Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ローカルLLMでどこまでコードが書けるか / How much code can be wri...
Search
Naoki Kishida
May 13, 2026
Programming
530
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ローカルLLMでどこまでコードが書けるか / How much code can be written on a local LLM
2026/5/13のイベントでの登壇資料です
https://levtechlab.connpass.com/event/389511/
Naoki Kishida
May 13, 2026
More Decks by Naoki Kishida
See All by Naoki Kishida
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
180
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.7k
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
180
ローカルLLM基礎知識 / local LLM basics 2025
kishida
30
17k
AIエージェントでのJava開発がはかどるMCPをAIを使って開発してみた / java mcp for jjug
kishida
5
1.2k
AIの弱点、やっぱりプログラミングは人間が(も)勉強しよう / YAPC AI and Programming
kishida
13
6.9k
海外登壇の心構え - コワクナイヨ - / how to prepare for a presentation abroad
kishida
2
190
Current States of Java Web Frameworks at JCConf 2025
kishida
0
1.8k
AIを活用し、今後に備えるための技術知識 / Basic Knowledge to Utilize AI
kishida
28
7.5k
Other Decks in Programming
See All in Programming
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
570
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
240
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.3k
関数型プログラミングのメリットって何だろう?
wanko_it
0
150
Webフレームワークの ベンチマークについて
yusukebe
0
200
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
460
初めてのKubernetes 本番運用でハマった話
oku053
0
120
TAKTでAI駆動開発の品質を設計する
j5ik2o
7
1.7k
AI駆動開発を妨げる技術的負債の解消アプローチ / ai-refactoring-approach
minodriven
17
8.7k
Go1.27で導入されるジェネリクスメソッドでできること
mackee
0
250
ランチタイムLT会3周年!ランチタイムLT会を3年間続けられたお話
y0hgi
1
130
Featured
See All Featured
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
Code Reviewing Like a Champion
maltzj
528
40k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.7k
The Language of Interfaces
destraynor
162
27k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
280
How to build a perfect <img>
jonoalderson
1
5.8k
Test your architecture with Archunit
thirion
1
2.3k
Rails Girls Zürich Keynote
gr2m
96
14k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Transcript
ローカルLLMでどこまでコードが書けるのか 2026-05-13 レバテックLAB 「ローカルLLM 組織での“実運用”の可能性」 きしだ なおき
05/13/2026 2 自己紹介 • きしだ なおき • X(twitter): @kis •
サブスクも始めました。 • blog: きしだのHatena • (nowokay.hatenablog.com) • 「プロになるJava」というJavaの本を書いてます
3 2023年からの3年で おうちで動くLLMはどう変わったか
2023 「動いて偉い!」 • チャットのできるモデルが出始める • 日本語を学習させないと 日本語は話せない • 「対話できてえらい」 「聞いたことに答えてくれて
偉い」
2024「まともに動く!」 • まともな意味のある長文を出す • 特別に学習しなくても日本語で答える
2025「使えそう!」 • Gemma 3/Qwen3登場 • 意味のある動くプログラムを一発で出す • 専門的な内容を解説する
2026「使える!」 • Gemma 4 / Qwen3.6登場 • 英語のレポートを要約して解説 • まとまったプログラムを作る
• エージェントで作業する
現在の状況(モデル) • 30Bくらいのモデル • 1往復でおわるチャットには十分 • 要約、翻訳、簡単な質問 • 最初のコーディングなら十分 •
デバッグには ハマることがある • 500B以上のモデル • 高度なこと以外には十分 • メモリ高騰が残念
現在の状況(ビジネス的) • コーディングエージェント使い放題はコストがかさむ • プロプラモデルは制限がきびしい • プロプラモデルは値上がりする • サーバーが足りてない •
新しい高性能モデルは高くなっていってる
今日の話 • 手元のマシンでコーディング作業を行う • 32GB-64GBの統合メモリでQwen3.6 / Gemma 4を動かす • 将来的には192GB-256GBで250B程度を動かす
• 15万トークン以内の作業 • LLM用サーバーで共有はおすすめしない • コーディングの高負荷でサーバーを運用するのは大変 • ある程度をQwen3.6 / Gemma 4でまかなうならコスト回収も大変 • オープンモデルでもAPIを使ったほうがいい • 単にモデル選択と利用料金の問題になる
いま使えるモデル • Dense / MoE • MoEは一部だけ動かす • 速いし知識がある •
Denseは全部動かす • 重いけど賢い • アテンション • フル – O(n^2) 重いけど賢い • スライド – 全体を見れないけど確実な作業 • スパース - 全体を見るけど少しあいまい • 線形 – 計算を工夫してO(n)、誤差で間違いが出やすい
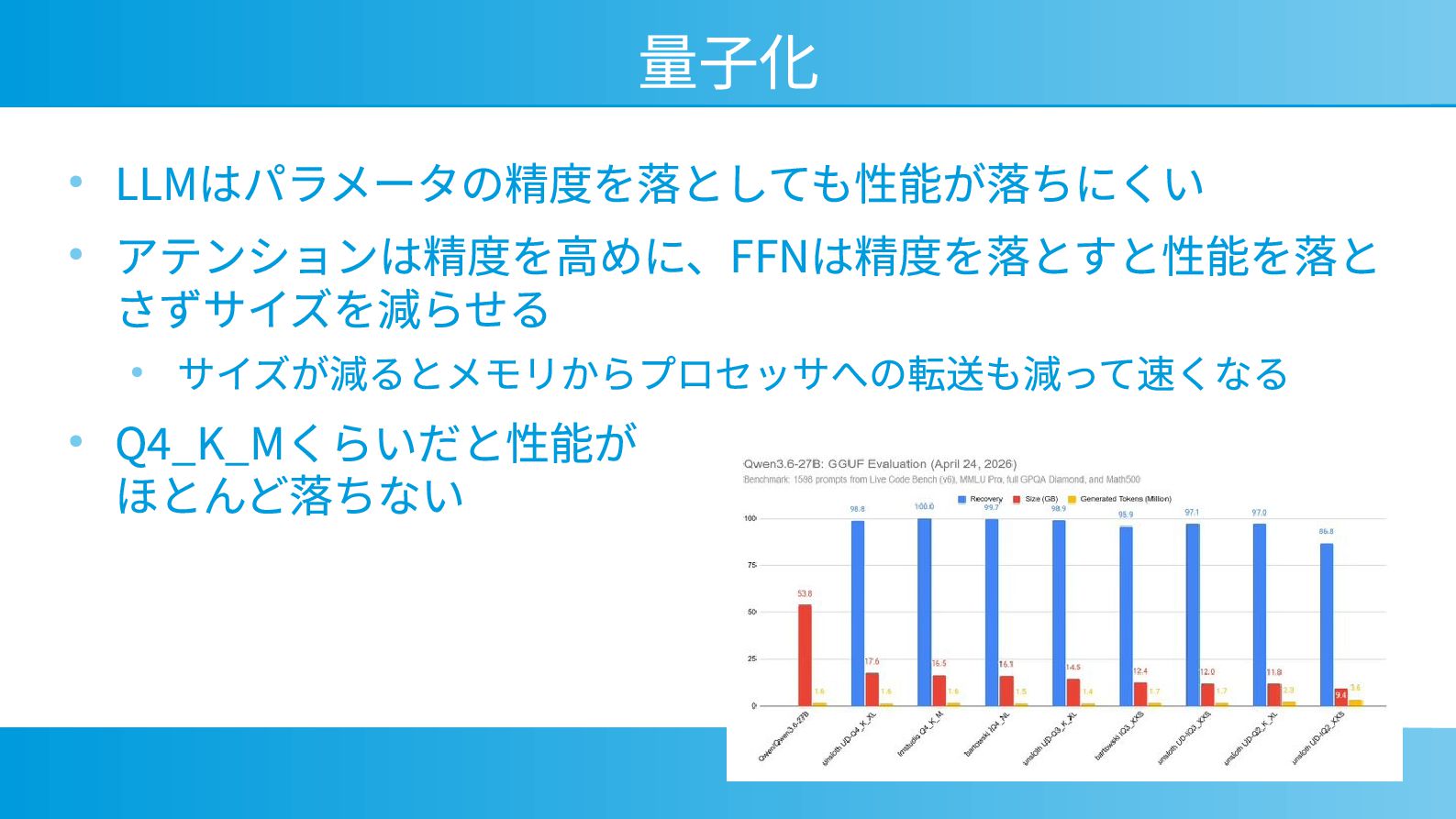
量子化 • LLMはパラメータの精度を落としても性能が落ちにくい • アテンションは精度を高めに、FFNは精度を落とすと性能を落と さずサイズを減らせる • サイズが減るとメモリからプロセッサへの転送も減って速くなる • Q4_K_Mくらいだと性能が
ほとんど落ちない
ハードウェア • SoC – CPU/NPU/GPUを統合したチップ • AMD Ryzen AI Max+
395 – EVO-X2: 128GB / 48万円 • Intel Core Ultra 7 – MINISFORM M2 32GB / 22万円 • NVIDIA GB10 – Ascent GX10: 128GB / 58万円 • Apple Silicon – Mac Studio: 96GB / 60万円 • GPU(32GB) • RTX 5060 Ti 16GB x2 / 20万円 • Intel Arc Pro B70 / 22万円 • Radeon AI Pro R9700 / 25万円 • RTX 5090 / 60万円~ • RTX PRO 4500 / 60万円
ソフトウェア • 推論エンジン • llama.cpp • MLX • 管理ツール •
LM Studio • Ollama • チャット • Open WebUI • コーディングエージェント • OpenCode • Claude Code • Codex
最適化 • ハードウェアの進化だけでは動かせるモデルは増えない • 230Bくらいが限界そう • メモリ削減 • TurboQuant •
KVキャッシュ(それまでの出力の計算結果)を削減 • 速度向上 • MTP(multi-token prediction) • 投機的デコード • 軽いモデルに3トークン出させて本番モデルで答え合わせ
まとめ • かなり実用になってきている • HTML画面の最初の作り起こしなどは十分にまかせれる • コスト削減 • デバッグや設計などはフロンティアモデルを使う •
将来的にはかなりの作業を手元でできるはず • その準備は やっておいたほうがいい •
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}