Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[IR Reading 2023春 論文紹介] A Unified Framework for...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kohei Shinden
PRO
June 10, 2023
Research
190
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[IR Reading 2023春 論文紹介] A Unified Framework for Learned Sparse Retrieval (ECIR 2023) /IR-Reading-2023-Spring
https://sigirtokyo.github.io/post/2023-06-10-irreading_2023spring/
Kohei Shinden
PRO
June 10, 2023
More Decks by Kohei Shinden
See All by Kohei Shinden
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
220
[IR Reading 2023秋 論文紹介] On the Impact of Outlier Bias on User Clicks (SIGIR 2023) /IR-Reading-2023-Fall
koheishinden
PRO
0
200
[IR Reading 2022秋 論文紹介] Price DOES Matter!: Modeling Price and Interest Preferences in Session-based Recommendation (SIGIR 2022) /IR-Reading-2022-Fall
koheishinden
PRO
0
190
[ACM SIGMOD-J 79] The Web Conference 2022 国際会議報告 Security セッション /ACM-SIGMOD-J-79-The-Web-Conf-2022
koheishinden
PRO
0
190
[IR Reading 2022春 論文紹介] Personalized Transfer of User Preferences for Cross-domain Recommendation (WSDM 2022) /IR-Reading-2022-Spring
koheishinden
PRO
0
190
[IR Reading 2021秋 論文紹介] Fairness among New Items in Cold Start Recommender Systems (SIGIR 2021) /IR-Reading-2022-Fall
koheishinden
PRO
0
190
[IR Reading 2021春 論文紹介] Investigating the Influence of Ads on User Search Performance, Behaviour, and Experience during Information Seeking (CHIIR 2021) /IR-Reading-2021-Spring
koheishinden
PRO
0
190
Other Decks in Research
See All in Research
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
470
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
630
SLAMはどこまで解決されたのか?
tomonom
0
800
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
700
重要だけど測れていないもの:高齢者ケアの見えない課題
theoriatec2024
0
410
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
260
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
300
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
110
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
580
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
380
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
Featured
See All Featured
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Visualization
eitanlees
152
17k
A Tale of Four Properties
chriscoyier
163
24k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
The Spectacular Lies of Maps
axbom
PRO
1
860
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
We Have a Design System, Now What?
morganepeng
55
8.2k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
270
A better future with KSS
kneath
240
18k
ラッコキーワード サービス紹介資料
rakko
1
3.9M
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Transcript
[論⽂紹介] A Unified Framework for Learned Sparse Retrieval Thong Nguyen1,
Sean MacAvaney2, Andrew Yates1 1University of Amsterdam, 2University of Glasgow ECIR 2023 論⽂紹介する⼈ 筑波⼤学加藤研究室 新⽥洸平 https://sites.google.com/view/kohei-shinden ※スライド中の図表は論⽂より引⽤ 2023年6⽉10⽇ IR Reading 2023 春 ⼀般セッション2 No.3
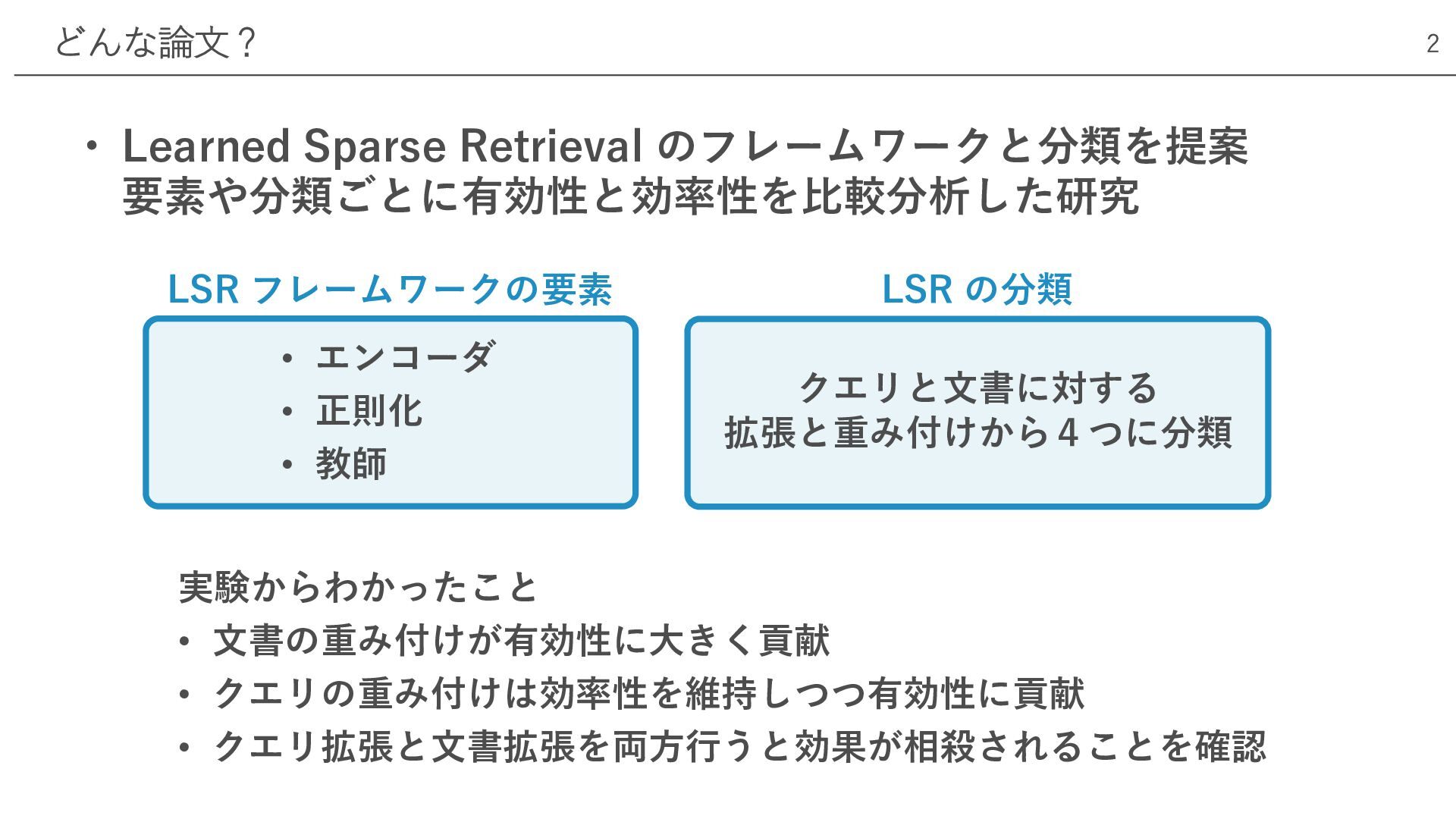
• Learned Sparse Retrieval のフレームワークと分類を提案 要素や分類ごとに有効性と効率性を⽐較分析した研究 どんな論⽂? 2 実験からわかったこと •
⽂書の重み付けが有効性に⼤きく貢献 • クエリの重み付けは効率性を維持しつつ有効性に貢献 • クエリ拡張と⽂書拡張を両⽅⾏うと効果が相殺されることを確認 LSR フレームワークの要素 LSR の分類 • エンコーダ • 正則化 • 教師 クエリと⽂書に対する 拡張と重み付けから4つに分類
• Learned Sparse Retrieval (LSR)とは データセットから単語の重要度を学習し利⽤するスパース検索 ‒ 現在主流である転置インデックスベースの⼿法をそのまま利⽤可能 ‒ 重要度の学習には
BERT などの Transformer ベースのモデルを利⽤ ‒ 代表的な⼿法: SPLADE, DeepCT, uniCOIL, TILDE, EPIC etc. Learned Sparse Retrieval とは? 3 BM25 を LSR 的に考えると IDF を Query Encoder, TF を Document Encoder と捉えられる (LSR では重み付けを⾏う Encoder が Transformer)
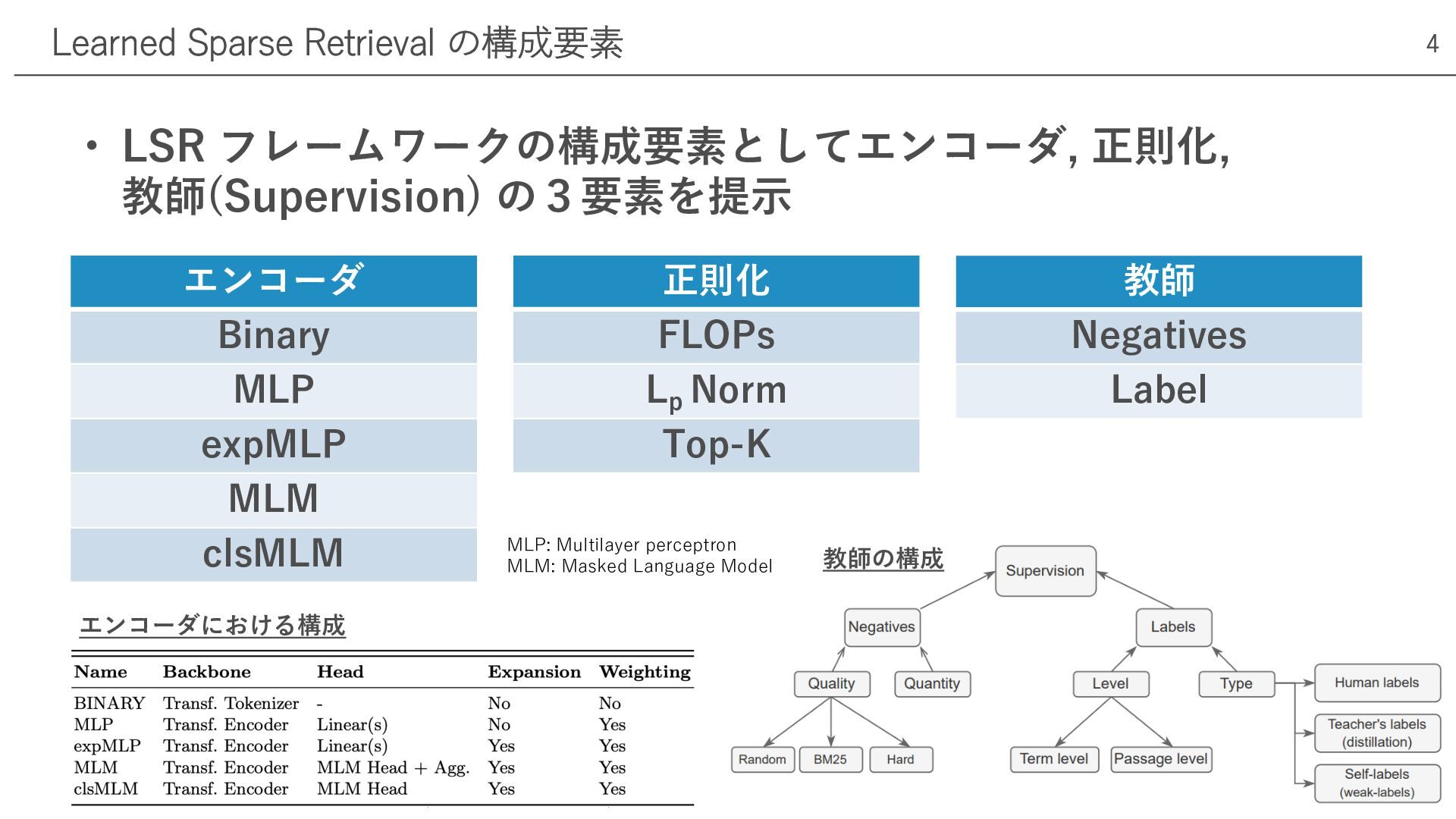
• LSR フレームワークの構成要素としてエンコーダ, 正則化, 教師(Supervision) の3要素を提⽰ Learned Sparse Retrieval の構成要素
4 エンコーダ Binary MLP expMLP MLM clsMLM 正則化 FLOPs Lp Norm Top-K 教師 Negatives Label 教師の構成 エンコーダにおける構成 MLP: Multilayer perceptron MLM: Masked Language Model
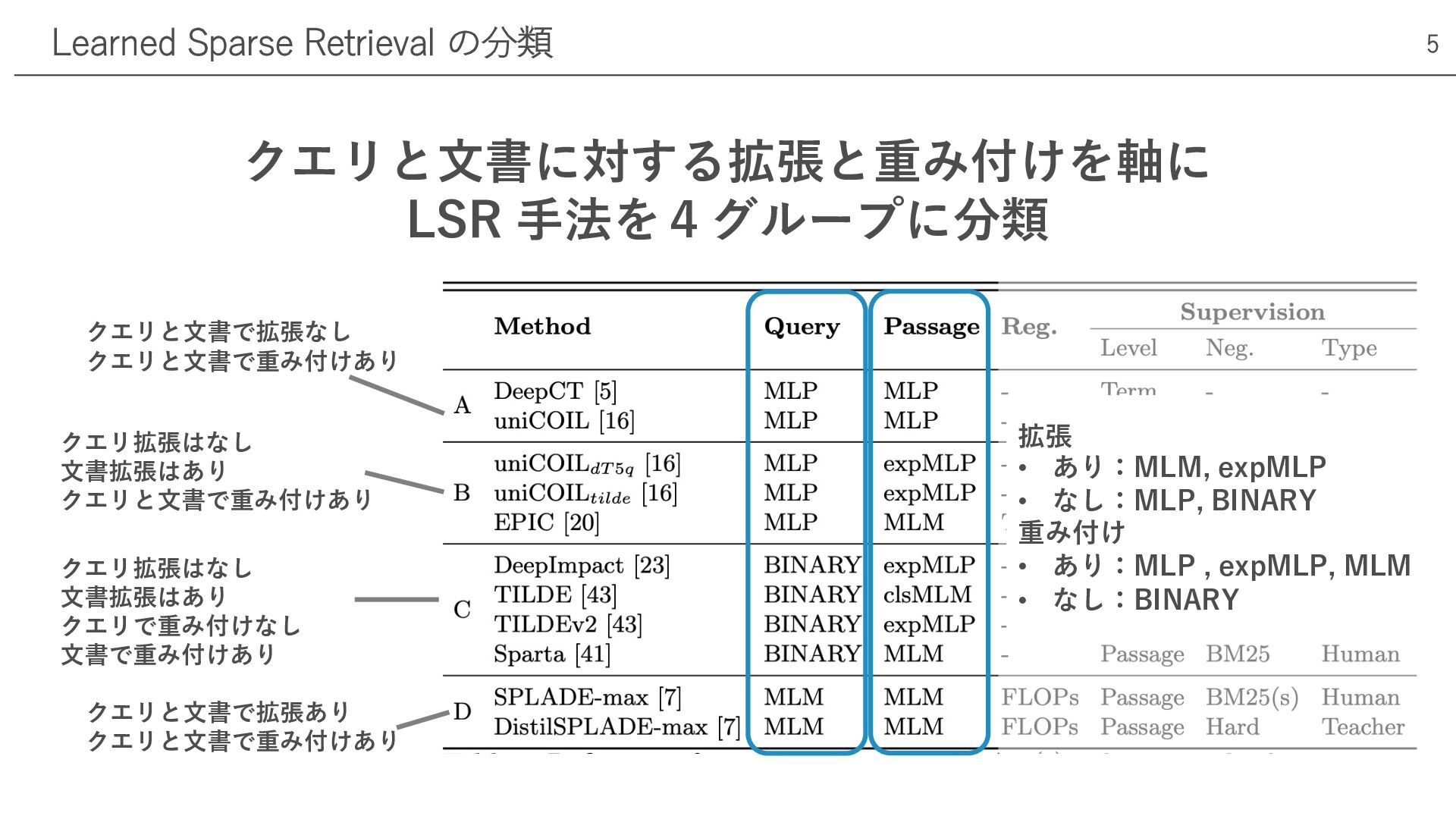
クエリと⽂書に対する拡張と重み付けを軸に LSR ⼿法を4グループに分類 Learned Sparse Retrieval の分類 5 クエリと⽂書で拡張なし クエリと⽂書で重み付けあり
クエリ拡張はなし ⽂書拡張はあり クエリと⽂書で重み付けあり クエリ拡張はなし ⽂書拡張はあり クエリで重み付けなし ⽂書で重み付けあり クエリと⽂書で拡張あり クエリと⽂書で重み付けあり 拡張 • あり:MLM, expMLP • なし:MLP, BINARY 重み付け • あり:MLP , expMLP, MLM • なし:BINARY
リサーチクエスチョン 6 既存 LSR ⼿法における結果は再現可能か? →既存⼿法とほぼ同等の性能で再現可能 既存⼿法 + 最新の学習⼿法でパフォーマンスはどうなるか? →ハードネガティブのマイニングやクロスエンコーダからの蒸留
を取り⼊れることで既存⼿法の性能も⼤きく向上 エンコーダアーキテクチャの違いはどう影響するか? →拡張・重み付け・正則化を⽐較した結果,⽂書の重み付けが ⼤きな効果を⽰し,クエリ拡張と⽂書拡張を同時に⾏うと 効果が相殺されることがわかった RQ1 RQ2 RQ3
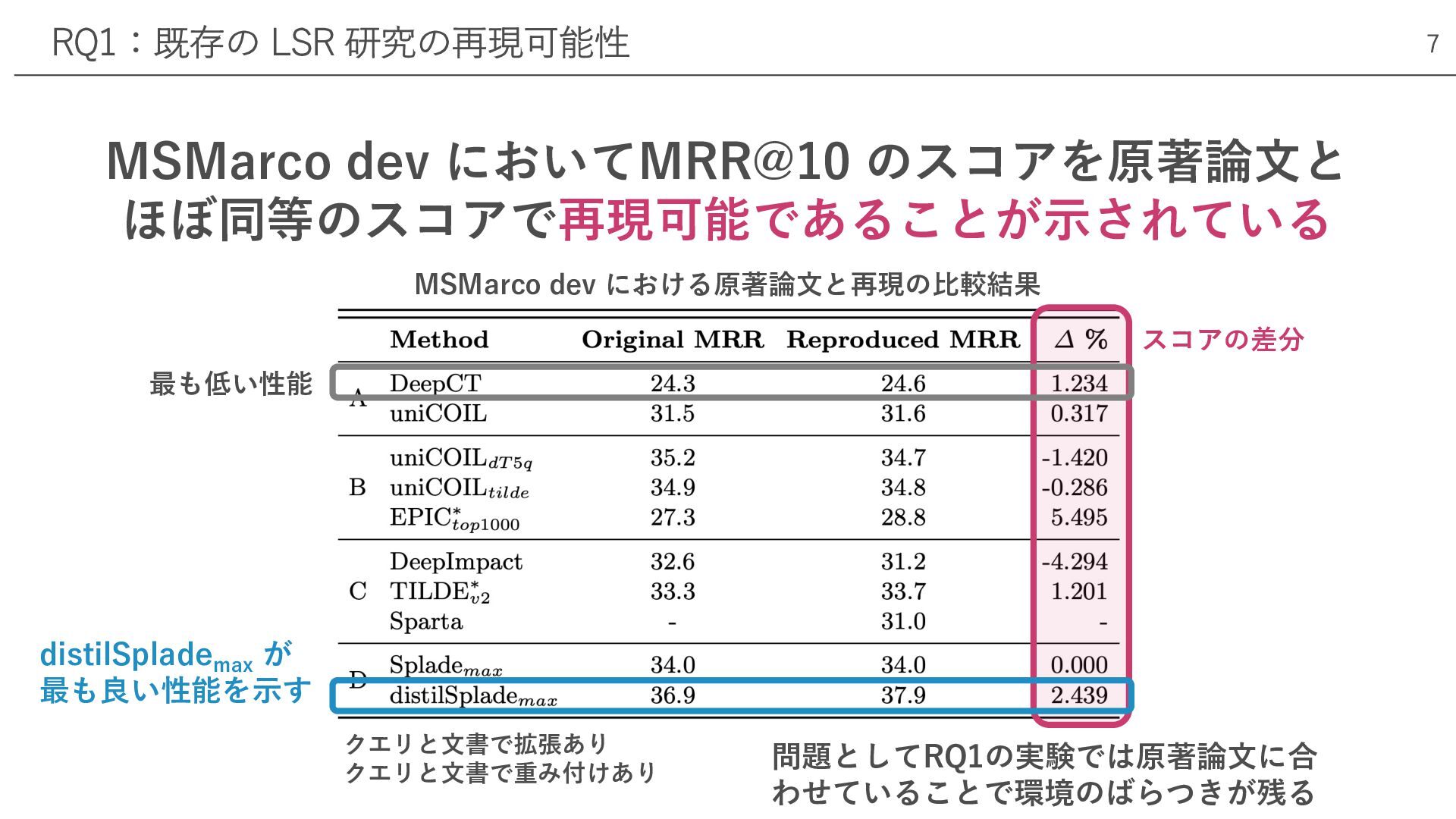
MSMarco dev においてMRR@10 のスコアを原著論⽂と ほぼ同等のスコアで再現可能であることが⽰されている RQ1:既存の LSR 研究の再現可能性 distilSplademax が
最も良い性能を⽰す 7 MSMarco dev における原著論⽂と再現の⽐較結果 スコアの差分 クエリと⽂書で拡張あり クエリと⽂書で重み付けあり 問題としてRQ1の実験では原著論⽂に合 わせていることで環境のばらつきが残る 最も低い性能
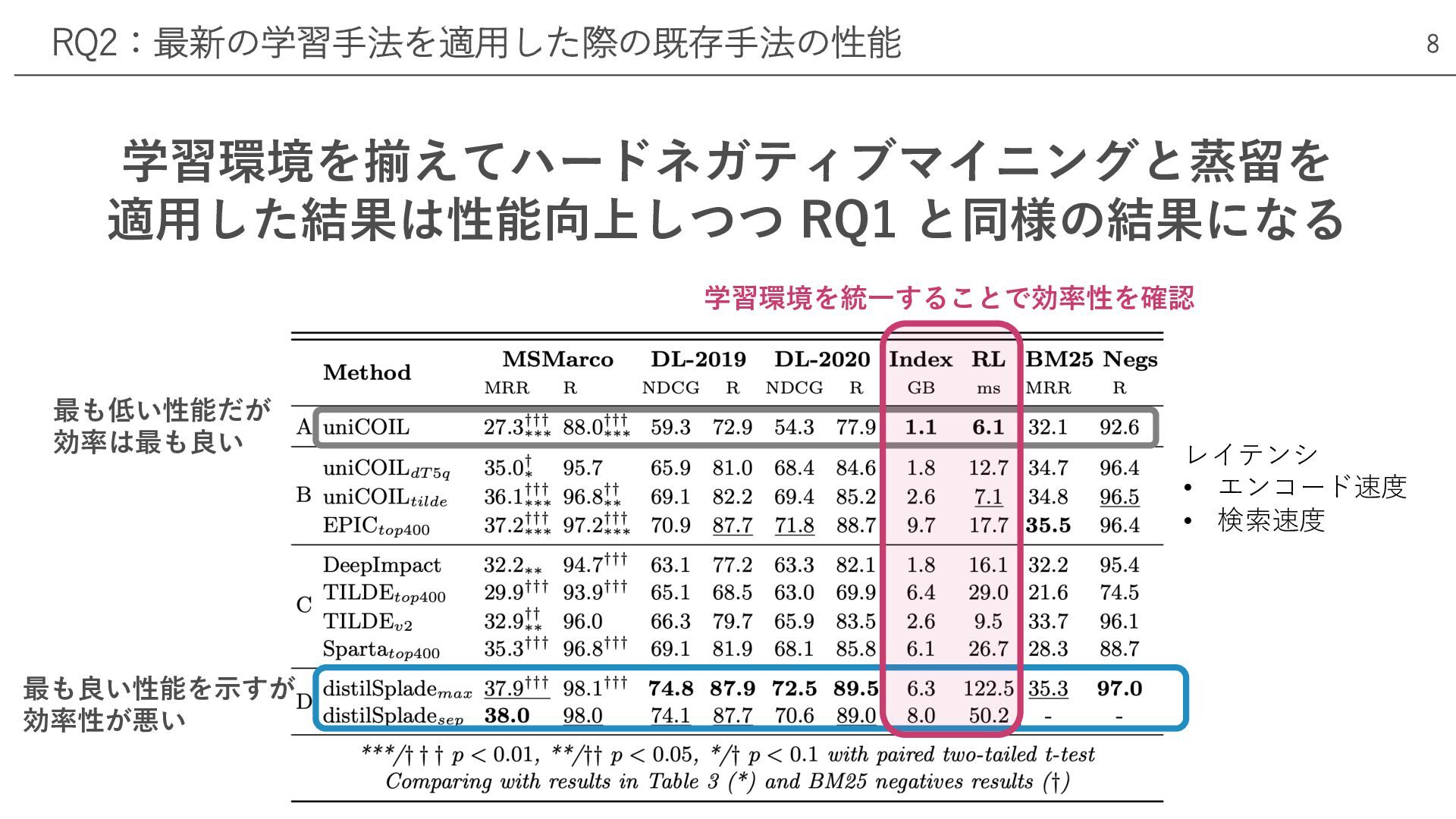
学習環境を揃えてハードネガティブマイニングと蒸留を 適⽤した結果は性能向上しつつ RQ1 と同様の結果になる RQ2:最新の学習⼿法を適⽤した際の既存⼿法の性能 8 最も低い性能だが 効率は最も良い 最も良い性能を⽰すが 効率性が悪い
学習環境を統⼀することで効率性を確認 レイテンシ • エンコード速度 • 検索速度
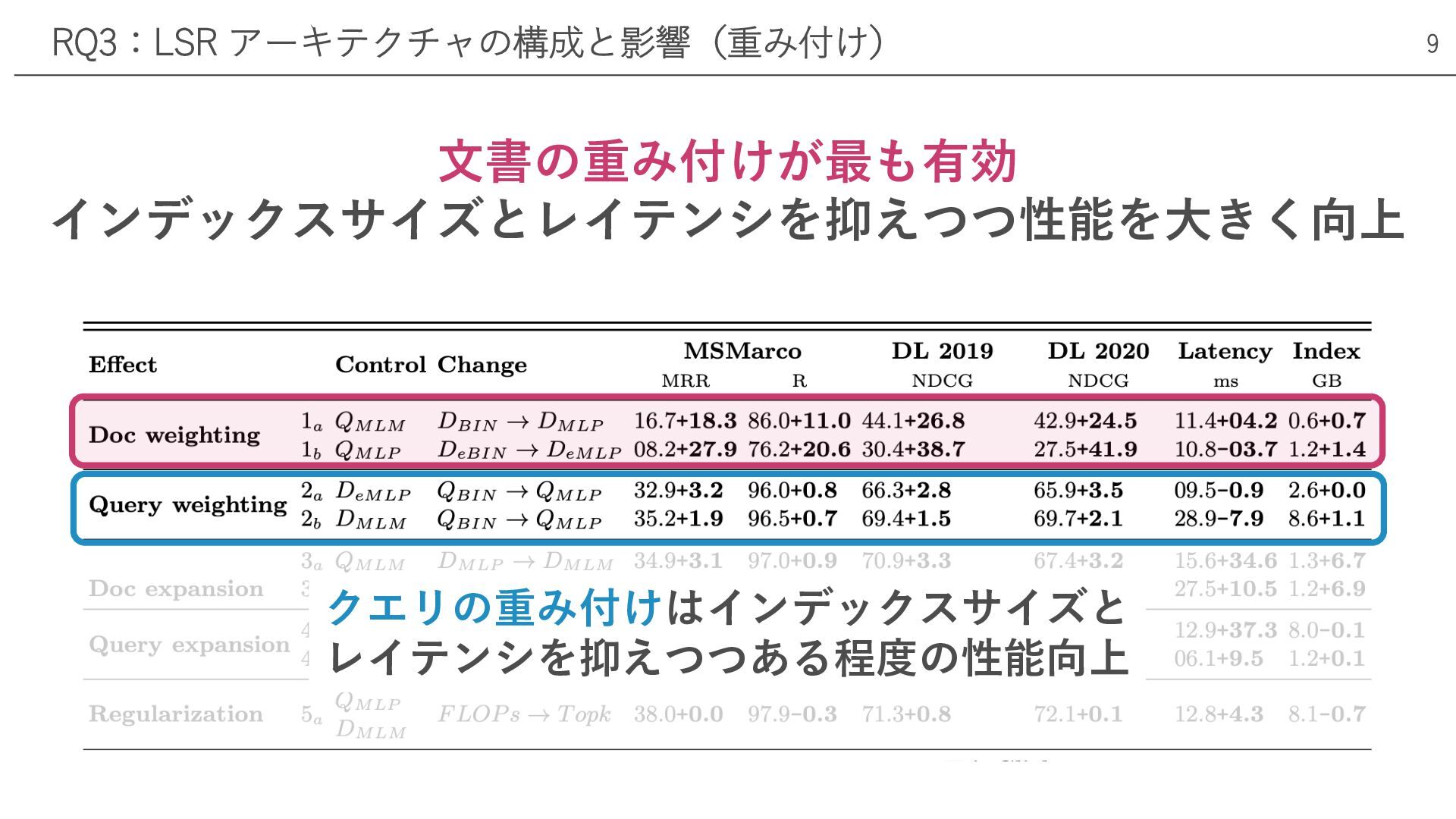
⽂書の重み付けが最も有効 インデックスサイズとレイテンシを抑えつつ性能を⼤きく向上 RQ3:LSR アーキテクチャの構成と影響(重み付け) クエリの重み付けはインデックスサイズと レイテンシを抑えつつある程度の性能向上 9
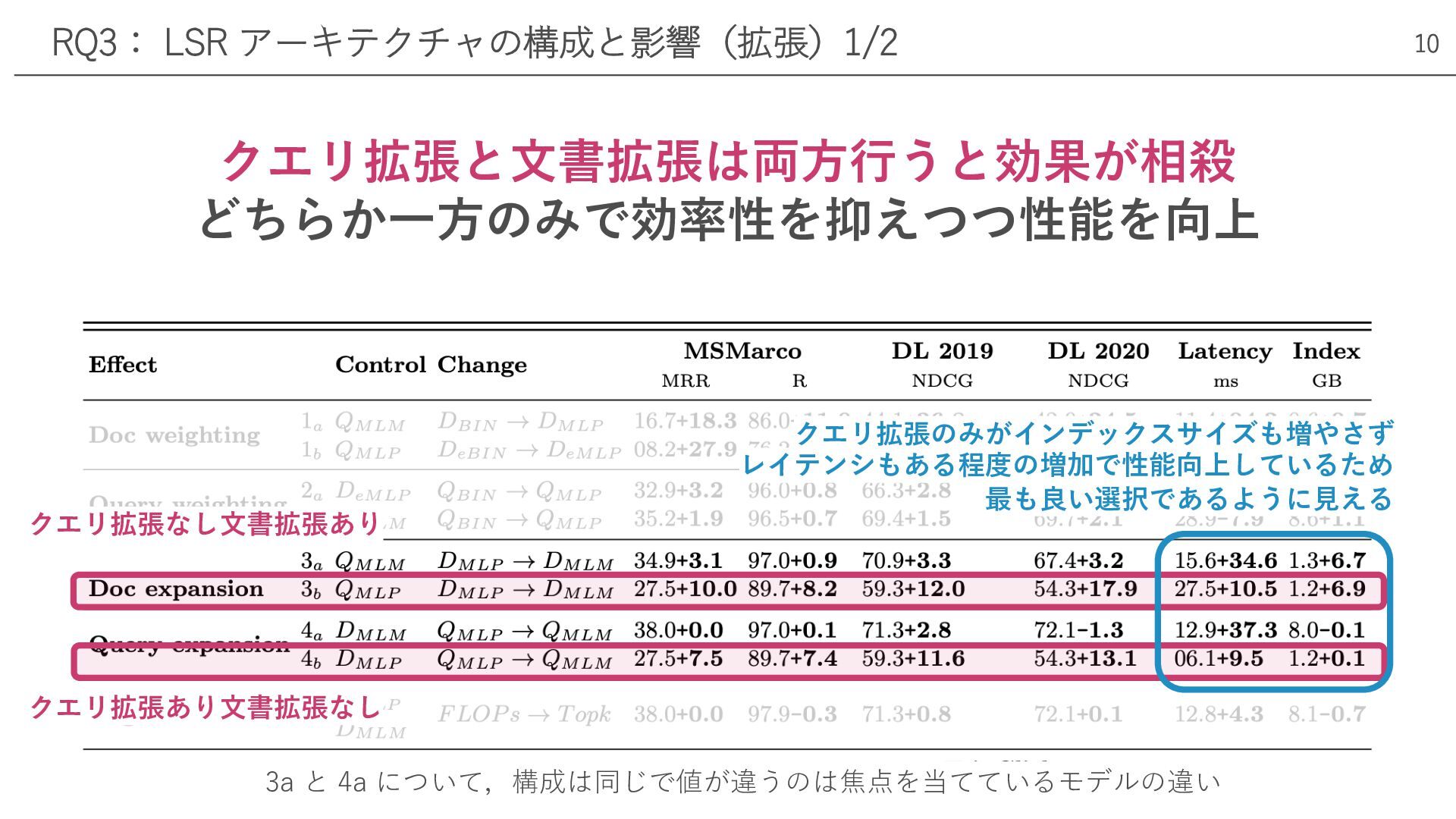
クエリ拡張と⽂書拡張は両⽅⾏うと効果が相殺 どちらか⼀⽅のみで効率性を抑えつつ性能を向上 RQ3: LSR アーキテクチャの構成と影響(拡張)1/2 クエリ拡張なし⽂書拡張あり クエリ拡張あり⽂書拡張なし クエリ拡張のみがインデックスサイズも増やさず レイテンシもある程度の増加で性能向上しているため 最も良い選択であるように⾒える
10 3a と 4a について,構成は同じで値が違うのは焦点を当てているモデルの違い
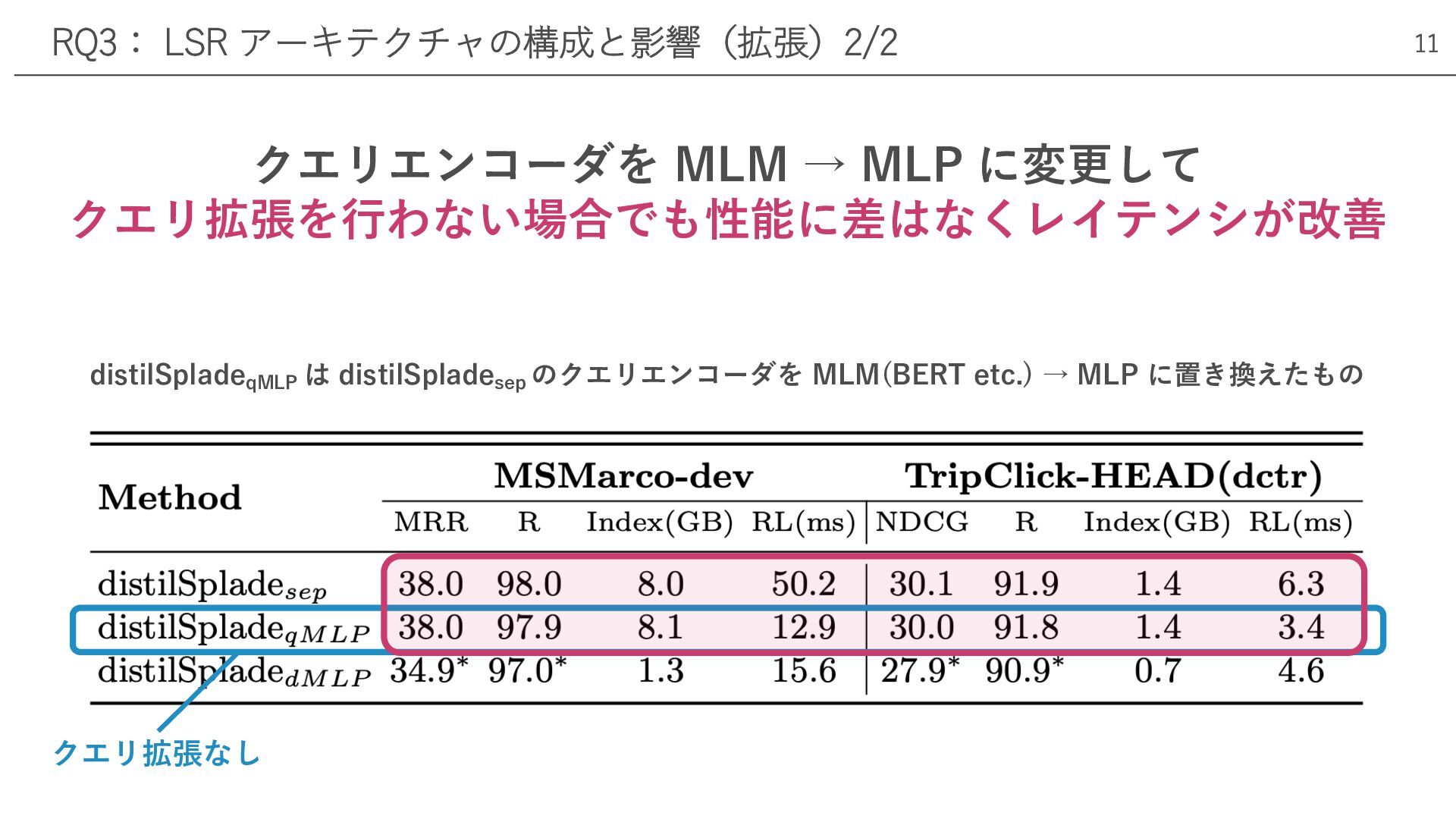
クエリエンコーダを MLM → MLP に変更して クエリ拡張を⾏わない場合でも性能に差はなくレイテンシが改善 RQ3: LSR アーキテクチャの構成と影響(拡張)2/2 クエリ拡張なし
distilSpladeqMLP は distilSpladesep のクエリエンコーダを MLM(BERT etc.) → MLP に置き換えたもの 11
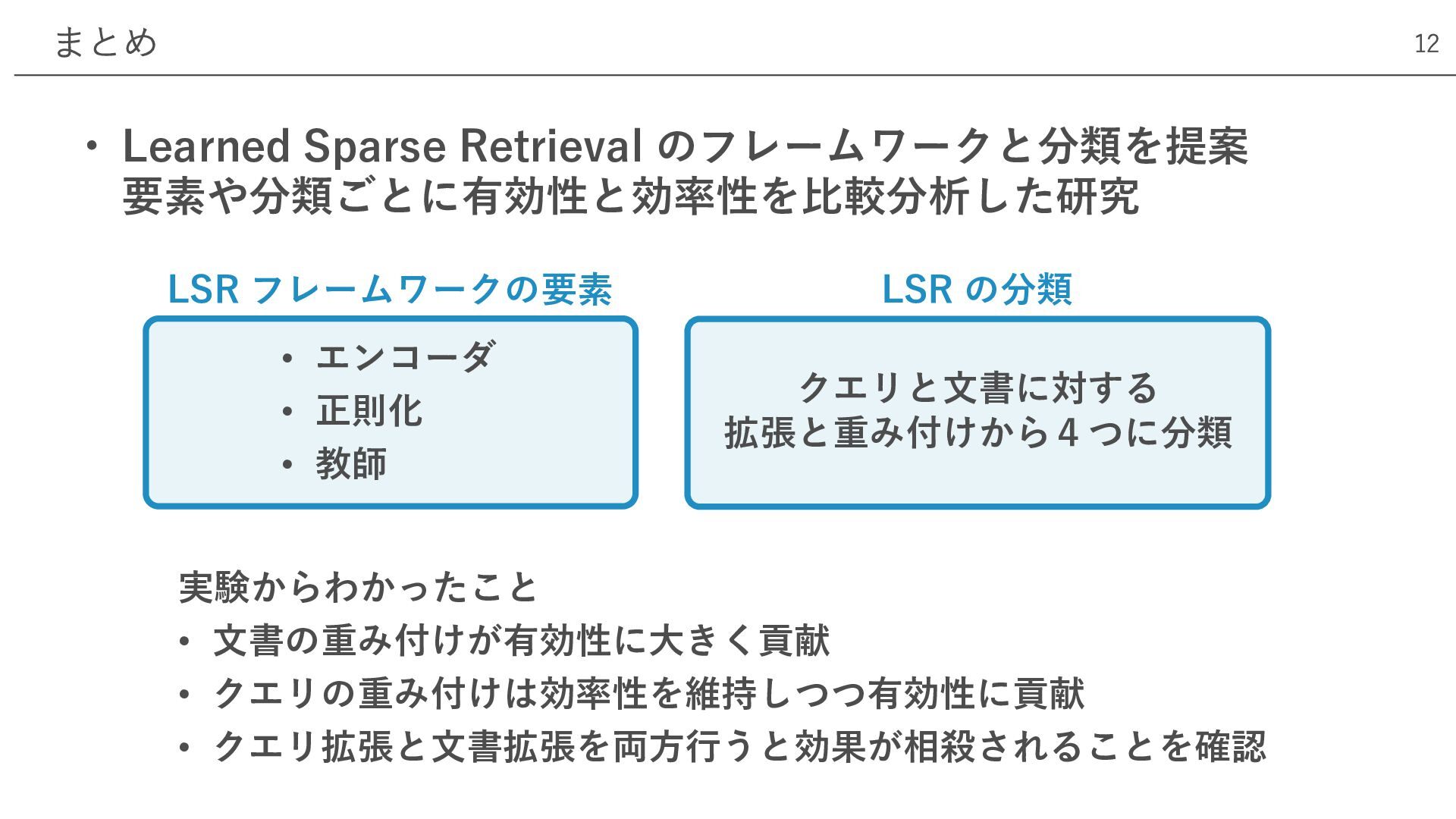
• Learned Sparse Retrieval のフレームワークと分類を提案 要素や分類ごとに有効性と効率性を⽐較分析した研究 まとめ 12 実験からわかったこと •
⽂書の重み付けが有効性に⼤きく貢献 • クエリの重み付けは効率性を維持しつつ有効性に貢献 • クエリ拡張と⽂書拡張を両⽅⾏うと効果が相殺されることを確認 LSR フレームワークの要素 LSR の分類 クエリと⽂書に対する 拡張と重み付けから4つに分類 • エンコーダ • 正則化 • 教師
![[論⽂紹介] A Unified Framework for Learned Sparse Retrieval Thong Nguyen1,](https://files.speakerdeck.com/presentations/ed44ab6239654239a2dcf313c3af8fb5/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}