Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Character Eyes: Seeing Language through Charact...
Search
katsutan
October 15, 2019
Technology
240
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Character Eyes: Seeing Language through Character-Level Taggers
文献紹介
https://www.aclweb.org/anthology/W19-4811.pdf
長岡技術科学大学
自然言語処理研究室
勝田 哲弘
katsutan
October 15, 2019
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
260
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
DSGAN: Generative Adversarial Training for Distant Supervision Relation Extraction
katsutan
0
300
Other Decks in Technology
See All in Technology
AWS Summit 2026で見えたSIerにとっての Amazon Quickの位置づけ
maf_0521
0
160
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
350
きのこカンファレンス2026_肩書きを外したとき私は誰か
yamasatimi
1
130
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
150
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
520
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
7
530
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
260
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
370
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
0
210
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
130
ゼロをイチにする仕事が終わったあと
smasato
0
280
トークン最適化のためのユーザーストーリー分析 / User Story Analysis for Token Optimization
oomatomo
0
170
Featured
See All Featured
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
280
Deep Space Network (abreviated)
tonyrice
0
220
Practical Orchestrator
shlominoach
191
11k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
880
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
55k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
What's in a price? How to price your products and services
michaelherold
247
13k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Why Our Code Smells
bkeepers
PRO
340
58k
Transcript
Character Eyes: Seeing Language through Character-Level Taggers Proceedings of the
Second BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 95–102 Florence, Italy, August 1, 2019. 長岡技術科学大学 自然言語処理研究室 勝田 哲弘 2019/10/15 文献紹介
Introduction • この論文が注目しているもの • サブワードのベクトル表現 • 文字レベルモデルの利点 • 単語単位では低頻度で学習できない場合も対応できる •
現状 • 言語知識(morphology and orthography)のエンコードを説明できない • Bi-LSTMの文字エンコーダーを分析する 2
Tagging Task • 評価を行うモデルはLSTM tagging models Ling et al. (2015)
• Char-LSTM → Word-Bi-LSTM → two-layer perceptron → softmax • 各単語の隠れ層パーセプトロンに送られてタグスコアを生成 • morphosyntactic attribute tagging Pinter et al. (2017) • 独自のperceptron + softmax scaffoldingを使用 3
Language Selection • 2つの形態学的特性に基づいて言語を選択 • 24のデータセットはすべて、Universal Dependencies (UD) version 2.3
(Nivre et al., 2018)から取得 • 言語特性はWorld Atlas of Language Structures (Bickel and Nichols, 2013; Dryer, 2013) • Affixation. • UDで利用可能なすべての言語を選択 • Suffixing以外も含まれる • Morphological Synthesis 4
Technical Setup • データセット • 複数のtreebankがある言語では最も大きいものを使用 • ‘http’ を含む単語は ‘URL’に置換
• ‘@’を含む単語は ‘EMAIL’に置換 • Hyperparameters • bidirectional character-level LSTM • hidden state: 128, character embedding size: 256 • word-level bidirectional LSTM • 2layers, hidden state 128, dropout 0.5 • MLP • Size: tagset size, 活性化関数: tanh 5
Results • Word embeddingなしで同等の精度 • Char embedが256と大きいことに起因 6
Analysis • モデルの分析 • 言語情報をどのようにエンコードしているのか? • Metrics • 各文字ごとの隠れ層の出力を観察 average
absolute, max absolute 7
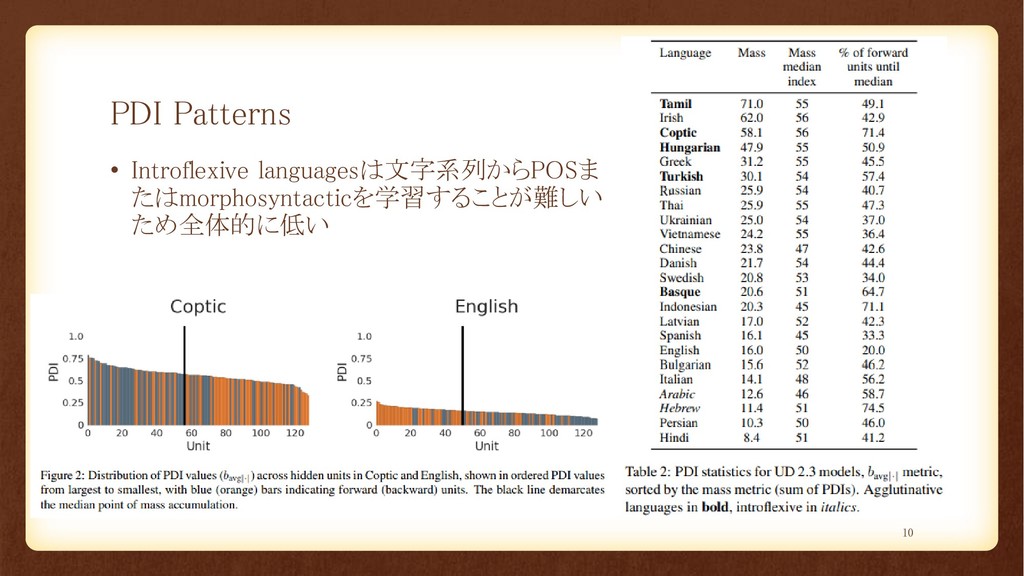
Analysis • 相互情報(MI)に基づく language-level metric: PDI • base metricの範囲は同じサイズのB個のビンに分割 •
各単語からのbase activationsはT POSタグカテゴリごとに合計され、正規化されて結合 確率分布が生成される • PDIが高いと異なる単語に対して異なる活性化を行っている • タスクとしては優れた分類器になっている 8
Analysis • 言語は各ユニットに1つずつ dhのPDI scoresを生成 • さらに2つの language-level metricsを定義 •
sum of PDI values: • the relative importance of forward and backward units: 9
PDI Patterns • Introflexive languagesは文字系列からPOSま たはmorphosyntacticを学習することが難しい ため全体的に低い 10
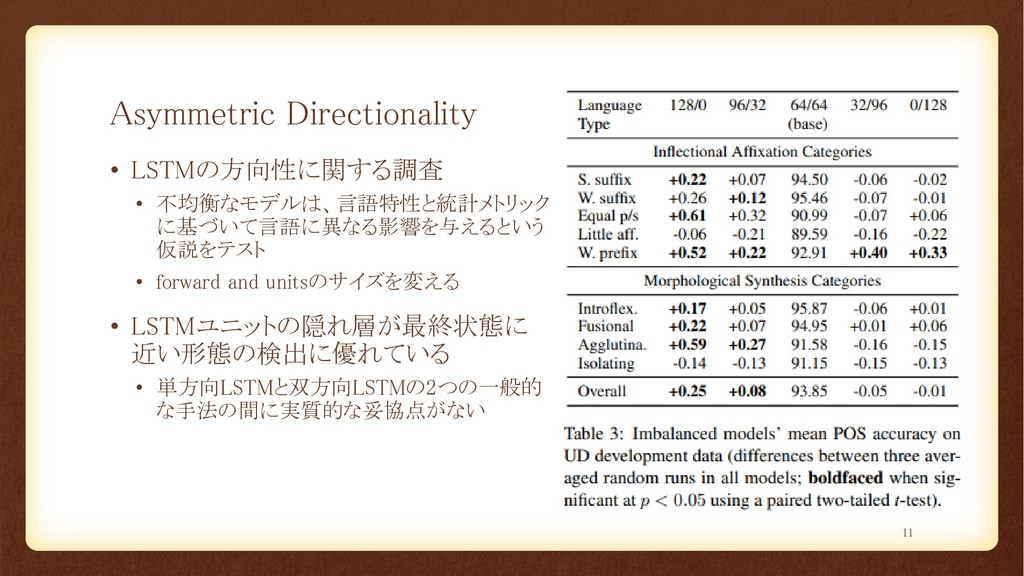
Asymmetric Directionality • LSTMの方向性に関する調査 • 不均衡なモデルは、言語特性と統計メトリック に基づいて言語に異なる影響を与えるという 仮説をテスト • forward
and unitsのサイズを変える • LSTMユニットの隠れ層が最終状態に 近い形態の検出に優れている • 単方向LSTMと双方向LSTMの2つの一般的 な手法の間に実質的な妥協点がない 11
Conclusion • 文字レベルのBi-LSTMモデルは多くの言語で意味のある単語表現を計算 するが、その方法は各言語のtypological propertiesによって異なる • この観察結果は、モデル選択の動機になる • agglutinative languagesは単一方向の分析を強く好む
• 今後、メトリックにさらなる制御を導入する • タグの分布やインスタンスの数などのデータセット属性、および収束率や初期化の効 果などの学習関連のプロパティを組み込む 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}