Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Improving Word Embeddings Using Kernel PCA
Search
katsutan
September 17, 2019
Technology
250
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Improving Word Embeddings Using Kernel PCA
文献紹介
https://www.aclweb.org/anthology/W19-4323
長岡技術科学大学
勝田 哲弘
katsutan
September 17, 2019
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
260
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
240
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
DSGAN: Generative Adversarial Training for Distant Supervision Relation Extraction
katsutan
0
300
Other Decks in Technology
See All in Technology
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
0
200
最近評価が難しくなった
maroon8021
0
210
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
150
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
300
Zoom2Youtube.Claude
kawaguti
PRO
1
160
AI Agentをシステムに組み込む前にゆるく向き合ってみる
hayama17
0
200
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
150
どうして今サーバーサイドKotlinを選択したのか
nealle
0
190
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
260
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
400
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.3k
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
950
Featured
See All Featured
Mobile First: as difficult as doing things right
swwweet
225
10k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
180
30 Presentation Tips
portentint
PRO
1
340
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
430
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
Paper Plane
katiecoart
PRO
1
52k
Transcript
IMPROVING WORD EMBEDDINGS USING KERNEL PCA 文献紹介 長岡技術科学大学 勝田 哲弘
ABSTRACT トレーニング時間を短縮し、パフォーマンスを向上させるために、 morphological information を考慮した埋め込みモデルのための新しいアプローチ 単語類似度行列のカーネル主成分分析(KPCA)で得られる単語のmorphological informationで強化
英語とドイツ語の単語の類似性と類推のタスクでモデルを評価 元のスキップグラムモデルとfastTextモデルよりも高い精度を達成 必要なトレーニングデータと時間も大幅に減少 2
INTRODUCTION Word embeddingでよく用いられる手法 Word2vec-skipgram fastText fastTextはサブワードを考慮することで低頻度語をある程度改善できる
しかし、ニュースなどに出てくる新しい単語などは失敗する場合が多い 語彙が時間の経過で変化するデータセット内でうまく機能するアプローチの 提案 3
KPCA-BASED SKIP-GRAM AND FASTTEXT MODELS 単語類似度行列でKPCAを使用した埋め込み事前学習 語彙内の単語に対して文字列の類似度を計算し類似度行列を生成
単語、サブワード埋め込みをKPCAで初期化 意味的に類似した単語は、 roots, affixes, syllablesなどの一般的な形態素 をしばしば共有する morphologically richな言語で特に役立つ 4
KERNEL PCA ON STRING SIMILARITIES 語彙V内の単語w、文字列の類似度関数S(n-gram similarity)、非線形カーネル関 数K(ガウス)で単語類似度行列を計算
Kの列ベクトルkiはwiの| V |次元表現と見なすことができるため、V次元のwiの 単語の特徴空間表現が得られる PCAによって単語ベクトルを低次元空間に投影 最も高い固有値λ1からλdに対応するd個の固有ベクトルv1からvdを選択 5
MODELS WITH KPCA EMBEDDING 語彙Vを制限して、テキストコーパスの最も頻繁な単語のみを含める Vに含まれない単語snewは、カーネルベクトルを用いて計算 Semanticな情報を考慮するためword2vec、fastTextに組み込む
fastTextではサブワードのベクトル表現も同様に計算して使用 6
EXPERIMENTAL RESULTS -DATASET 様々なサイズのデータセットでトレーニングしたモデルのパフォーマンスを評価 評価 単語とそれらの関係の間のセマンティックおよび構文の類似性の計算を含む単語類推タスク
文分類タスクなどの後続の処理で埋め込みがどの程度機能するか 7
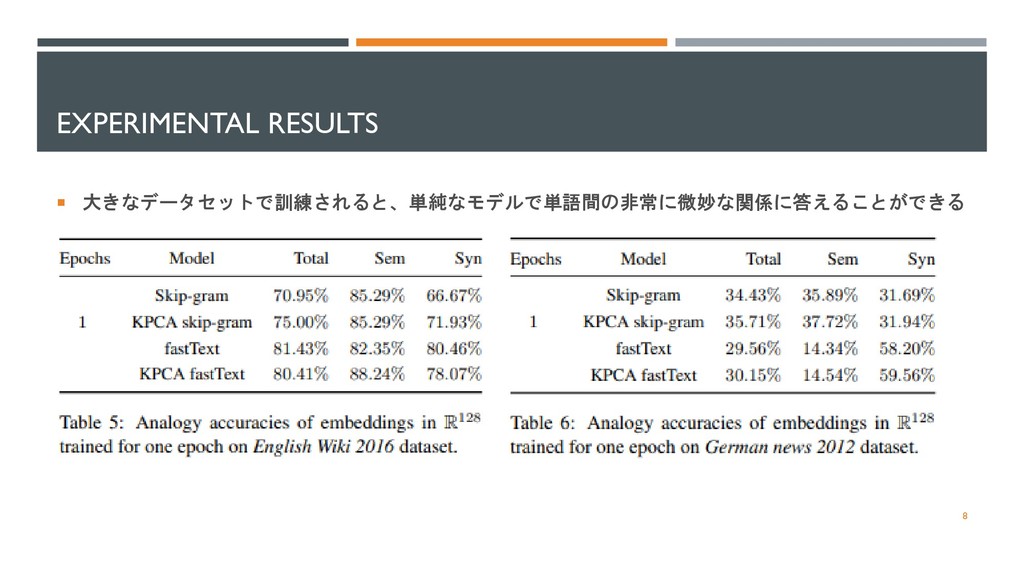
EXPERIMENTAL RESULTS 大きなデータセットで訓練されると、単純なモデルで単語間の非常に微妙な関係に答えることができる 8
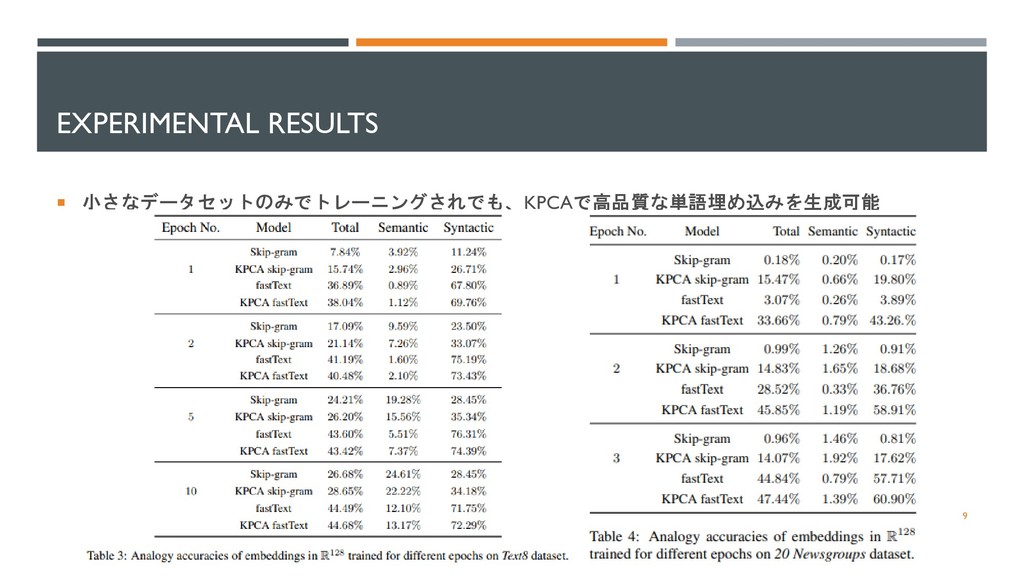
EXPERIMENTAL RESULTS 小さなデータセットのみでトレーニングされでも、KPCAで高品質な単語埋め込みを生成可能 9
EVALUATION OF PERFORMANCE ON DOWNSTREAM APPLICATIONS 埋め込みモデルから取得した埋め込みを使用してCNNを初期化、トレーニング中の埋め込み層を固定 10
CONCLUSION KPCAを用いた単語埋め込みの改善手法を提案 KPCAの対象となる小さな語彙から計算された文字列類似度行列に基づいた単語の埋め込みを生成 単語のKPCAベースのベクトル表現をskipgramモデルへの入力として使用して、単語の文脈も考慮し た埋め込みを取得 KPCAを用いることで:
word similarityやword analogyの改善 より少ないデータセット、エポック数でも学習が可能 11
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}