Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Simple and Effective Paraphrastic Similarity fr...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
katsutan
January 27, 2020
Technology
230
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Simple and Effective Paraphrastic Similarity from Parallel Translations
文献紹介
https://www.aclweb.org/anthology/P19-1453.pdf
長岡技術科学大学
勝田 哲弘
katsutan
January 27, 2020
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
260
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
240
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
DSGAN: Generative Adversarial Training for Distant Supervision Relation Extraction
katsutan
0
300
Other Decks in Technology
See All in Technology
グローバルチームと挑むプロダクト開発
sansantech
PRO
1
150
“ID沼入口” - 基本とセキュリティから始める、考え続けるためのID管理技術勉強会 告知&イントロ
ritou
0
380
4人目のSREはAgent
tanimuyk
0
380
初めてのDatabricks勉強会
taka_aki
2
230
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
520
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
250
SRE Lounge Hiroshimaへの招待
grimoh
0
150
アラート調査向けAIエージェントの本番導入とその後/AI Agents for Alert Investigation: Production Deployment and After
taddy_919
1
360
きのこカンファレンス2026_肩書きを外したとき私は誰か
yamasatimi
1
130
『AIに負けない』より『AIと遊ぶ』」〜ワクワクが最強のテスト・QA学習戦略_公開用
odan611
1
370
NDIAS CTF 2026 問題解説会資料
bata_24
0
170
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
0
150
Featured
See All Featured
The Cost Of JavaScript in 2023
addyosmani
55
10k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
Accessibility Awareness
sabderemane
1
150
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
Designing Powerful Visuals for Engaging Learning
tmiket
1
440
A Tale of Four Properties
chriscoyier
163
24k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
640
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Product Roadmaps are Hard
iamctodd
55
12k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
Simple and Effective Paraphrastic Similarity from Parallel Translations 長岡技術科学大学 自然言語処理研究室
勝田 哲弘 文献紹介 Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4602–4608 Florence, Italy, July 28 - August 2, 2019
Abstract ➢言い換え文の埋め込みを学習するためのモデル ➢時間のかかる言い換えコーパスの作成ステップを削除 ➢bitextから直接学習 ➢結果 ➢このモデルは最先端の複雑なモデルよりも優れている ➢高速であり、クロスリンガルタスクに適用できる 2
Introduction ➢これまでの文の類似性 ➢言い換えフレーズのデータセットで学習 ➢大きなバイリンガルコーパスから言い換えデータセット を誘導する ➢本論文 ➢文の埋め込みをbitextで直接学習 ➢高速に文章をエンコードするシンプルなモデル 3
Learning Sentence Embeddings ➢Training ⚫ トレーニングデータ ⚫ それぞれソース言語とターゲット言語の一連の並列文 ペア (
, ) ⚫ ネガティブサンプリング ⚫ の翻訳ではないターゲット文′ をランダムに選択 ⚫ ( , )を( , ′ )よりもマージンδ近づける 4 目的関数 (; ): 各言語のパラメーターを持つ センテンスエンコーダー
Learning Sentence Embeddings ➢Negative Sampling ➢ mega-batching, Wieting and Gimpel(2018)
➢Mが大きいほど困難な例を提供 ➢Mega-batching ➢M個のミニバッチを集約して1つのメガバッチを作成し、 メガバッチから負の例を選択 ➢メガバッチの各ペアに負の例があれば、メガバッチはM 個のミニバッチに分割 5
Learning Sentence Embeddings Encoders ➢SP ➢sentencepiece のサブワードを平均 ➢TRIGRAM ➢文字トライグラムの平均 ➢WORD
➢単語の平均 ➢LSTM-SP ➢Sentencepieceを用いた双方向LSTM 6
Experiments ➢並列データと逆翻訳された並列データの学習 を比較 ➢2012-2016年のSemEval Semantic Textual Similarity (STS) ➢2つのsemantic cross-lingual
tasksでの最良の モデルSPを比較 ➢2017 SemEval STS ➢2018 Building and Using Parallel Corpora (BUCC) 7
Back-Translated Text vs. Parallel Text ➢En-EnはEn-CS(1M) より、 SPを除いて高い相関 ➢同数の英文を用意すれば 同程度の性能
➢En-CS設定でSPは最高の パフォーマンスを発揮
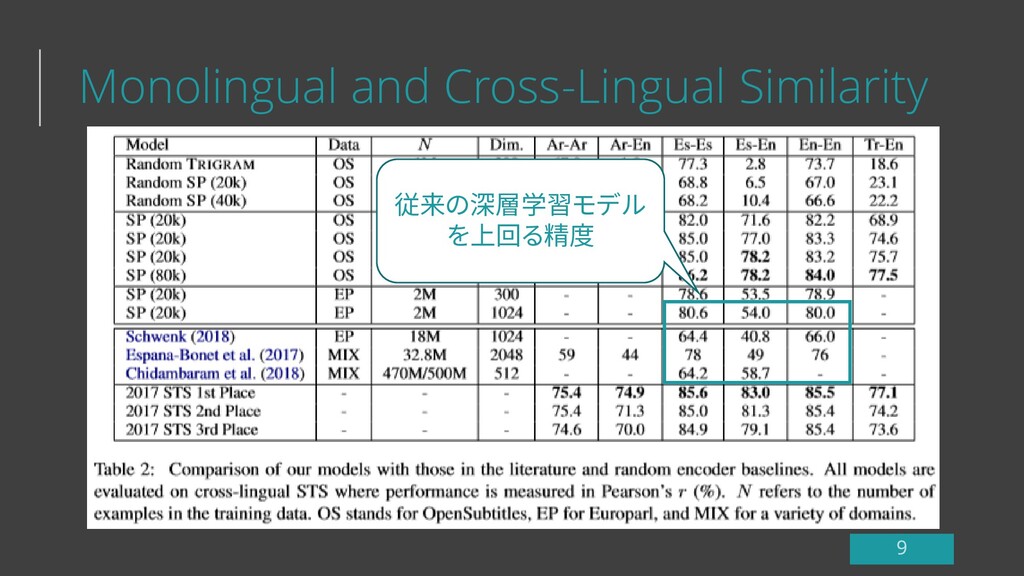
Monolingual and Cross-Lingual Similarity 従来の深層学習モデル を上回る精度
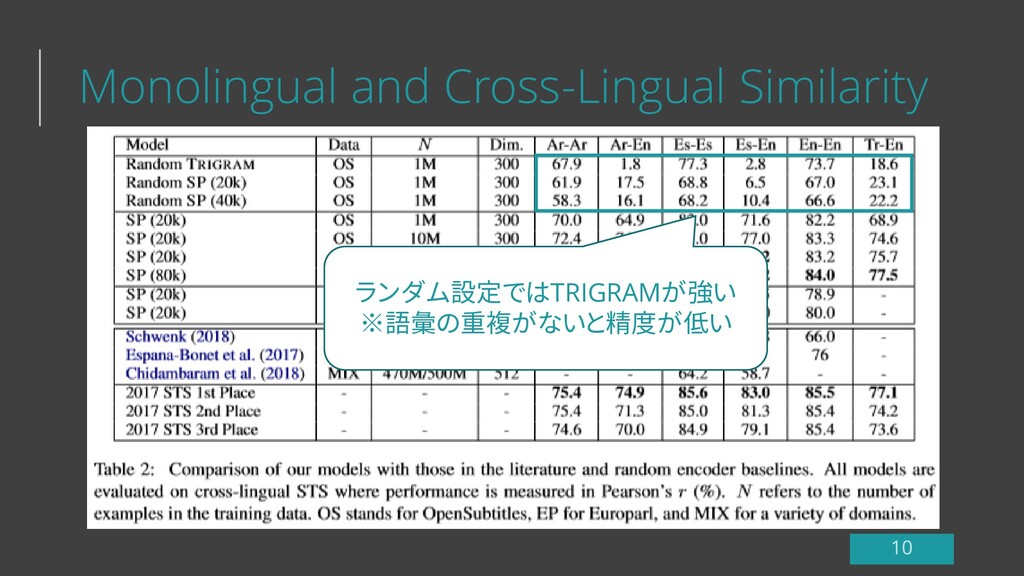
Monolingual and Cross-Lingual Similarity ランダム設定ではTRIGRAMが強い ※語彙の重複がないと精度が低い
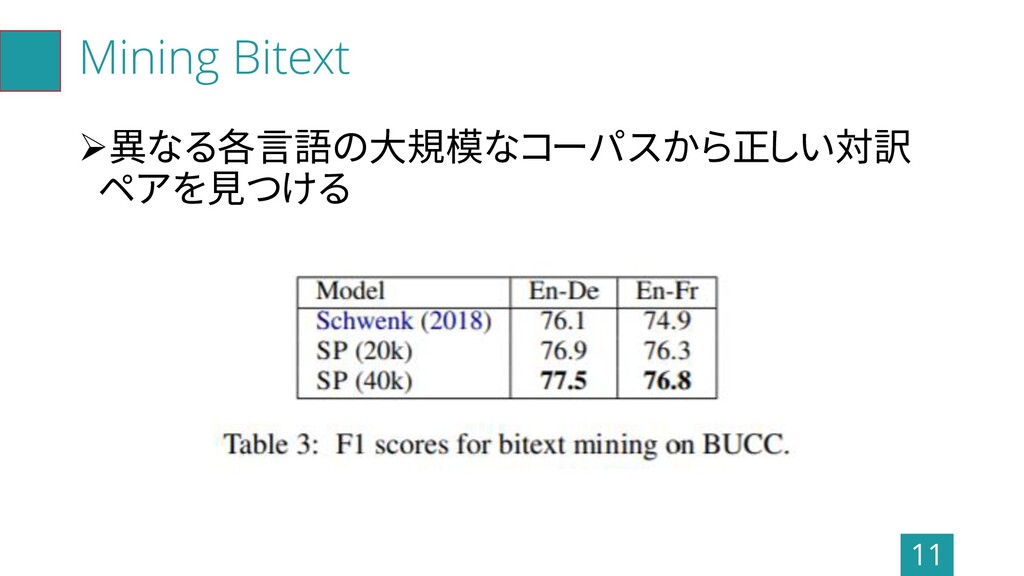
Mining Bitext ➢異なる各言語の大規模なコーパスから正しい対訳 ペアを見つける 11
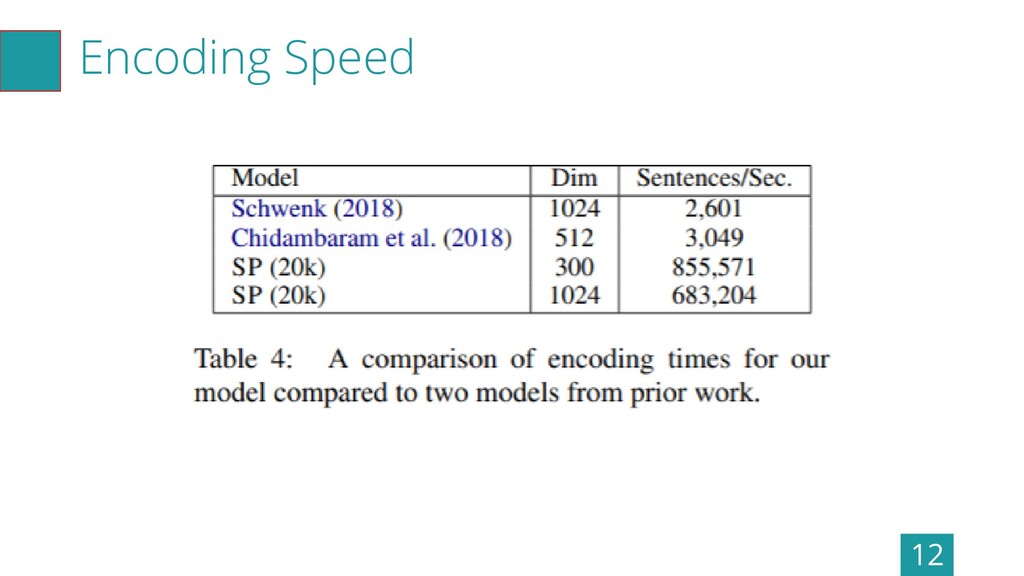
Encoding Speed 12
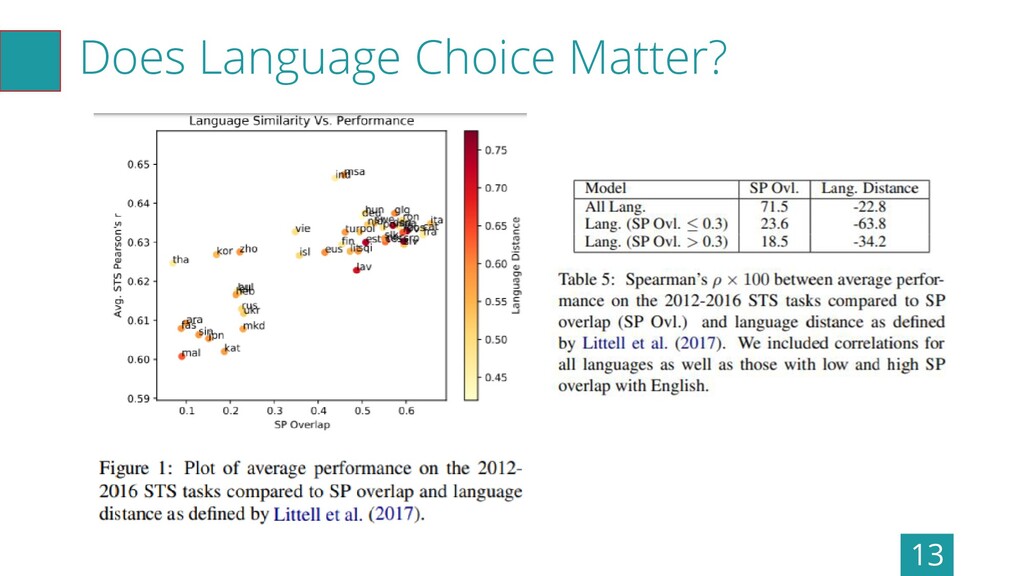
Does Language Choice Matter? 13
Conclusion ➢bitextを直接使用することにより精度の高い文の埋 め込みを作成 ➢ピボットや逆翻訳などを使用する必要がない ➢言語横断的表現が生成可能 ➢比較可能な従来の方法と比べて圧倒的に高速 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}