If you're only using Ecto for schema modules, changeset functions, inserts, and updates, you're missing out on some great features.
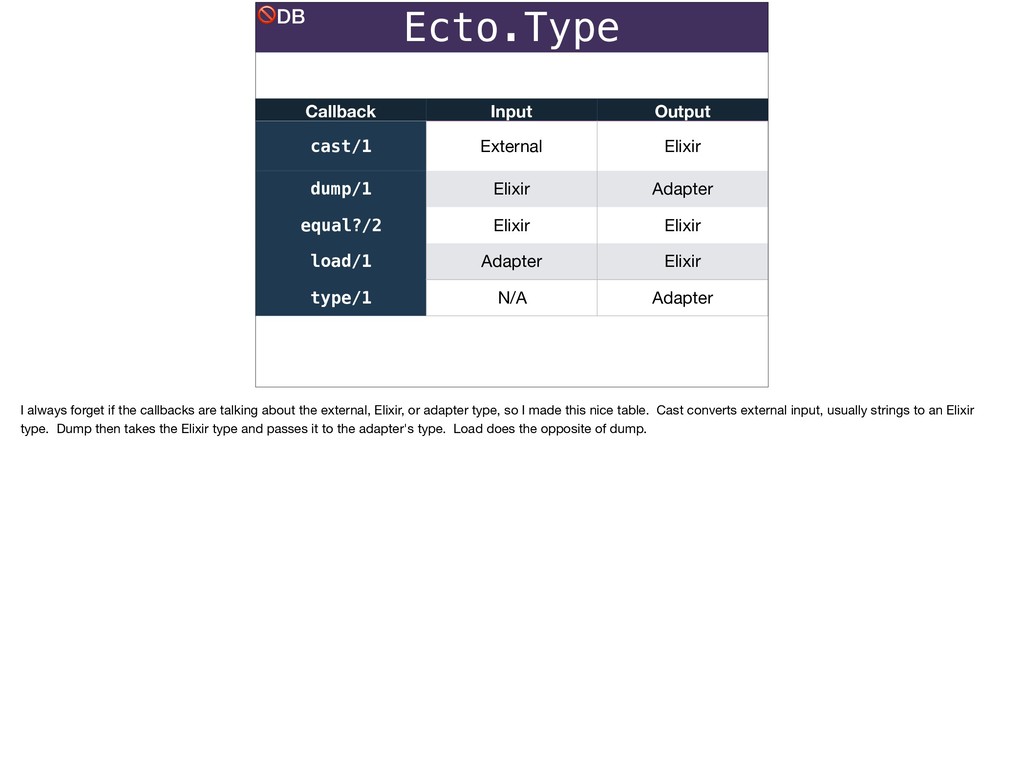
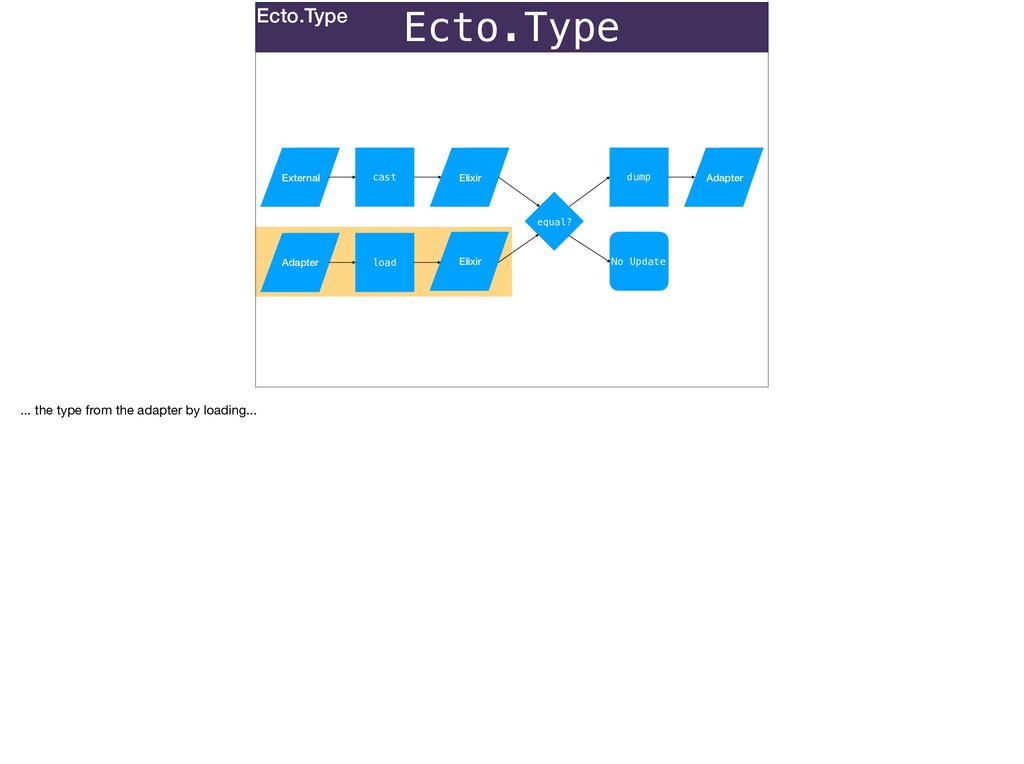
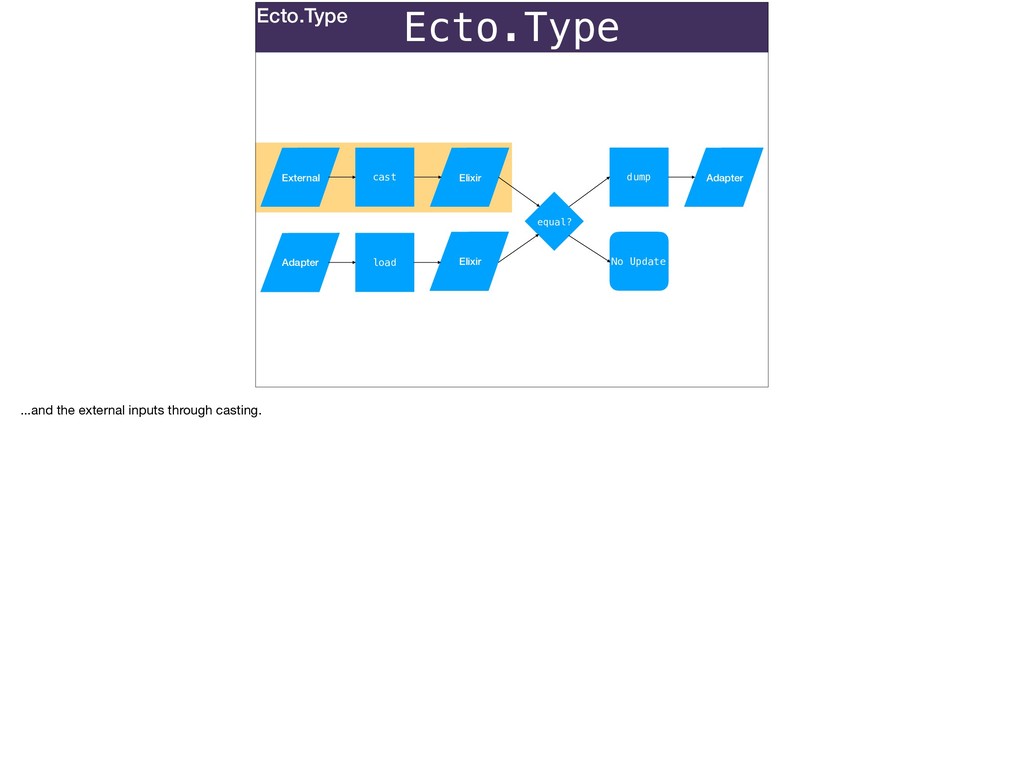
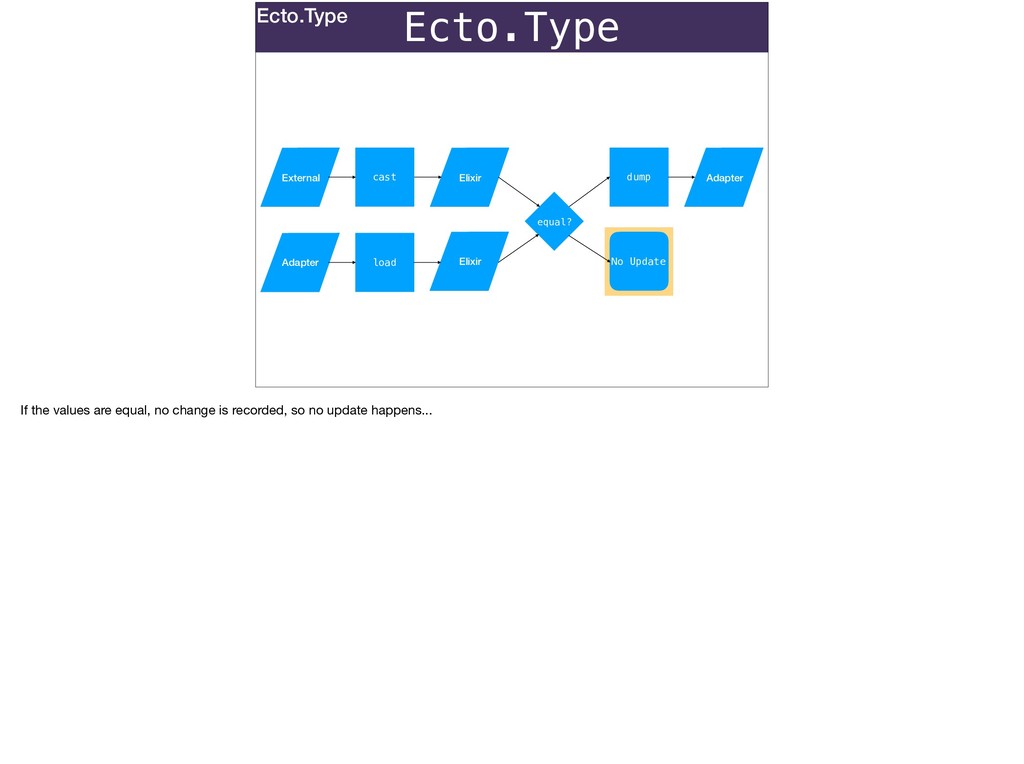
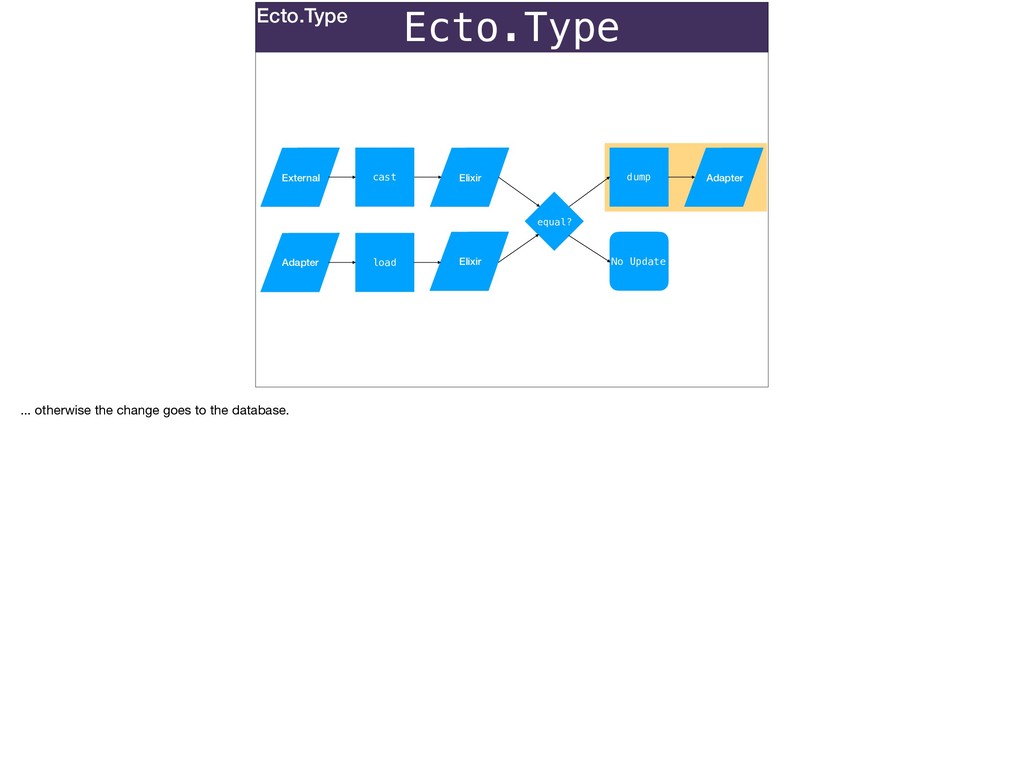
Without a database: Ecto.Types can be used to convert stringly-typed data from any source to native Elixir.
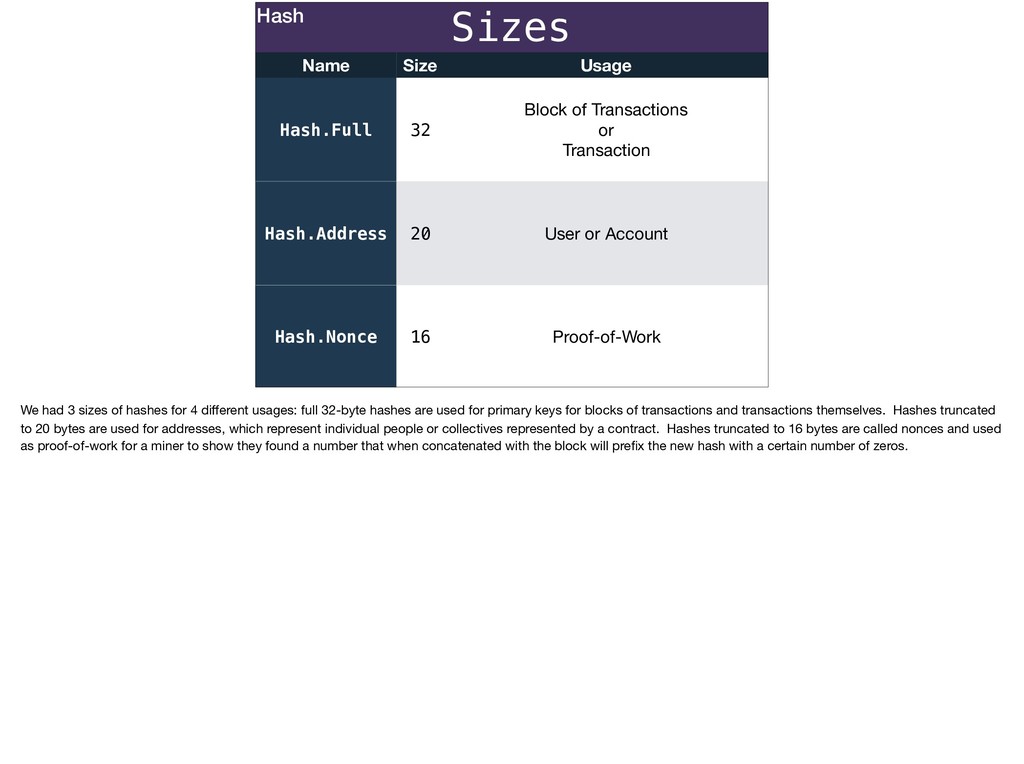
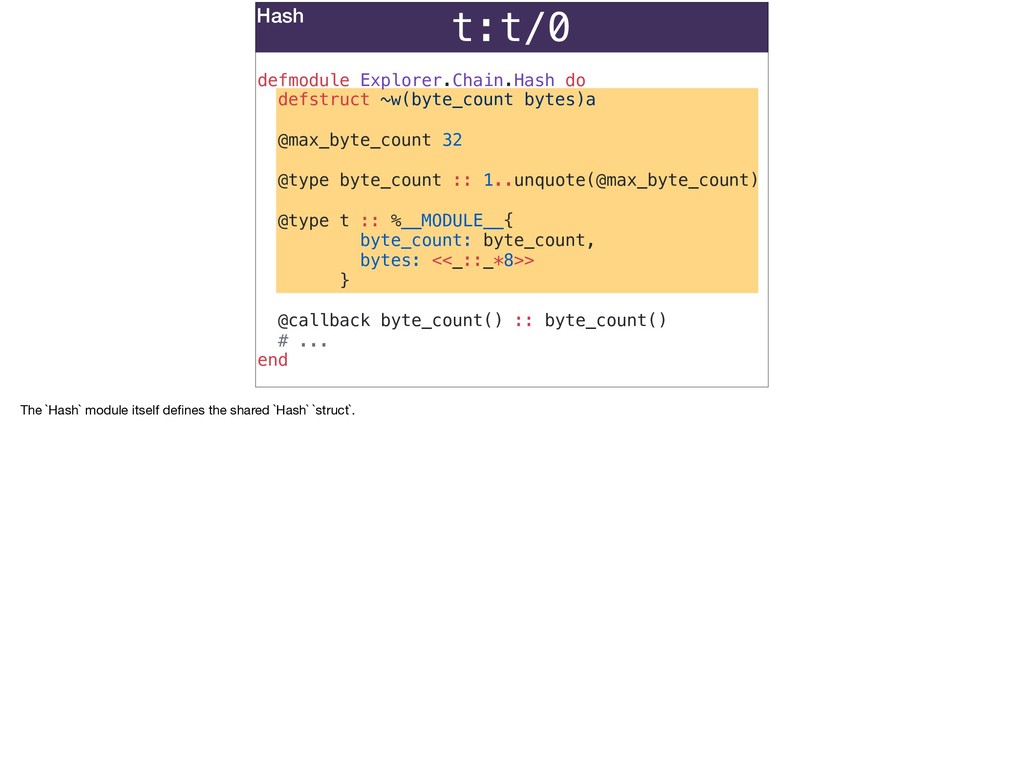
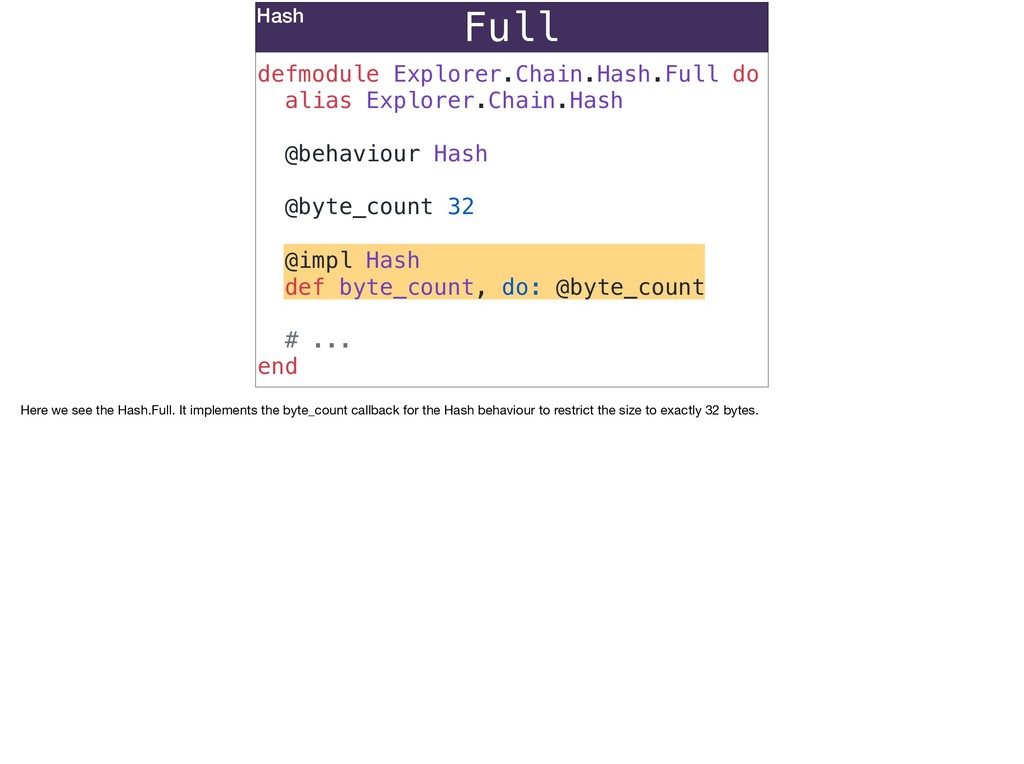
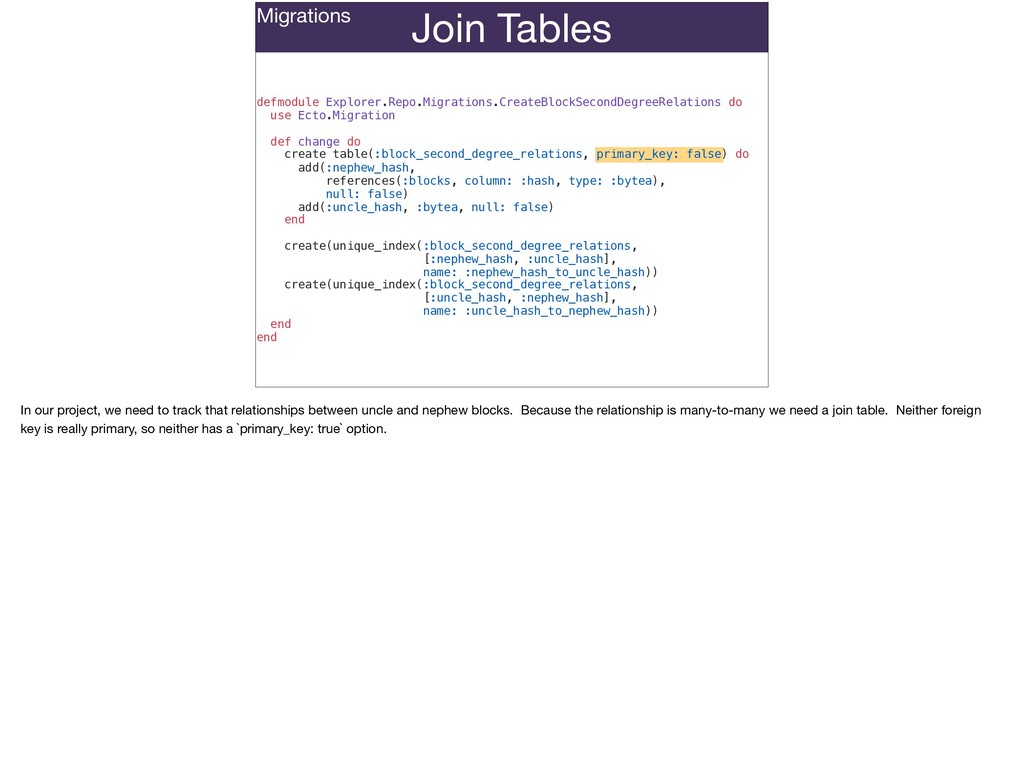
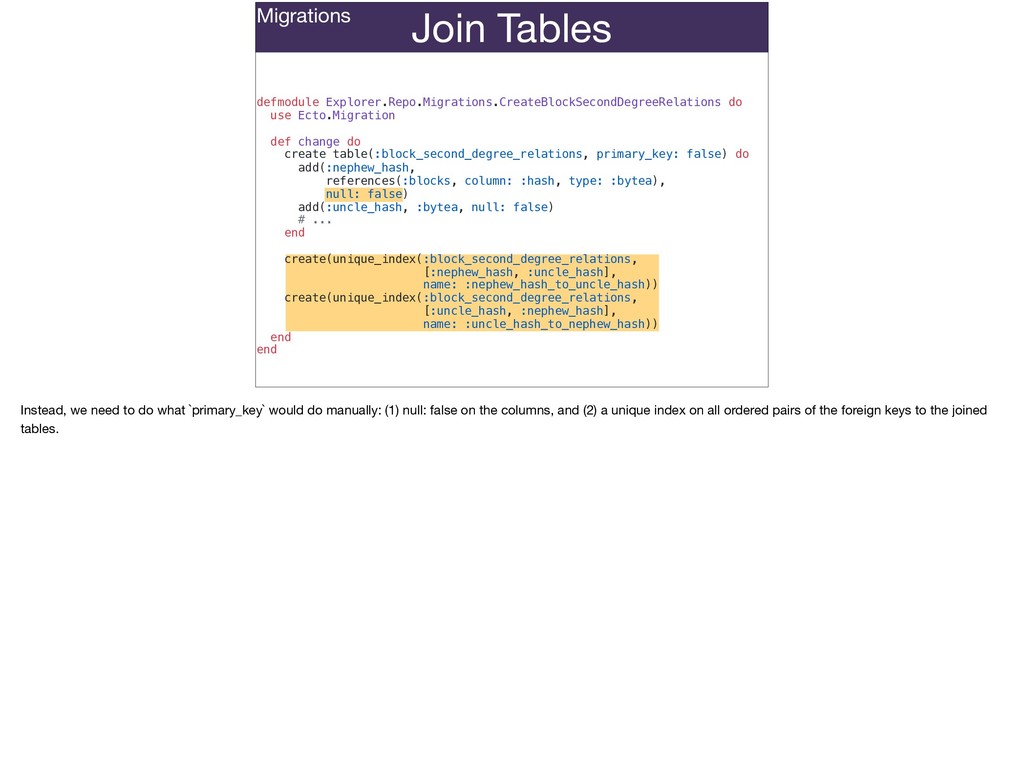
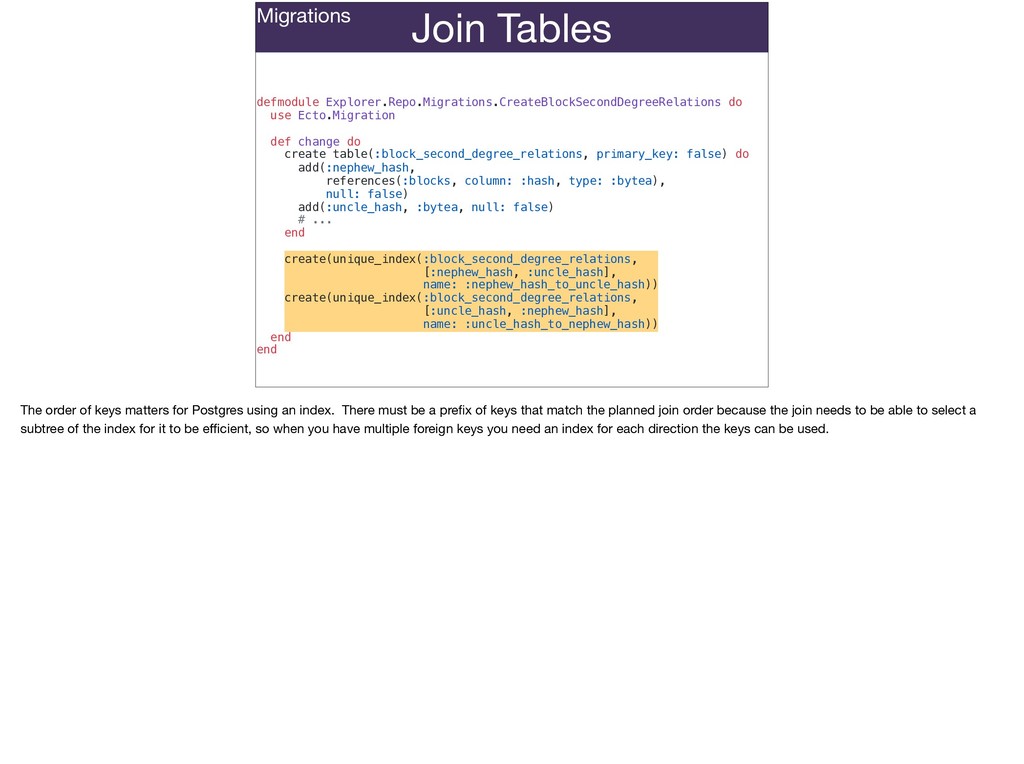
Ecto migrations can represent primary keys that aren't integers and more closely reflect unique identifiers in your domain; join tables that use composite primary keys that represent what’s unique about the join instead of an arbitrary id column; accurately represent the difference between time keeping in the database and in your Ecto schemas using different timestamp configs.
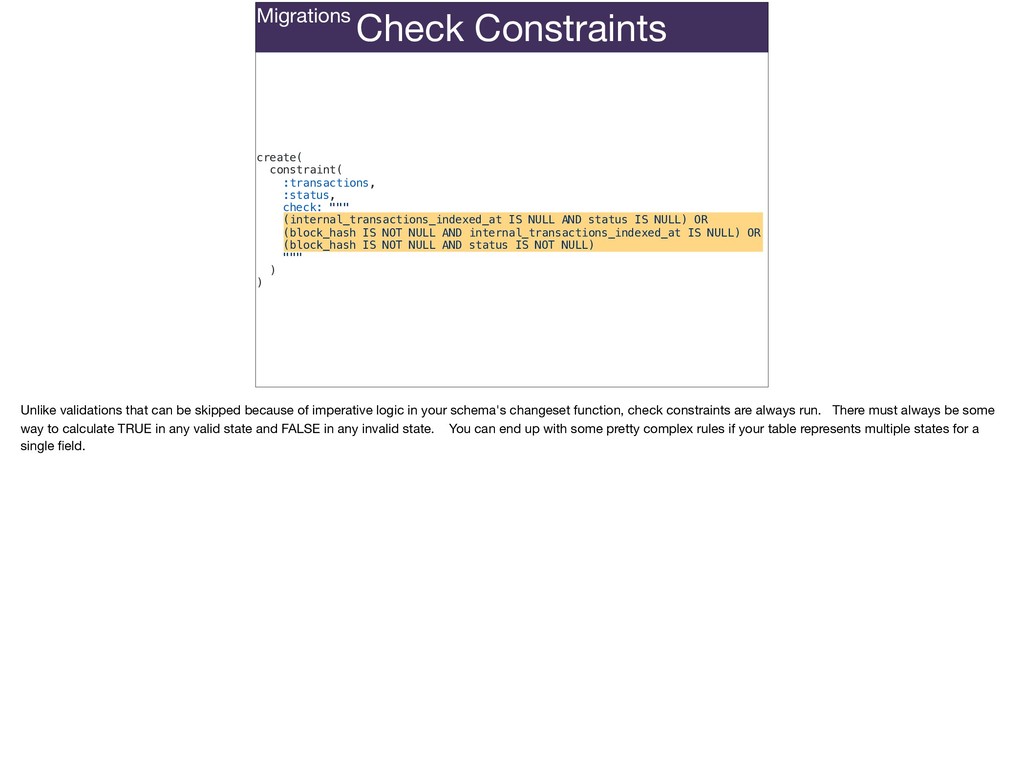
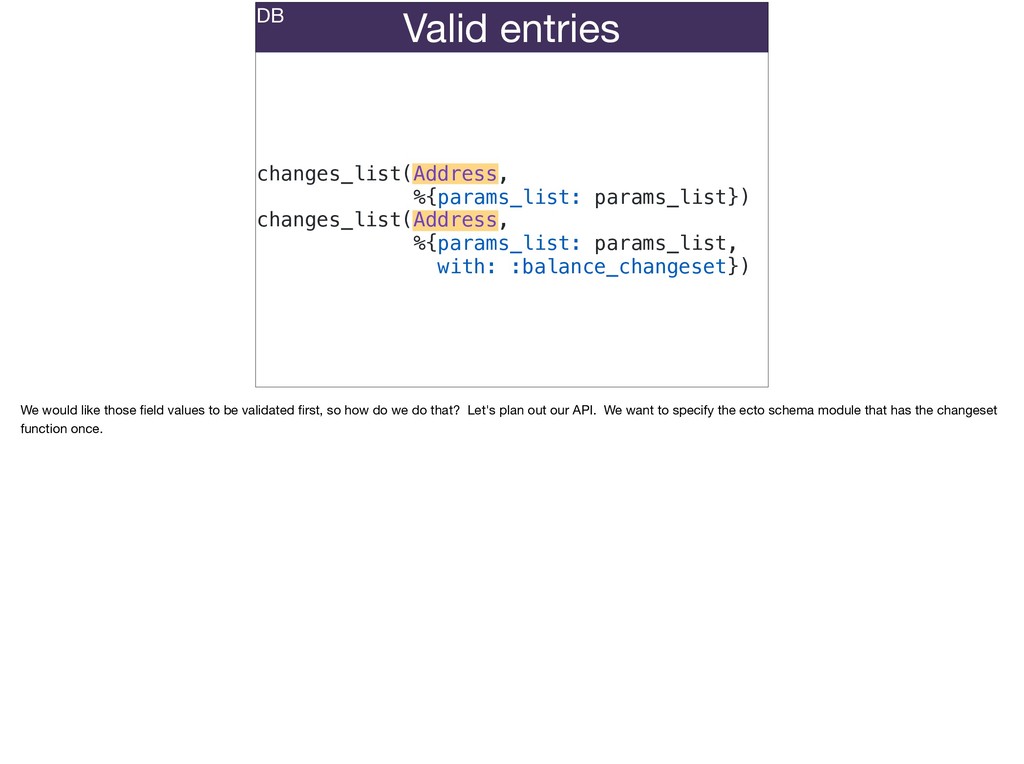
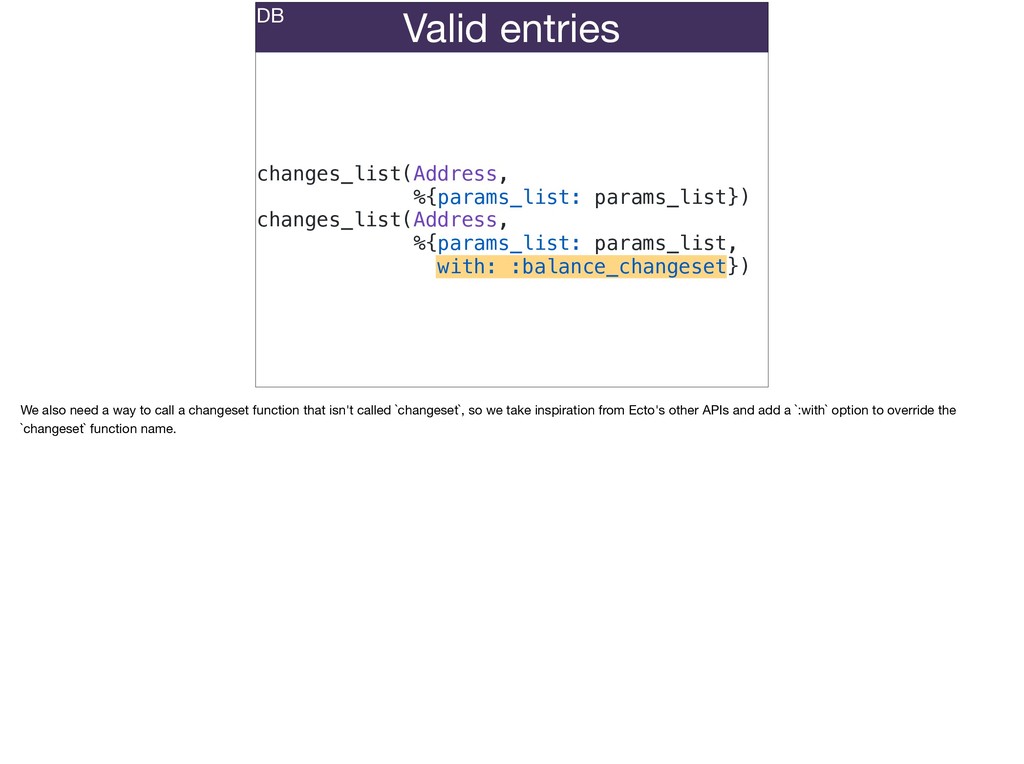
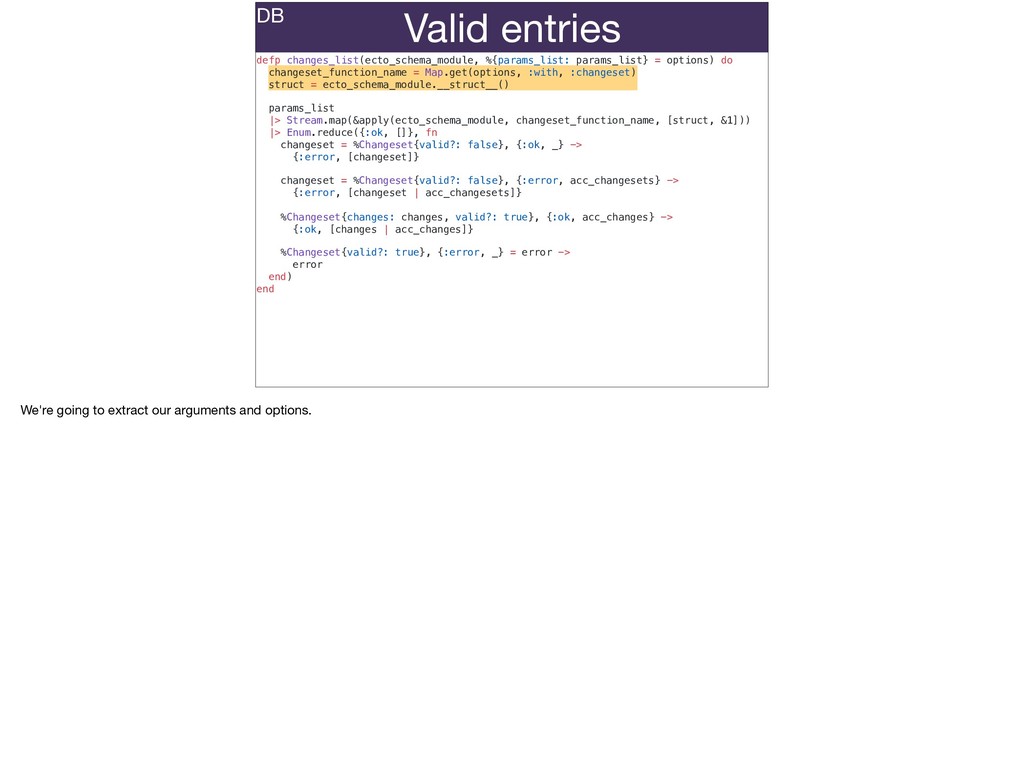
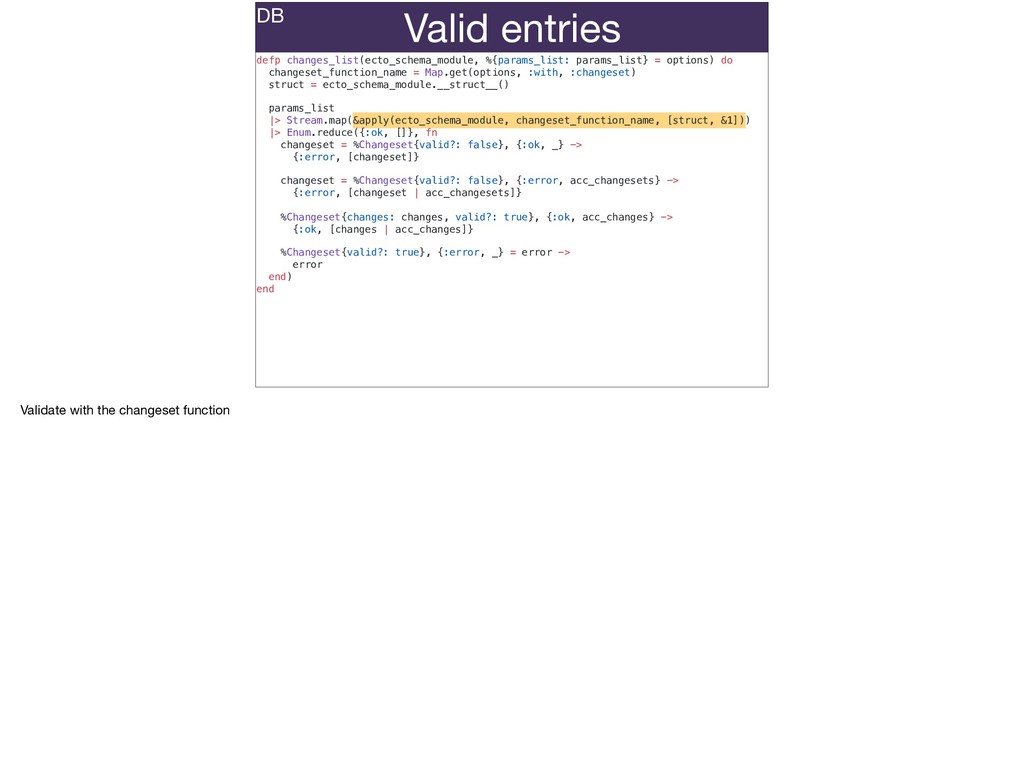
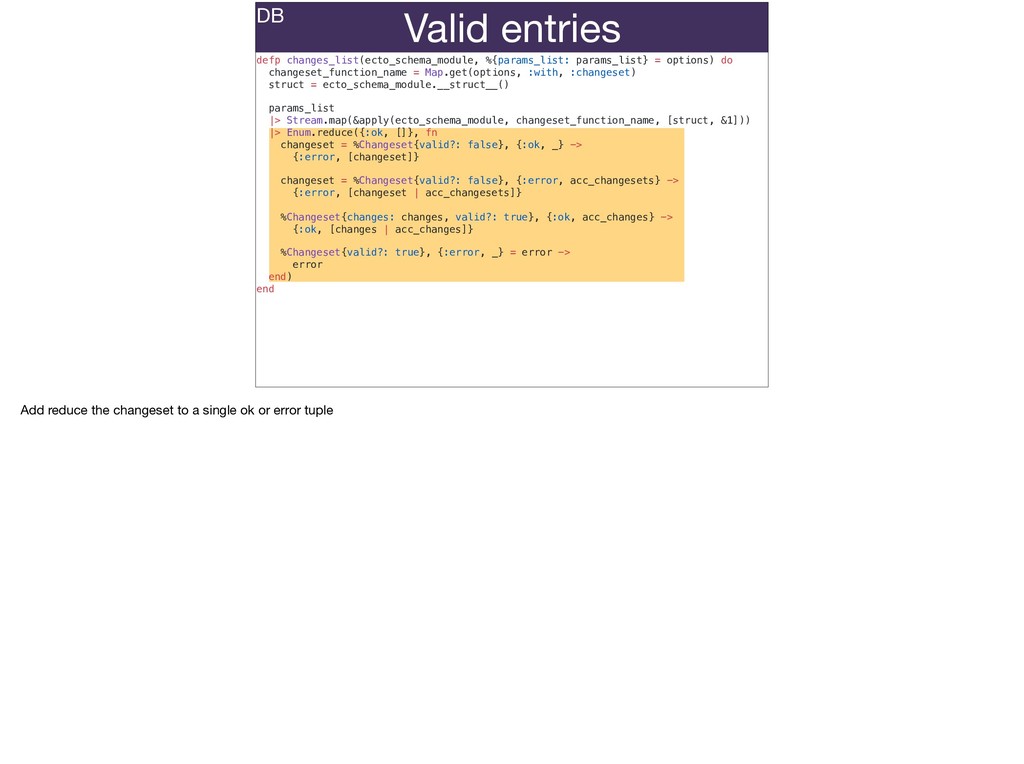
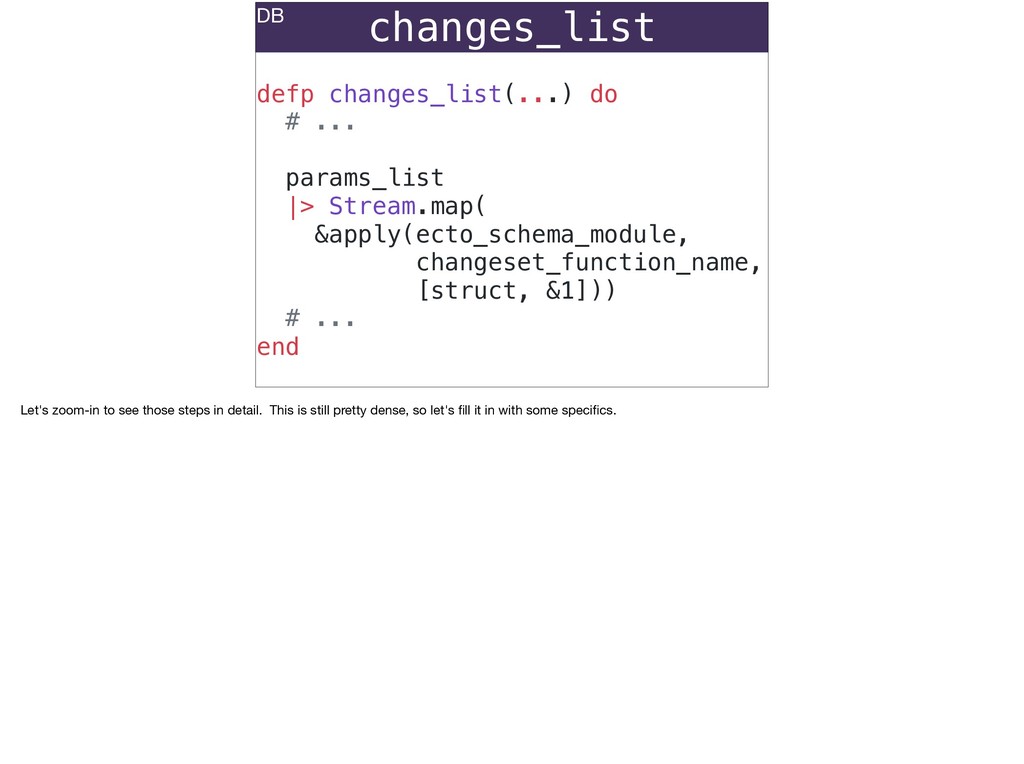
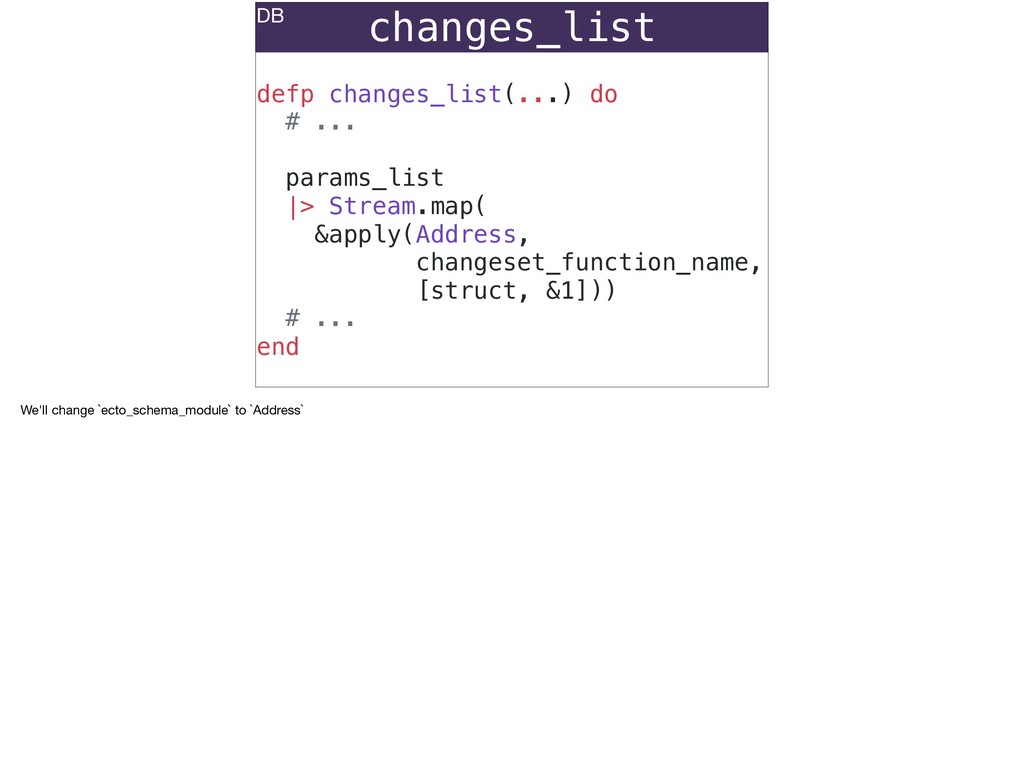
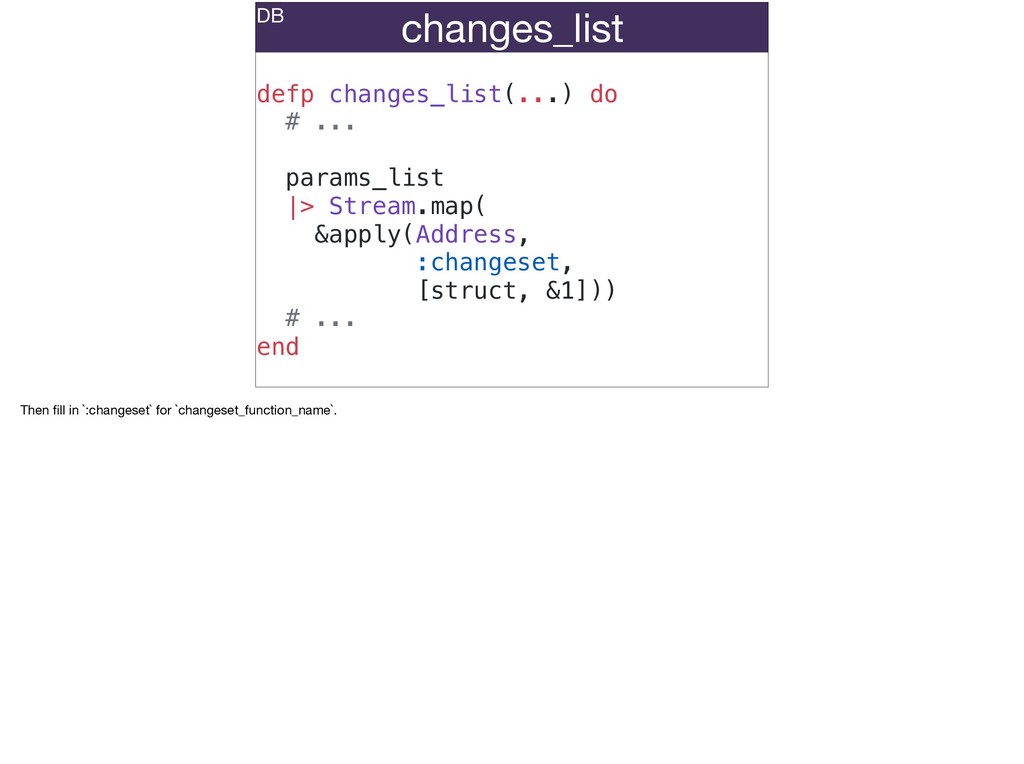
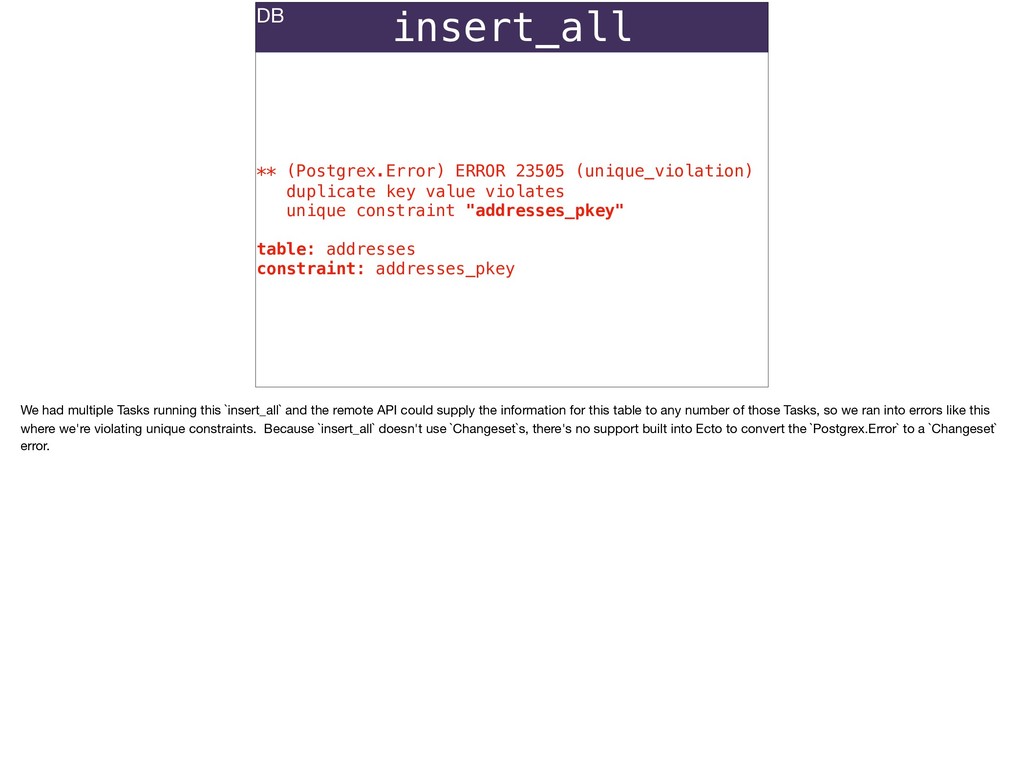
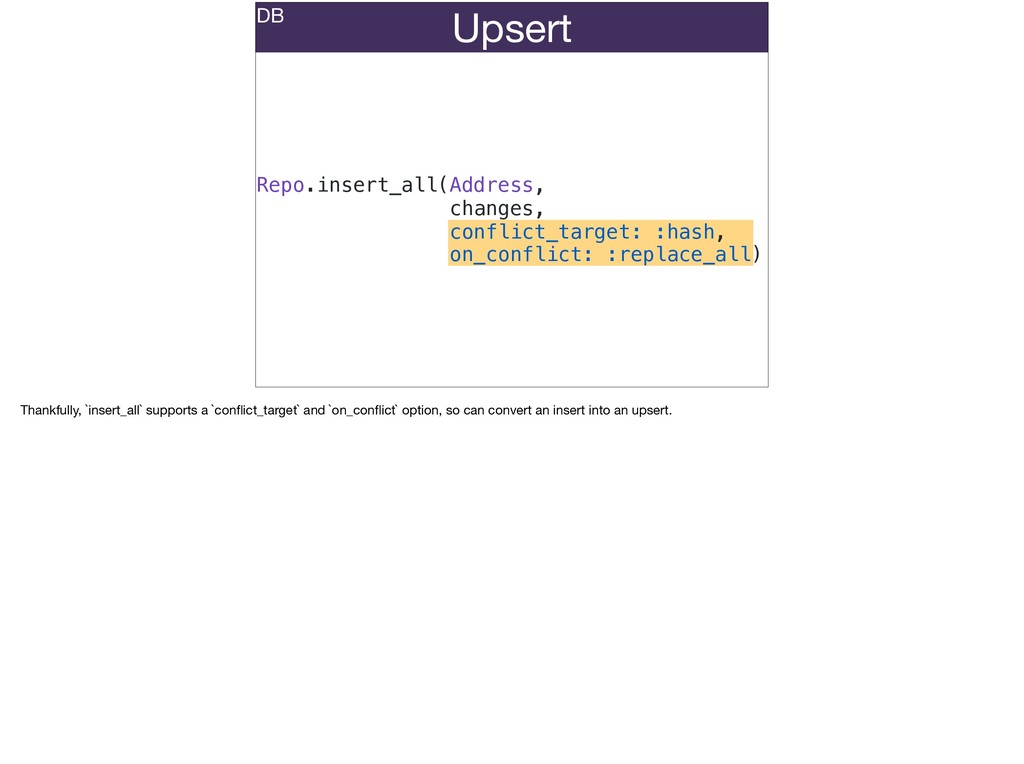
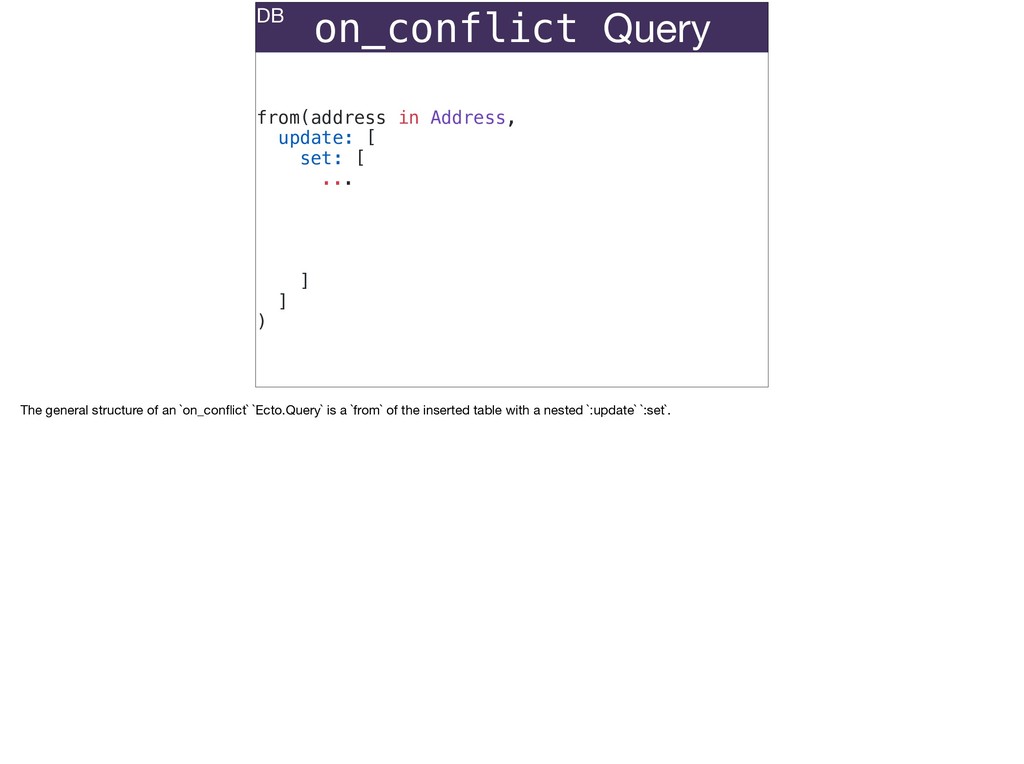
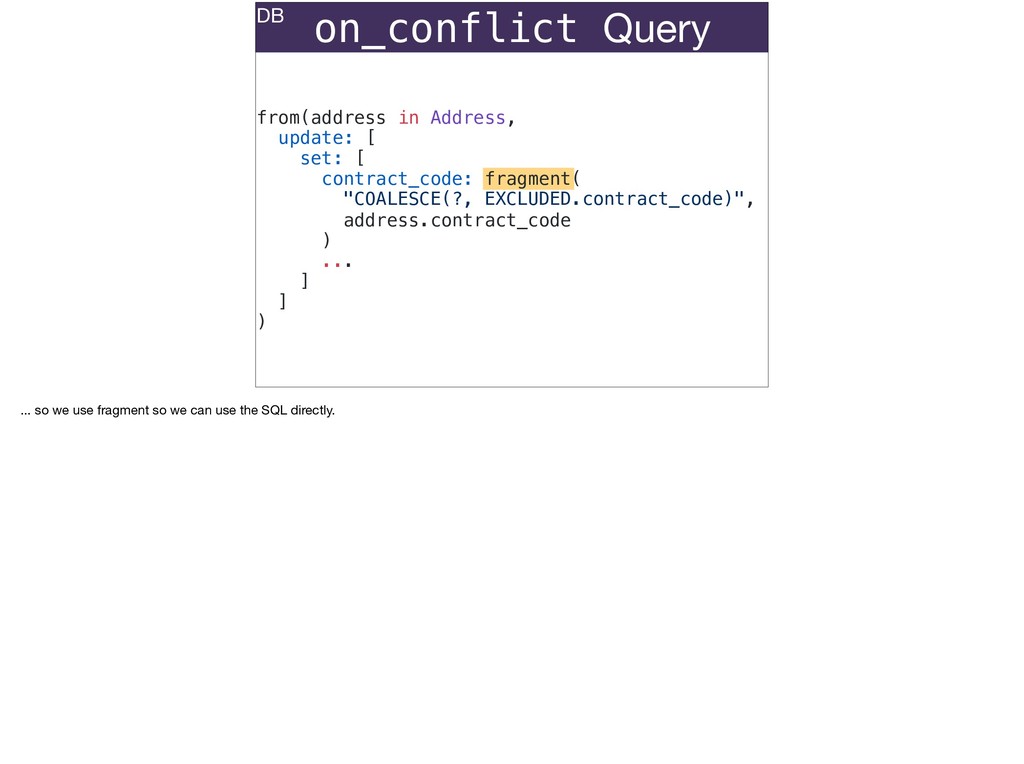
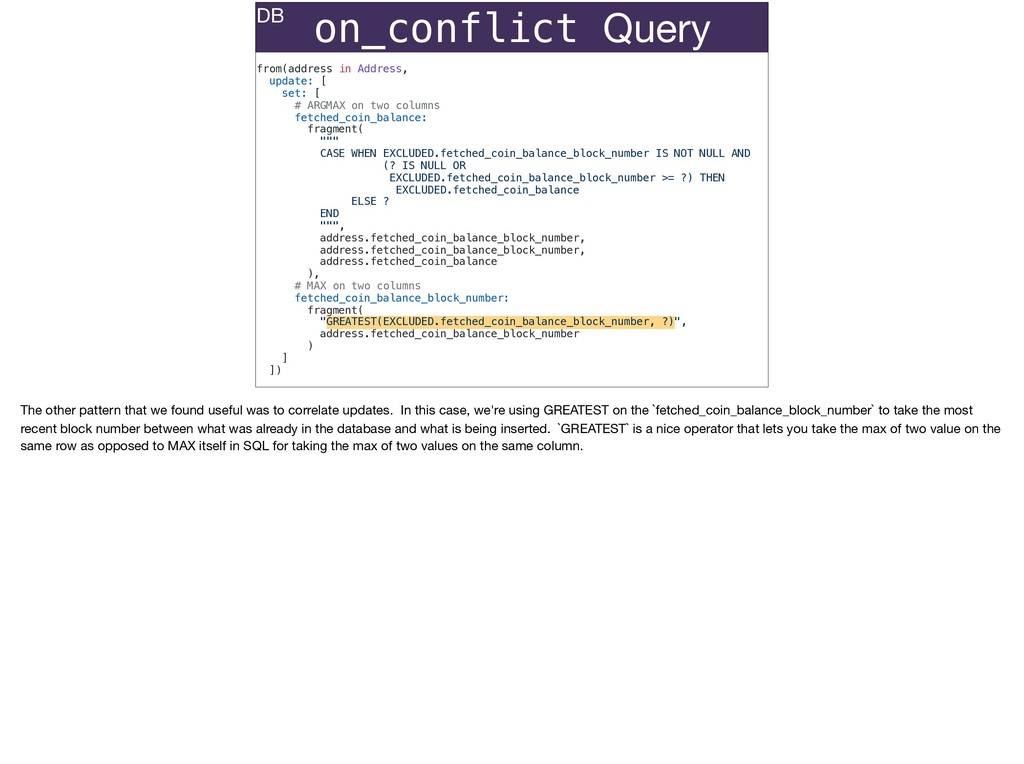
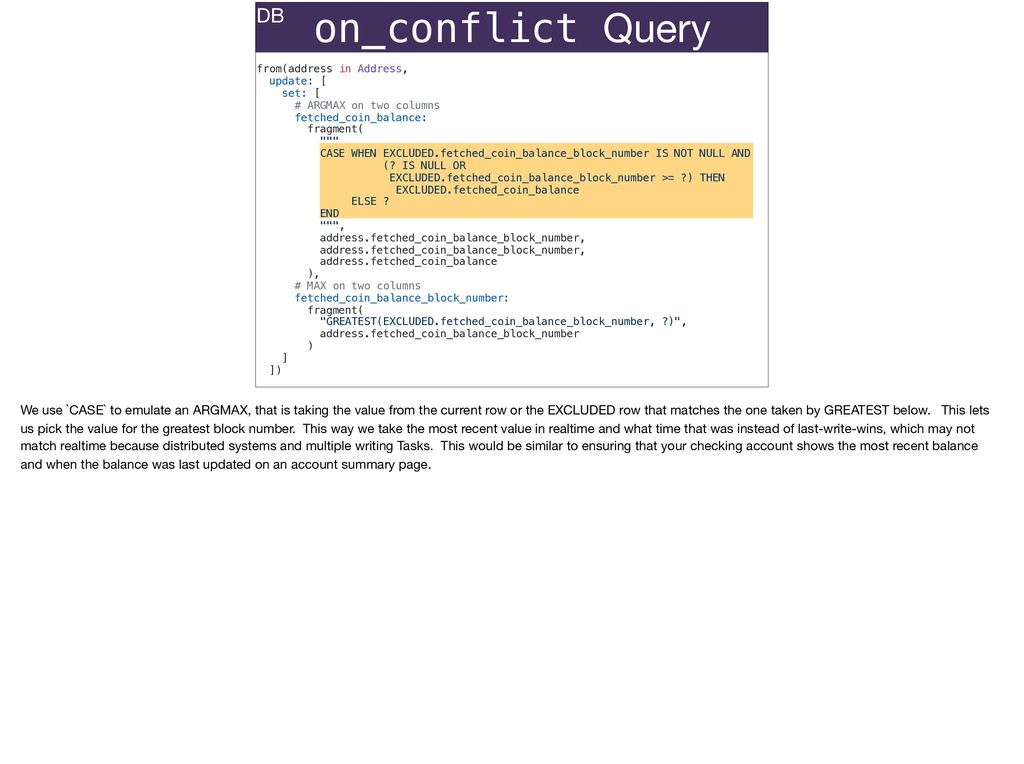
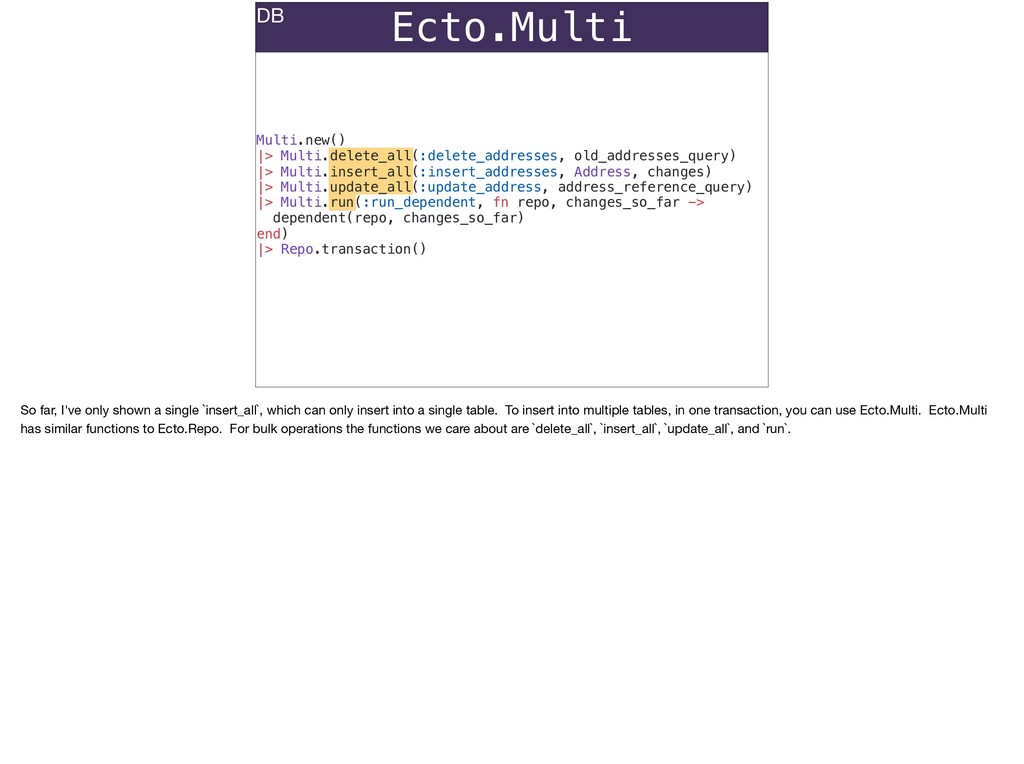
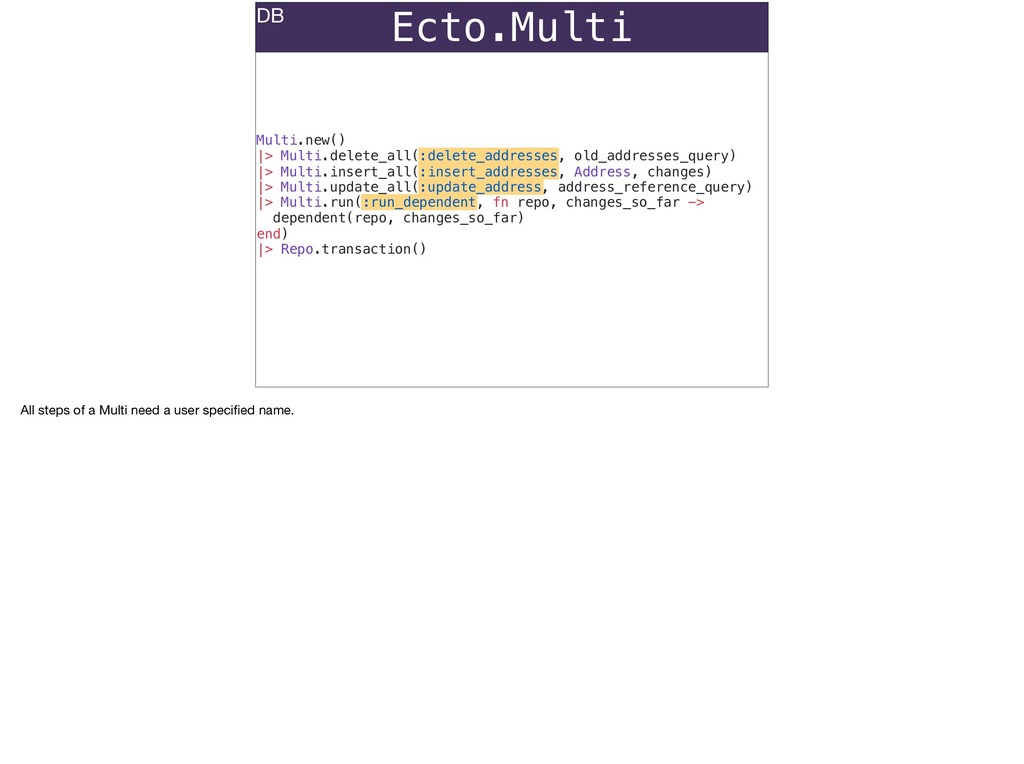
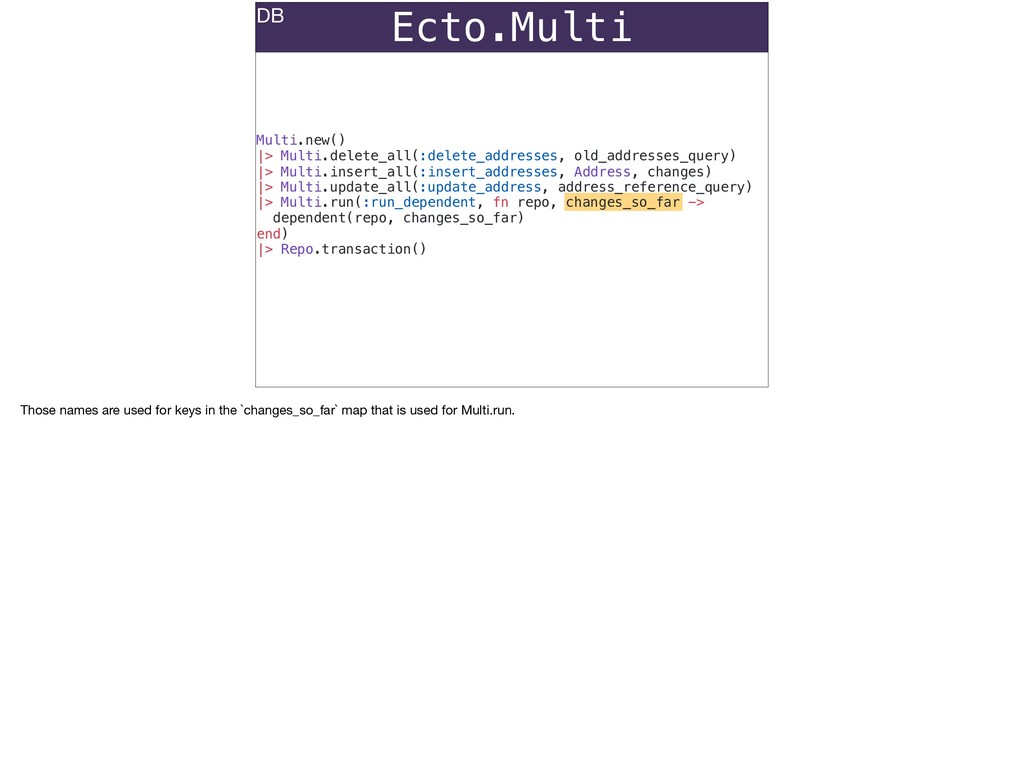
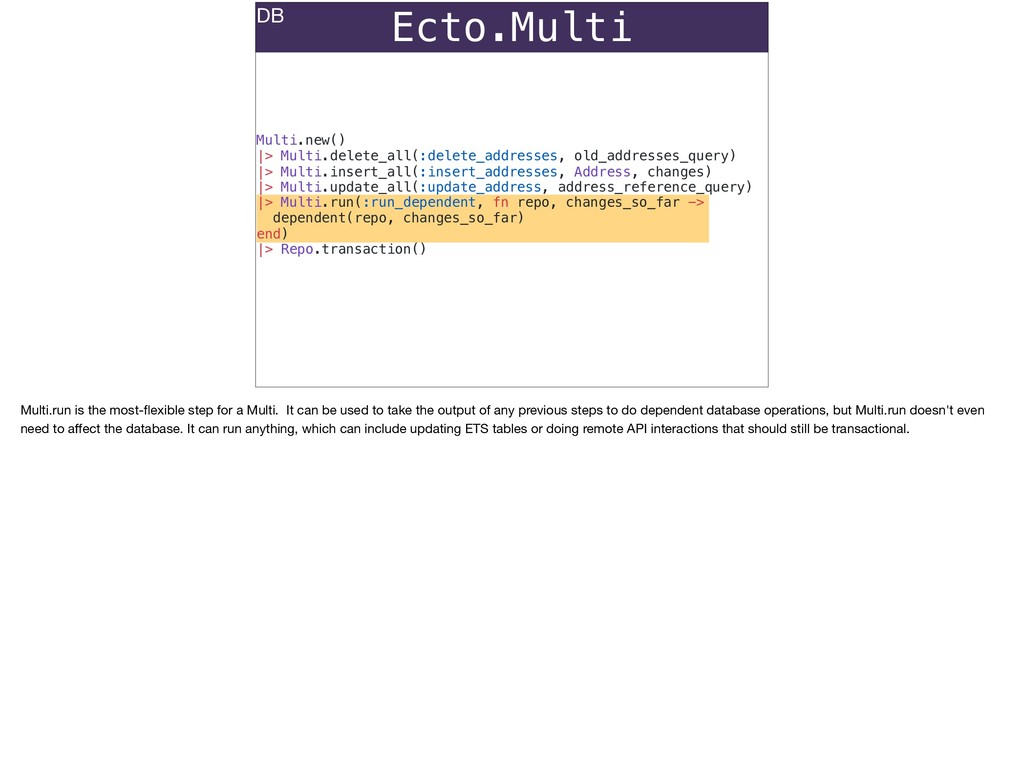
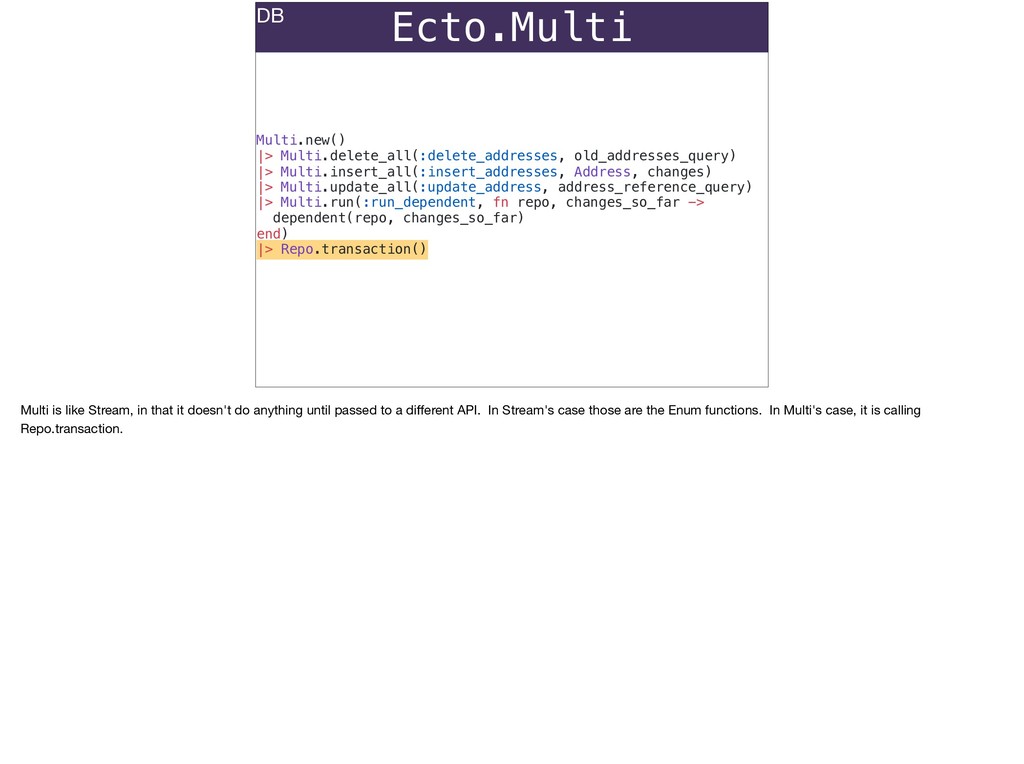
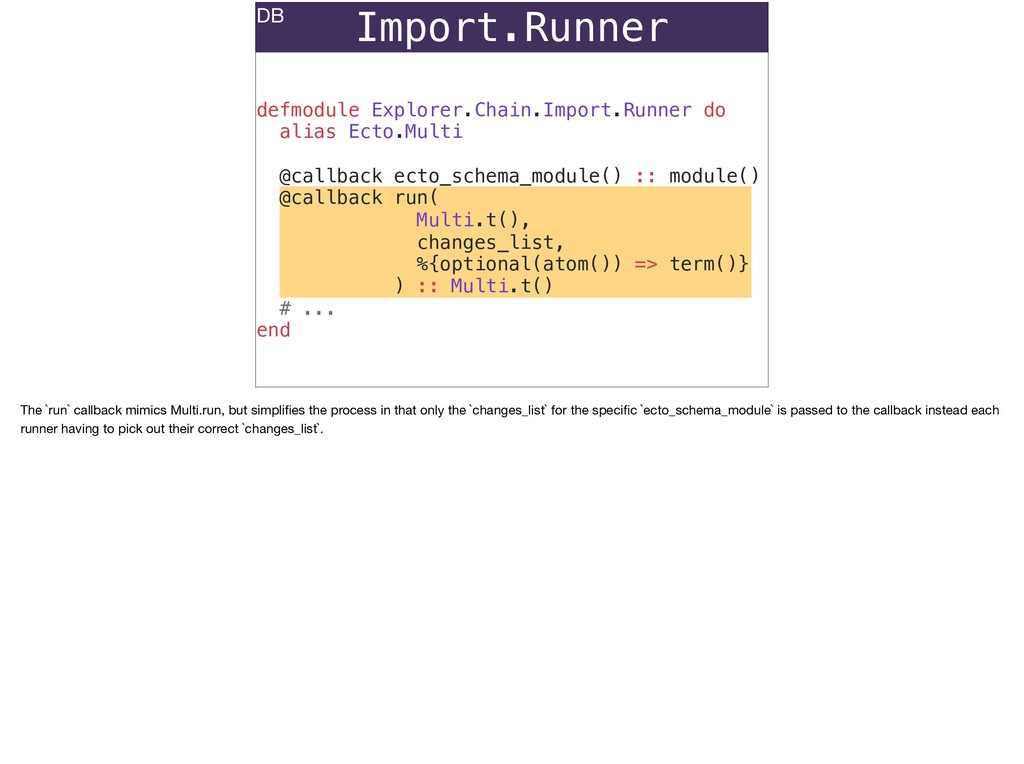
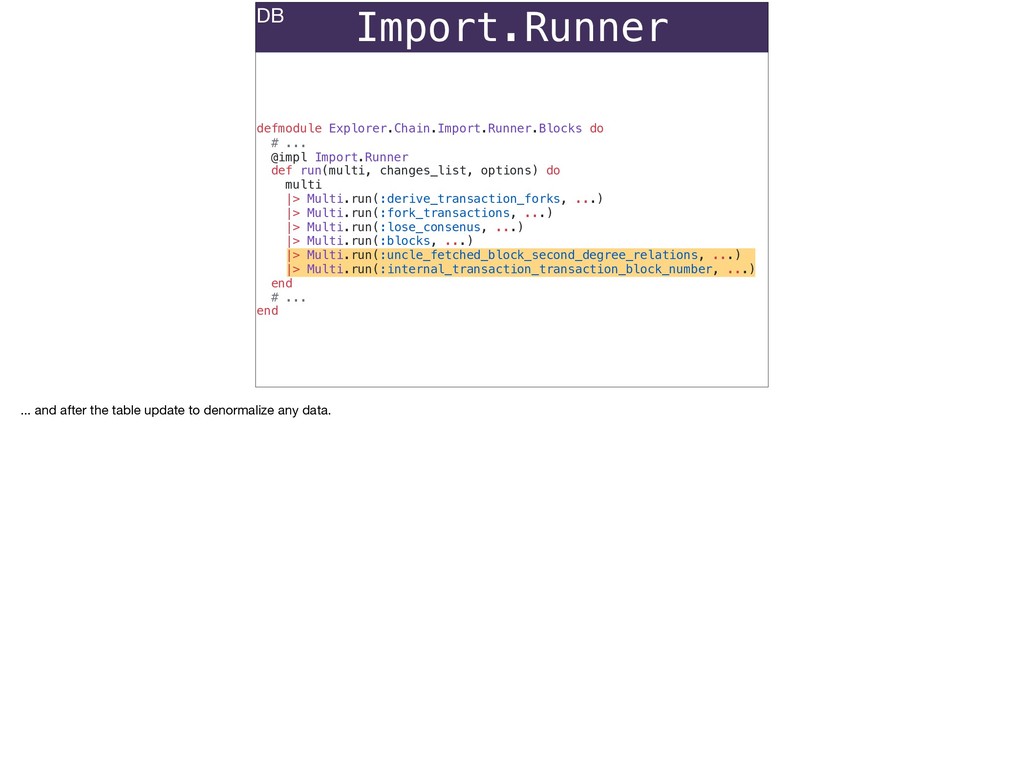
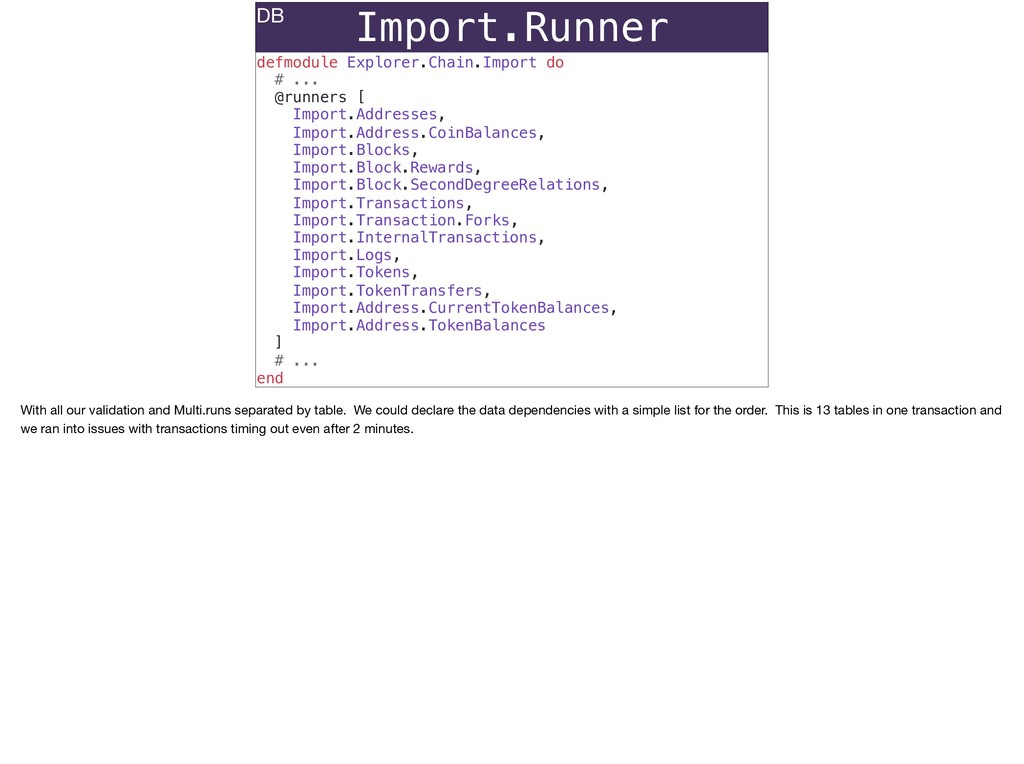
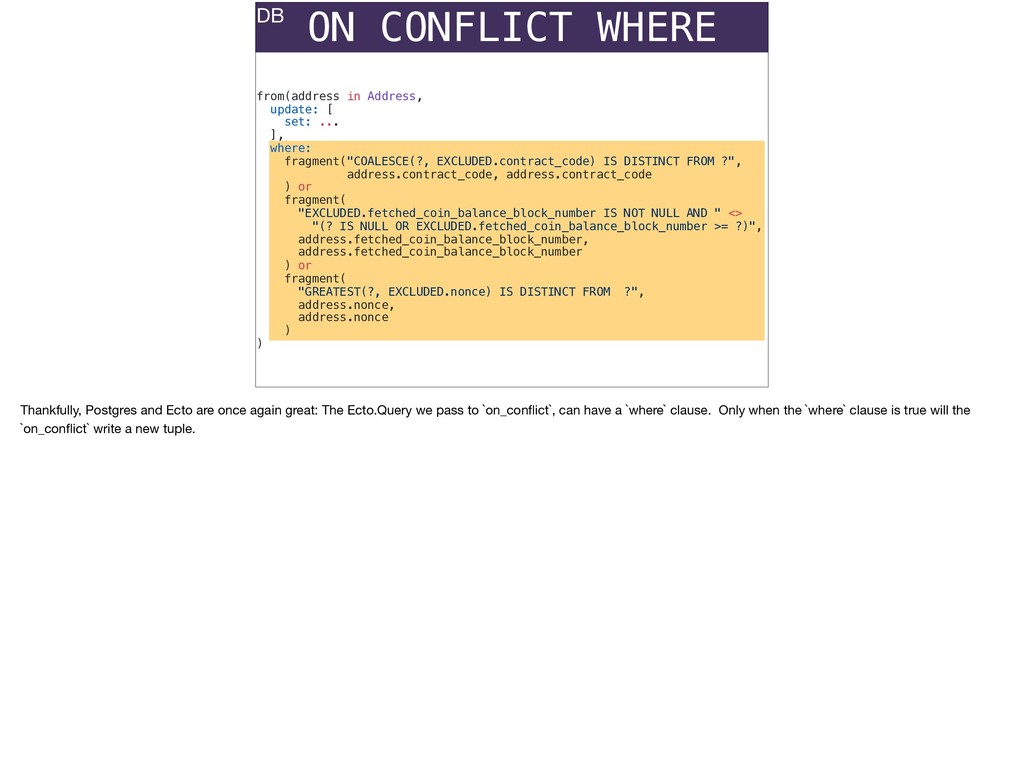
The full power of Postgres is available through Ecto constraints: unique constraints can be tuned to specific conditions; exclusion constraints make ranges and scheduling easy; and check constraints are even more general and allow modeling complete validation logic in the database. Constraints ensure that different code paths can't corrupt your data and violate business rules. Leaning on the database constraints is crucial when doing bulk operations in concurrent ETL pipelines, but Luke will show how you don't need to abandon changeset and validations just because insert_all doesn't support inserting changesets.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Ecto.Type Hash Callback Input Output cast/1 "0x[A-Fa-f0-6]*" binary dump/1 binary](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DB insert_all entries •%{name => value} •[{name, value}] Focusing on](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_70.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DB changes_list defp changes_list(...) do # ... |> Enum.reduce({:ok, []},](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_81.jpg){kind=link}
![DB changes_list defp changes_list(...) do # ... |> Enum.reduce({:ok, []},](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_82.jpg){kind=link}
![DB changes_list defp changes_list(...) do # ... |> Enum.reduce({:ok, []},](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_83.jpg){kind=link}
![DB changes_list defp changes_list(...) do # ... |> Enum.reduce({:ok, []},](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_84.jpg){kind=link}
![DB changes_list defp changes_list(...) do # ... |> Enum.reduce({:ok, []},](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_85.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DB Import.Stage defmodule Explorer.Chain.Import.Stage do @callback runners() :: [Runner.t(), ...]](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_119.jpg){kind=link}
![DB Import.Stage defmodule Explorer.Chain.Import.Stage do @callback runners() :: [Runner.t(), ...]](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_120.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact Personal Email [email protected] Twitter/ Slack @KronicDeth Meetup https://www.meetup.com/ Austin-Elixir](https://files.speakerdeck.com/presentations/abba10f0cfe64ecaad595b78e8c0adf2/slide_130.jpg){kind=link}