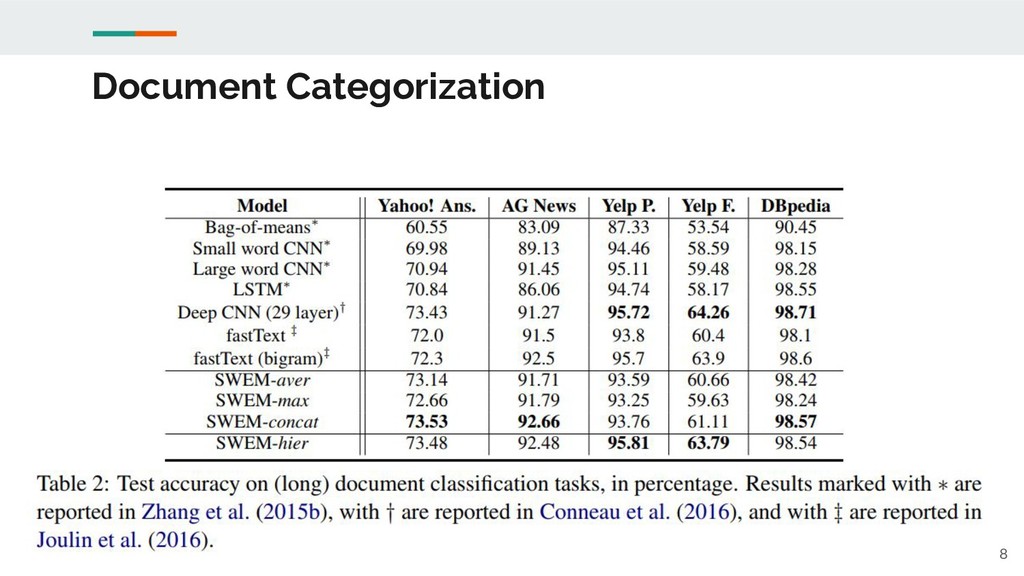
Document Categorization 8
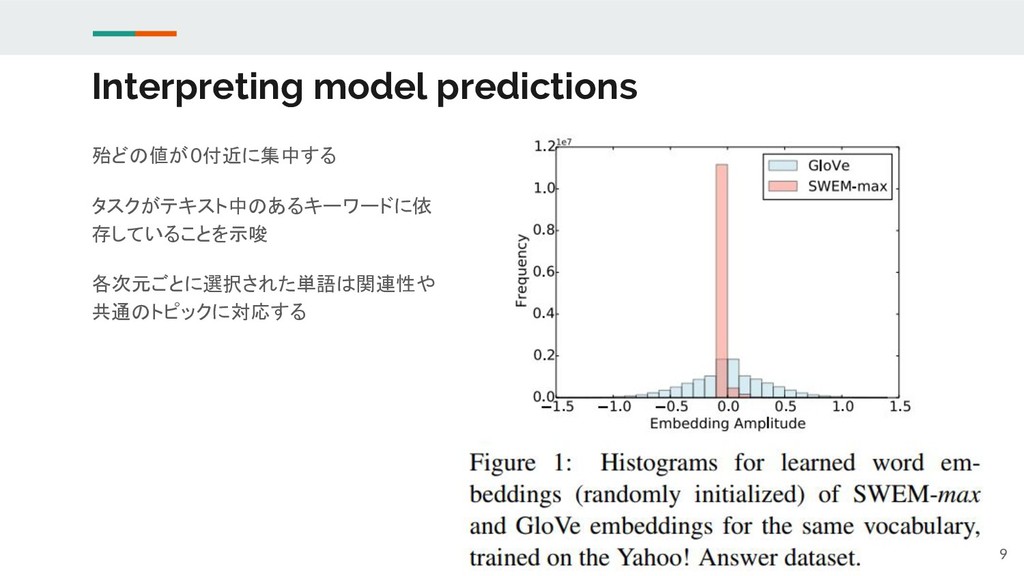
Interpreting model predictions 殆どの値が0付近に集中する タスクがテキスト中のあるキーワードに依 存していることを示唆 各次元ごとに選択された単語は関連性や 共通のトピックに対応する 9
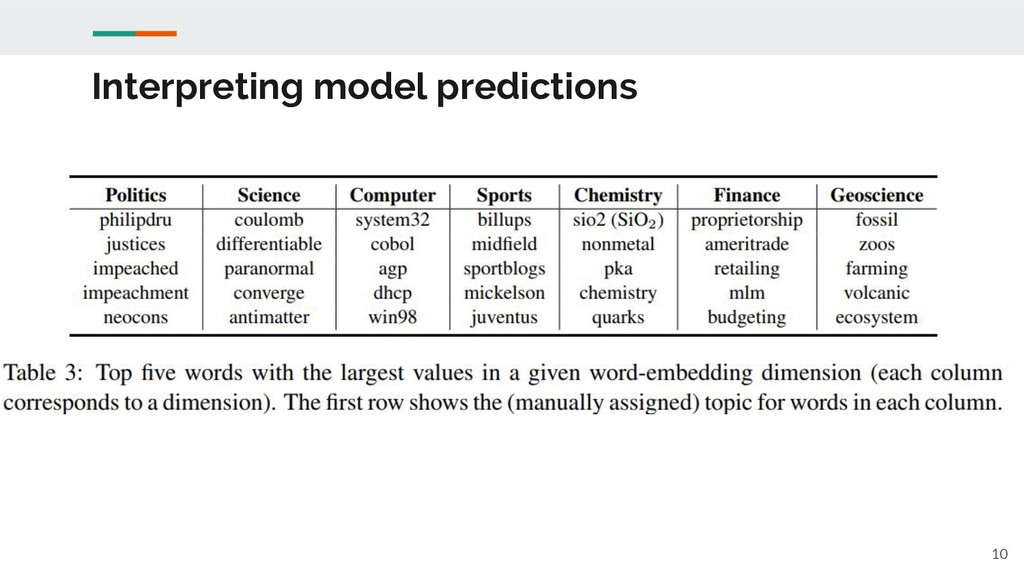
Interpreting model predictions 10
Importance of word-order information 11
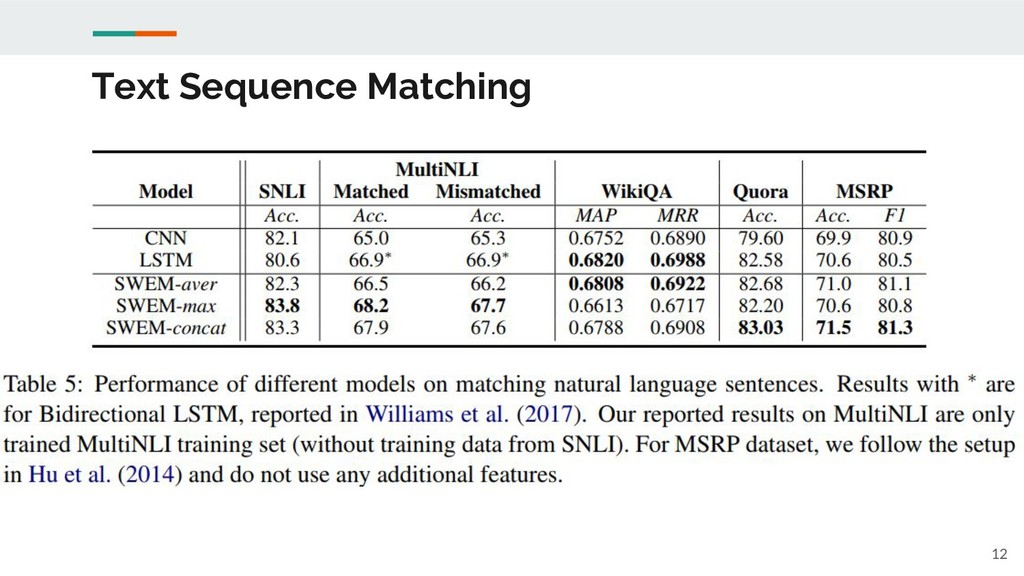
Text Sequence Matching 12
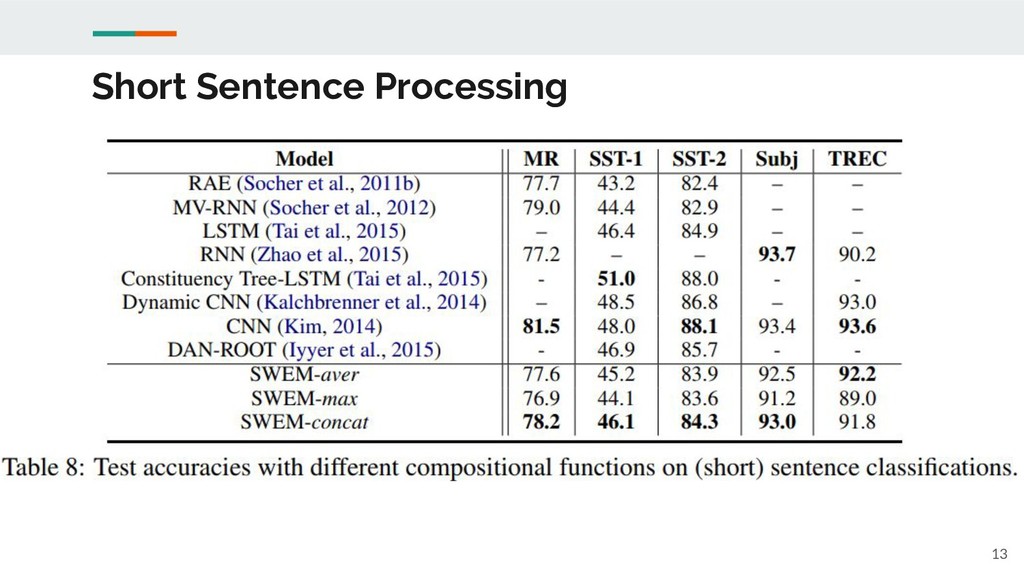
Short Sentence Processing 13
Extension to other languages • Sogou news corpus(a Chinese dataset
represented by Pinyin) ◦ SWEM-concat accuracy : 91.3% ◦ SWEM-hier (window size of 5) accuracy : 96.2% ◦ CNN (95.6%) and LSTM (95.2%) • より語順に敏感な中国語においても最高精度に匹敵する 14
Conclusions 17のデータセットでSWEM、CNN、LSTMのモデル間の比較を行った • 単純なプーリングは長い文書の表現に効果的、短い文にはCNN/LSTMが 最適 • 感情分類はトピック分類よりも語順に敏感である、hierarchical poolingは CNN/LSTMと同等の結果が得られる •
NLI、QAでは単純なpoolingが優れた精度を出す • SWEM Max Poolingでは、分散表現の各次元にトピックと対応付けられる ような意味的パターンが見られた 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}