a bustling futuristic cityscape, where sleek, high-tech vehicles navigate through a well-lit, multi-level urban environment. The atmosphere is lively, filled with the sounds of engines and the distant hum of city life. The camera captures the essence of this advanced world, showcasing a mix of modern architecture and dynamic street life. As the video progresses, the focus shifts to a striking black sports car, its sleek design and glowing red taillights drawing the viewer's attention. The car glides effortlessly through the streets, embodying the essence of speed and elegance. The surrounding environment is alive with activity, featuring a variety of vehicles, including a distinctive orange car that adds a splash of color to the scene. The camera work is dynamic, employing a mix of wide shots that capture the expansive nature of the city and close-ups that highlight the intricate details of the vehicles. The lighting is bright and vibrant, enhancing the futuristic feel of the setting. The soundtrack is a blend of electronic beats and ambient sounds, creating a sense of urgency and excitement. The narrative unfolds as the main character, a driver in a sleek black sports car, embarks on a journey through this vibrant world. The character's actions are fluid and confident, reflecting a sense of purpose and determination. The dialogue is minimal, allowing the visuals to convey the story, with occasional voiceovers that provide context and insight into the character's thoughts and motivations. As the video nears its conclusion, the focus shifts to a dramatic moment where the main character is seen driving through a tunnel, illuminated by bright lights that create a striking contrast against the dark interior of the car. The camera captures the intensity of the moment, emphasizing the character's focus and determination. The scene is filled with a sense of anticipation, as the character approaches a critical point in their journey. The video concludes with a poignant moment, as the main character reflects on their journey and the lessons they have learned. The character's thoughts are conveyed through a series of voiceovers, providing a deeper understanding of their motivations and the challenges they have faced. The camera work remains dynamic, with close-ups that highlight the character's emotions and the surrounding environment. Throughout the video, the use of special effects and visual effects enhances the futuristic feel, creating a sense of wonder and excitement. The camera work is smooth and polished, with a focus on capturing the character's journey in a visually engaging manner. The lighting and color palette are carefully chosen to evoke a sense of energy and vibrancy, while the sound design complements the visuals, enhancing the overall experience.
{kind=link}
{kind=link}
![背景︓ビデオキャプション⽣成は⻑尺動画および⻑⽂の扱いに課題 3 n ⻑尺動画において,フレーム数とともに計算量が増⼤ [Wang+, ACL24] →トークン圧縮⼿法 [Li+, ECCV24] n](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_2.jpg){kind=link}
![関連研究︓動画を扱うためのトークン圧縮の⼿法 4 Video-LLaMA MovieChat ⼿法 概要 MovieChat [Song+, CVPR24] トークン圧縮の⼿法として隣接するフレーム間のトークンの類似度に基](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_3.jpg){kind=link}
![提案⼿法: アーキテクチャ 5 AuroraCap: LLaVA-1.5 [Liu+, NeurIPS23]と同様の構成 n LLM n](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_4.jpg){kind=link}
![提案⼿法: 段階的な画像トークン圧縮 6 Token merging: 画像や映像の分類・編集タスク [Li+, CVPR24]において有効なトークン圧縮⼿法 n ViTのSelf-Attention層後にトークン圧縮](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_5.jpg){kind=link}
![提案⼿法: 段階的な画像トークン圧縮 7 Token merging: 画像や映像の分類・編集タスク [Li+, CVPR24]において有効なトークン圧縮⼿法 n ViTのSelf-Attention層後にトークン圧縮](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_6.jpg){kind=link}
![提案⼿法: 段階的な画像トークン圧縮 8 Token merging: 画像や映像の分類・編集タスク [Li+, CVPR24]において有効なトークン圧縮⼿法 n ViTのSelf-Attention層後にトークン圧縮](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_7.jpg){kind=link}
![提案⼿法: 段階的な画像トークン圧縮 9 Token merging: 画像や映像の分類・編集タスク [Li+, CVPR24]において有効なトークン圧縮⼿法 n ViTのSelf-Attention層後にトークン圧縮](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_8.jpg){kind=link}
![提案⼿法: 段階的な画像トークン圧縮 10 Token merging: 画像や映像の分類・編集タスク [Li+, CVPR24]において有効なトークン圧縮⼿法 n ViTのSelf-Attention層後にトークン圧縮](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_9.jpg){kind=link}
![提案⼿法: 段階的な画像トークン圧縮 11 Token merging: 画像や映像の分類・編集タスク [Li+, CVPR24]において有効なトークン圧縮⼿法 n ViTのSelf-Attention層後にトークン圧縮](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_10.jpg){kind=link}
![提案⼿法: 段階的な画像トークン圧縮 12 Token merging: 画像や映像の分類・編集タスク [Li+, CVPR24]において有効なトークン圧縮⼿法 n ViTのSelf-Attention層後にトークン圧縮](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_11.jpg){kind=link}
{kind=link}
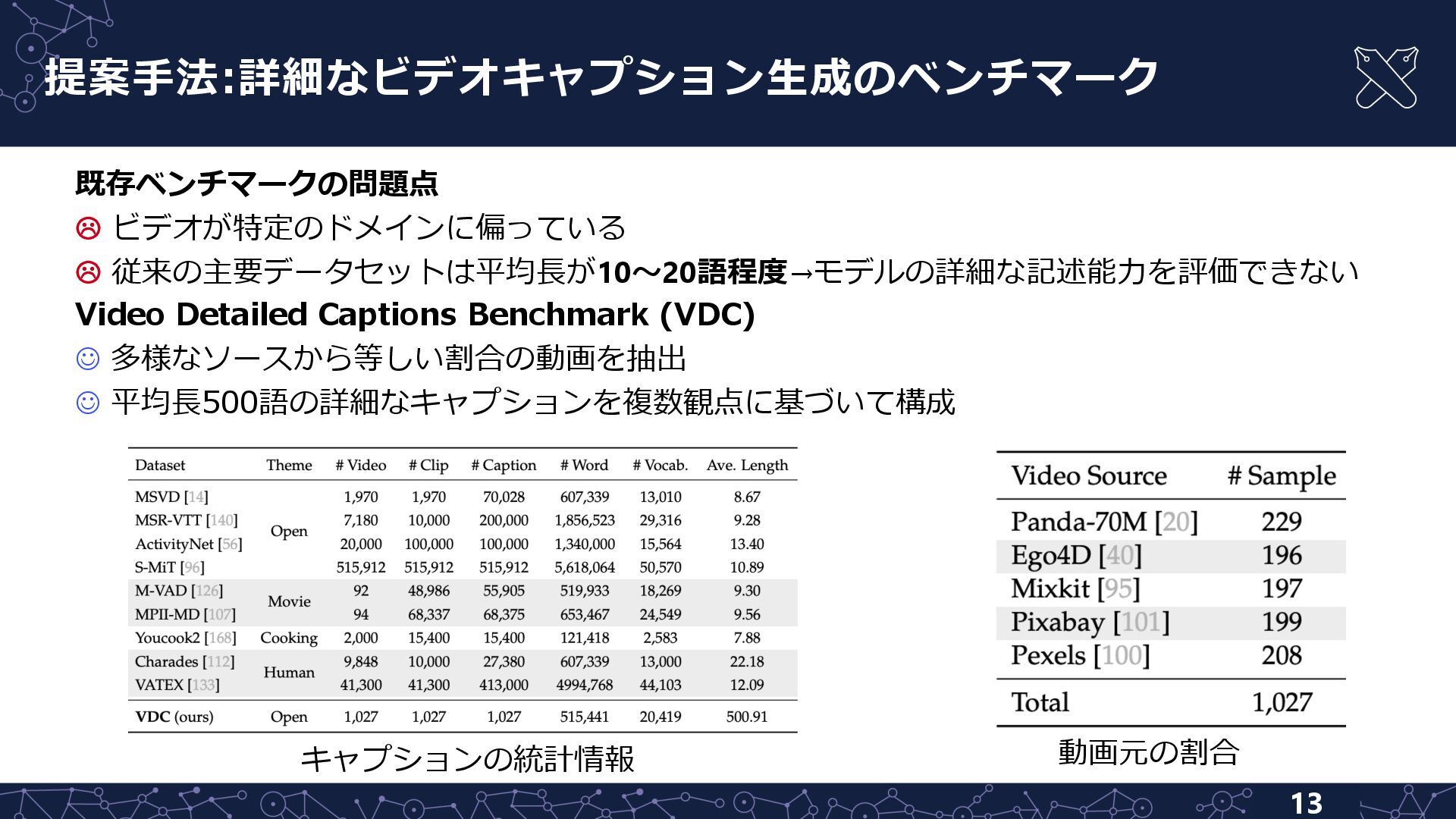
![提案⼿法:VDC Benchmarkの構築 14 ビデオ収集 複数のドメインの動画を同程度の割合で抽出 n Panda-70M [Chen+, CVPR20]: YouTubeの野⽣動物,料理,スポーツなど多様なドメインの1分動画](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_13.jpg){kind=link}
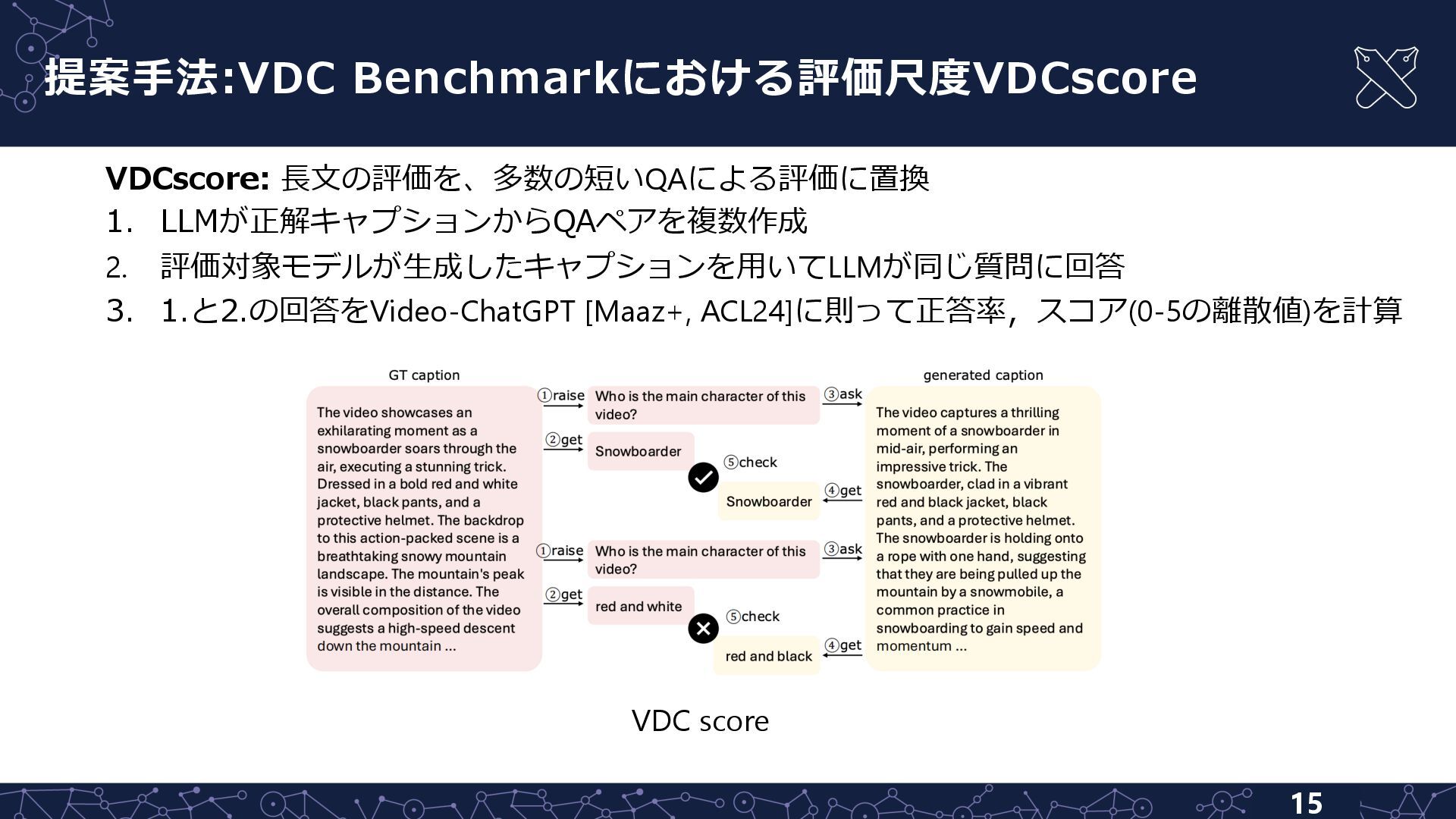{kind=link}
![実験設定 16 AuroraCapのバックボーン n LLM: Vicuna-v1.5(7B) [Zheng+, NeurIPS23] n Projector:](https://files.speakerdeck.com/presentations/8838d33040fe41359a80003fc03b255d/slide_15.jpg){kind=link}
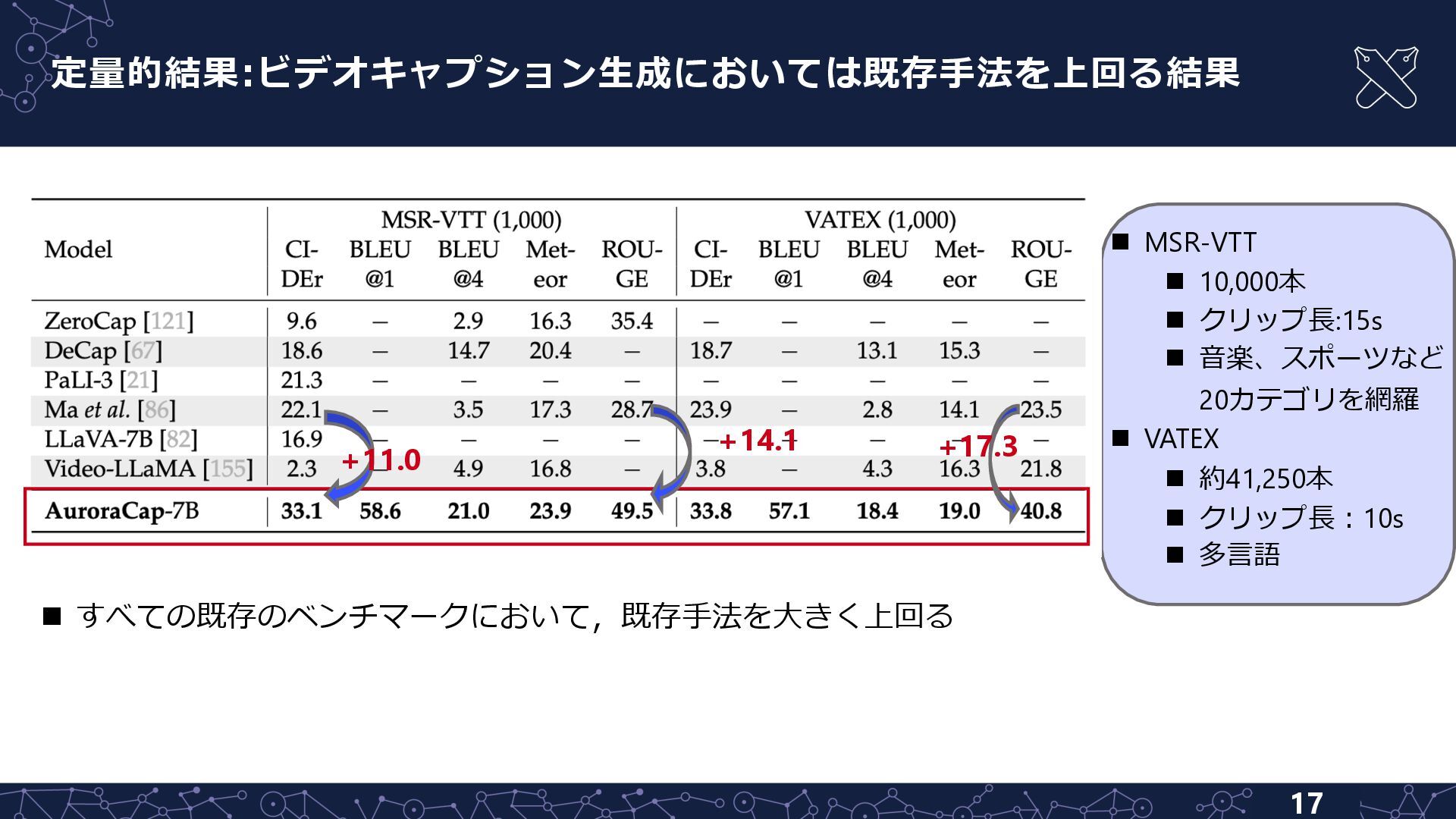{kind=link}
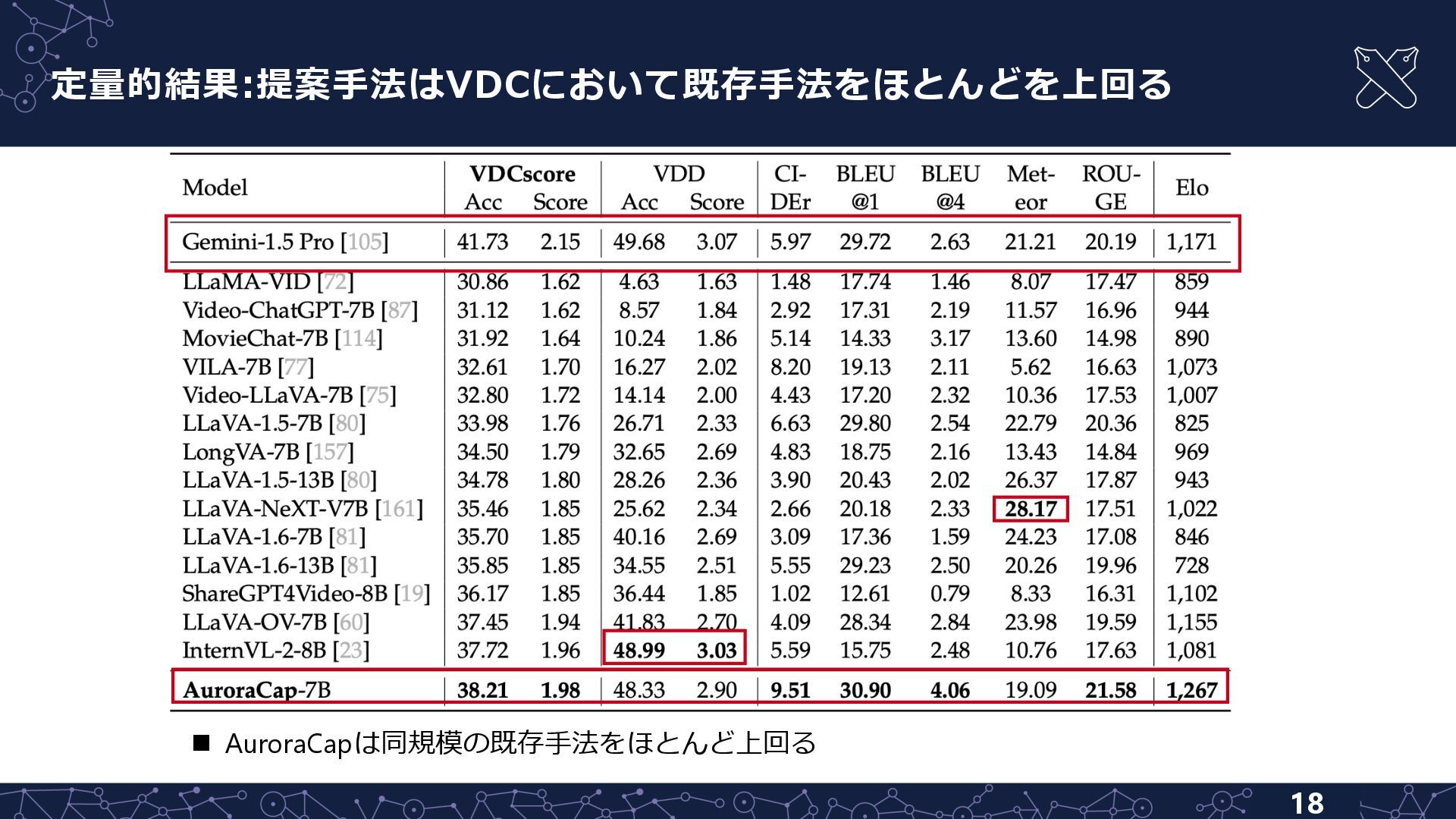{kind=link}
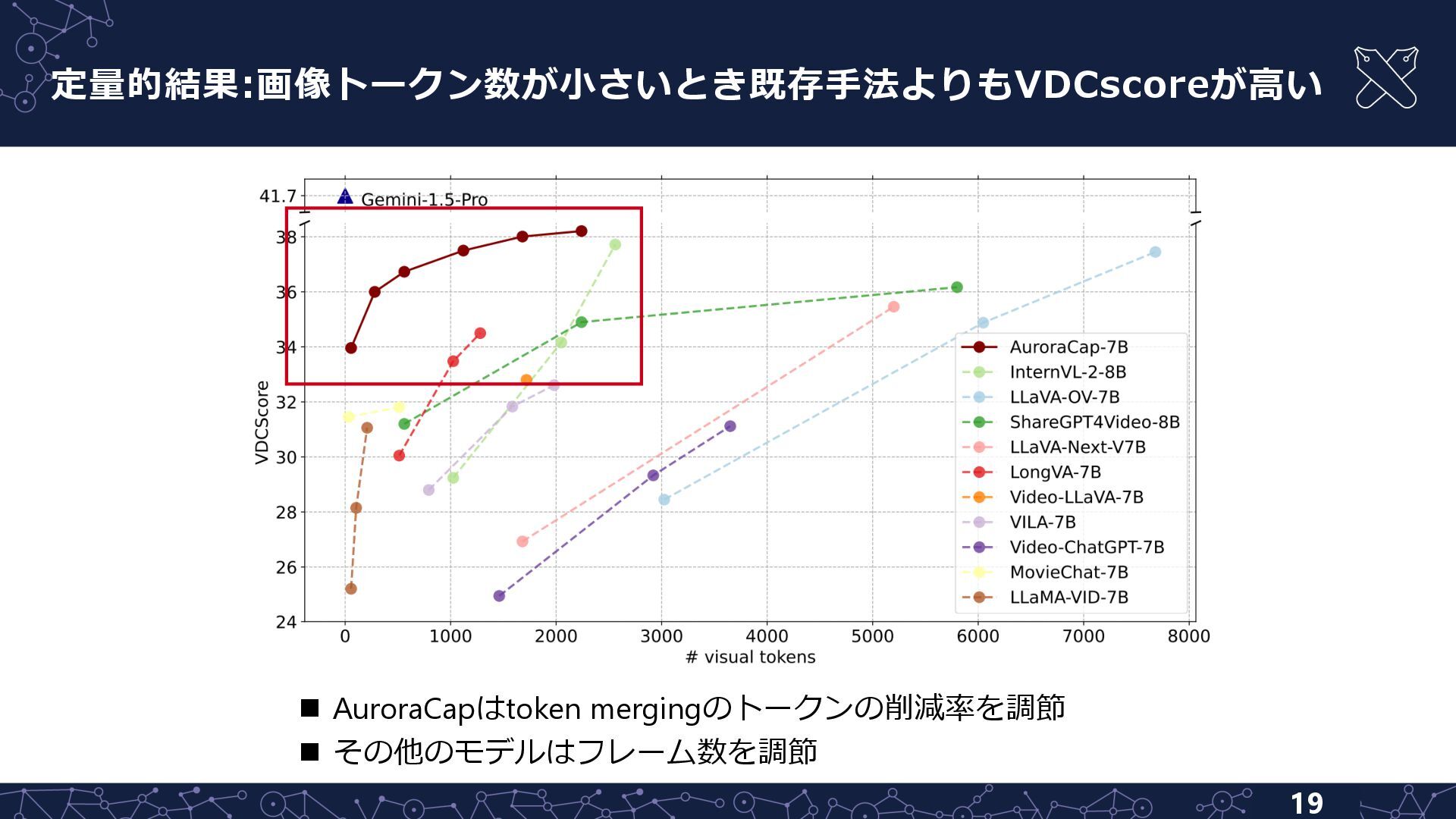{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
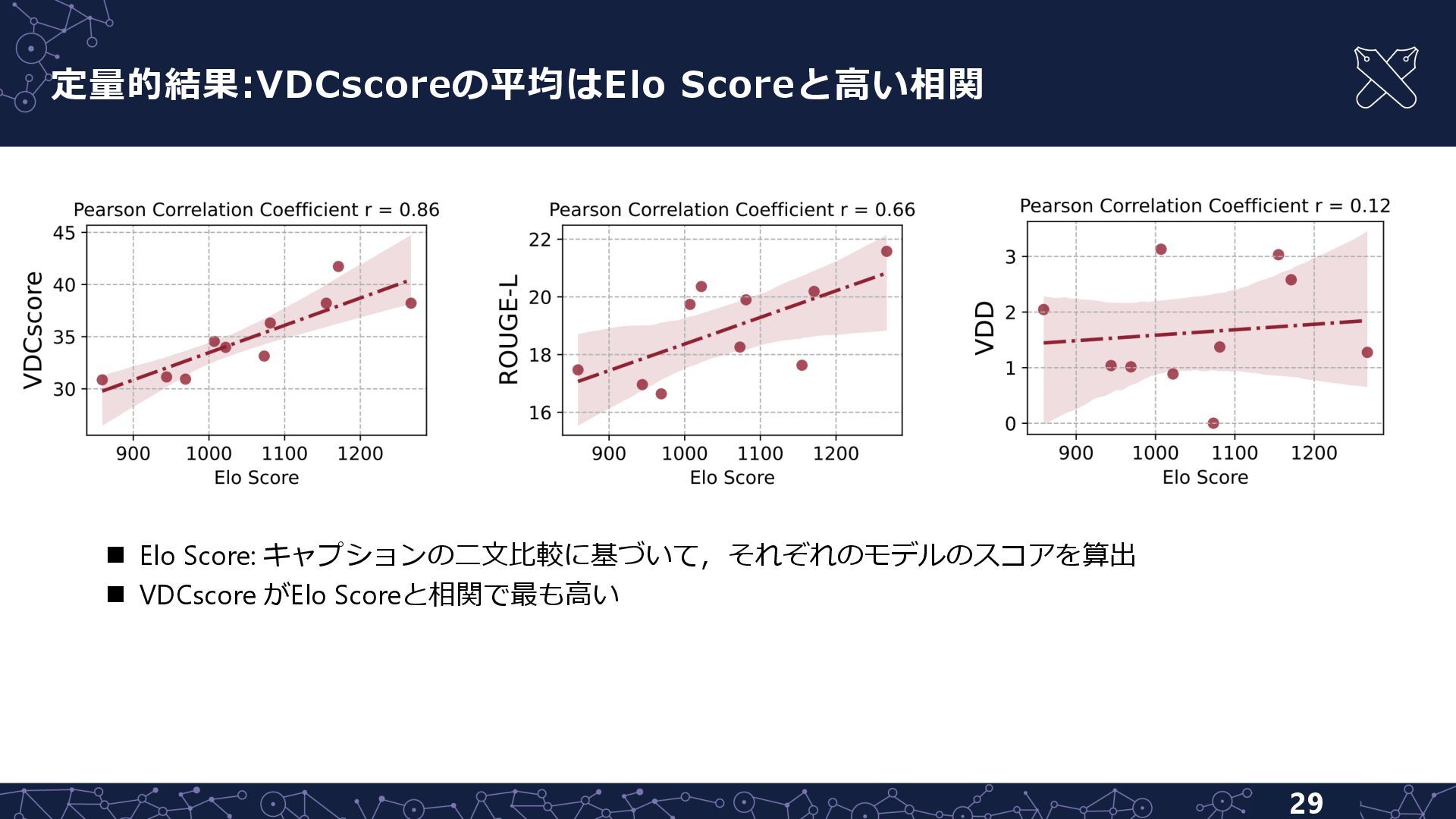{kind=link}
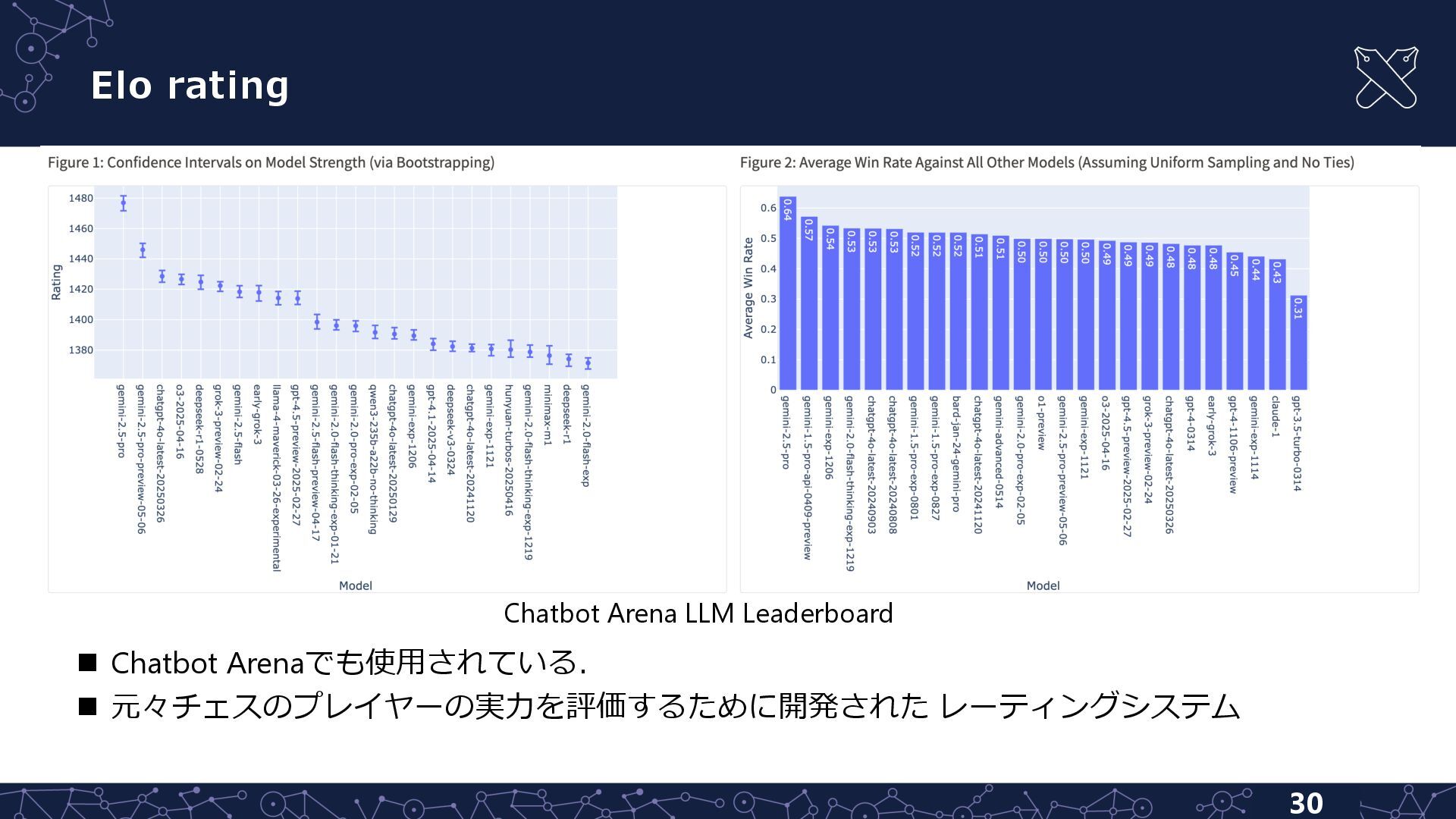{kind=link}
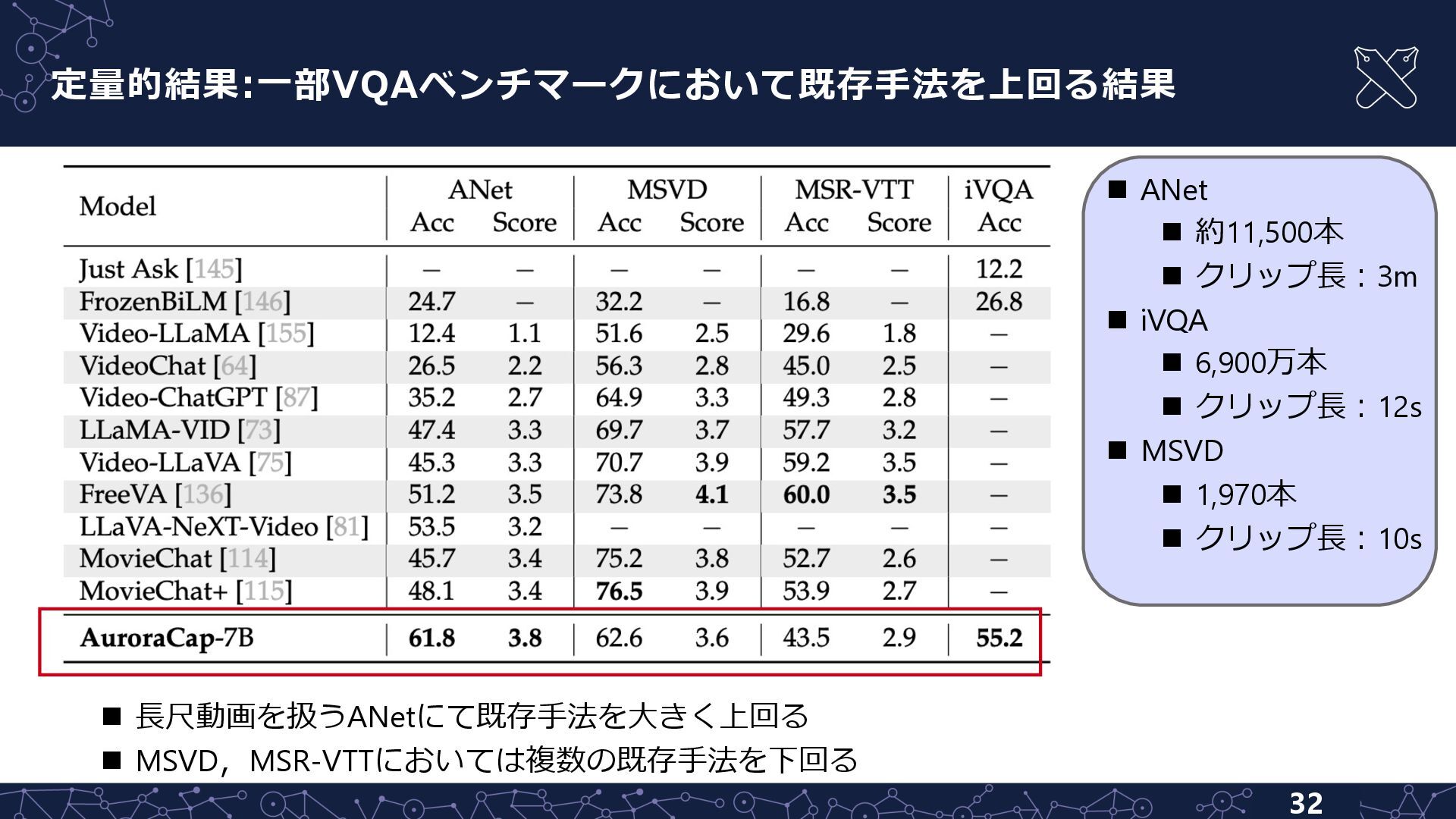{kind=link}
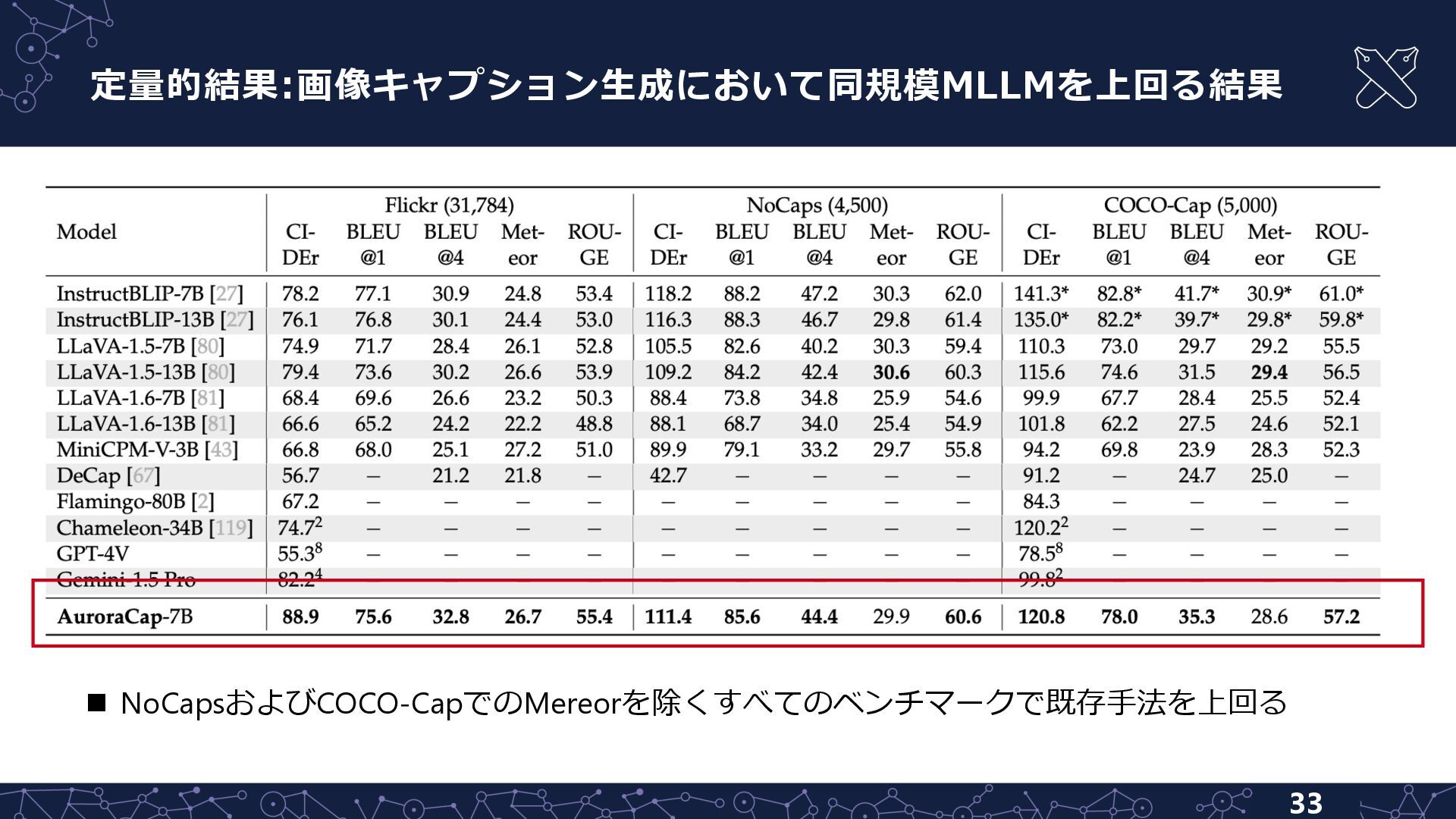{kind=link}
{kind=link}
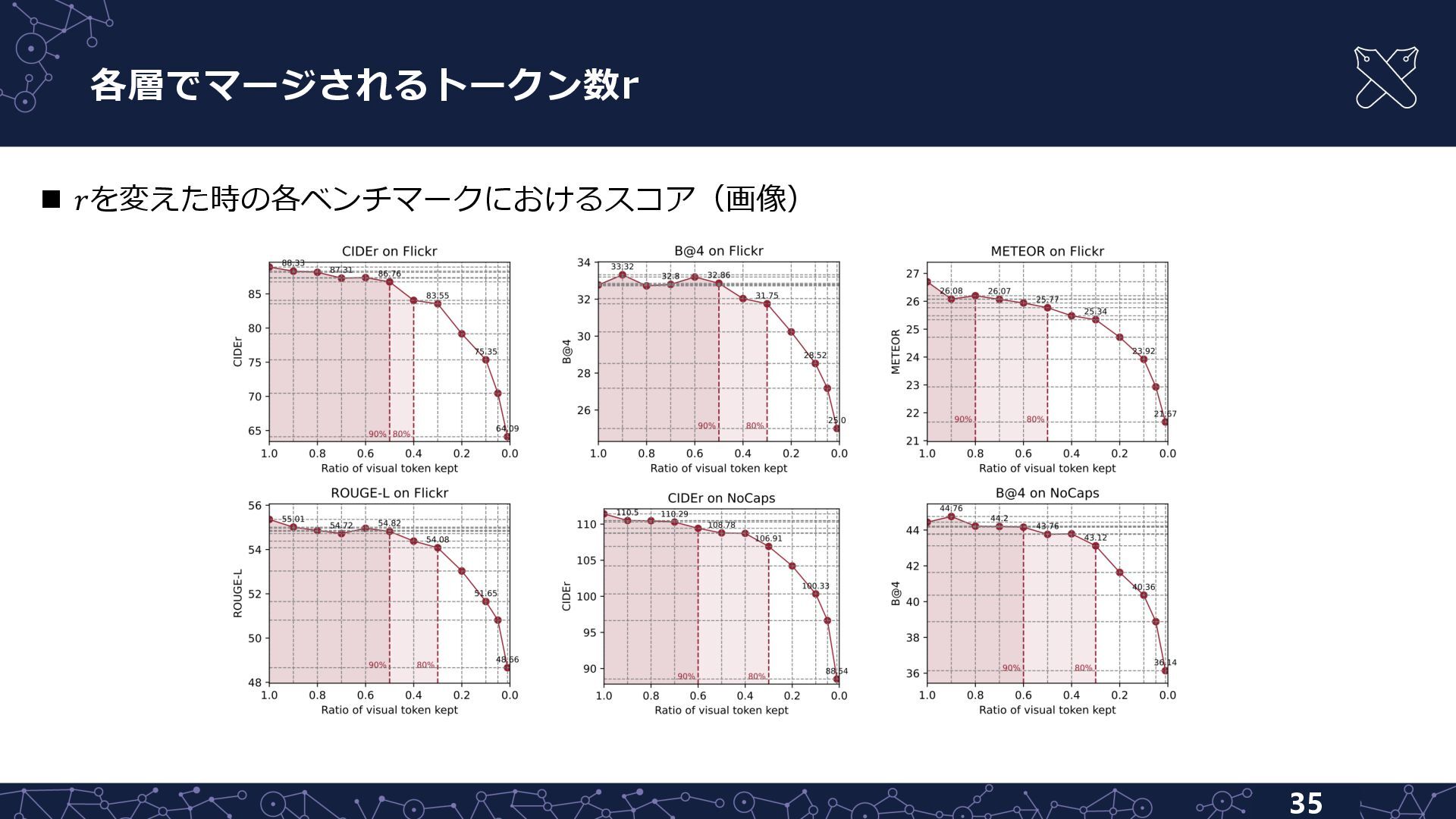{kind=link}
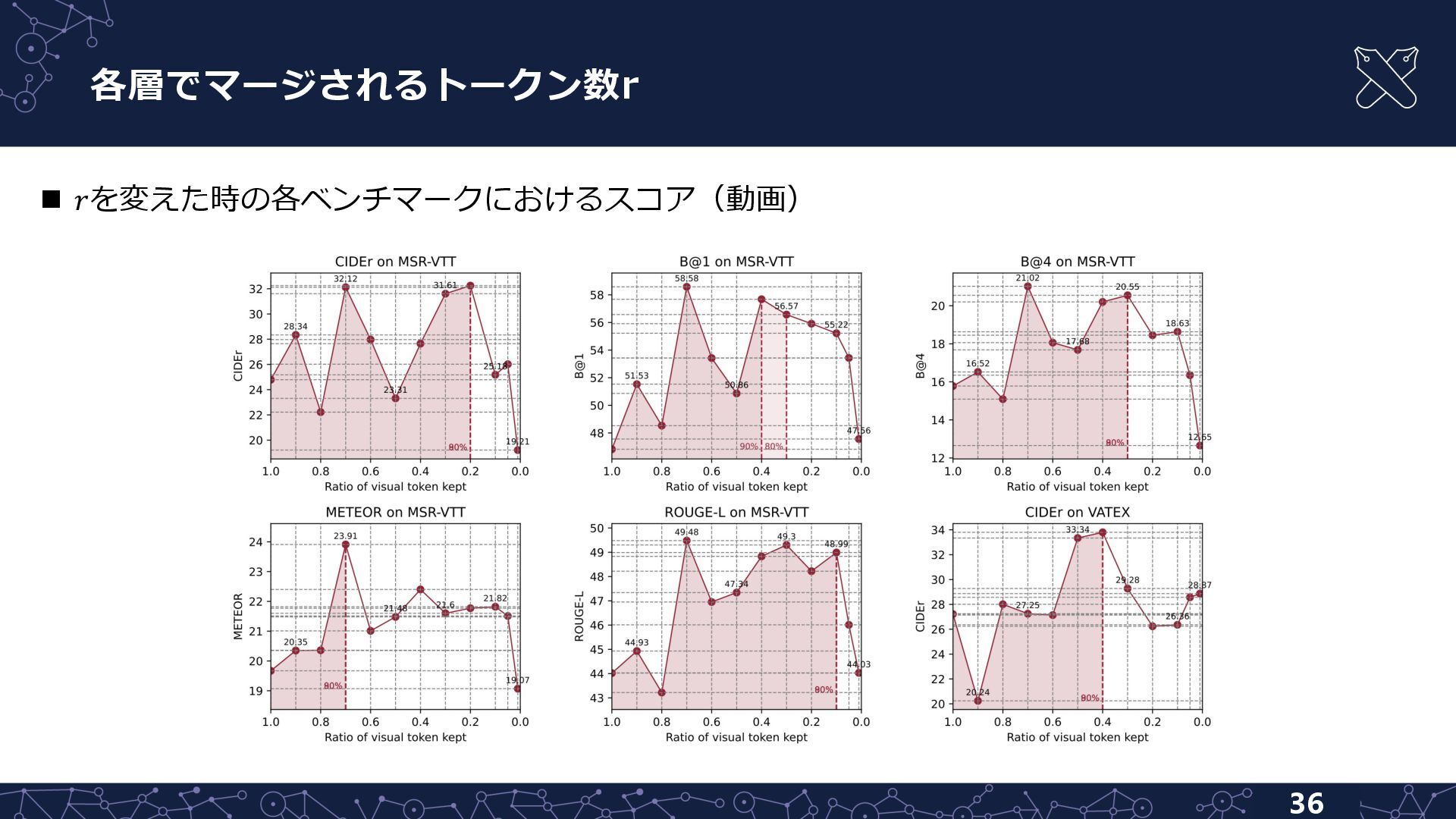{kind=link}
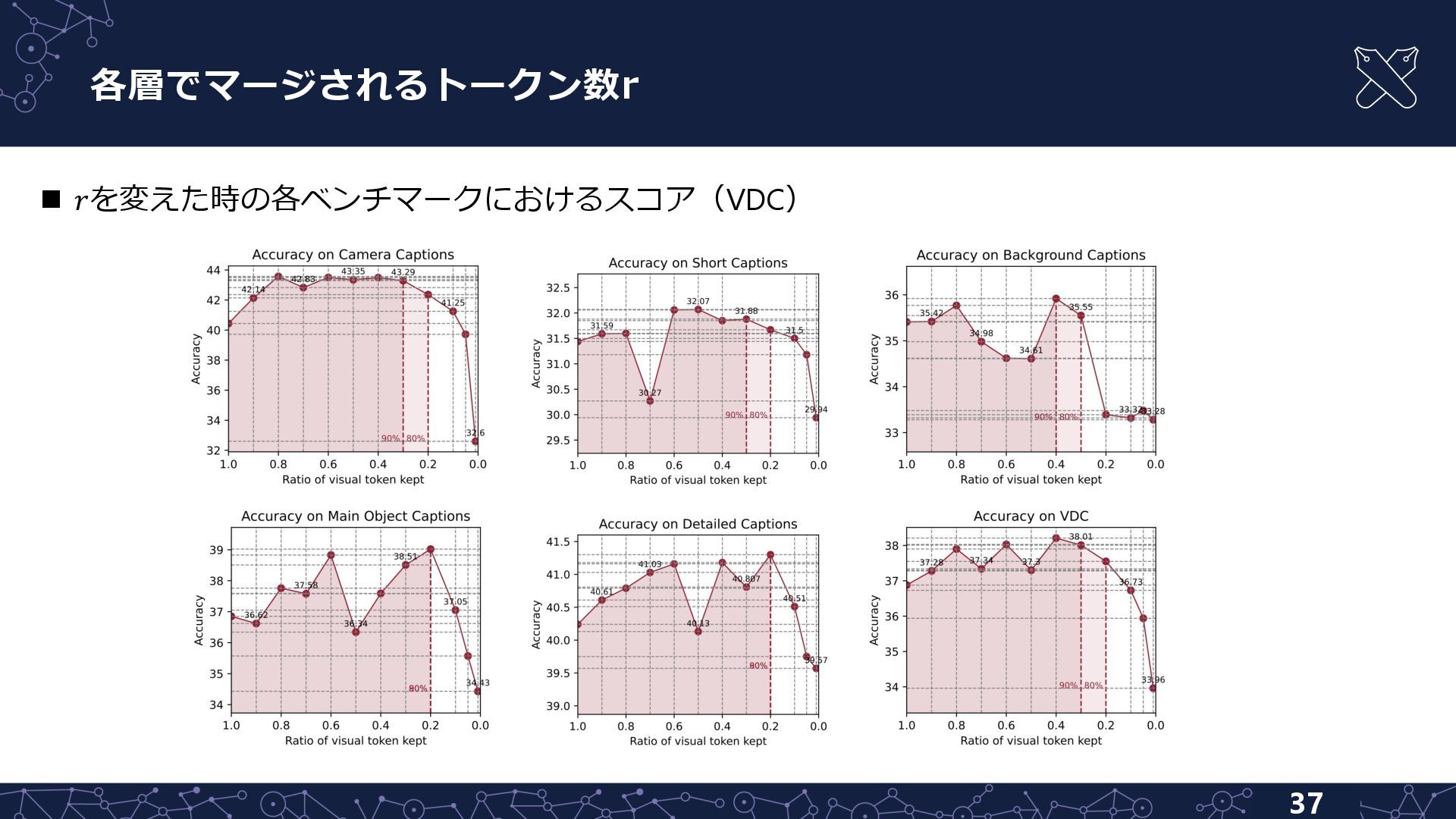{kind=link}
{kind=link}
{kind=link}