defacto standard for storing data in a web application. • A lot of times, that data isn’t really relational at all. • RDBMS’s have lots of rules that can impact performance.
great for a lot of uses. • If you have data that’s actually relational and you need transactions, joins and have a limited number of data types, then an RDBMS will work for you.
are no transactions or relations so it’s a simple bucket and lookup. • Extremely flexible • Commonly used as caches in front of slower resources (like MySQL - bazinga!)
hashing algorithm allows you to scale easily to hundreds of nodes. • Redis - persistent, slightly more complex than memcached (has support for arrays) but still highly performant. • Riak - The Rails Machine guys love it. Jesse?
BigTable or Amazon’s Dynamo. • Pick two out of three from the CAP theorem in order to get horizontal scalability. • Data stored by column instead of by row.
data where you know your query scenario ahead of time. • Large = 100s of millions of records. • Data-mining log files and other sources of similar data.
documents, etc • Support for adding and removing things from arrays and embedded documents (addToSet, for example). • Map/Reduce support and strong indexes • Regular expression support in queries
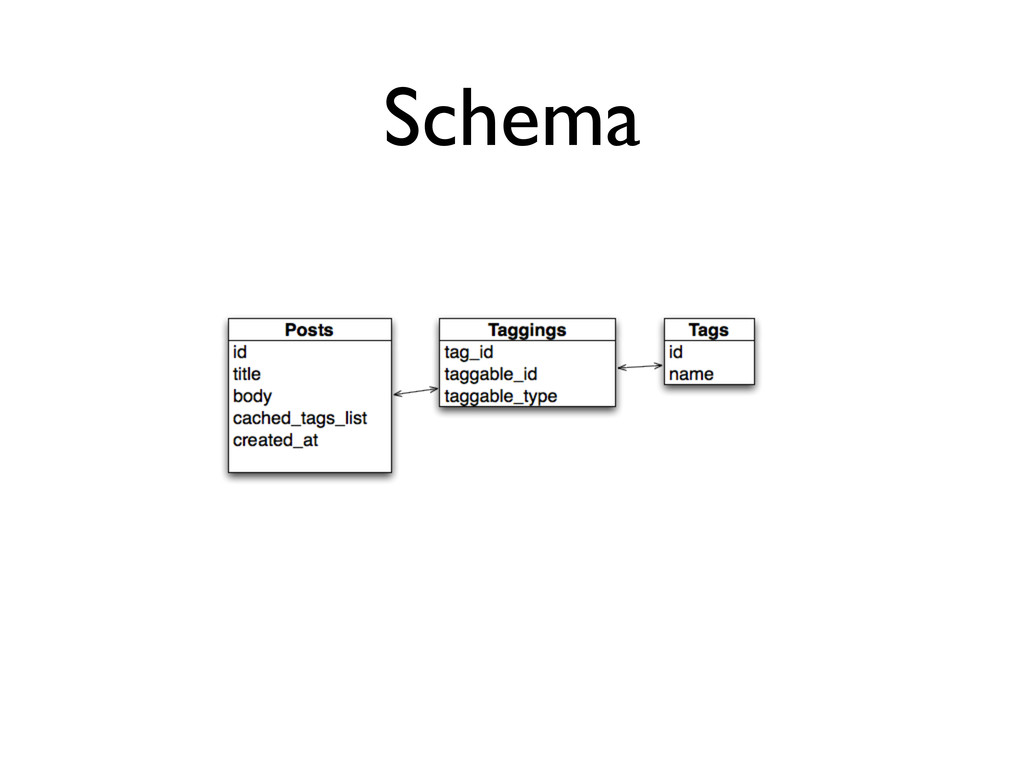
the embedded document will always be selected with the parent. • Indexes - MongoDB punishes you much earlier for missing indexes than MySQL. • Document size - Currently, documents are limited to 4MB, which should be large enough, but if it’s not...
<< tag self.add_to_set(:tags => tag) unless self.new_record? end def remove_tag(tag) tag = Post.clean_tag(tag) self.tags.delete(tag) self.pull(:tags => tag) unless self.new_record? end def self.clean_tag(str) str.strip.downcase.gsub(" ","-").gsub(/[^a-z0-9-]/,"") end def self.clean_tags(str) out = [] arr = str.split(",") arr.each do |t| out << self.clean_tag(t) end out end
build web apps. • For most apps, I don’t need transactions. • Eventual consistency is actually OK. • Partial updates and arrays make things that are a pain in SQL-land absolutely painless. • It’s just smart enough without getting in the way.
• We’ve got lots of options for storing application data. • The key is picking the one that solves our real problem. • And if an RDBMS is the right tool, that’s OK too.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! • Kevin Lawver • @kplawver • [email protected] • http://kevinlawver.com](https://files.speakerdeck.com/presentations/4e80db0471b5b70060000f2e/slide_43.jpg){kind=link}