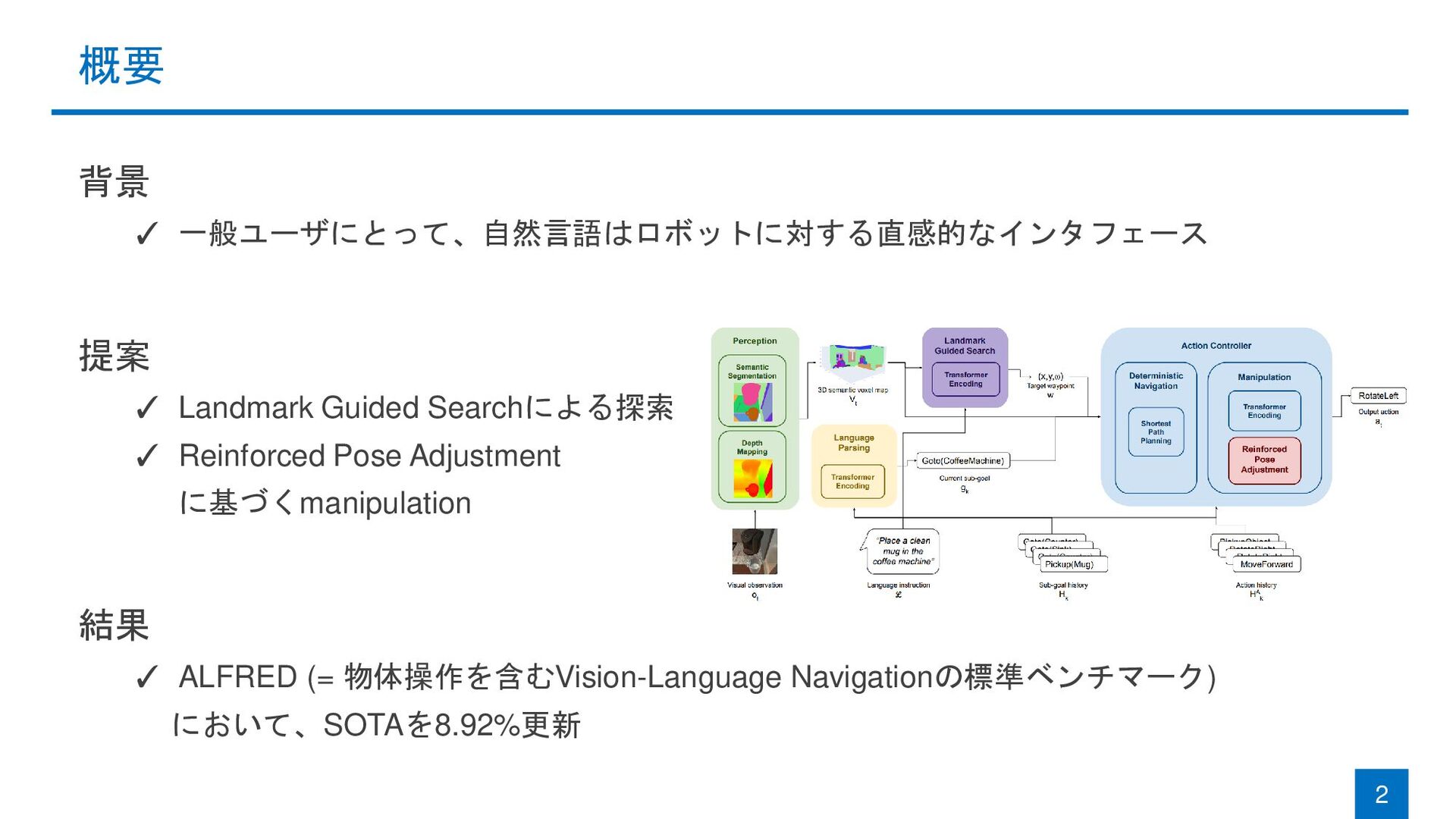
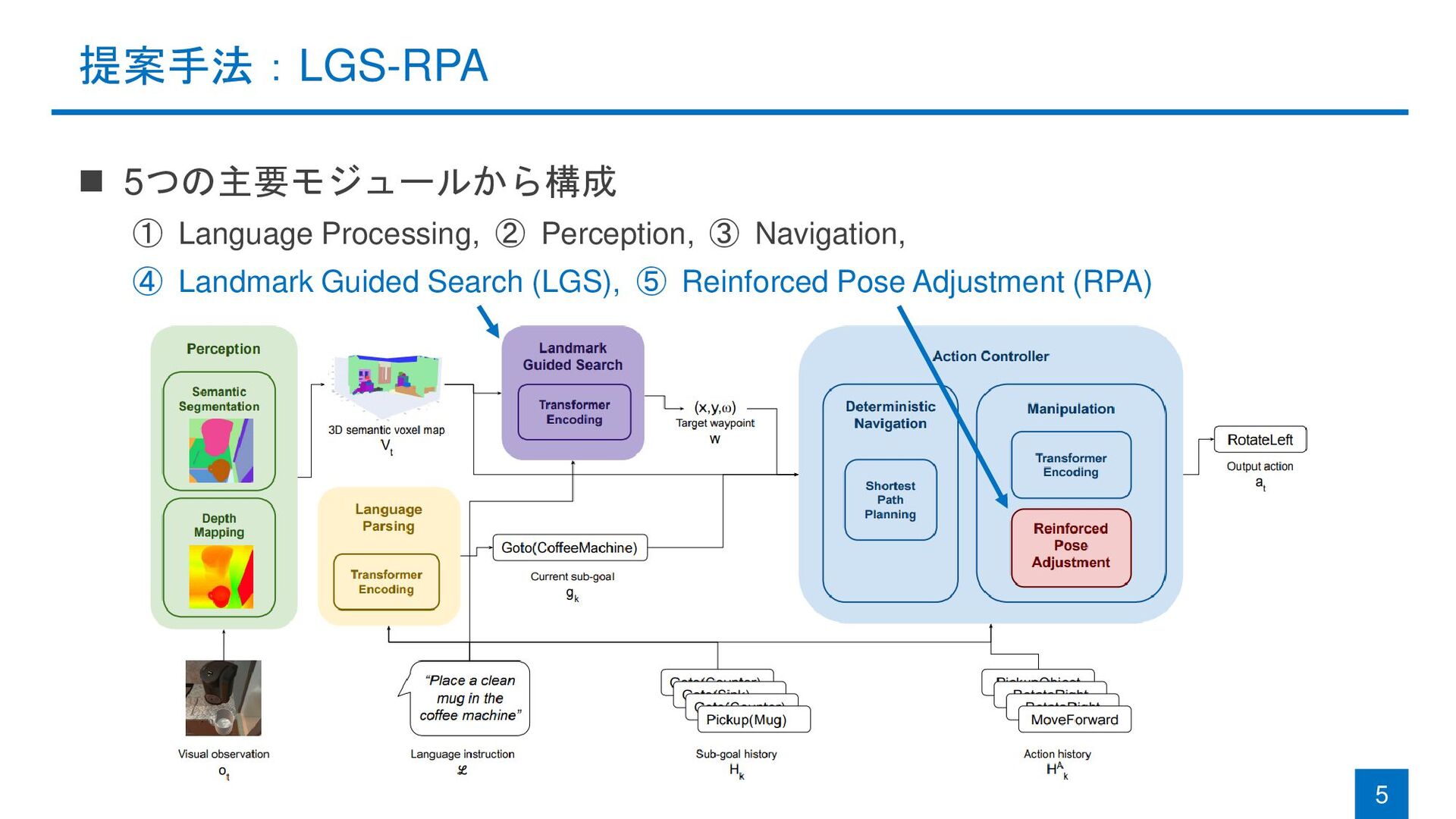
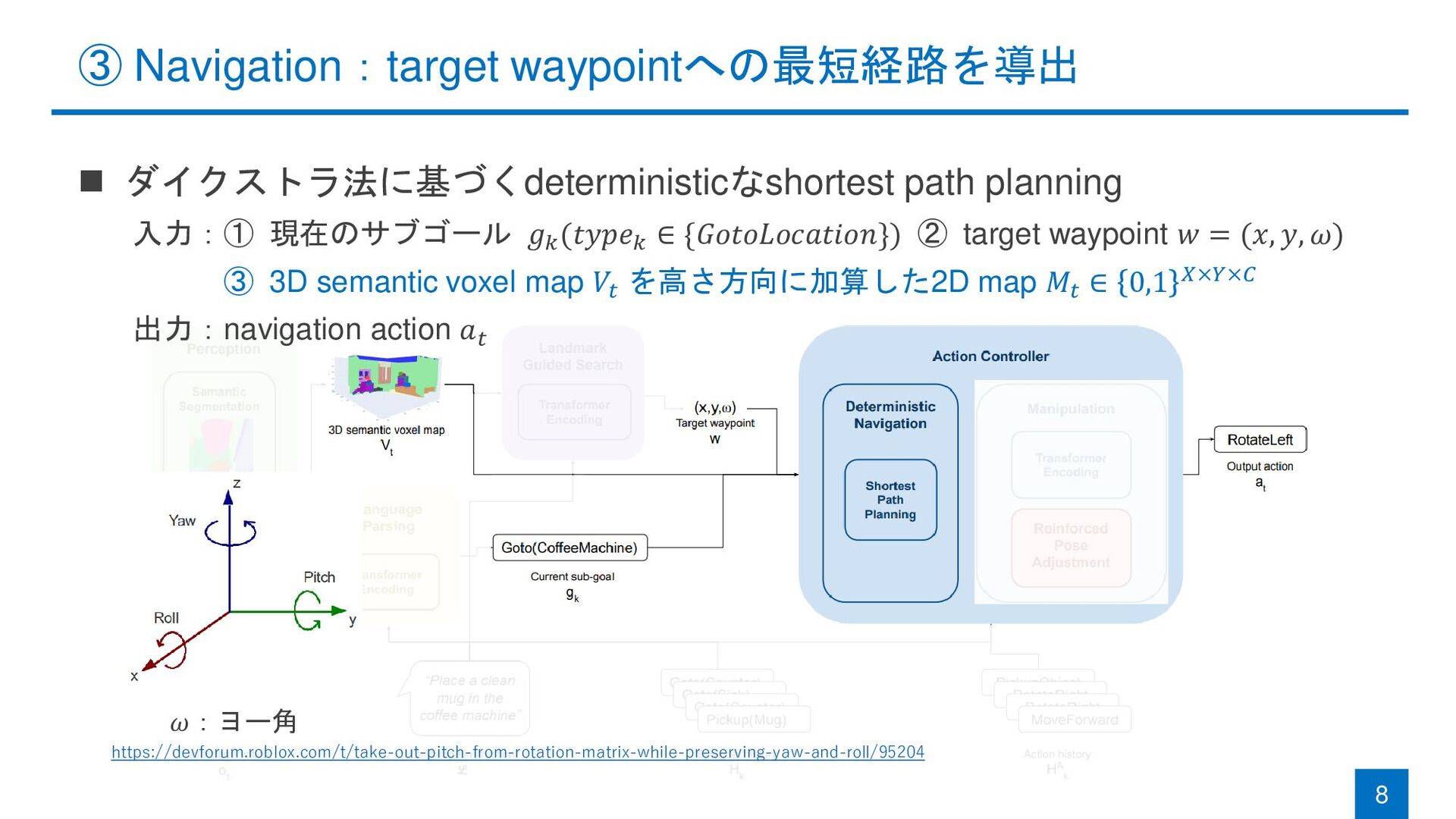
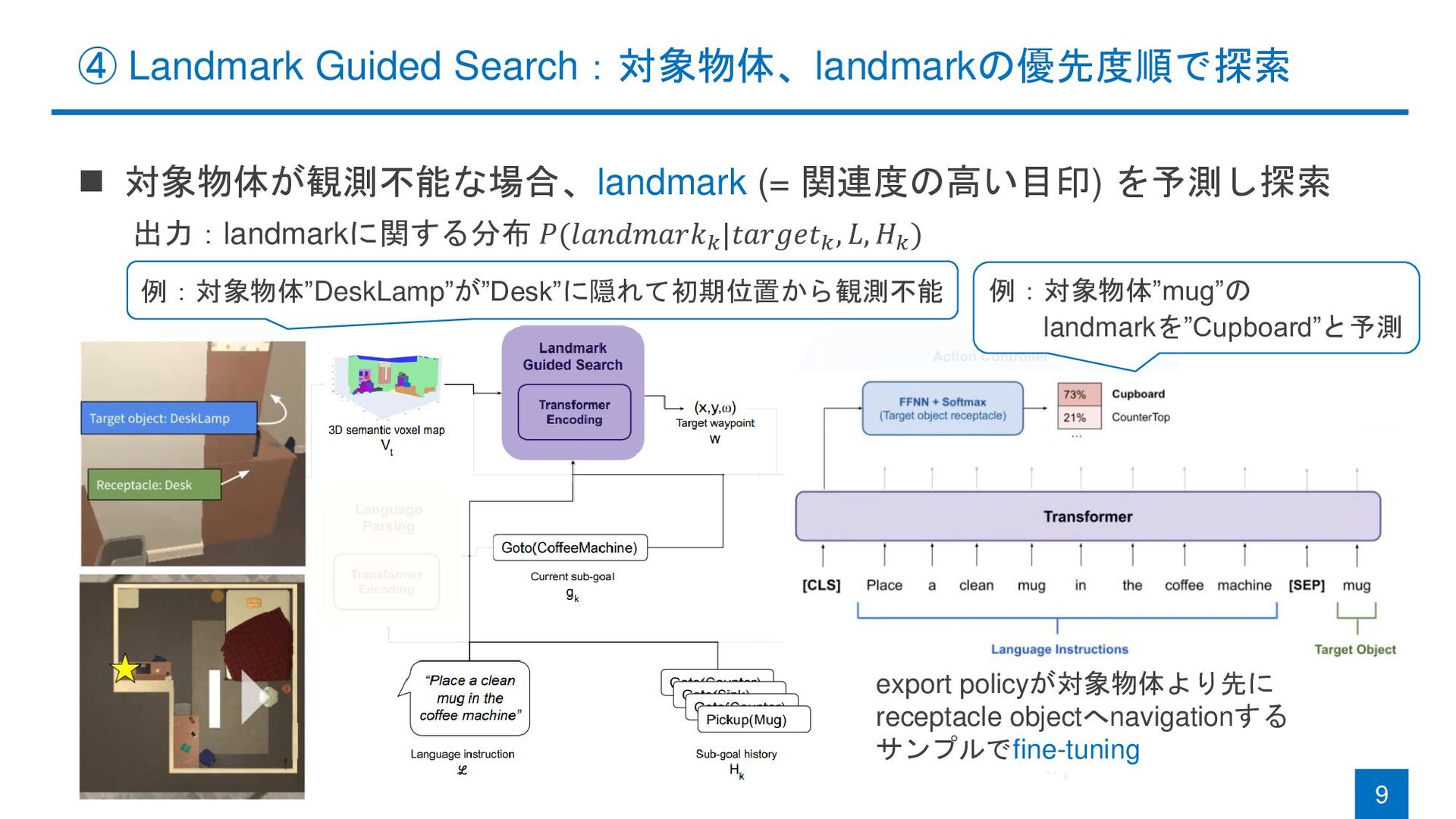
with Landmark Guided Search and Reinforced Pose Adjustment Michael Murray and Maya Cakmak (University of Washington) RA-L & IROS 2022 Michael Murray and Maya Cakmak. "Following Natural Language Instructions for Household Tasks with Landmark Guided Search and Reinforced Pose Adjustment." RA-L 2022.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![① Language Processing:次のサブゴールを予測 ◼ 2つのBERT [Devlin+, NAACL19] transformerで構成 入力:① 指示文](https://files.speakerdeck.com/presentations/3a1fda53d41d4f61b234b79be0497977/slide_5.jpg){kind=link}
![② Perception:3D semantic voxel mapを更新 ◼ HLSM [Blukis+, CoRL21] と同様に、U-Net](https://files.speakerdeck.com/presentations/3a1fda53d41d4f61b234b79be0497977/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
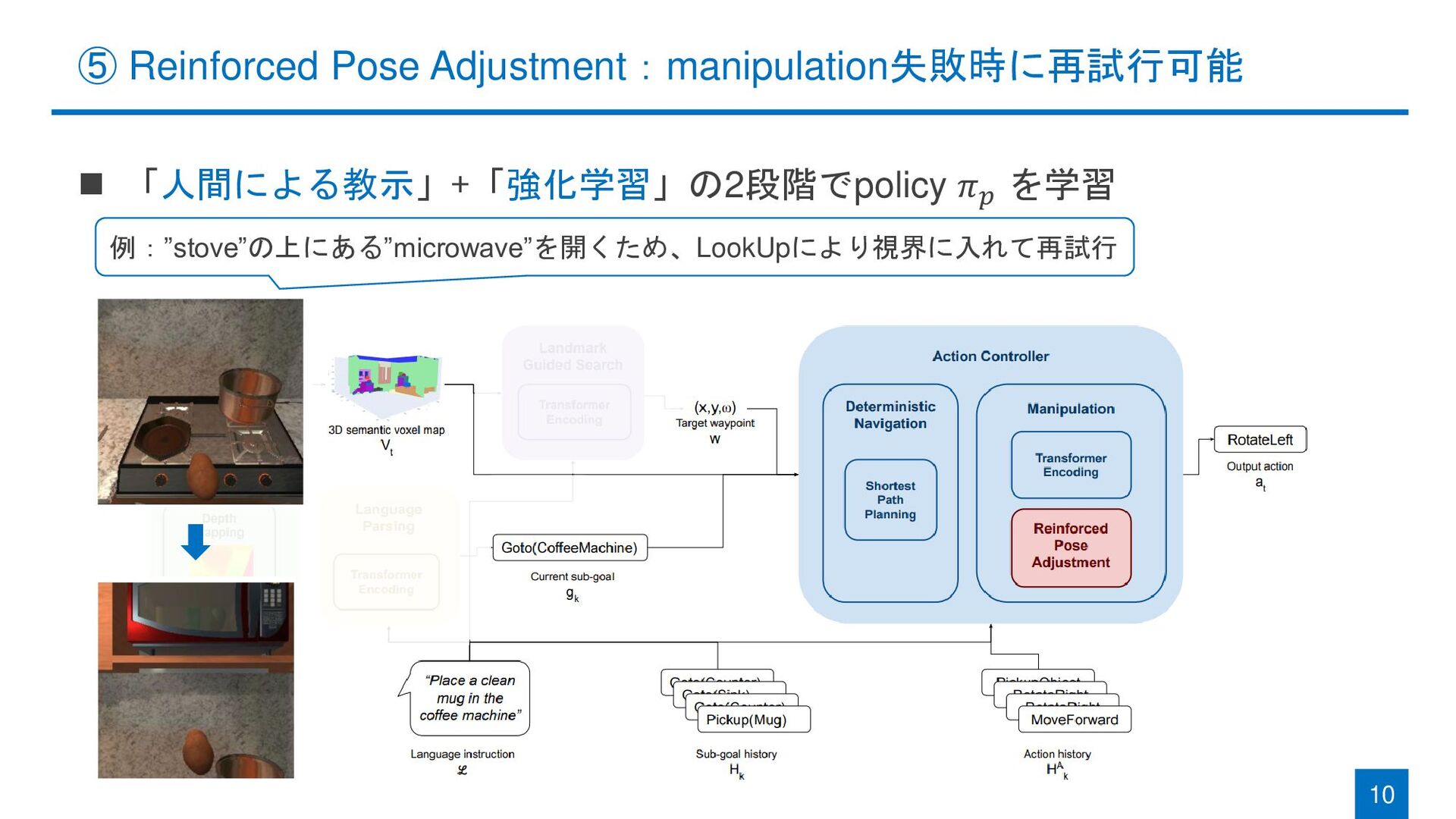{kind=link}
![実験設定:ALFRED [Shridhar+, CVPR20] ◼ 7種類のタスクを120種類の屋内環境で実施 ◼ 自然言語による指示:High/Low-levelの2パターン ◼ 評価指標 ①](https://files.speakerdeck.com/presentations/3a1fda53d41d4f61b234b79be0497977/slide_10.jpg){kind=link}
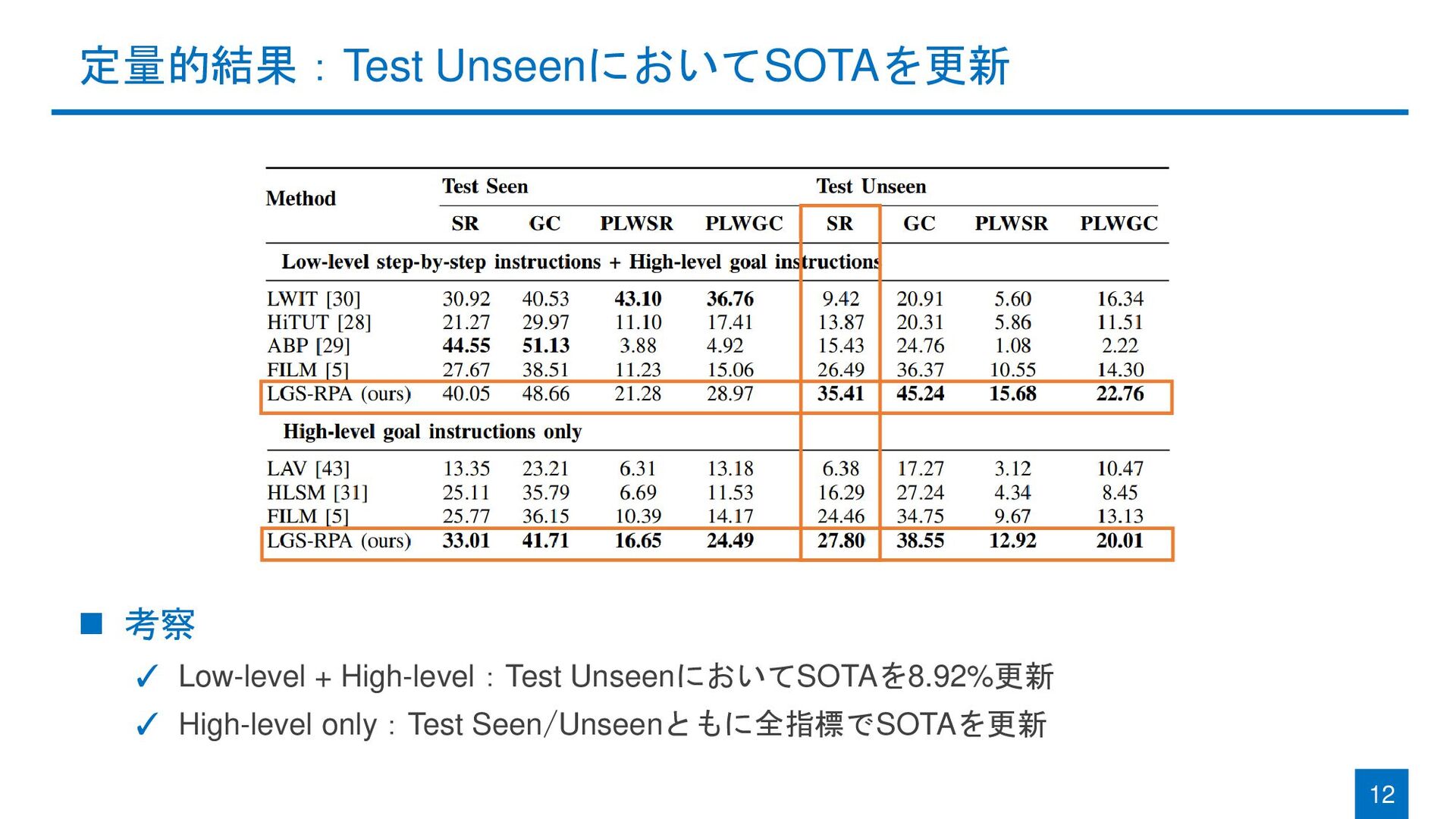{kind=link}
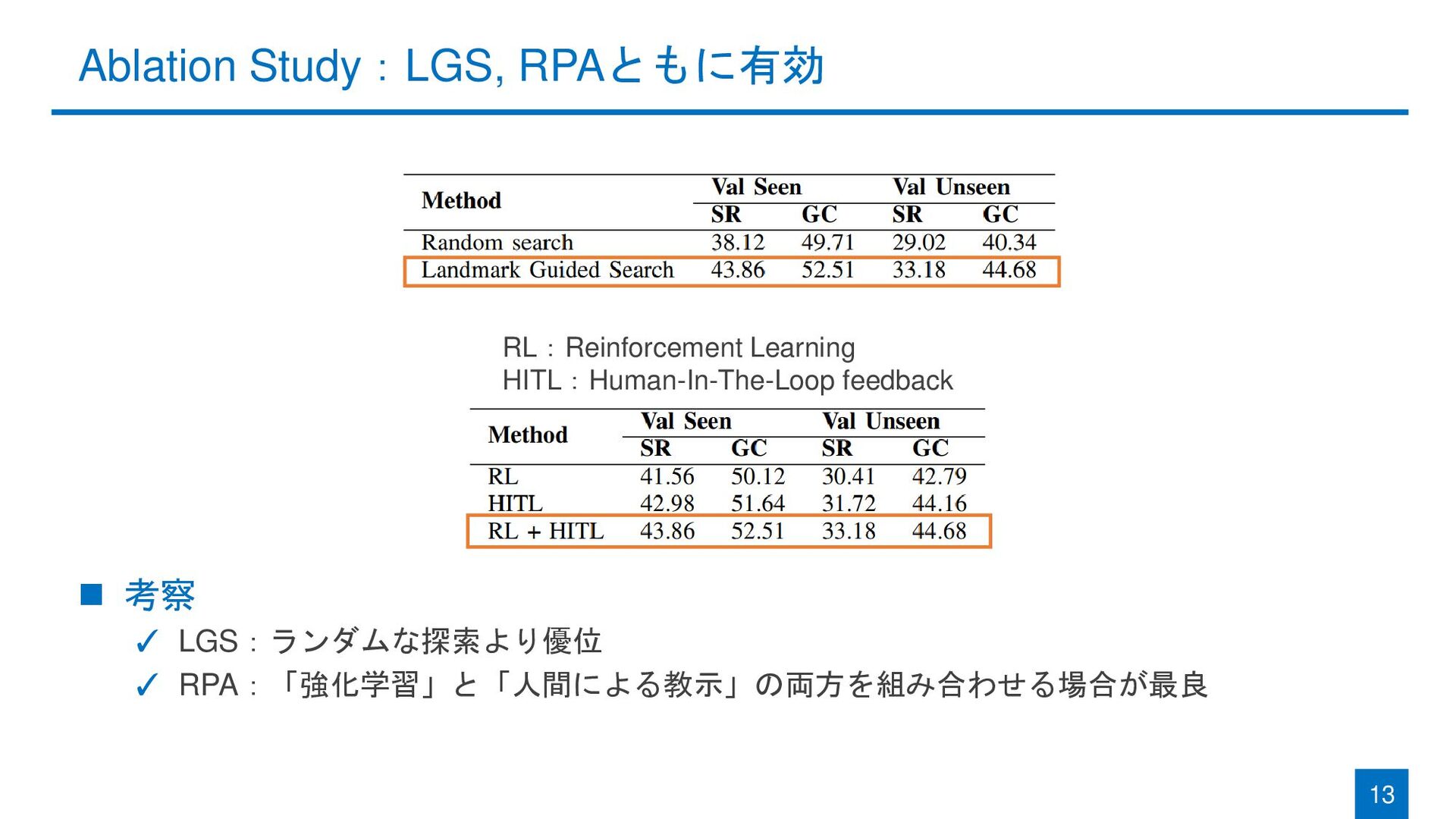{kind=link}
{kind=link}
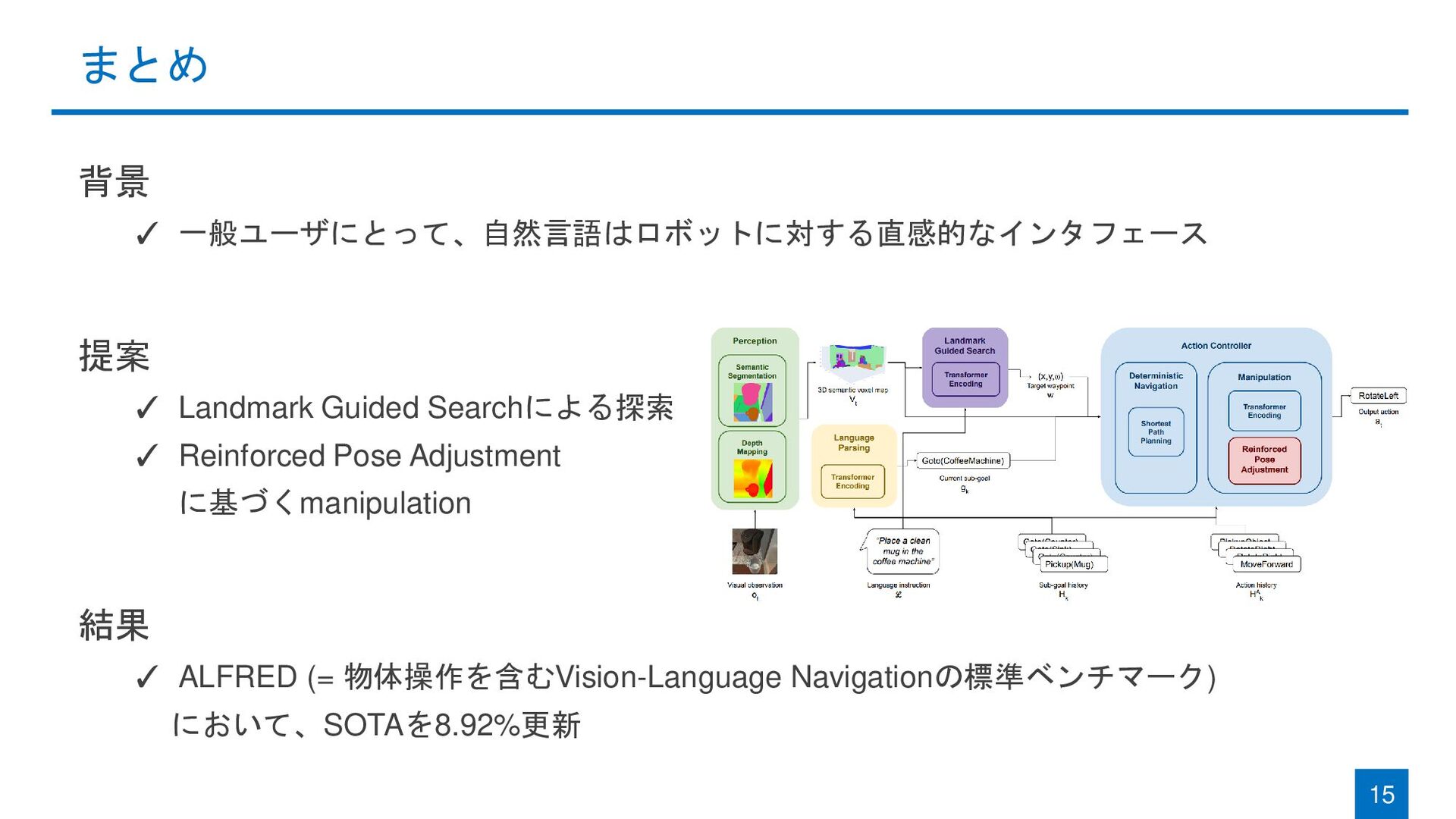{kind=link}
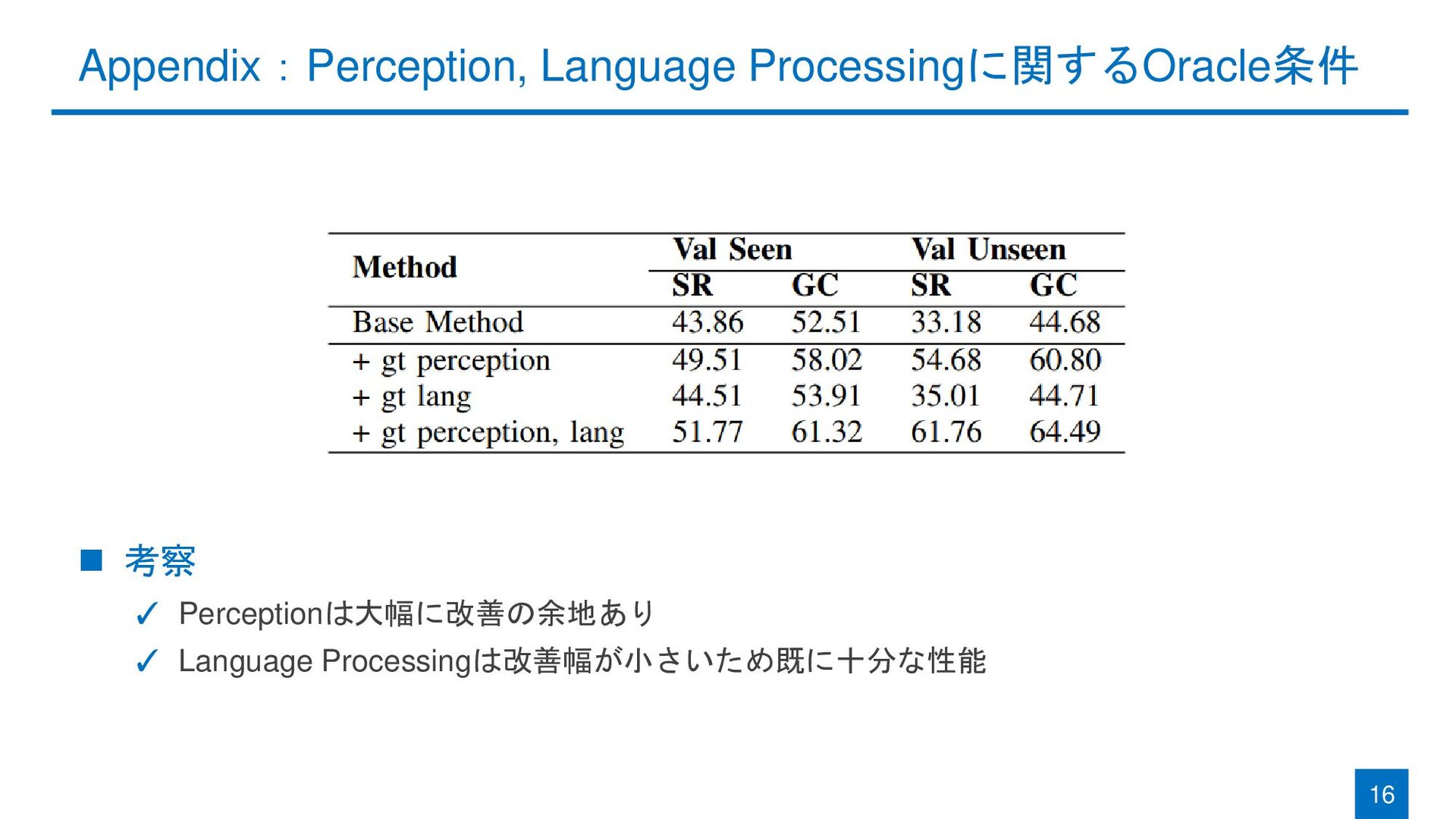{kind=link}
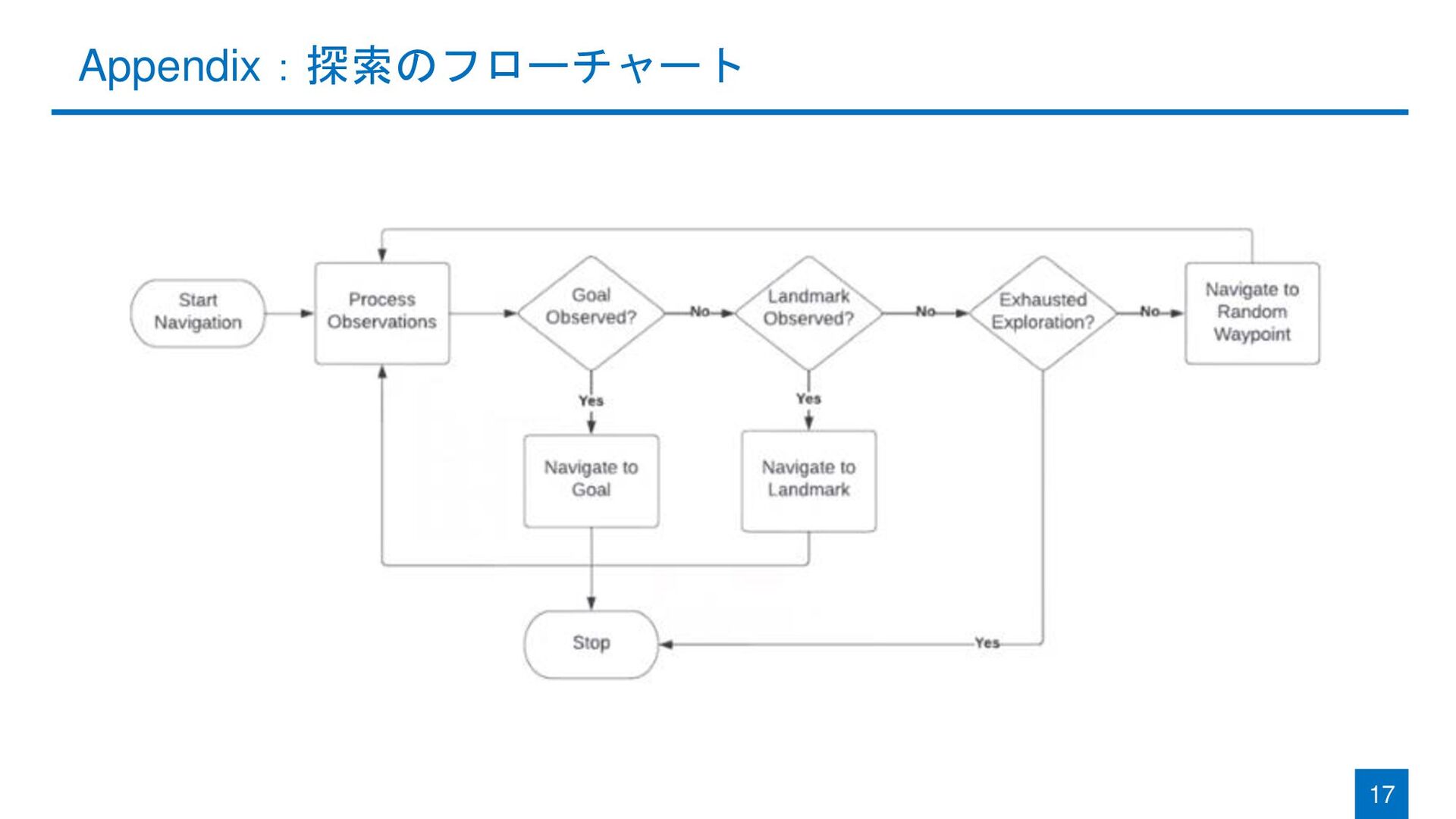{kind=link}