2026/03/17 実施のイベント Snowflake Tech Fast Track の登壇資料です。
【Data Superhero セッション】
実務で効く Snowflake パフォーマンスチューニング入門
Snowflakeは基本的に自動最適化が強力なDWHですが、設計やクエリの書き方、Warehouseの使い方によって性能やコストは大きく変わります。本セッションでは、実務でよく遭遇する「クエリが遅い」「コストが増えた」といった課題を題材に、Query Profileの見方、クラスタリングやパーティション設計の考え方、Warehouse設定の基本、dbtと組み合わせて使う際の話など、パフォーマンス改善のためにまず押さえるべきポイントを整理して解説します。明日から使える実践的な考え方を中心に紹介します。
https://www.snowflake.com/snowflake-tech-fast-track/
登壇に関するテックブログも書いているのでご覧ください。
https://zenn.dev/finatext/articles/snowflake-tech-fast-track-2026-performance-tuning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
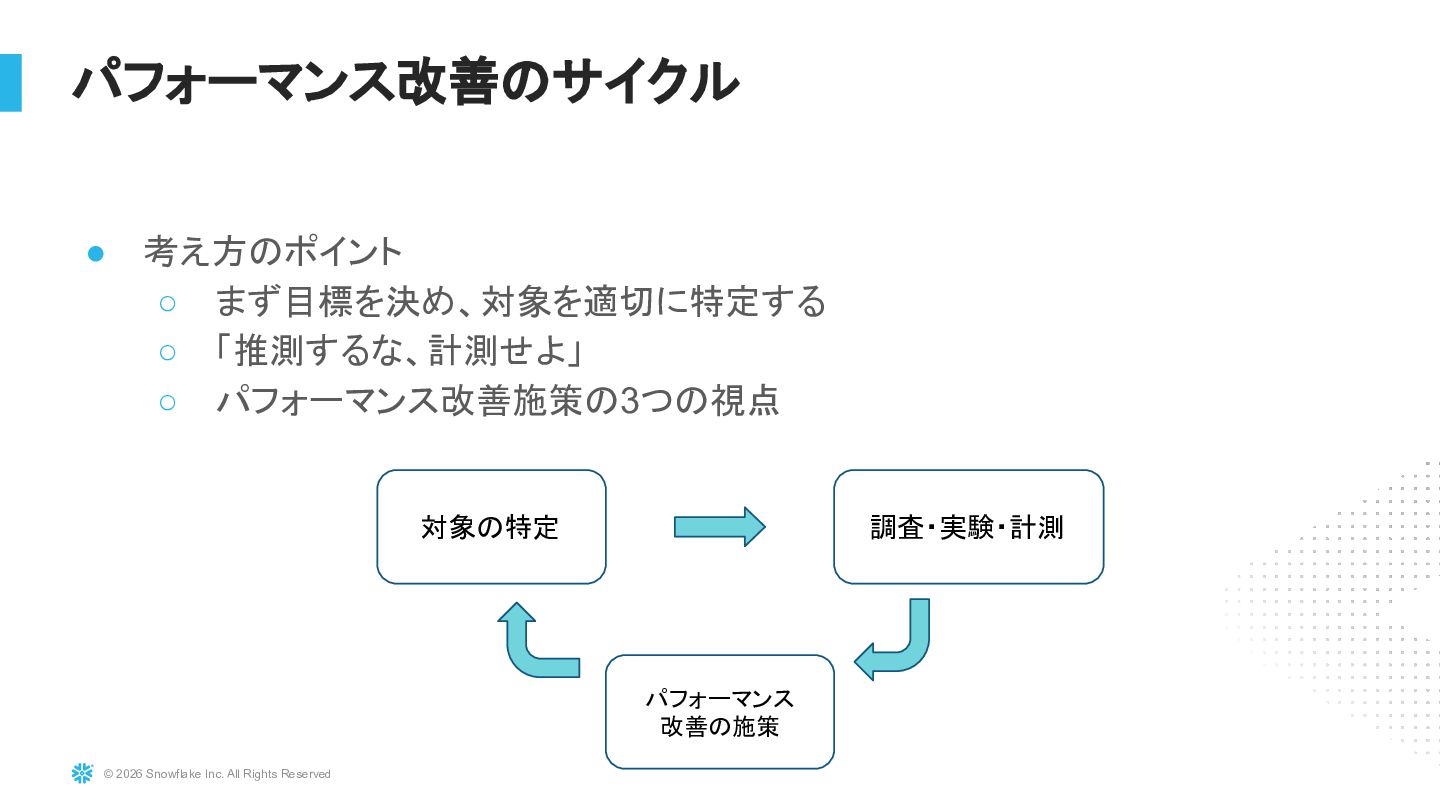{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
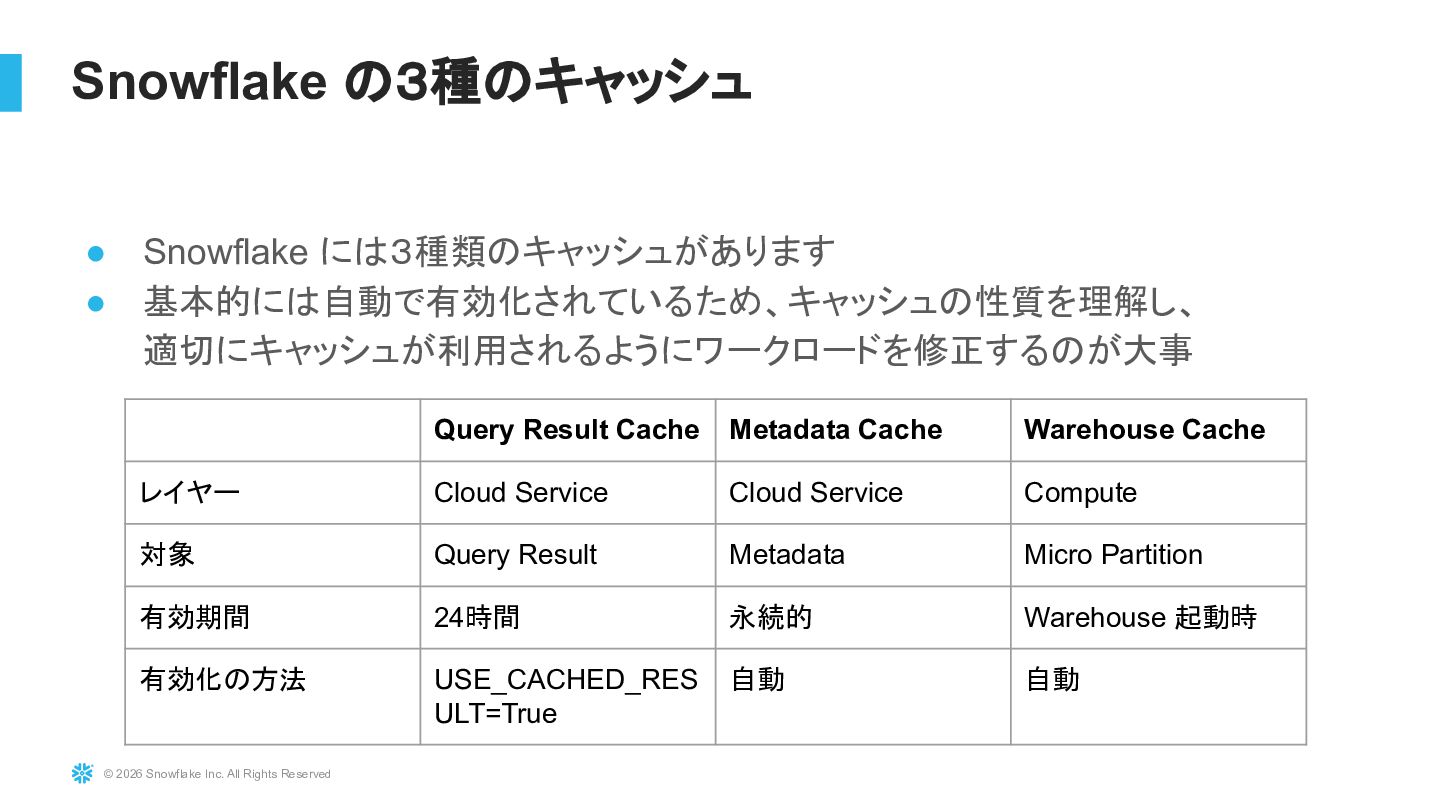{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
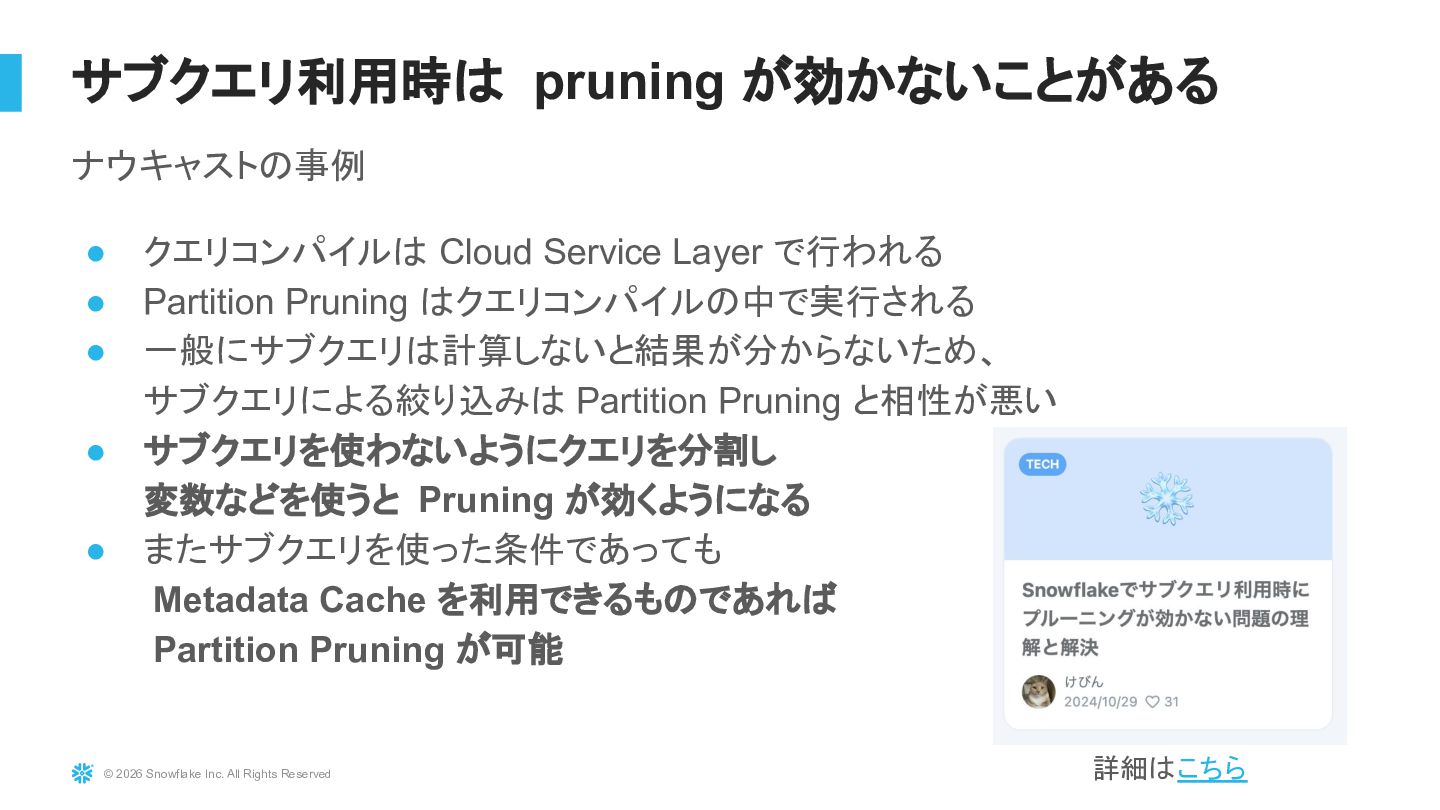{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
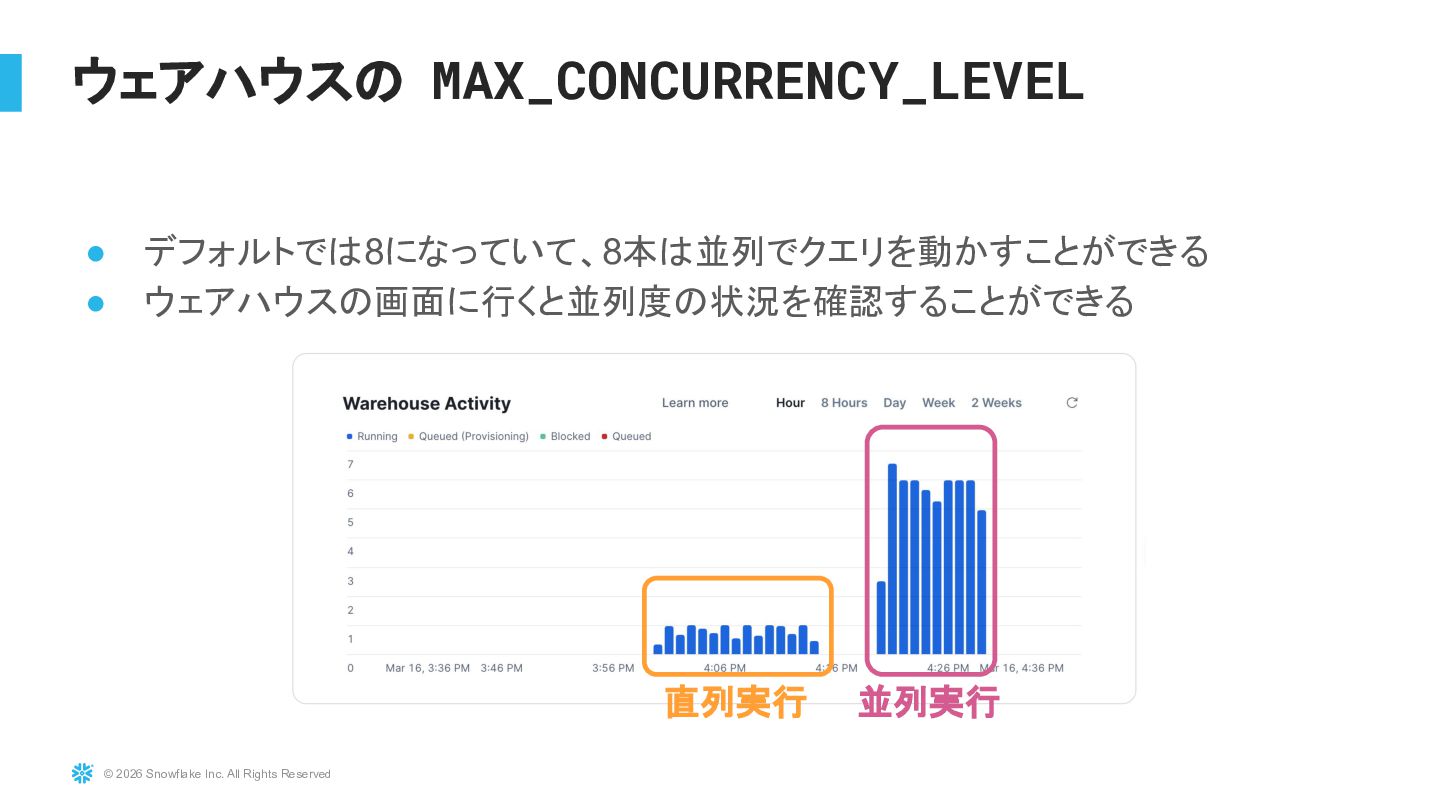{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}