Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[JSAI23] Co-Scale Cross-Attentional Transformer...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
June 01, 2023
Technology
650
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[JSAI23] Co-Scale Cross-Attentional Transformer for Object Rearrangement Task
Semantic Machine Intelligence Lab., Keio Univ.
PRO
June 01, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
現場との対話から始める “作る前に問い直す”業務改善
mochico50
1
220
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
450
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
310
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
520
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
2
230
OPENLOGI Company Profile for engineer
hr01
1
74k
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
1
110
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
160
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
110
Featured
See All Featured
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
Design in an AI World
tapps
1
270
Everyday Curiosity
cassininazir
0
260
Paper Plane
katiecoart
PRO
2
52k
We Are The Robots
honzajavorek
0
280
Making the Leap to Tech Lead
cromwellryan
135
10k
Practical Orchestrator
shlominoach
191
11k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
HDC tutorial
michielstock
2
750
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Transcript
物体再配置タスクのための Co-Scale Cross-Attentional Transformer 慶應義塾大学 松尾榛夏 石川慎太朗 杉浦孔明
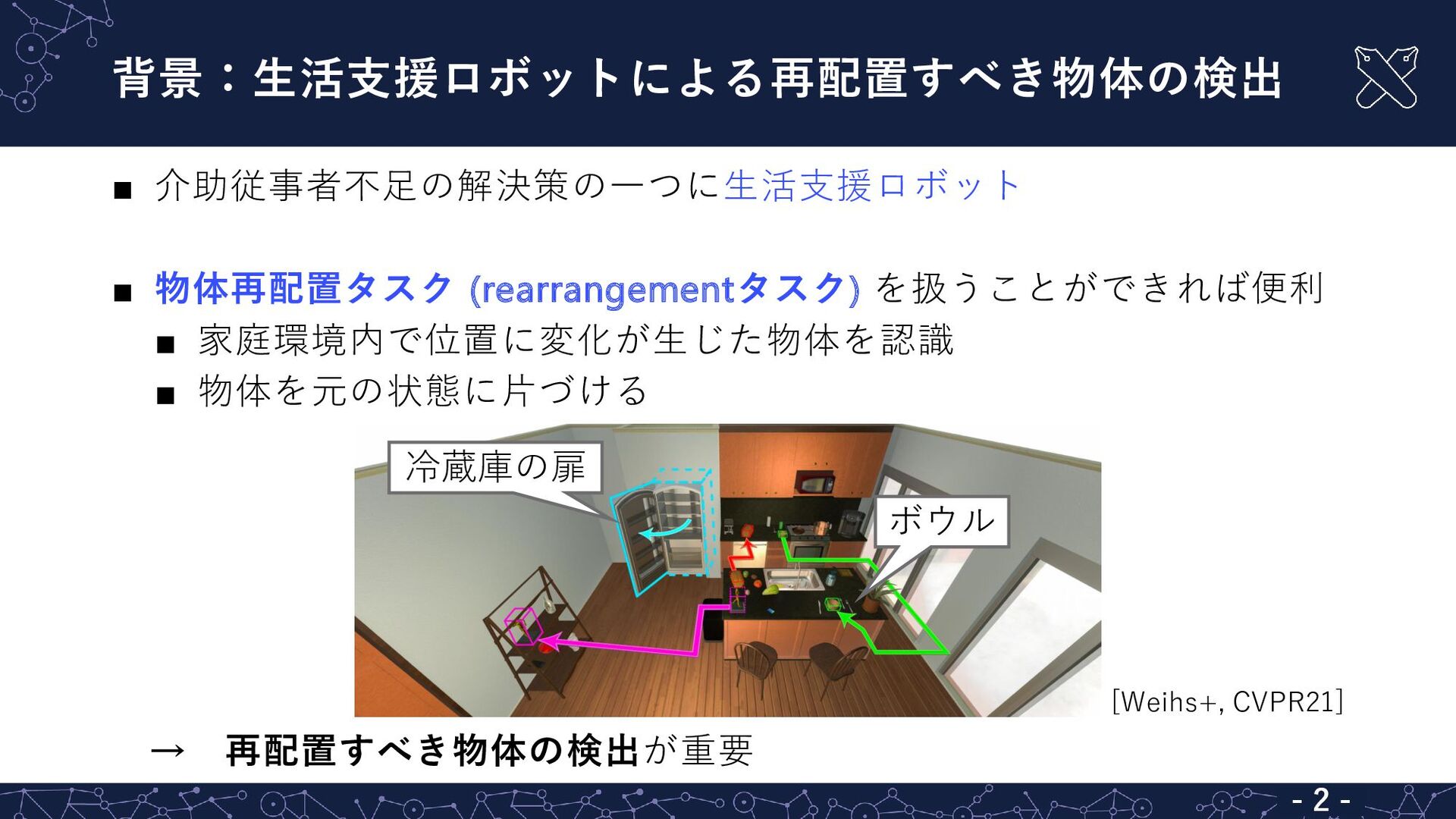
背景:生活支援ロボットによる再配置すべき物体の検出 - 2 - ▪ 介助従事者不足の解決策の一つに生活支援ロボット ▪ 物体再配置タスク (rearrangementタスク) を扱うことができれば便利
▪ 家庭環境内で位置に変化が生じた物体を認識 ▪ 物体を元の状態に片づける → 再配置すべき物体の検出が重要 [Weihs+, CVPR21] 冷蔵庫の扉 ボウル
▪ 対象タスク:Rearrangement Target Detection (RTD) ▪ 入力された目標状態と現在の状態の画像から再配置対象を検出し、 その物体をマスクした画像を出力 ▪ 再配置対象
▪ 目標状態と現在の状態の間で、位置および向きが変化する物体、 開閉する引き出しおよび扉 問題設定:Rearrangement Target Detection 目標状態 現在の状態 マスク画像 - 3 -
▪ Scene Understanding Challenge (Scene Change Detection) ▪ CVPR 2023で開催されるEmbodied
AI Workshopのタスクの1つ 問題設定:室内での変化検出はEmbodied AI タスクの1つ https://www.youtube.com/watch?v=jQPkV29KFvI&t=88s - 4 -
RTD:画素値の比較では再配置対象の検出は難しい ▪ 画素値の比較 光や影の影響あり 扉の開閉は画素値の変化が少ない → 再配置対象の検出は難しい 目標状態
現在の状態 正解マスク画像 画素値の比較 - 5 -
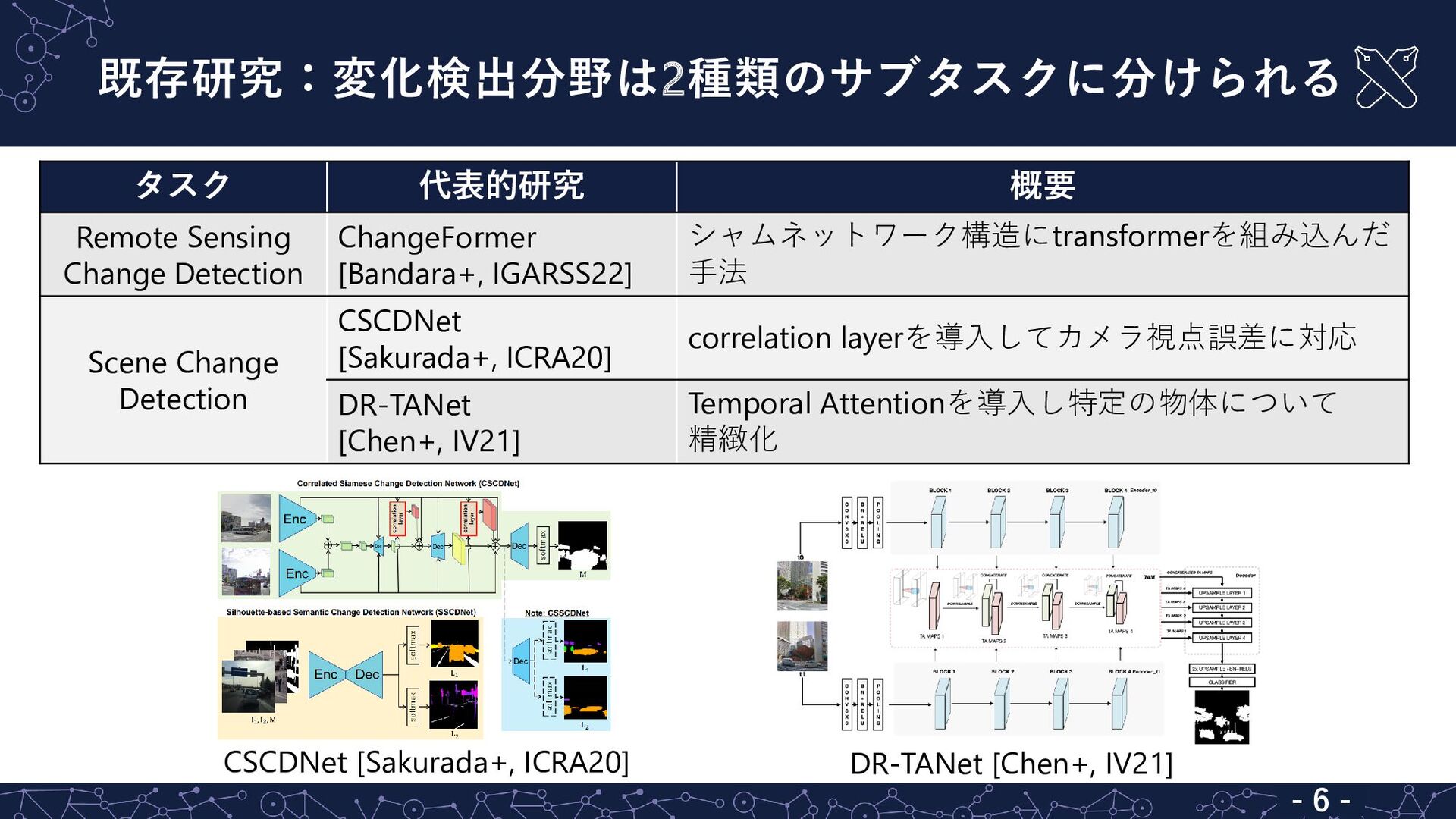
既存研究:変化検出分野は2種類のサブタスクに分けられる タスク 代表的研究 概要 Remote Sensing Change Detection ChangeFormer [Bandara+,
IGARSS22] シャムネットワーク構造にtransformerを組み込んだ 手法 Scene Change Detection CSCDNet [Sakurada+, ICRA20] correlation layerを導入してカメラ視点誤差に対応 DR-TANet [Chen+, IV21] Temporal Attentionを導入し特定の物体について 精緻化 CSCDNet [Sakurada+, ICRA20] DR-TANet [Chen+, IV21] - 6 -
既存研究の問題点: RTDのためにはセグメンテーションの性能が不十分 ▪ CSCDNet [Sakurada+, ICRA20] ▪ 特徴量抽出:ResNet [He+, CVPR16]
▪ 2枚の画像の関係性のモデル化:画像の連結 (A) RTDタスクには直接適用できない (B) Attention機構を用いていない & (C) 関係性のモデル化が不十分 → 複雑な形状の物体のセグメンテーションに失敗 Scene Change Detectionにはない 扉の開閉の検出 - 7 -
提案手法:CoaT [Xu+, ICCV21] による視覚情報の強化& cross-attentionによる関係性のモデル化 ▪ (A) Co-Scale Cross-Attentional Transformerの提案
▪ RTDタスクに適用 ▪ 3種類のモジュール ▪ 新規性 ▪ (B) Serial Encoderの導入 ▪ attention機構による視覚情報の強化 ▪ (C) Cross-Attentional Encoderの導入 ▪ 関係性のモデル化のための cross-attention - 8 -
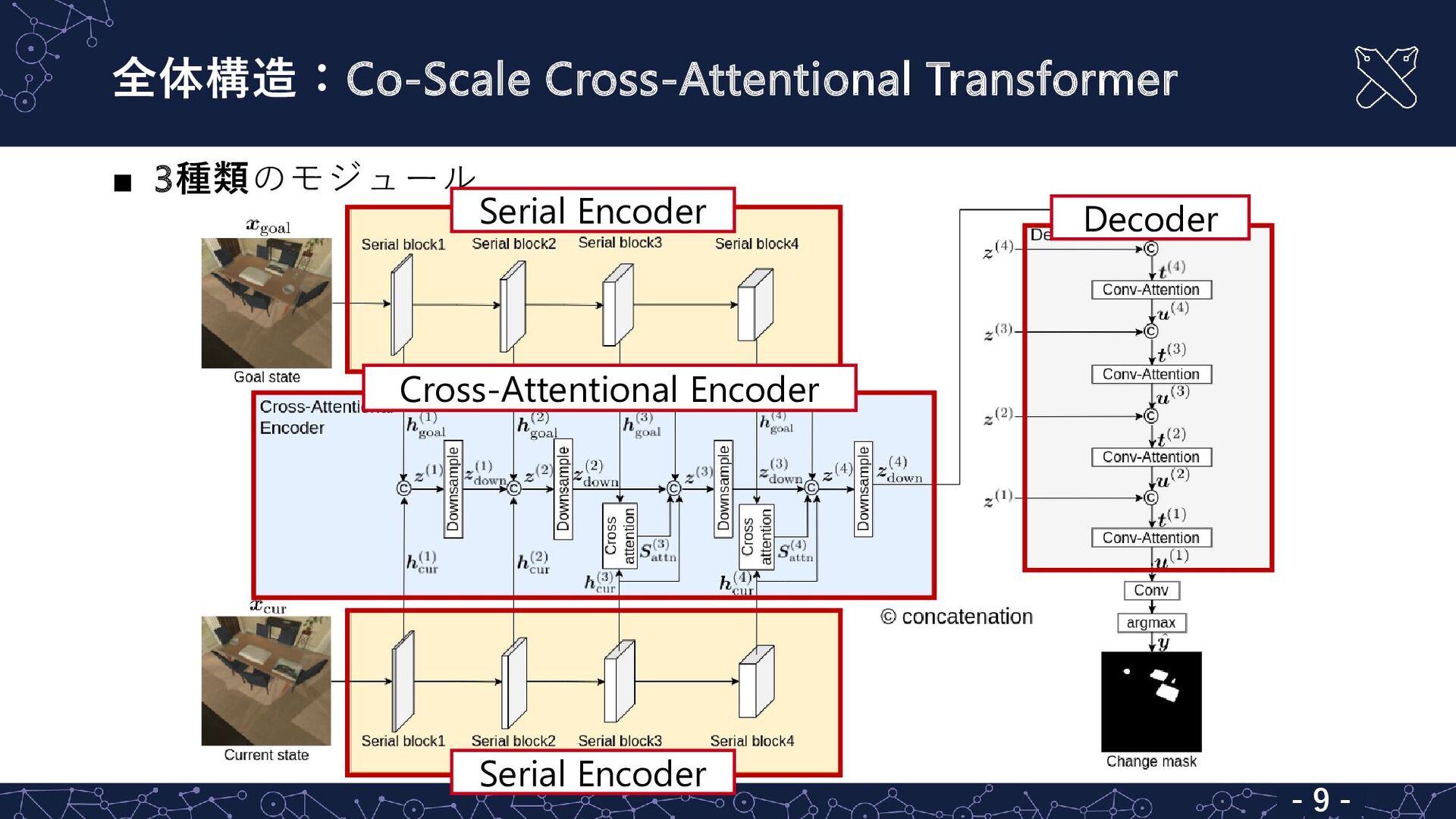
全体構造:Co-Scale Cross-Attentional Transformer ▪ 3種類のモジュール - 9 - Serial Encoder
Serial Encoder Cross-Attentional Encoder Decoder
1. Serial Encoder: CoaT [Xu+, ICCV21] による視覚情報の強化 ▪ 複数のCoaT serial
block [Xu+, ICCV21]を用いて2種類の入力から 画像特徴量を抽出 𝑖 = 4 𝑖番目のserial block ➀パッチ埋め込み層でダウンサンプリング ②平坦化&CLSトークンを結合 ③Conv-Attention Module [Xu+, ICCV21]を適用 ④画像トークンとCLSトークンを分離& 画像トークンを変形 入力:RGB画像 - 10 - 𝑖 = 1 𝑖 = 2 𝑖 = 3
Conv-Attention Module ▪ CoaT [Xu+, ICCV21] で提案 ▪ 畳み込みをPosition embeddingとして
利用 ▪ 計算量を削減しつつself-attentionを 計算 → 計算量を削減したattention構造 - 11 -
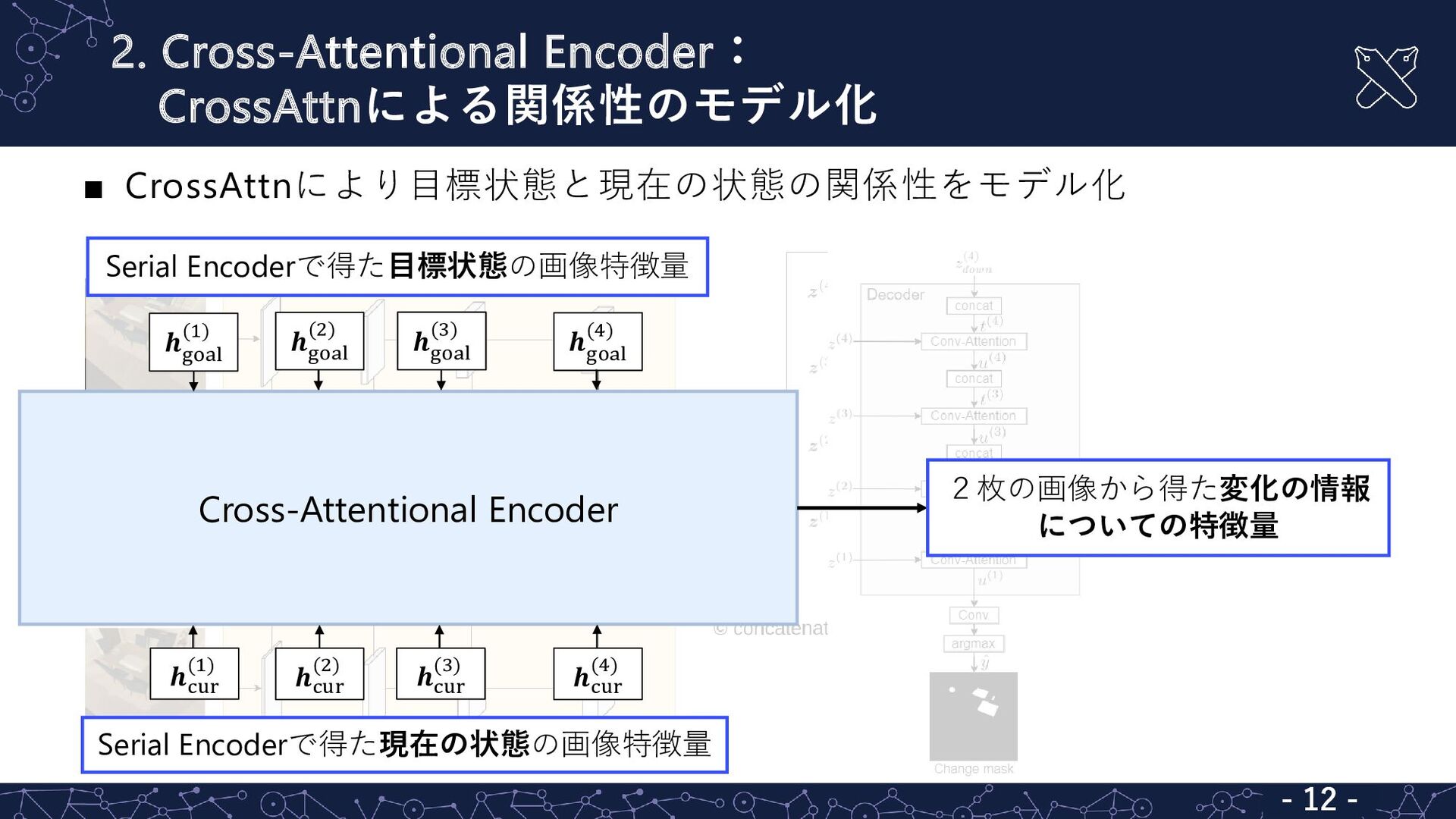
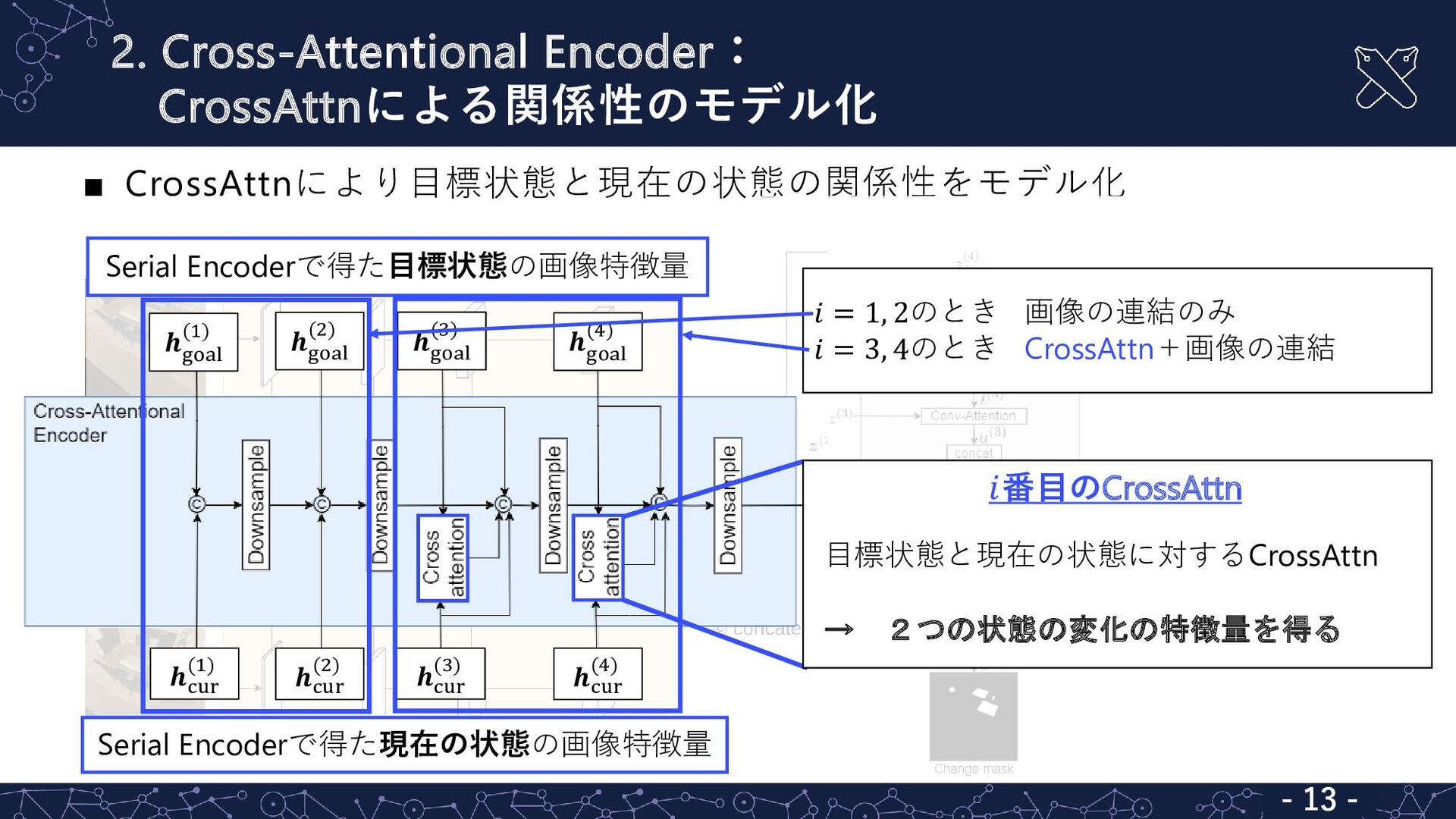
2. Cross-Attentional Encoder: CrossAttnによる関係性のモデル化 - 12 - ▪ CrossAttnにより目標状態と現在の状態の関係性をモデル化 -
12 - 𝒉 goal (1) 𝒉 goal (2) 𝒉 goal (3) 𝒉 goal (4) 𝒉cur (1) 𝒉cur (2) 𝒉cur (3) 𝒉cur (4) - 12 - Cross-Attentional Encoder Serial Encoderで得た目標状態の画像特徴量 Serial Encoderで得た現在の状態の画像特徴量 2枚の画像から得た変化の情報 についての特徴量
2. Cross-Attentional Encoder: CrossAttnによる関係性のモデル化 - 13 - ▪ CrossAttnにより目標状態と現在の状態の関係性をモデル化 -
13 - 𝑖 = 1, 2のとき 画像の連結のみ 𝑖 = 3, 4のとき CrossAttn+画像の連結 𝒉 goal (1) 𝒉 goal (2) 𝒉 goal (3) 𝒉 goal (4) 𝒉cur (1) 𝒉cur (2) 𝒉cur (3) 𝒉cur (4) 𝑖番目のCrossAttn 目標状態と現在の状態に対するCrossAttn → 2つの状態の変化の特徴量を得る - 13 - Serial Encoderで得た目標状態の画像特徴量 Serial Encoderで得た現在の状態の画像特徴量
3. Decoder:予測マスク画像の作成 - 14 - ▪ アップサンプリングを繰り返して 元の画像サイズの予測マスク画像を作成 ▪ ①
Cross-Attentional Encoderで得た変化 の異なる段階の特徴量を連結 ② Conv-Attention Moduleを適用& アップサンプリング ▪ 特徴量の連結、Conv-Attention Module 適用、アップサンプリングを繰り返す ▪ 出力: ෝ 𝒚(元の画像サイズ) - 14 -
▪ アップサンプリングを繰り返して 元の画像サイズの予測マスク画像を作成 ▪ ① Cross-Attentional Encoderで得た変化 異なる段階の特徴量を連結 ② Conv-Attention
Moduleを適用& アップサンプリング ▪ 特徴量の連結、Conv-Attention Module 適用、アップサンプリングを繰り返す ▪ 出力: ෝ 𝒚(元の画像サイズ) 3. Decoder:予測マスク画像の作成 - 15 - Change mask - 15 -
損失関数:soft Dice lossを導入 - 16 - ▪ soft Dice loss
ℒsDice = 1 − 1 𝐾 𝑖=1 𝐾 2 σ𝑗=1 𝑁 𝒚𝑖,𝑗 𝑝 ෝ 𝒚𝑖,𝑗 σ 𝑗=1 𝑁 𝒚𝑖,𝑗 + σ 𝑗=1 𝑁 𝑝 ෝ 𝒚𝑖,𝑗 + 𝜖 ▪ Dice loss [Milletari+, 16]やIoU loss [Rahman+, ISVC16]と 類似した処理 ▪ Dice lossは0か1の値のみを使用するが、soft Dice lossは確率を使用 ▪ 例:0.51の確率で1になっていた画素を0.51として扱うことが可能 ▪ 損失関数: ℒ = 𝜆ce ℒce 𝒚, ෝ 𝒚 + 𝜆sDice ℒsDice 𝒚, 𝑝(ෝ 𝒚) ℒce :交差エントロピー誤差 - 16 - ℒsDice :soft Dice loss
実験:RTDデータセット&評価尺度 - 17 - ▪ RTDデータセット ▪ AI2-THOR [Kolve+, 17]で作成
▪ 構成 ▪ 目標状態および現在の状態のRGB画像 ▪ 正解マスク画像 ▪ 12000サンプル ▪ 再配置対象の変化距離 ▪ シミュレーション環境上で50cm以上の移動 ▪ 評価尺度 ▪ mean Intersection over Union (mIoU) ▪ F1-score - 17 -
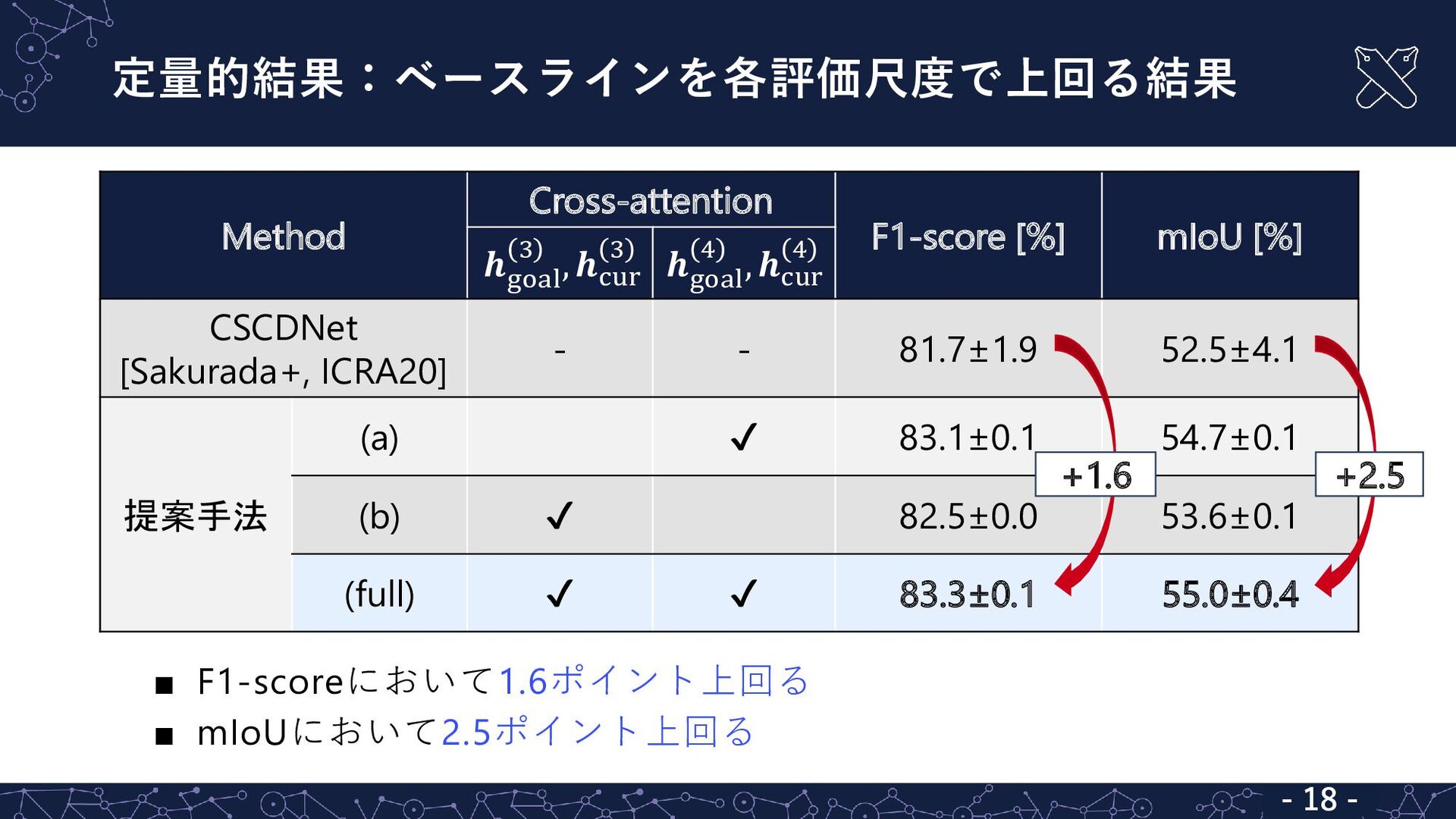
定量的結果:ベースラインを各評価尺度で上回る結果 - 18 - ▪ F1-scoreにおいて1.6ポイント上回る ▪ mIoUにおいて2.5ポイント上回る - 18
- Method Cross-attention F1-score [%] mIoU [%] 𝒉 goal 3 , 𝒉cur 3 𝒉 goal 4 , 𝒉cur 4 CSCDNet [Sakurada+, ICRA20] - - 81.7±1.9 52.5±4.1 提案手法 (a) ✔ 83.1±0.1 54.7±0.1 (b) ✔ 82.5±0.0 53.6±0.1 (full) ✔ ✔ 83.3±0.1 55.0±0.4 +1.6 +2.5
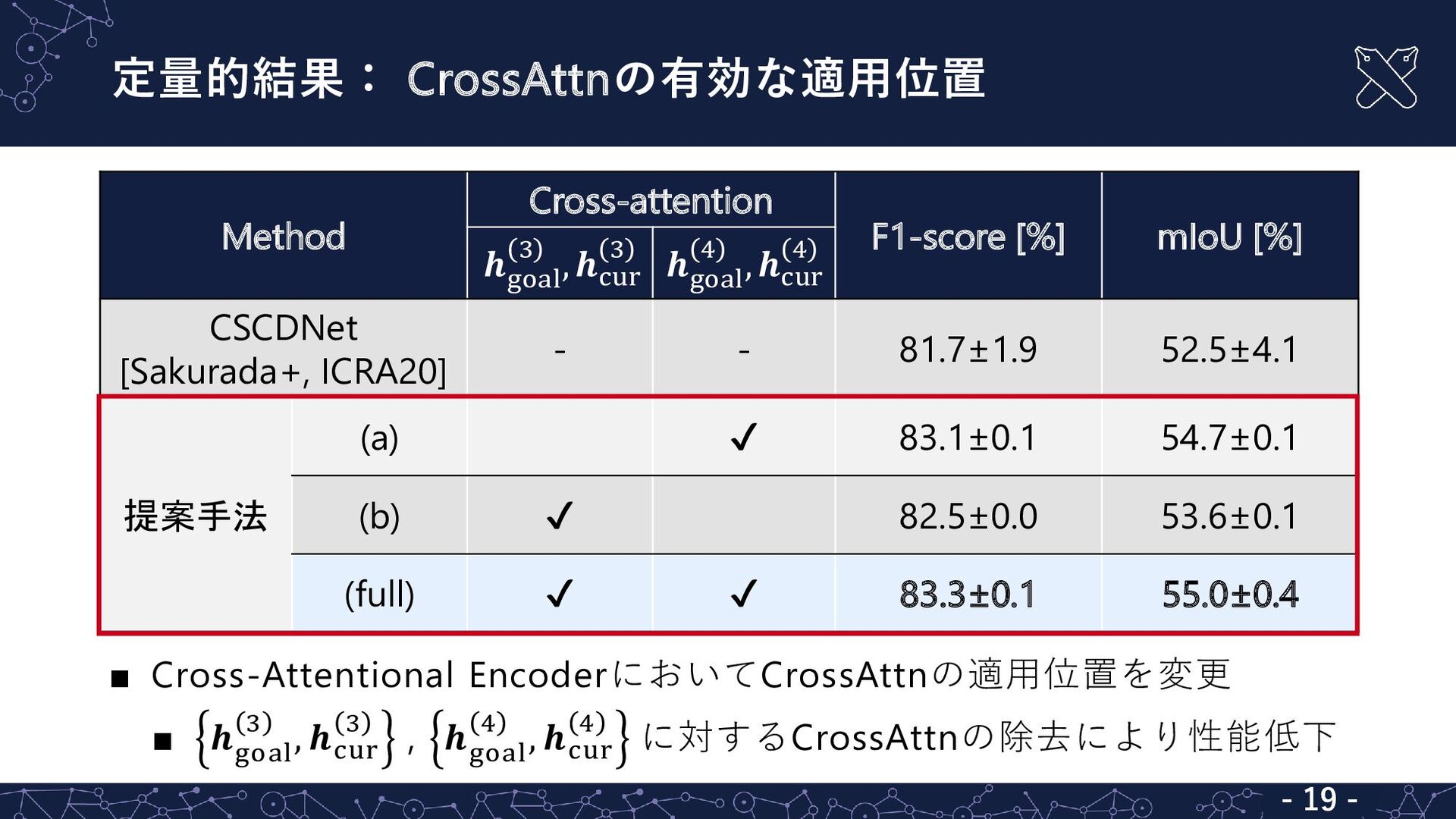
定量的結果: CrossAttnの有効な適用位置 - 19 - - 19 - Method Cross-attention
F1-score [%] mIoU [%] 𝒉 goal 3 , 𝒉cur 3 𝒉 goal 4 , 𝒉cur 4 CSCDNet [Sakurada+, ICRA20] - - 81.7±1.9 52.5±4.1 提案手法 (a) ✔ 83.1±0.1 54.7±0.1 (b) ✔ 82.5±0.0 53.6±0.1 (full) ✔ ✔ 83.3±0.1 55.0±0.4 ▪ Cross-Attentional EncoderにおいてCrossAttnの適用位置を変更 ▪ 𝒉 goal 3 , 𝒉cur 3 , 𝒉 goal 4 , 𝒉cur 4 に対するCrossAttnの除去により性能低下
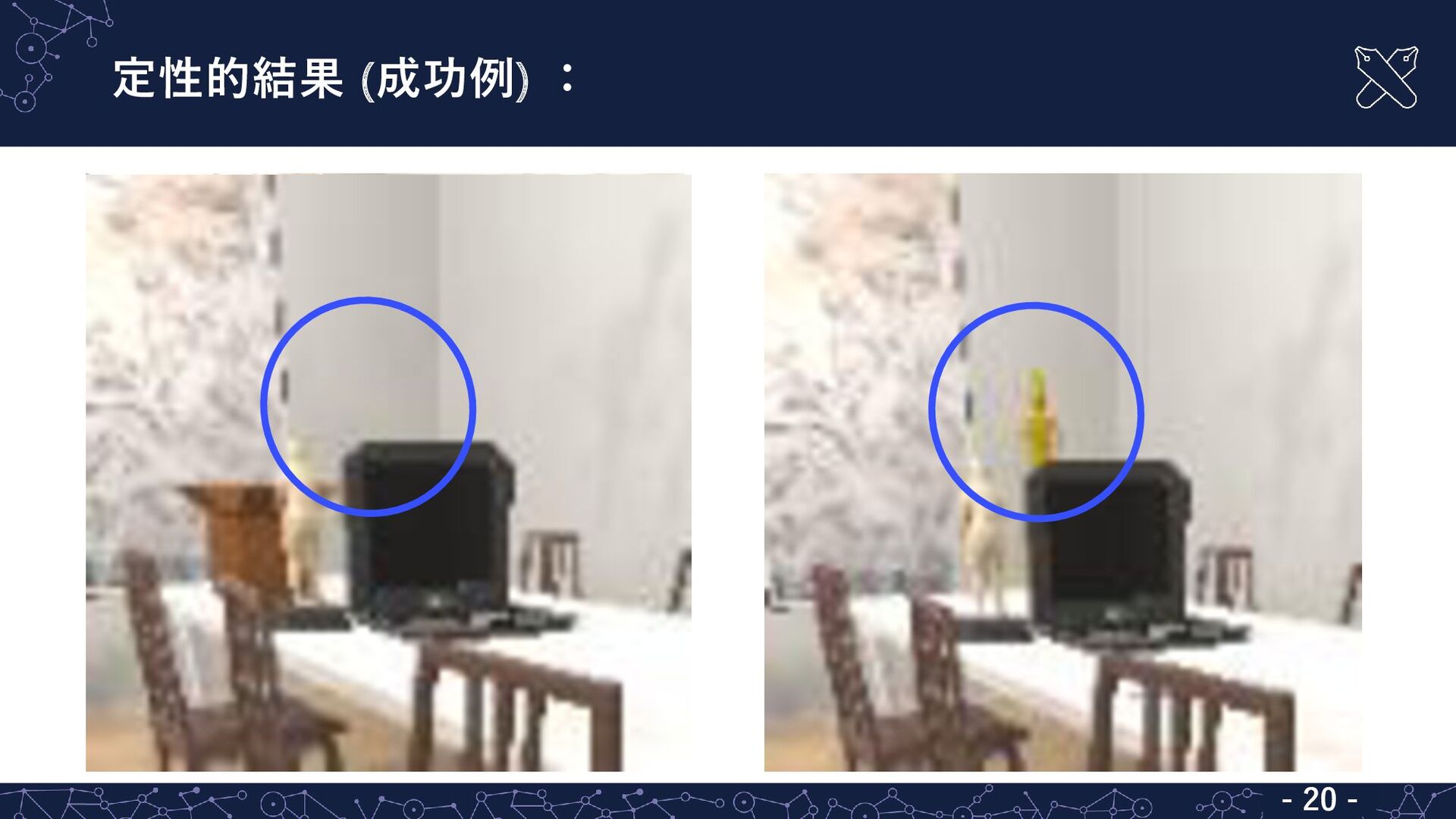
定性的結果 (成功例) : - 20 - - 20 -
定性的結果 (成功例) : - 21 - - 20 -
定性的結果 (成功例) : - 22 - - 20 -
定性的結果 (成功例):物体全体をマスク - 23 - ▪ ベースライン手法 過小なセグメンテーション領域 ▪
提案手法 ☺ 物体全体をマスク & 物体が分離した部分もマスク Ground Truth ベースライン手法 提案手法 - 21 - 物体が分離した部分もマスク 過小なセグメンテーション領域 物体全体をマスク
定性的結果 (成功例) : - 24 - - 22 -
定性的結果 (成功例) : - 25 - - 22 -
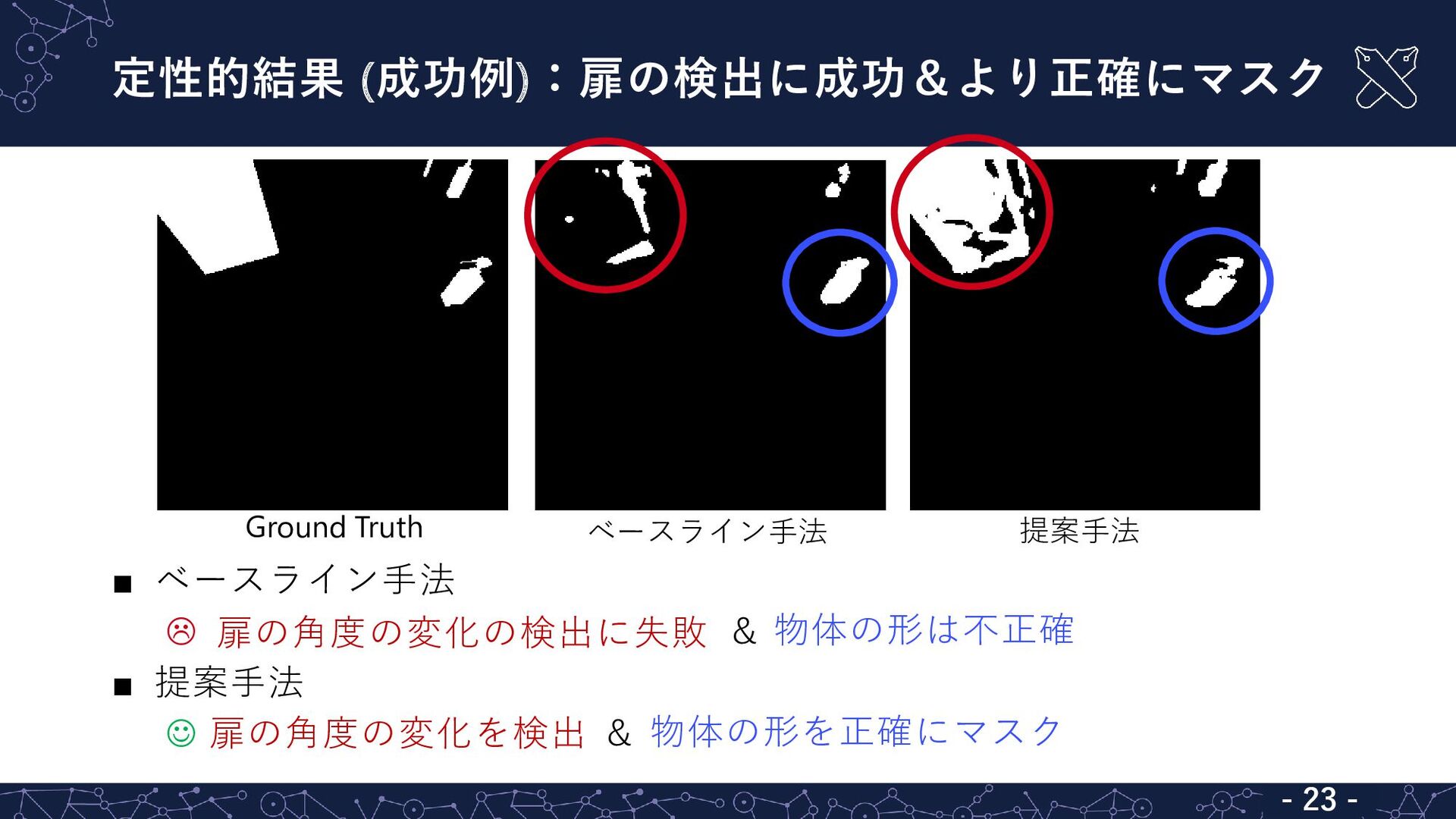
定性的結果 (成功例):扉の検出に成功&より正確にマスク - 17 - ▪ ベースライン手法 扉の角度の変化の検出に失敗 &
物体の形は不正確 ▪ 提案手法 ☺ 扉の角度の変化を検出 & 物体の形を正確にマスク Ground Truth ベースライン手法 提案手法 扉の角度の変化の検出に失敗 扉の角度の変化を検出 物体の形を正確にマスク 物体の形は不正確 - 23 -
定性的結果 (失敗例) : - 27 - - 24 -
定性的結果 (失敗例) : - 28 - - 24 -
定性的結果 (失敗例): 僅かな変化の検出失敗&鏡に映っている物体の検出 - 29 - ▪ 引き出しの開いている割合が少し増加 ▪ 問題設定自体が難しい
▪ 鏡に映っている物体も検出 ▪ 鏡の反射をモデルが理解できていない Ground Truth ベースライン手法 提案手法 引き出しの開いている割合が少し増加 鏡に映っている物体も検出 - 25 -
まとめ:Co-Scale Cross-Attentional Transformerの提案 - 23 - ▪ Co-Scale Cross-Attentional Transformer
▪ Serial Encoderの導入 ▪ Cross-Attentional Encoderの導入 ▪ ベースライン手法をmIoUおよびF1-scoreで上回る - 26 -
Appendix:エラー分析 変化距離が短い物体の検出 - 20 - ▪ 50cmより短い移動距離の物体を誤検出 ▪ 原因:入力として深度情報を与えていないため、物体の変化距離の 予測が困難だったと考えられる
▪ 解決策:depth画像を入力として用いる 目標状態 現在の状態 Ground Truth 提案手法 - 27 -
Appendix:エラー分析の分類 (IoUワースト100サンプル) - 29 - ▪ サンプル中に異なる再配置対象に関する検出誤りが複数存在する場合、 それぞれを独立した失敗例として扱った 失敗名 数
変化距離が短い物体の検出 35 小物体のセグメンテーション誤り 26 アノテーション誤り 14 全体が写っていない物体のセグメンテーション誤り 12 過小または過剰な領域予測 12 検出位置の微小なずれ 5 光や影の誤検出 4 - 28 -
Appendix:ハイパーパラメータ - 24 - 最適化関数 Adam (𝛽1 = 0.5, 𝛽2
= 0.999) 学習率 0.001 バッチサイズ 16 Loss weights 𝜆ce = 1, 𝜆sDice = 1 Serial Encoder #L: [2, 2, 2, 2], #A: 8 Cross Attentional Encoder #A: 8 Decoder #L: [1, 1, 1, 1], #A: 8 ▪ Serial Encoderの𝑖番目のserial blockから出力される画像特徴マップの 高さ、幅、チャネル数を表す𝐻𝑖 , 𝑊𝑖 , 𝐶𝑖 ▪ 𝐻1 = 64, 𝑊1 = 64, 𝐶1 = 64, 𝐻𝑖+1 = 𝐻𝑖 2 , 𝑊𝑖+1 = 𝑊𝑖 2 , 𝐶𝑖+1 = 𝐶𝑖 × 2 ▪ ただし、 𝐶3 , 𝐶4 はそれぞれ320, 512 - 29 -
Appendix:soft Dice lossとDice lossの比較 - 25 - ▪ Dice loss
[Milletari+, 16] ℒDice = 1 − 2 σ𝑗=1 𝑁 𝑦𝑗 𝑝 ො 𝑦𝑗 σ 𝑗=1 𝑁 𝑦𝑗 + σ 𝑗=1 𝑁 ො 𝑦𝑗 + 𝜖 ▪ soft Dice loss ℒsDice = 1 − 1 𝐾 𝑖=1 𝐾 2 σ𝑗=1 𝑁 𝑦𝑖,𝑗 𝑝 ො 𝑦𝑖,𝑗 σ 𝑗=1 𝑁 𝑦𝑖,𝑗 + σ 𝑗=1 𝑁 𝑝 ො 𝑦𝑖,𝑗 + 𝜖 ▪ Dice lossは0か1の値のみを使用するが、soft Dice lossは確率を使用 ▪ 例:0.51の確率で1になっていた画素を0.51として扱うことが可能 ▪ 複数回による実験の結果、いずれも性能が向上 - 30 -
Appendix:データセット作成方法の詳細 - 26 - ① ロボットがいる部屋の目標状態においてロボットの一人称視点画像を保存 ② ロボットは移動しないまま、シミュレーション環境内にある物体を ランダムに移動または開閉し、再び一人称視点画像を保存 ③
各状態の画像を保存すると同時に以下を取得 ▪ 再配置対象のID ▪ 目標状態および現在の状態におけるシミュレーション環境上での位置 ▪ 一人称視点画像内での位置 ④ ③を使用してマスク画像を取得 - 31 -
Appendix:データセットの詳細 - 27- ▪ 訓練集合:10000サンプル ▪ FloorPlan 1~20,201~220,301~320,401~420 ▪ 検証集合:1000サンプル
▪ FloorPlan 21~25,221~225,321~325,421~425 ▪ テスト集合:1000サンプル ▪ FloorPlan 26~30,226~230,326~330,426~430 https://ai2thor.allenai.org/demo/ - 32 -
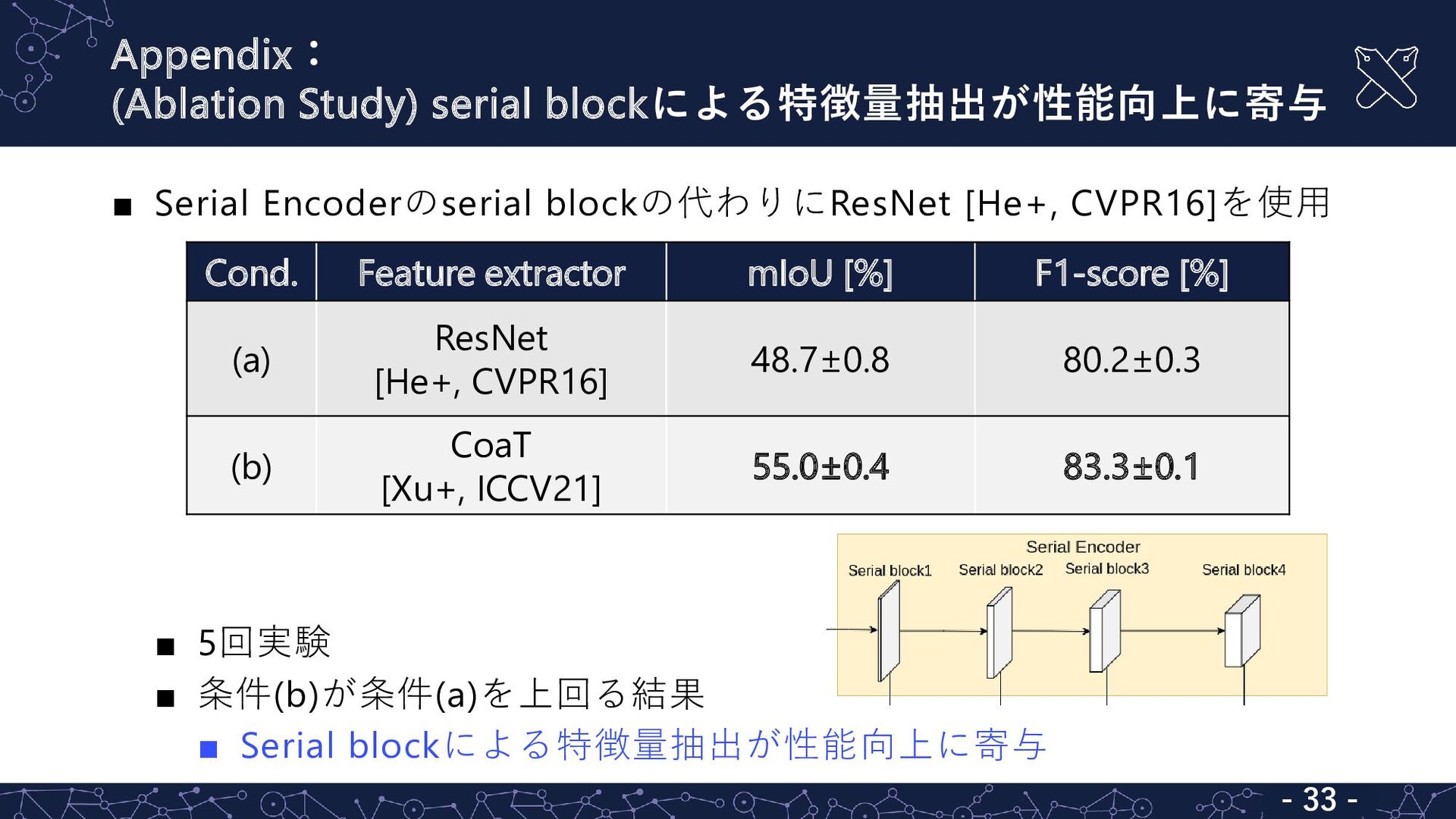
Appendix: (Ablation Study) serial blockによる特徴量抽出が性能向上に寄与 - 28 - ▪ Serial
Encoderのserial blockの代わりにResNet [He+, CVPR16]を使用 ▪ 5回実験 ▪ 条件(b)が条件(a)を上回る結果 ▪ Serial blockによる特徴量抽出が性能向上に寄与 Cond. Feature extractor mIoU [%] F1-score [%] (a) ResNet [He+, CVPR16] 48.7±0.8 80.2±0.3 (b) CoaT [Xu+, ICCV21] 55.0±0.4 83.3±0.1 - 33 -
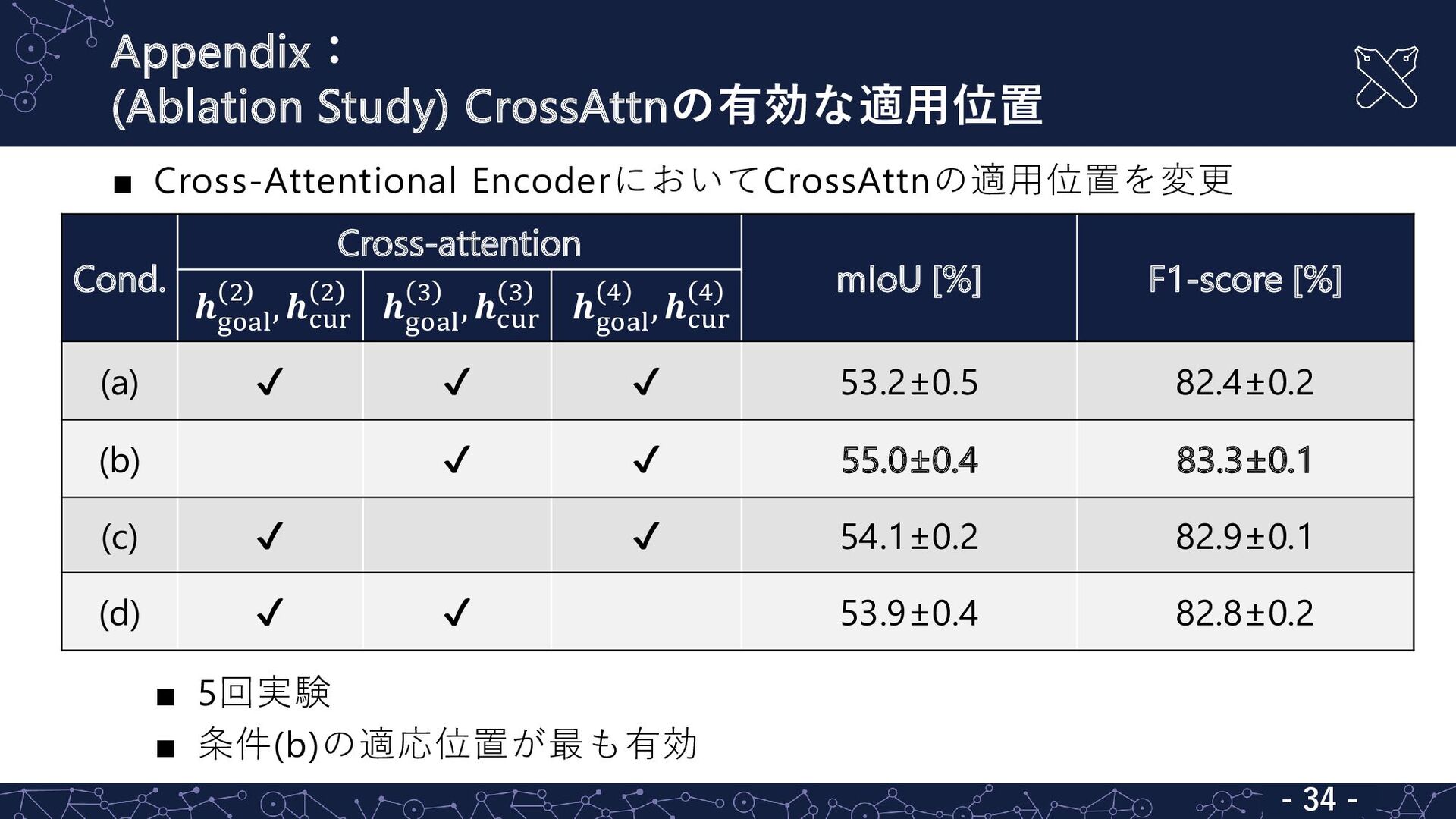
Appendix: (Ablation Study) CrossAttnの有効な適用位置 - 26 - ▪ Cross-Attentional EncoderにおいてCrossAttnの適用位置を変更
▪ 5回実験 ▪ 条件(b)の適応位置が最も有効 Cond. Cross-attention mIoU [%] F1-score [%] 𝒉 goal 2 , 𝒉cur 2 𝒉 goal 3 , 𝒉cur 3 𝒉 goal 4 , 𝒉cur 4 (a) ✔ ✔ ✔ 53.2±0.5 82.4±0.2 (b) ✔ ✔ 55.0±0.4 83.3±0.1 (c) ✔ ✔ 54.1±0.2 82.9±0.1 (d) ✔ ✔ 53.9±0.4 82.8±0.2 - 34 -
Appendix:入力の変更 - 21 - ▪ 入力:RGB画像, depth画像, SAM [Kirillow+, 23]
によるセグメンテーション画像 ▪ 目標状態と現在の状態の間で照度変化あり 目標状態 現在の状態 depth画像 (目標状態) SAM (目標状態) - 35 -
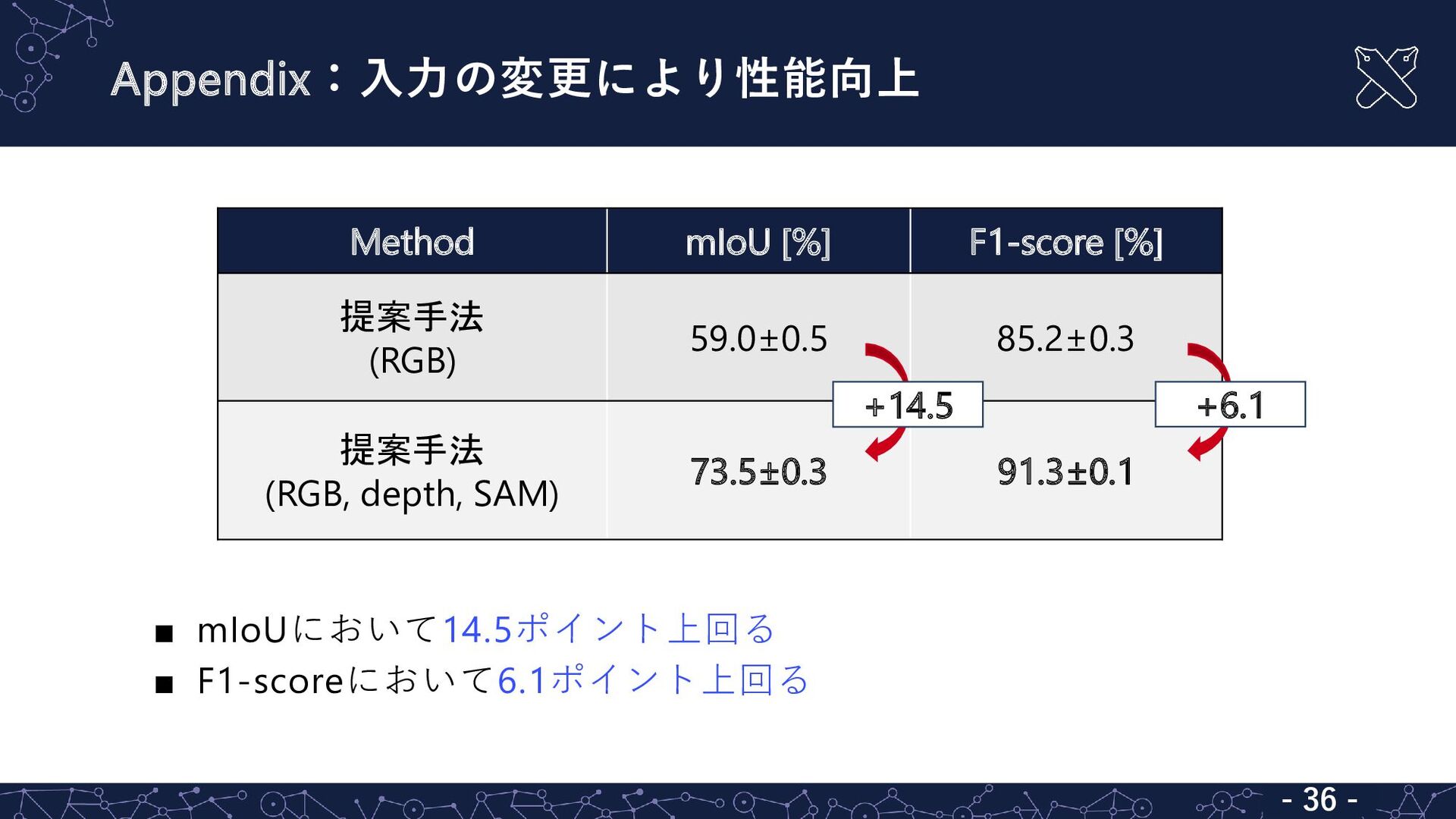
Appendix:入力の変更により性能向上 - 22 - ▪ mIoUにおいて14.5ポイント上回る ▪ F1-scoreにおいて6.1ポイント上回る Method mIoU
[%] F1-score [%] 提案手法 (RGB) 59.0±0.5 85.2±0.3 提案手法 (RGB, depth, SAM) 73.5±0.3 91.3±0.1 +14.5 +6.1 - 36 -
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存研究の問題点: RTDのためにはセグメンテーションの性能が不十分 ▪ CSCDNet [Sakurada+, ICRA20] ▪ 特徴量抽出:ResNet [He+, CVPR16]](https://files.speakerdeck.com/presentations/2f7b0fe43c794573884a65823e9add57/slide_6.jpg){kind=link}
![提案手法:CoaT [Xu+, ICCV21] による視覚情報の強化& cross-attentionによる関係性のモデル化 ▪ (A) Co-Scale Cross-Attentional Transformerの提案](https://files.speakerdeck.com/presentations/2f7b0fe43c794573884a65823e9add57/slide_7.jpg){kind=link}
{kind=link}
![1. Serial Encoder: CoaT [Xu+, ICCV21] による視覚情報の強化 ▪ 複数のCoaT serial](https://files.speakerdeck.com/presentations/2f7b0fe43c794573884a65823e9add57/slide_9.jpg){kind=link}
![Conv-Attention Module ▪ CoaT [Xu+, ICCV21] で提案 ▪ 畳み込みをPosition embeddingとして](https://files.speakerdeck.com/presentations/2f7b0fe43c794573884a65823e9add57/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験:RTDデータセット&評価尺度 - 17 - ▪ RTDデータセット ▪ AI2-THOR [Kolve+, 17]で作成](https://files.speakerdeck.com/presentations/2f7b0fe43c794573884a65823e9add57/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix:入力の変更 - 21 - ▪ 入力:RGB画像, depth画像, SAM [Kirillow+, 23]](https://files.speakerdeck.com/presentations/2f7b0fe43c794573884a65823e9add57/slide_38.jpg){kind=link}
{kind=link}