fetching instructions from visual information ü Target-dependent UNITER models relationships between instruction and objects in image ü Our model outperformed baseline in terms of classification accuracy on two standard datasets
daily care and support in aging society Motivation Interacting naturally through language is important for robots e.g.) “Go get the bottle on the table” Domestic Service Robots (DSRs) - Capable of physically assisting handicapped people - Expected to overcome shortage of home care workers 3 [https://global.toyota/jp/download/8725271]
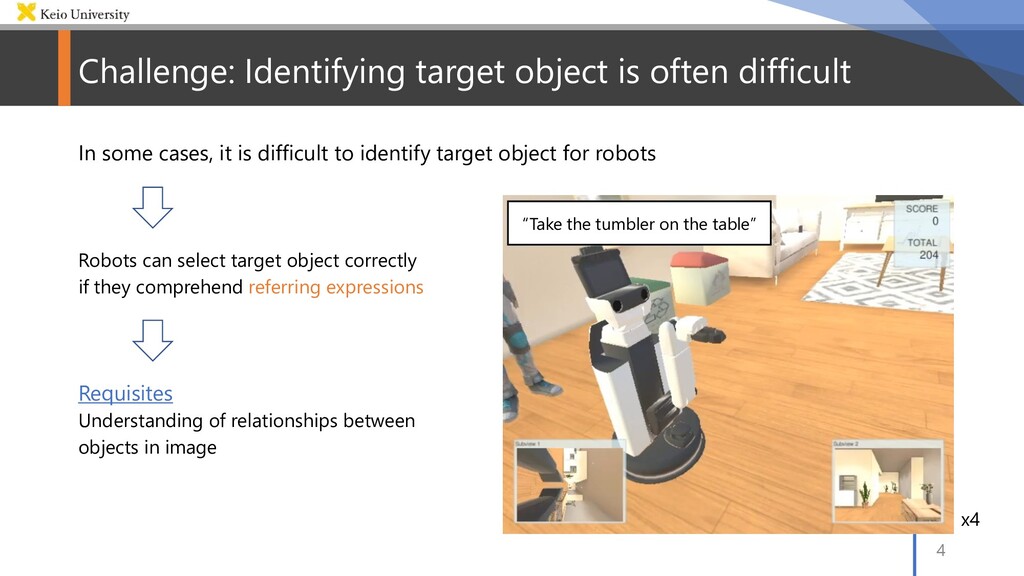
for robots Robots can select target object correctly if they comprehend referring expressions Requisites Understanding of relationships between objects in image Challenge: Identifying target object is often difficult 4 x4 “Take the tumbler on the table”
Vision and language • ViLBERT [Lu+ 19]: Handles image and text inputs in two separate Transformers • UNITER [Chen+ 20]: Fuses image and text inputs in a single Transformer • VILLA [Gan+ 20]: Learns V&L representations through adversarial training MLU-FI • [Hatori+ 18]: Method for object picking task • MTCM, MTCM-AB [Magassouba+ 19, 20]: Identifies target object from instruction and whole image [Hatori 18] VILLA [Gan 20]
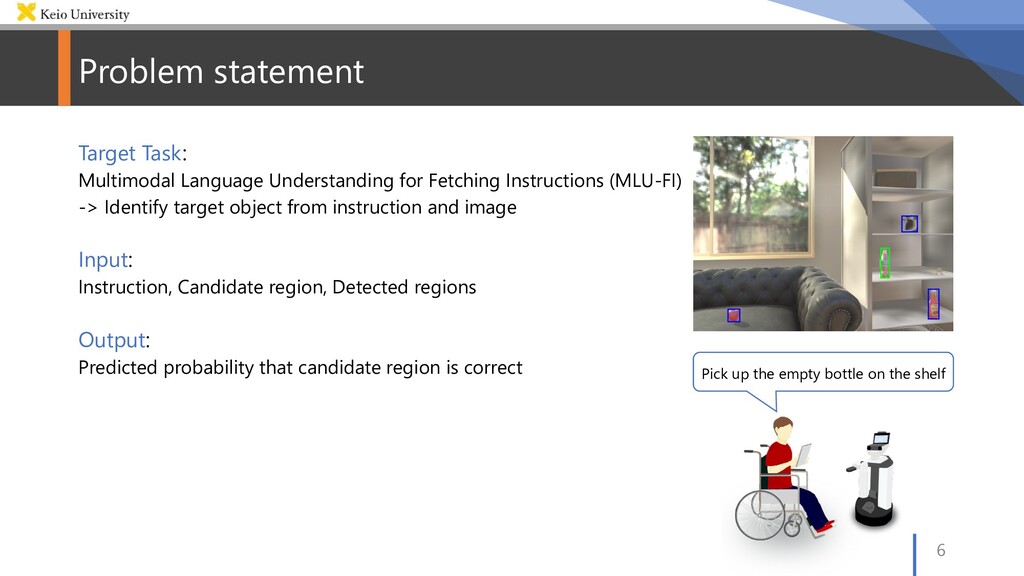
Instructions (MLU-FI) -> Identify target object from instruction and image Input: Instruction, Candidate region, Detected regions Output: Predicted probability that candidate region is correct Pick up the empty bottle on the shelf
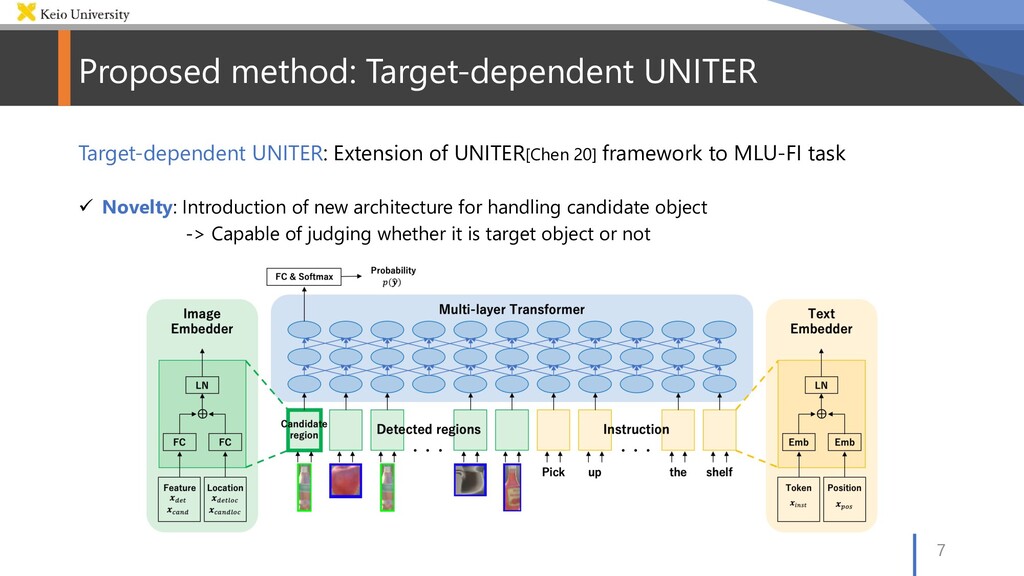
20] framework to MLU-FI task ü Novelty: Introduction of new architecture for handling candidate object -> Capable of judging whether it is target object or not
: One-hot vector set representing each token of instruction We tokenize instruction using WordPiece [Wu 16] and convert it into token sequence e.g.) “Pick up the empty bottle on the shelf” -> [“Pick”, “up”, “the”, ”empty”, ”bottle”, “on”, “the”, “shelf”, “.”] • 𝑥%&# : One-hot vector set representing each token’s position of instruction
detected regions • 𝑥'($ : Feature vectors of all detected region extracted from image • 𝑥)*"' : A feature vector selected from 𝑥'($ We extract feature vectors using Faster R-CNN [Ren 16] • 𝑥'($+&) : Location feature vectors of all detected region • 𝑥)*"'+&) : A location feature vector selected from 𝑥'($+&) We use seven-dimensional vector as location feature (normalized left/top/right/bottom coordinates, width, height, and area)
Datasets (consist of images and a set of instructions) Name Image Instruction Vocabulary size Average sentence length PFN-PIC [Hatori 18] 1180 90759 4682 14.2 WRS-UniALT 570 1246 167 7.1 “Pick up the white box next to the red bottle and put it in the lower left box” “Pick up the empty bottle on the shelf”
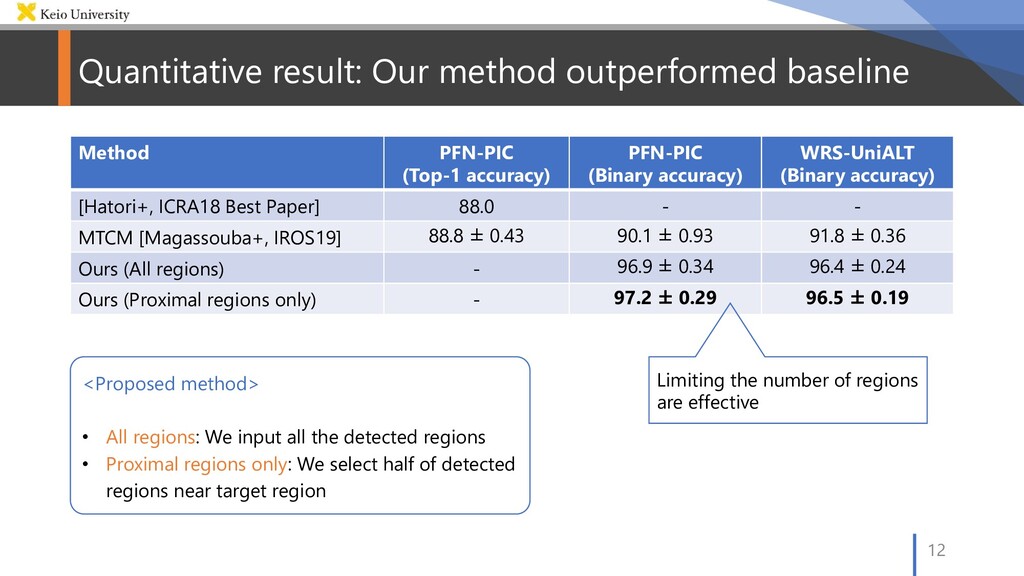
accuracy) PFN-PIC (Binary accuracy) WRS-UniALT (Binary accuracy) [Hatori+, ICRA18 Best Paper] 88.0 - - MTCM [Magassouba+, IROS19] 88.8 ± 0.43 90.1 ± 0.93 91.8 ± 0.36 Ours (All regions) - 96.9 ± 0.34 96.4 ± 0.24 Ours (Proximal regions only) - 97.2 ± 0.29 96.5 ± 0.19 <Proposed method> • All regions: We input all the detected regions • Proximal regions only: We select half of detected regions near target region Limiting the number of regions are effective
in the bottom right section of the box and move it to the bottom left section of the box” “Take the can juice on the white shelf” 𝑝 " 𝑦 = 0.999 𝑝 " 𝑦 = 8.19×10!"# Correctly identify candidate object as target object Correctly identify candidate object as different object from target object
white on the side from the upper left box, to the lower left box” “Take the white cup on the corner of the table.” 𝑝 " 𝑦 = 0.978 𝑝 " 𝑦 = 0.999 Fail to predict because region contains many pixels unrelated to candidate object Fail to predict because region is too small
fetching instructions from visual information ü Target-dependent UNITER models relationships between instruction and objects in image ü Our model outperformed baseline in terms of classification accuracy on two standard datasets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}