Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
A robust self-learning method for fully unsuper...
Search
katsutan
June 19, 2019
Technology
320
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
文献紹介
長岡技術科学大学 自然言語処理研究室
勝田 哲弘
katsutan
June 19, 2019
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
260
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
240
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
DSGAN: Generative Adversarial Training for Distant Supervision Relation Extraction
katsutan
0
300
Other Decks in Technology
See All in Technology
はてなのサービス基盤を支える Kubernetes《足腰》
masayoshimaezawa
0
430
飲食店もAIで。レジ締めやハンディシステムをつくってる話 / Using AI for restaurant management
vtryo
0
240
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
150
ご挨拶「10周年を迎える共創ラボのこれまでとこれから」
iotcomjpadmin
0
180
RAGの精度向上とエージェント活用
kintotechdev
2
130
cccccc
moznion
0
1.7k
『AIに負けない』より『AIと遊ぶ』」〜ワクワクが最強のテスト・QA学習戦略_公開用
odan611
1
370
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
300
知見・人・API・DB・予算 ─ ナイナイ尽くしだった人事データ整備 with dbt、5年間の学び
ken6377
1
150
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
150
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
400
LiDAR SLAMの実装とセンサ融合 ~Lie群からContinuous-Time LIOまで~
naokiakai
1
940
Featured
See All Featured
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Paper Plane (Part 1)
katiecoart
PRO
0
9.5k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
400
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
180
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
800
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
580
Transcript
A robust self-learning method for fully unsupervised cross-lingual mappings of
word embeddings Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers), pages 789–798, 2018. 文献紹介 長岡技術科学大学 自然言語処理研究室 勝田 哲弘
Abstract • 先行研究でadversarial trainingによって教師なしで複数言語の分散表現を 共有することが可能になった ◦ 良い精度 ◦ しかし、評価は非常に近い単語間でのみ行われている •
より堅牢なモデルの提案 ◦ 単語分散表現の構造的類似性を明示的に活用する完全に教師なしの初期化 ◦ iterative self-learningに基づく代替アプローチ 実装は以下で公開されている https://github.com/artetxem/vecmap 2
Introduction • Cross-lingual embedding mappings ◦ 単一言語コーパスを使用して異なる言語ごとに分散表現を個別に訓練し、線形変換によっ て共有空間にマッピングする ▪ 辞書を必要とするものがほとんど
▪ 最近、adversarial trainingで教師なしが可能に ◦ iterative self-learningは非常に小さい辞書( 25対の単語程)からの高品質なマッピングが可 能 (Artetxe et al., 2017) • 単語類似度の分布をもとに初期解を構築 ◦ 教師なし 3
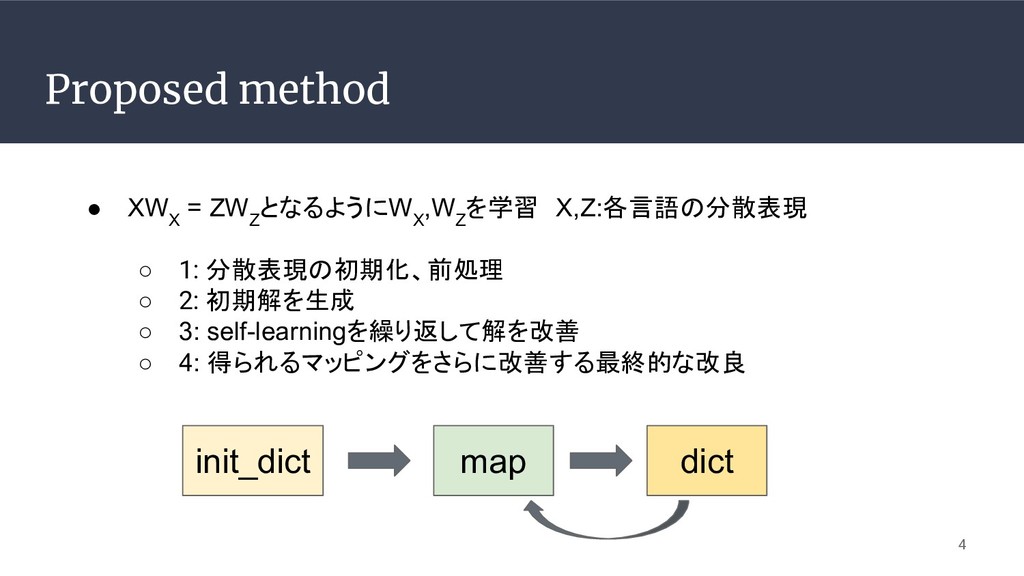
Proposed method • XW X = ZW Z となるようにW X
,W Z を学習 X,Z:各言語の分散表現 ◦ 1: 分散表現の初期化、前処理 ◦ 2: 初期解を生成 ◦ 3: self-learningを繰り返して解を改善 ◦ 4: 得られるマッピングをさらに改善する最終的な改良 4 init_dict map dict
Embedding normalization 前処理 ベクトルの長さを正規化 ↓ 各次元の兵権を中心に揃える ↓ 再び、長さを正規化 内積を取るとcos類似度が計算できる ユークリッド距離が類似度の尺度とみなせる
5
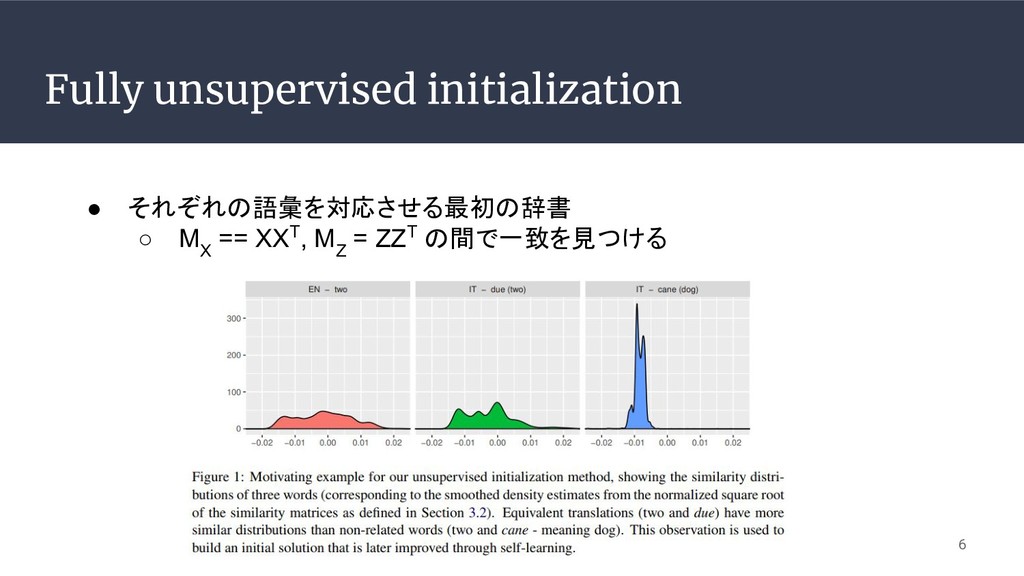
Fully unsupervised initialization • それぞれの語彙を対応させる最初の辞書 ◦ M X == XXT,
M Z = ZZT の間で一致を見つける 6
Robust self-learning 学習は収束するまで次の2つのステップを繰り返す • 現在の辞書Dを最大化する直交マッピングを計算 • 最近傍検索 ◦ 7
Robust self-learning • Stochastic dictionary induction ◦ 類似度行列を確率pで保持、残りを0にする ◦ p
= 0.1から徐々に増やす • Frequency-based vocabulary cutoff ◦ 各言語で高頻度のk単語に制限 • CSLS retrieval ◦ k最近傍の平均コサイン類似度 • Bidirectional dictionary induction 8
Symmetric re-weighting • それぞれの相互相関に従って再加重 9
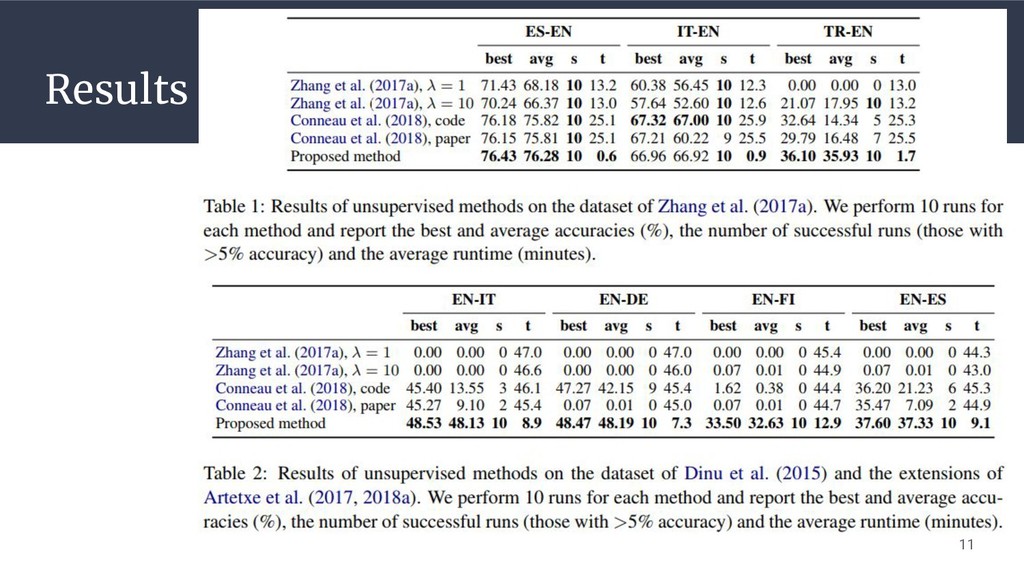
Experimental settings 対訳辞書抽出の精度を評価 Dinu et al. (2015),subsequent extensions of Artetxe
et al. (2017, 2018) • 分散表現(CBOW: 300-dimension) ◦ WacKy crawling corpora (English, Italian, German) ◦ Common Crawl (Finnish) ◦ WMT News Crawl (Spanish) Zhang et al. (2017a) • 分散表現(CBOW: 50-dimension) ◦ Wikipedia 10
Results 11
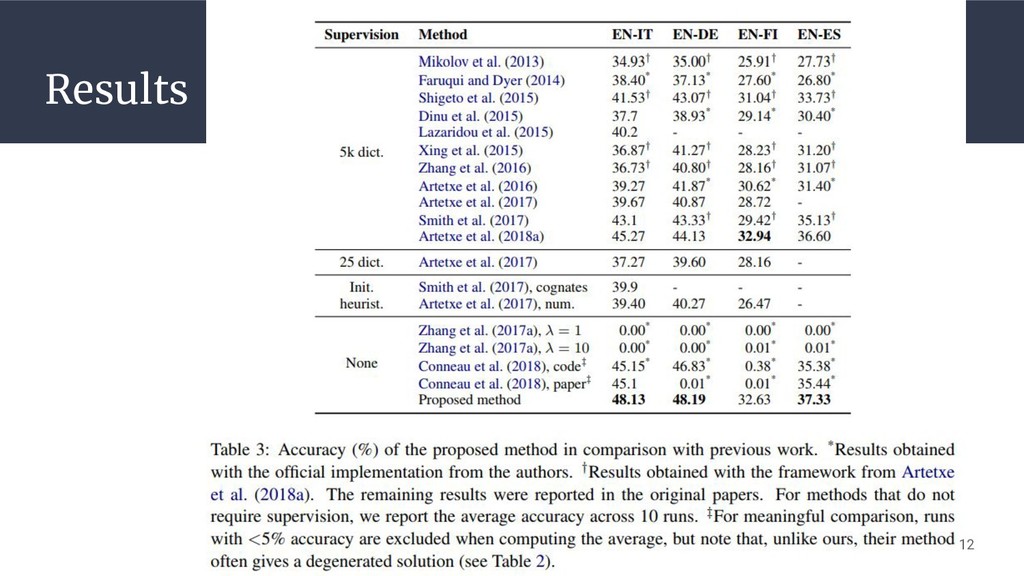
Results 12
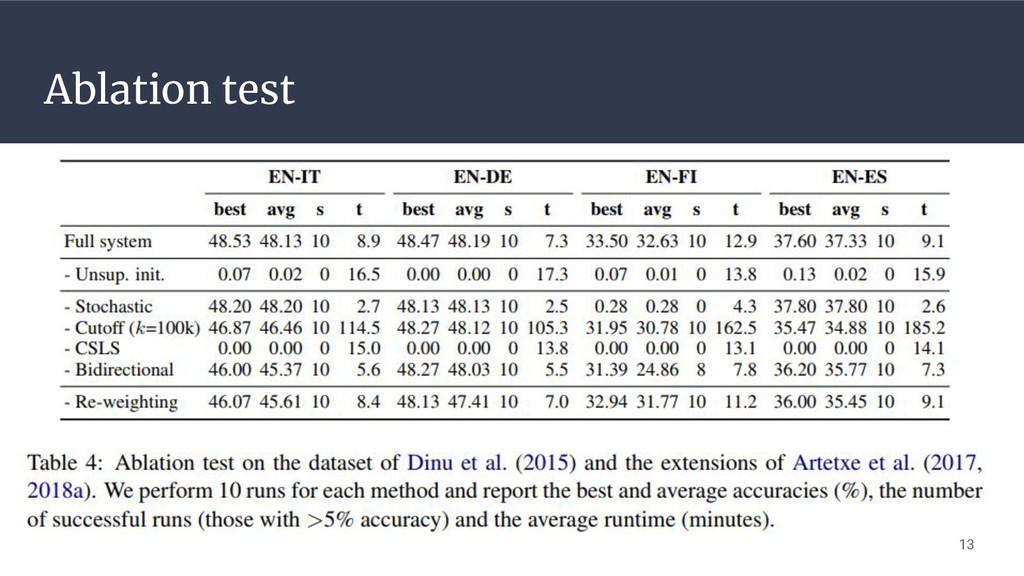
Ablation test 13
Conclusions • self-learningと初期の弱いマッピング手法を組み合わせたモデルの提案 ◦ 教師なし、ハイパーパラメータに強く依存しない • 教師なし、教師つきマッピングに関する以前の研究と比較して最良の結果を 示した • 将来的には、バイリンガルからマルチリンガルへと拡張し、さらに長いフレー
ズを埋め込む 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}