Share
Python Charity Talks in Japan 2021.09 コミュニティセッション2:Unagi.py/Python駿河 https://pyconjp.connpass.com/event/218154/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
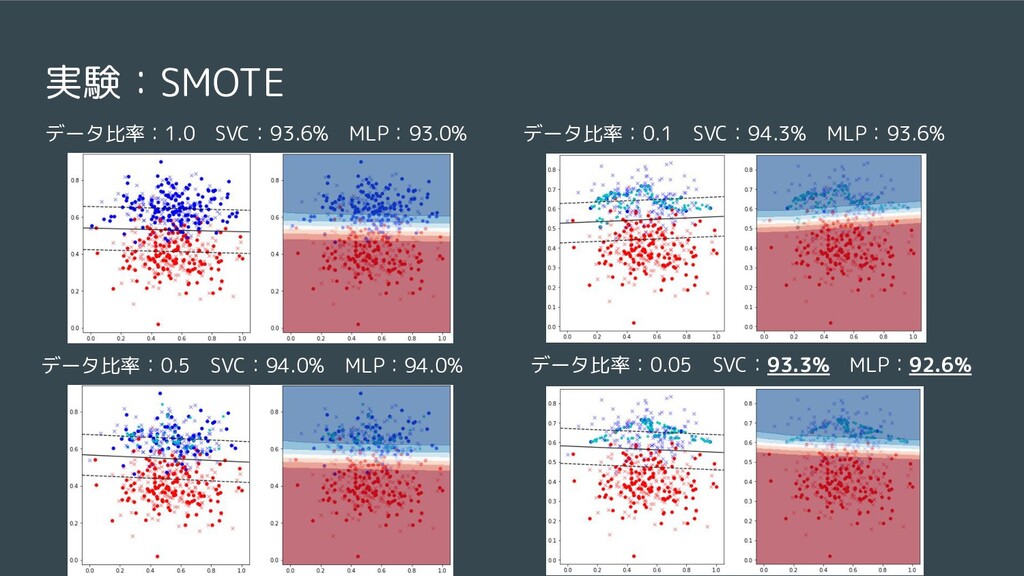
![一貫性のないデータセットへの対策 [3]C.Northcutt, L.Jiang, I.Chuang, “Confident Learning: Estimating Uncertainty in Dataset](https://files.speakerdeck.com/presentations/370dbf401a774c3e8195ea2a85cc7c31/slide_11.jpg){kind=link}
{kind=link}
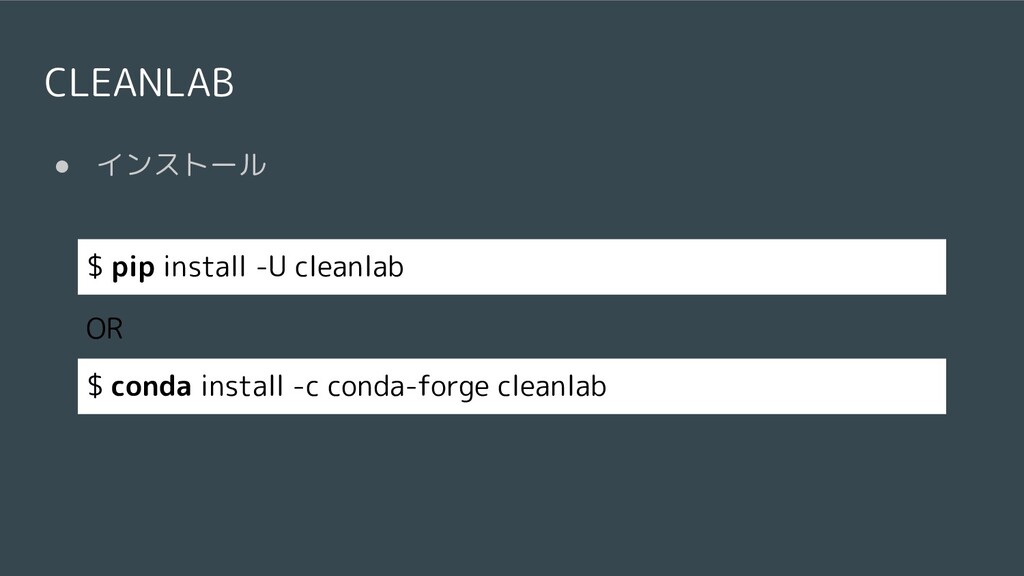
![CELANLABを使った学習 • sklearnのAPIとほぼ同じ感じで使える from cleanlab.classification import LearningWithNoisyLabels tr_X = [一貫性のない教師データ]](https://files.speakerdeck.com/presentations/370dbf401a774c3e8195ea2a85cc7c31/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
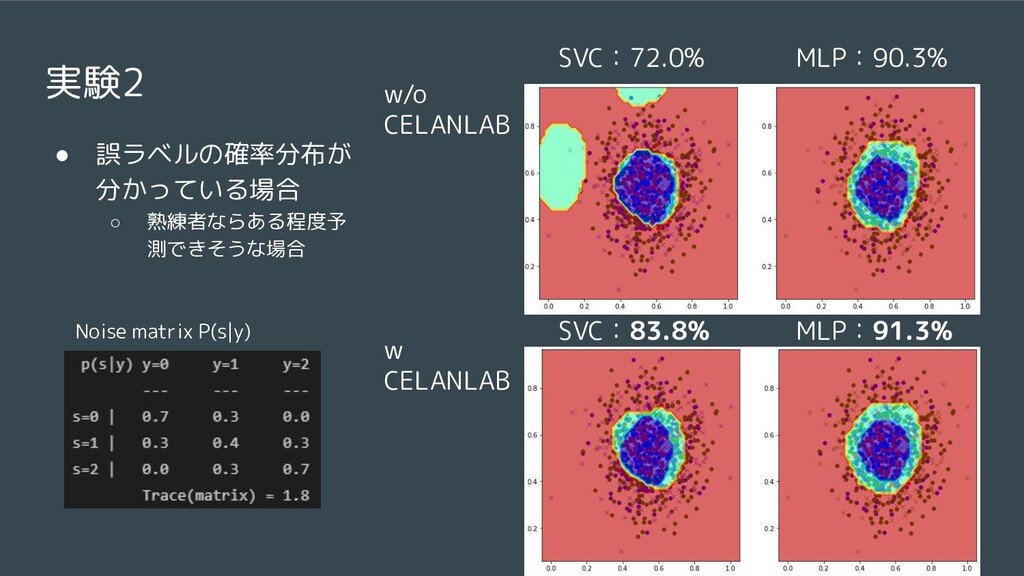{kind=link}
{kind=link}