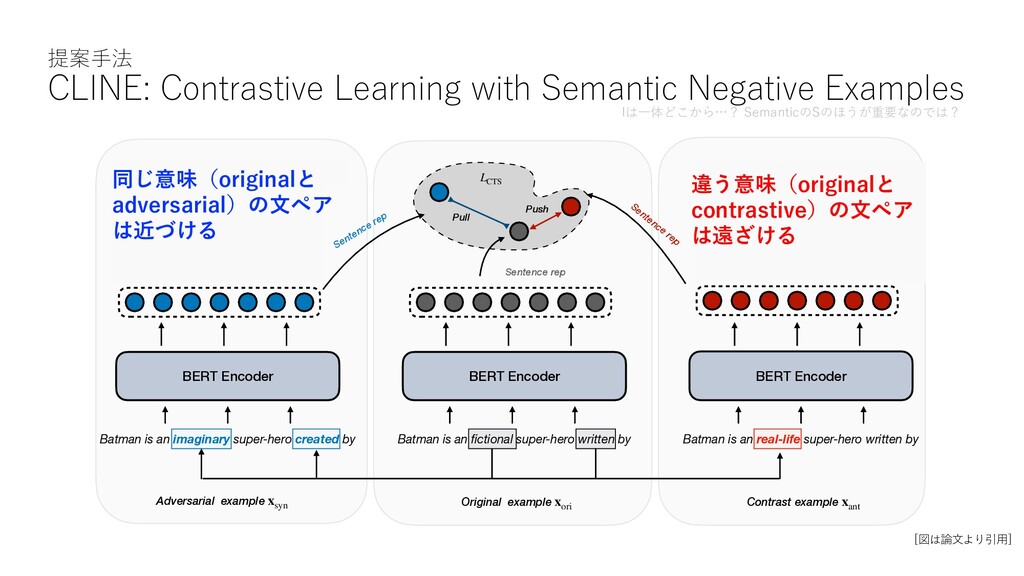
imaginary super-hero created by Batman is an real-life super-hero written by BERT Encoder BERT Encoder BERT Encoder Token-level Classifier Token-level Classifier 0 0 0 1 0 0 1 0 0 0 1 0 0 0 Adversarial example x syn Contrast example x ant Original example x ori Pull Push L RTD L RTD Sentence rep L CTS Sentence rep Sentence rep Figure 1: An illustration of our model, note that we use the embedding of [CLS] as the sentence representation. 提案⼿法 CLINE: Contrastive Learning with Semantic Negative Examples [図は論⽂より引⽤] 同じ意味(originalと adversarial)の⽂ペア は近づける 違う意味(originalと contrastive)の⽂ペア は遠ざける Iは⼀体どこから…? SemanticのSのほうが重要なのでは?
かなりstraightforwardなアプローチだが、これまでやられてこなかったことが意外 オリジナルの⽂ x ori: 同じ意味の⽂ x syn: 違う意味の⽂ x ant: Batman is an fictional super-hero written by Batman is an imaginary super-hero created by Batman is an real-life super-hero written by Ø 動詞、名詞、形容詞、副詞のみ置換 Ø x synは x oriの約4割の単語を同義語/上位語に置き換える Ø x antは x oriの約2割の単語を反意語/ランダムに置き換える
= exp(h⇤> c h0 c ). (5) Inspired by InfoNCE, we define an objective Lcts in the contrastive manner: Lcts = X x2X log f(xori, xsyn) f(xori, xsyn) + f(xori, xant) . (6) Note that different from some contrastive strategies that usually randomly sample multiple negative ex- amples, we only utilize one xant as the negative example for training. This is because the primary We evaluate tasks: • IMDB ysis da ment (p • SNLI ( guage ship be ond sen contrad first sen the next sentence prediction (NSP) objective since previous works have shown that NSP objective can hurt the performance on the downstream tasks (Liu et al., 2019; Joshi et al., 2020). Alternatively, adopt the embedding of [CLS] as the sentence repre- sentation for a contrastive objective. The metric between sentence representations is calculated as the dot product between [CLS] embeddings: f(x⇤, x0) = exp(h⇤> c h0 c ). (5) Inspired by InfoNCE, we define an objective Lcts in the contrastive manner: X ori syn laye 32 N pre- et a data 4.2 We task • contrastive learningでよく⾒る NCE lossを使った⽬的関数 ただし 同じ意味(originalとadversarial)の⽂ベクトルペアの内積が⼤きくなるように学習 違う意味(originalとcontrastive)の⽂ベクトルペアの内積が⼩さくなるように学習 BERTエンコーダーの [CLS]を表す出⼒層 1正解ペアに対して1負例ペア triplet loss的なloss。 (N個のNegative samplingは しない)
our goal, instead of arbitrarily sampling other sentences from the pre-training corpus as negative samples. Finally, we have the following training loss: L= 1LMLM + 2LRTD + 3Lcts, (7) where i is the task weighting learned by training. 4 Experiments ①Masked Language Model ③Contrastive Loss ②置換トークン検出タスク ①:いつものやつ ②:同義⽂ x syn、反意⽂ x ant内の各単語 x において、 x が置換されたかどうかを検出するタスク ③:前ページのロス関数。この論⽂のキモ
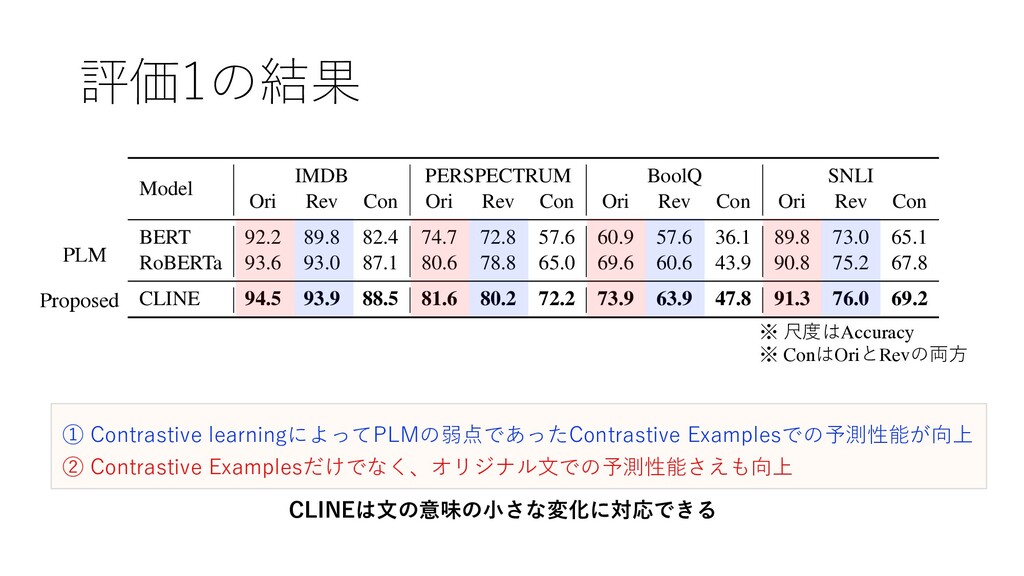
Rev Con Ori Rev Con Ori Rev Con BERT 92.2 89.8 82.4 74.7 72.8 57.6 60.9 57.6 36.1 89.8 73.0 65.1 RoBERTa 93.6 93.0 87.1 80.6 78.8 65.0 69.6 60.6 43.9 90.8 75.2 67.8 CLINE 94.5 93.9 88.5 81.6 80.2 72.2 73.9 63.9 47.8 91.3 76.0 69.2 Table 4: Accuracy on the original test set (Ori) and contrastive test set (Rev). Contrast consistency (Con) is a metric of whether a model makes correct predictions on every element in both the original test set and the contrastive test set. Model Method IMDB AG MR SNLI BERT Vanilla 88.7 88.8 68.4 48.6 FreeLB 91.9 93.3 75.9 56.1 Vanilla 93.9 91.9 79.7 55.1 to replace them with the most semantically similar and grammatically correct words. From the experimental results in Table 5, we can observe that our vanilla model achieves higher ※ 尺度はAccuracy ※ ConはOriとRevの両⽅ ① Contrastive learningによってPLMの弱点であったContrastive Examplesでの予測性能が向上 PLM Proposed CLINEは⽂の意味の⼩さな変化に対応できる ② Contrastive Examplesだけでなく、オリジナル⽂での予測性能さえも向上
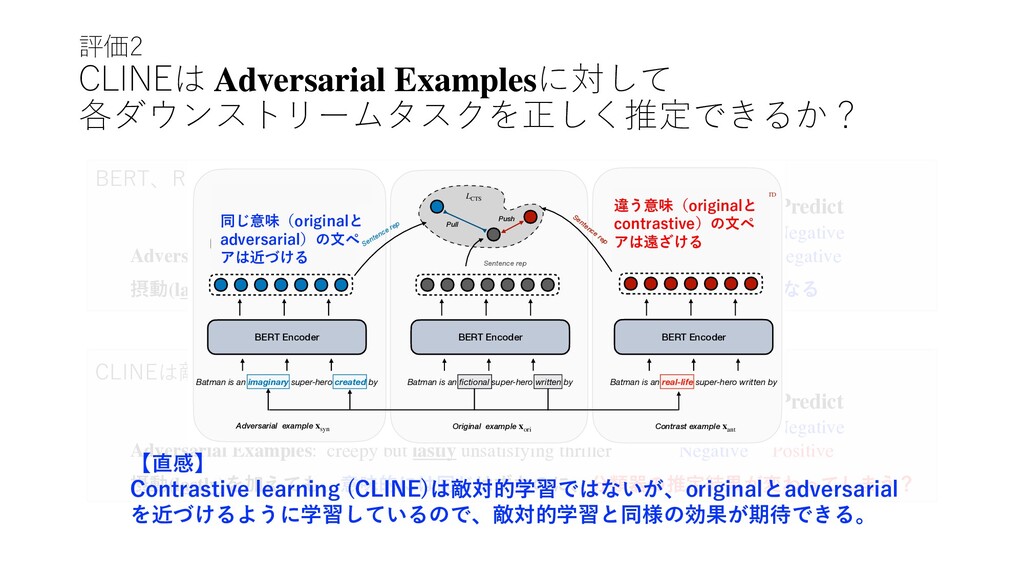
thriller Negative Negative Adversarial Examples: creepy but lastly unsatisfying thriller Negative Negative 摂動(lastly)を加えても、意味的には同じなので、分類器の推定結果も同じになる Sentence Label Predict BERT、RoBERTaに敵対的学習を適応したら... CLINEは敵対的学習をしているわけではないので… Original: creepy but ultimately unsatisfying thriller Negative Negative Adversarial Examples: creepy but lastly unsatisfying thriller Negative Positive 摂動(lastly)を加えても、意味的には同じはずなのに、分類器の推定結果が変わってしまう? Sentence Label Predict 【直感】 Contrastive learning (CLINE)は敵対的学習ではないが、originalとadversarial を近づけるように学習しているので、敵対的学習と同様の効果が期待できる。 Batman is an fictional super-hero written by Batman is an imaginary super-hero created by Batman is an real-life super-hero written by BERT Encoder BERT Encoder BERT Encoder Token-level Classifier Token-level Classifier 0 0 0 1 0 0 1 0 0 0 1 0 0 0 Adversarial example x syn Contrast example x ant Original example x ori Pull Push L RTD L RTD Sentence rep L CTS Sentence rep Sentence rep Figure 1: An illustration of our model, note that we use the embedding of [CLS] as the sentence representation. Intuitively, when we replace the representative words in a sentence with its antonym, the semantic of the sentence is easy to be irrelevant or even op- posite to the original sentence. As shown in Figure sion: h = E (x). (1) Masked Language Modeling Objective With 同じ意味(originalと adversarial)の⽂ペ アは近づける 違う意味(originalと contrastive)の⽂ペ アは遠ざける
CLINEは⽂の意味の変化に対応でき、ロバスト性を維持 Table 4: Accuracy on the original test set (Ori) and contrastive test set (Rev). Con of whether a model makes correct predictions on every element in both the origi set. Model Method IMDB AG MR SNLI BERT Vanilla 88.7 88.8 68.4 48.6 FreeLB 91.9 93.3 75.9 56.1 RoBERTa Vanilla 93.9 91.9 79.7 55.1 FreeLB 95.2 93.5 81.0 58.1 CLINE Vanilla 94.7 92.3 80.4 55.4 FreeLB 95.9 94.2 82.1 58.7 Table 5: Accuracy on the adversarial test set. RoBERTa across the original test set (Ori) and con- trastive test set (Rev). Contrast consistency (Con) is a metric defined by Gardner et al. (2020) to evalu- to replace them wit and grammatically From the experi can observe that ou accuracy on all the pared to the vanilla structing similar s and using the cont model can concen original example an then achieve better method is in the pr be combined with t methods. Compare PLM Proposed ② 敵対的学習と組み合わせることでさらに予測性能が向上(SOTA)
corpus as negative samples. Finally, we have the following training loss: L= 1LMLM + 2LRTD + 3Lcts, (7) where i is the task weighting learned by training. 4 Experiments We conduct extensive experiments and analyses to evaluate the effectiveness of CLINE. In this sec- tion, we firstly introduce the implementation (Sec- the gi • BoolQ ing c (yes o • AG level topic ence/ • MR ( sentim ①Masked Language Model ③Contrastive Loss ②置換トークン検出タスク ➠ 3つ必要でした。(アブレーションテストを実施) 評価4:⽂レベルの類似度に使う特徴量はどれが適切? ➠ BertScore > 平均 > [CLS] の順に性能が良い ➠ BERTベースCLINE > RoBERTaベースCLINE > BERT > RoBERTa の順に性能が良い • [CLS]出⼒層コサイン距離 / 全出⼒平均ベクトルコサイン距離 / BertScore [Zhang+20] の3種類 • similarity(original, adversarial) > similarity(original, contrastive) かどうかを定量評価 • BERT/RoBERTa/CLINEで試す • ⽂特徴量はBERTベースの⽅が性能が良い • RoBERTaはNextSentencePredictionタスクを省いているから?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contrastive Loss the dot product between [CLS] embeddings: f(x⇤, x0)](https://files.speakerdeck.com/presentations/bb797680f95347be9b19788effe4b202/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![評価1 Contrastive Examplesの正解データセット ContrastSets [Gardner+20] https://github.com/allenai/contrast-sets 4つのダウンストリームタスクにおいてオリジナル⽂(Ori)に対するContrastive Examples(Rev)が作成されている IMDB :](https://files.speakerdeck.com/presentations/bb797680f95347be9b19788effe4b202/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![評価2 Adversarial Examplesの正解データセット TextFooler [Jin+20]を使いAdversarial Examplesを作成 4つのダウンストリームタスクにおいてオリジナル⽂中の重要単語を⽂法的に正しくかつ同義語に置換 IMDB : AG](https://files.speakerdeck.com/presentations/bb797680f95347be9b19788effe4b202/slide_17.jpg){kind=link}
![評価2の結果 ※ 尺度はAccuracy ※ FreeLBは敵対的学習[Zhu+20]を適応 ① Contrastive learningでもAdversarial Examplesでの予測性能が向上 (評価1の結果と合わせて)](https://files.speakerdeck.com/presentations/bb797680f95347be9b19788effe4b202/slide_18.jpg){kind=link}
{kind=link}
{kind=link}