2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 1198–1203, Hong Kong, China, November 3–7, 2019. 長岡技術科学大学 勝田 哲弘
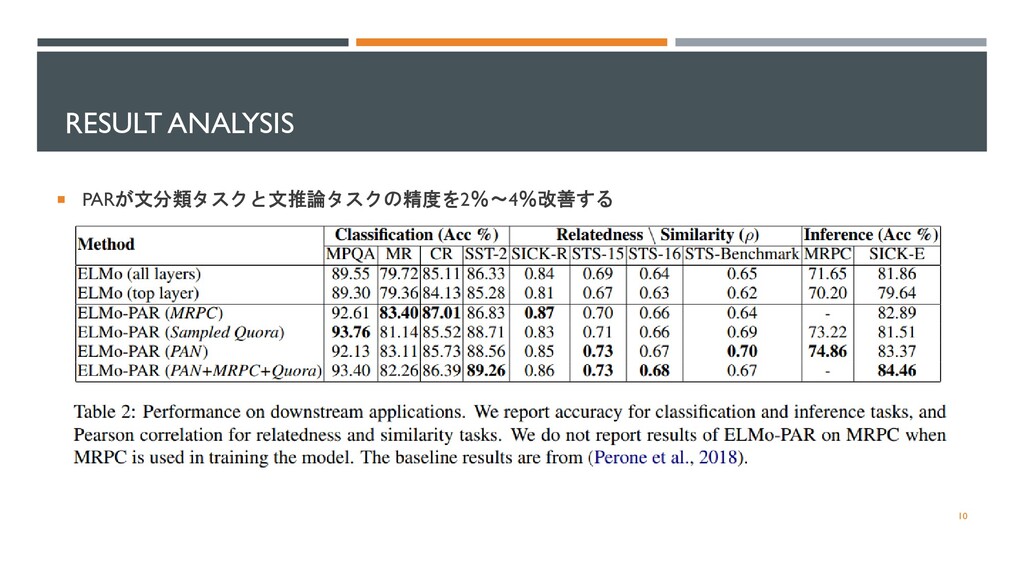
SentEval framework two baselines models: (1) ELMo (all layers) 3,074-dimensional sentence embedding by averaging all layers. (2) ELMo (top layers) 1,024 dimensional vector by averaging of the top layer. 8
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}