Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
“Cost-efficient and scalable ML-experiments in ...
Search
Keigo Hattori
May 28, 2020
Technology
2.8k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
“Cost-efficient and scalable ML-experiments in AWS with spot-instances, Kubernetes and Horovod” の紹介と感想
MLCT #12
https://mlct.connpass.com/event/172550/
Keigo Hattori
May 28, 2020
More Decks by Keigo Hattori
See All by Keigo Hattori
Rekcurd update and demo
keigohtr
0
610
What we need for MLOps
keigohtr
0
3.3k
Introduction of Machine Learning Production Pitch#1
keigohtr
0
3.7k
自動でツイッター要約をする執事ボット作った (API Meetup #28)
keigohtr
0
19k
API Meetup Tokyo #24 スマートスピーカーとAPI連携 LINE Clova
keigohtr
0
8k
API Meetup #22 LT大会(Apitore)
keigohtr
0
1.4k
AI x WebAPI もくもく会 Vol.1 イントロダクション
keigohtr
0
340
OneJapan企画提案ピッチ-大企業ハッカソン-
keigohtr
0
1.1k
API Meetup #17でのLT
keigohtr
0
630
Other Decks in Technology
See All in Technology
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
310
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
880
コンテナ・K8s研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
280
QA・ソフトウェアテスト研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
650
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
7
1.5k
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
1
390
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
330
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
530
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
100
Jitera Company Deck
jitera
0
570
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.3k
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
150
Featured
See All Featured
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.5k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.9k
From π to Pie charts
rasagy
0
240
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
A Tale of Four Properties
chriscoyier
163
24k
Building Applications with DynamoDB
mza
96
7.1k
RailsConf 2023
tenderlove
30
1.5k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
200
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Context Engineering - Making Every Token Count
addyosmani
9
1k
Accessibility Awareness
sabderemane
1
160
Transcript
“Cost-efficient and scalable ML-experiments in AWS with spot-instances, Kubernetes and
Horovod” の紹介と感想 MLOps enthusiast, @keigohtr #MLCT
Today’s topic “Cost-efficient and scalable ML-experiments in AWS with spot-instances,
Kubernetes and Horovod” について、ABEJA Platformの経験を踏まえて、ど こが良いと思ったかを紹介します 2
Who am I Keigo Hattori Software Engineer 3 2009.3 Tohoku
Univ / M.S. (Information Science) 2009.4~2017.10 Fuji Xerox / ML Engineer (NLP), etc 2017.11~2019.5LINE / Senior Software Engineer / Clova 2019.6~2020.5 ABEJA / Software Engineer / Platform 2020.5~ ??? MLOps 大好きです! @keigohtr
機械学習に関わる仕事とは? 4 学習 / Training 運用 / Operation
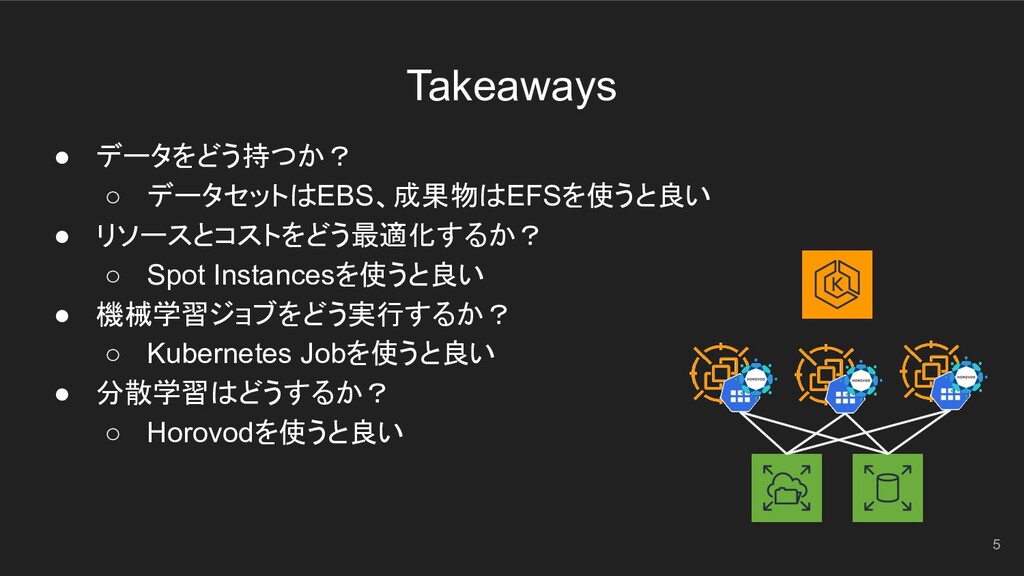
• データをどう持つか? ◦ データセットはEBS、成果物はEFSを使うと良い • リソースとコストをどう最適化するか? ◦ Spot Instancesを使うと良い •
機械学習ジョブをどう実行するか? ◦ Kubernetes Jobを使うと良い • 分散学習はどうするか? ◦ Horovodを使うと良い Takeaways 5
データをどう持つか? 6
AWSのストレージと特徴 7 S3 • 安い • 容量無限 • 堅牢性と可用性 が高い
• ファイル単位でア クセス EFS • 高い • 容量無限 • Multi-AZ • 複数インスタンス からマウント可能 EBS • 安い (S3よりは高い) • 容量は事前申告 • 単一 AZ • 単一インスタンス からマウント可能
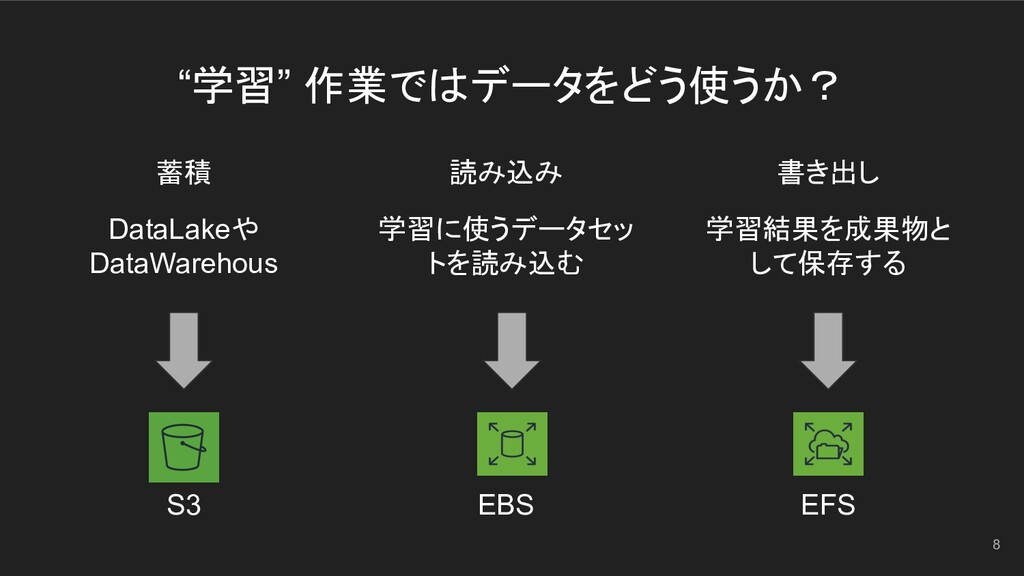
“学習” 作業ではデータをどう使うか? 8 蓄積 DataLakeや DataWarehous S3 書き出し 学習結果を成果物と して保存する
EFS 読み込み 学習に使うデータセッ トを読み込む EBS
“読み込み” にEBSを使う理由 9 学習における総実行時間が短縮できる • 機械学習(特に深層学習)では大量のデータを扱う = ファイル読み込みが多数発生する 他に選択肢がない •
goofys等でS3をマウントするのは安定しないので論外 • EFSと比べて早い O ur Experience
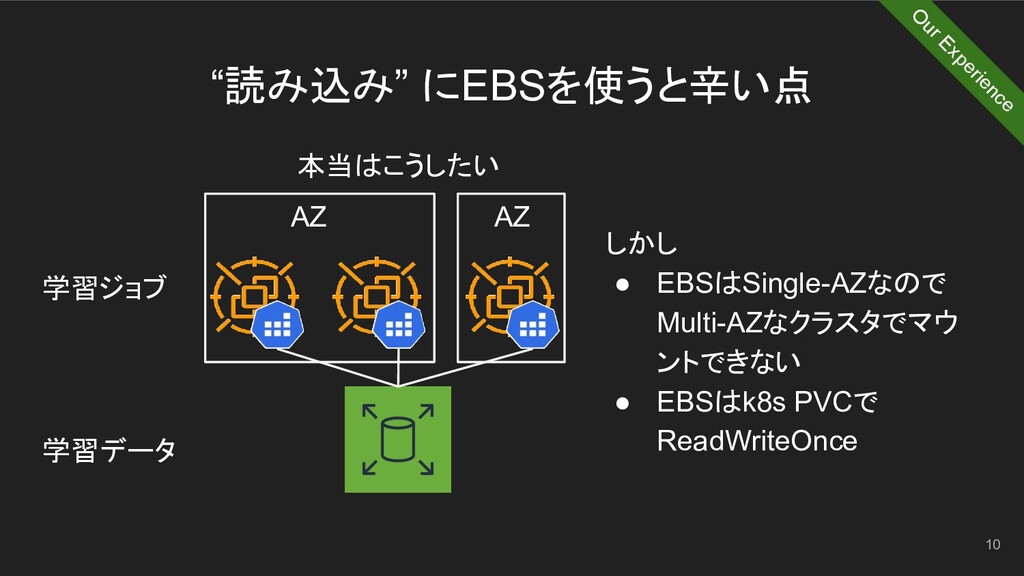
“読み込み” にEBSを使うと辛い点 10 本当はこうしたい AZ AZ 学習ジョブ 学習データ O ur
Experience しかし • EBSはSingle-AZなので Multi-AZなクラスタでマウ ントできない • EBSはk8s PVCで ReadWriteOnce
文献 (Rosebud AI) ではどうしたか? 11 • ジョブ毎にEBSを作成し、データセットをS3からコピーする • ジョブにマウントしたEBSはReadOnlyとして扱う •
ジョブが完了したらEBSは廃棄するか、次のジョブで再利用する ◦ EBSを再利用するとデータセットのコピーが省略できる = 次のジョブをすぐに走らせられる
ABEJA Platformではどうしているか? 12 • EBSを使わず、EFSを使っている ◦ EFSはMulti-AZかつMulti-attach ◦ ジョブがデータセットをS3からEFSにダウンロード ◦
EFSのダウンロード先はデータセット毎に固定し、並列するジョブが協 力してデータセットをダウンロード ※ 学習時にデータセット読み込みが非常に遅いので、見直し中 O ur Experience
“書き込み” にEFSを使う理由 13 成果物のサイズが予想できない • モデルのサイズはパラメータ次第 • 何を成果物に含めるかはユーザー次第 (e.g. ログファイル、ログの内容、中間モデル)
Disk fullでジョブが死ぬことを避けたい • 成果物のサイズが見積もれない(上記) • インスタンスで複数のジョブが同時に走ることもある = 他のユーザーのジョブでDisk fullになりうる O ur Experience
“書き込み” にEFSを使うと辛い点 14 • 気をつけないとクラウド破産する ◦ ユーザーはランニングコストを気にしない (容量は使えるだけ使う) ◦ 例えば、自然言語処理の場合、成果物が数十GBになることも。
試行錯誤やバージョニングで積み重なると・・・ O ur Experience
文献 (Rosebud AI) ではどうしたか? 15 • 成果物はEFSに置く • チェックポイントを設けて中間出力をEFSに置く •
ファイルはEFSの決められた場所に置く • 実験が中断したときに、中断したところから再開する • TensorBoardで各ジョブの結果を俯瞰できる
ABEJA Platformではどうしているか? 16 (文献に加え) • EFSを定期的に掃除して、ランニングコストを下げる • EFS掃除で成果物をロストしないように、ジョブ完了後に成果物を圧縮して S3にアップロードする •
(TensorBoardだけじゃなく、Jupyterも起動できる) O ur Experience
リソースとコストをどう最適化するか? 機械学習ジョブをどう実行するか? 17
やりたいこと • 可能な限りコストを抑え、しかし安定した計算クラスタを作る • スケーリングを自動化する ◦ 必要に応じてインスタンスが追加され、必要なければインスタンスが削 除されてほしい(スケールアウト、スケールイン) ◦ ↑をGPUサーバーでもやりたい
• 可能な限り効率的に機械学習ジョブを実行する ◦ 計算クラスタに詰め込めるだけ詰め込みたい = ジョブのキューイングとスケジューリング 18
文献 (Rosebud AI) ではどうしたか?(1/2) 19 • Spot Instancesを使った ◦ Spot
Instancesで安価な計算資源を確保 ◦ EKSで計算クラスタを構築 • Kubernetes Jobを使った ◦ ジョブのキューイングとスケジューリングはk8s
文献 (Rosebud AI) ではどうしたか?(2/2) 20 • Kubernetes Jobの突然死に対応した ◦ Spot
Instancesのインスタンスは取り上げられることがある = KubernetesのJobが突然死する ◦ そこで、少なくとも10分に1度、チェックポイントとして学習の途中経過 をEFSに保存した ◦ Jobが失敗/突然死した場合、KubernetesはJobを再実行する ◦ JobはEFSを参照し、チェックポイントから学習を再開する
ABEJA Platformではどうしているか?(1/3) 21 • Spot Instancesを管理するSpotInstを利用した ◦ Ref: スポットインスタンスを効率的に管理するSpotinstを使おう O
ur Experience
ABEJA Platformではどうしているか?(2/3) 22 • インスタンスに使うイメージを固定した ◦ ユーザーがどのCUDAを使うか分からないので、All-in-Oneな機械学 習用のAMIを使う • インスタンスの種類を固定した
◦ CPU/メモリをユーザーに選ばせると、インスタンスの利用効率(e.g. Podがうまくハマらない)が悪くなる = ランニングコストが悪くなる ◦ “インスタンスのスペック” ≒ ”Podのスペック” にした O ur Experience
ABEJA Platformではどうしているか?(3/3) 23 • ユーザーのコードはEFS上で動かした ◦ ユーザーのコードサイズが見積もれない = Disk fullで死ぬ可能性がある
◦ そこで、PodにEFSをマウントする ◦ EFS上にユーザーのコードをダウンロードし、実行する O ur Experience
分散学習はどうするか? 24
やりたいこと • 複数のGPUを使った分散学習をやりたい • ただし既存のコードはなるべく変更したくない 25
文献 (Rosebud AI) ではどうしたか?(1/2) 26 • Horovodを採用した ◦ 複雑性を回避するため、複数のインスタンスは使わない ◦
Multi-GPUを搭載したインスタンスで分散学習をする ◦ Horovodが提供するDocker Imageとサンプルコードが大変便利
文献 (Rosebud AI) ではどうしたか?(2/2) 27 (Spot InstancesによるJobの突然死への対応として) • master-workerに以下を担当させた ◦
masterが他のworkerの変数を初期化する ◦ チェックポイントの書き出しをする ◦ チェックポイントからの復元をする • 乱数を固定する ◦ シャッフリングやdata splitを再現させるため
ABEJA Platformではどうしているか? 28 • To Be Continued ◦ 現在、分散学習を公式にはサポートしていない (ただし、自分でやれば使える)
O ur Experience
• データをどう持つか? ◦ データセットはEBS、成果物はEFSを使うと良い • リソースとコストをどう最適化するか? ◦ Spot Instancesを使うと良い •
機械学習ジョブをどう実行するか? ◦ Kubernetes Jobを使うと良い • 分散学習はどうするか? ◦ Horovodを使うと良い Retrospective 29
Thank you! 30
• Cost-efficient and scalable ML-experiments in AWS with spot-instances, Kubernetes
and Horovod • スポットインスタンスを効率的に管理するSpotinstを使おう • 顧客のアプリケーションコードが動くマルチテナント環境における課題と EKSにたどり着くまで Reference 31
32 Q & A
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}