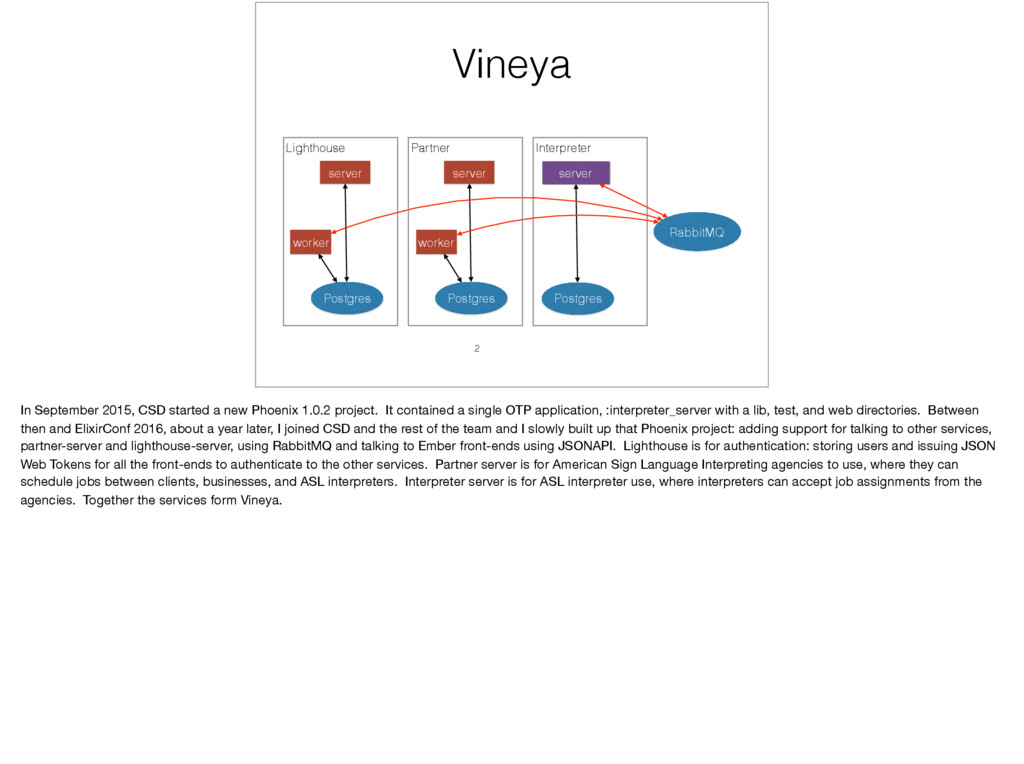
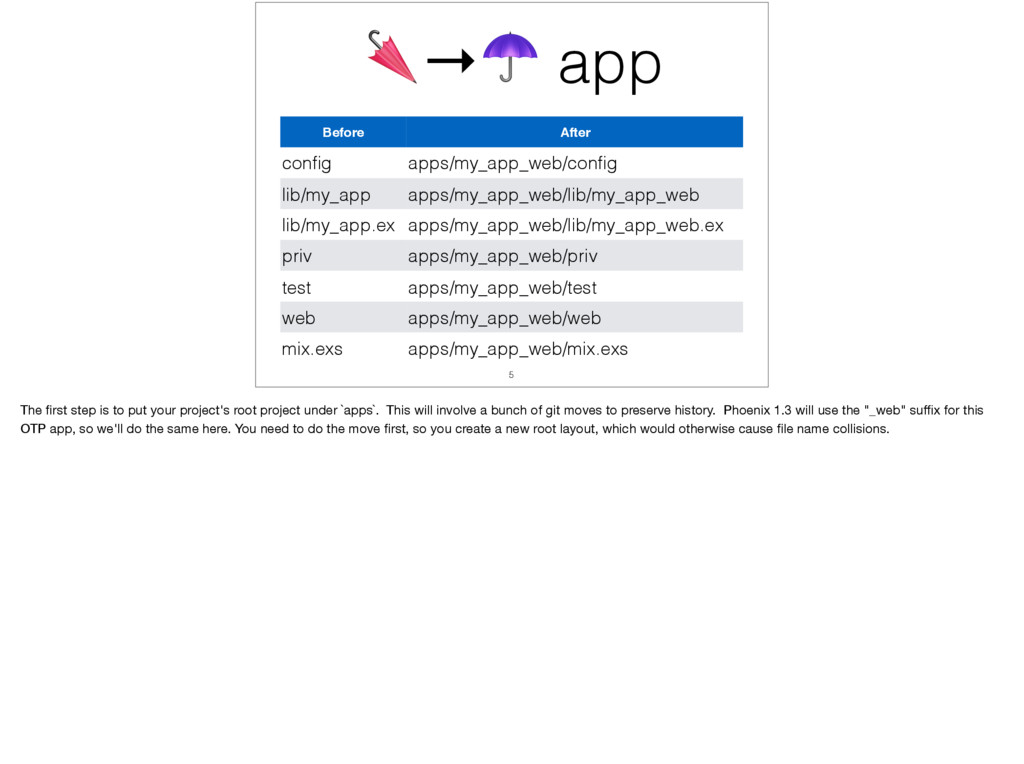
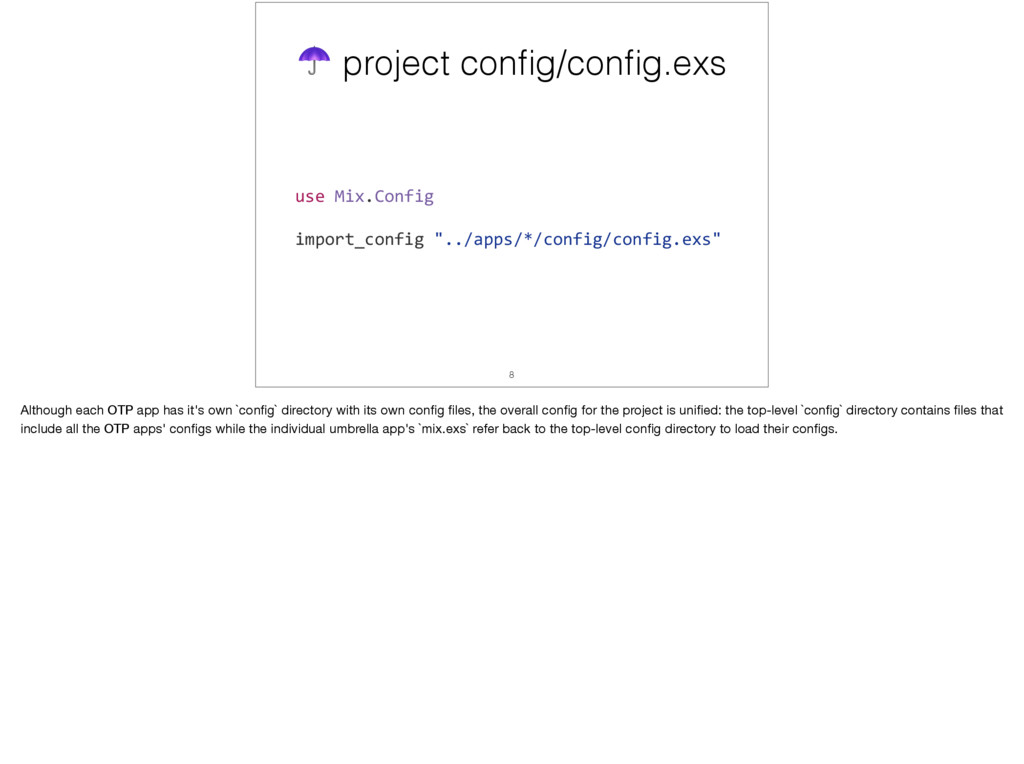
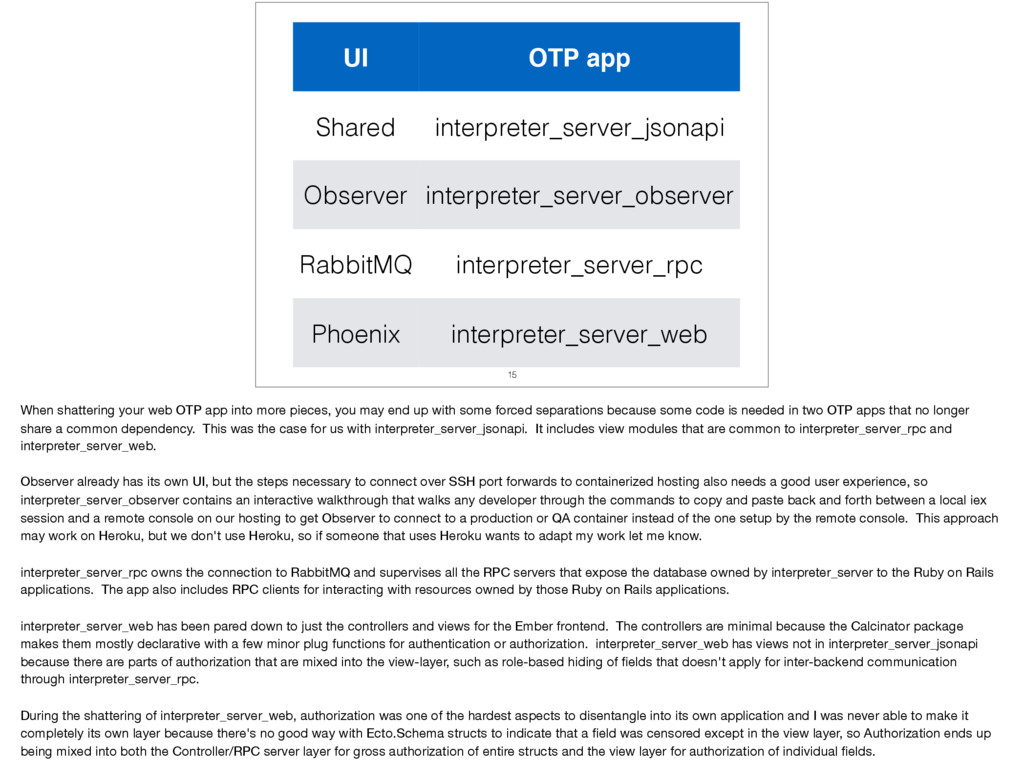
With the announcement of Phoenix 1.3 supporting umbrella projects at ElixirConf 2016, I was inspired to start early on converting our Phoenix 1.2 application to umbrella. Since the umbrella project templates weren't publicly available yet, I had to find the seams in our single, monolithic application where I could start breaking it into OTP apps for the umbrella project.
I'll cover the thought process of how I broke up the app and what guidelines I use now when adding new code as to whether add it to a pre-existing application or to make a new OTP application. I'll share the common code I was able to share between our RPC server and API controllers, which I believe is a good behaviour for resource module in Phoenix 1.3.
![Shattering your application into an umbrella project Luke Imhoff [email protected]](https://files.speakerdeck.com/presentations/877388db05f44d53a923d8b4738fb516/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
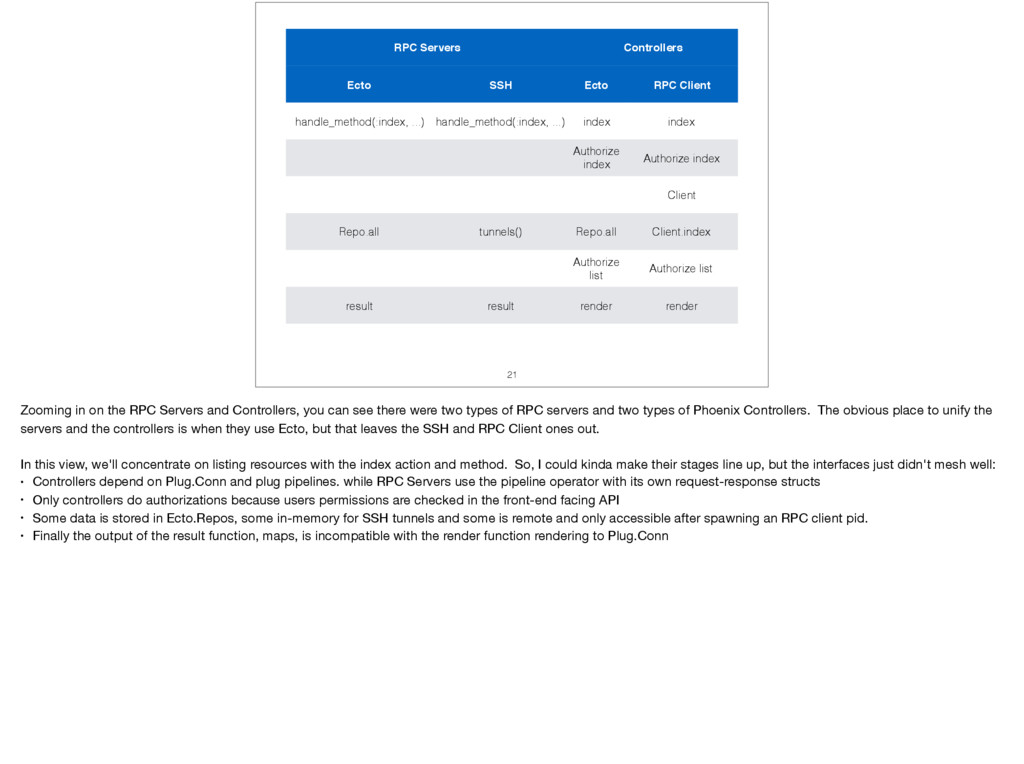{kind=link}
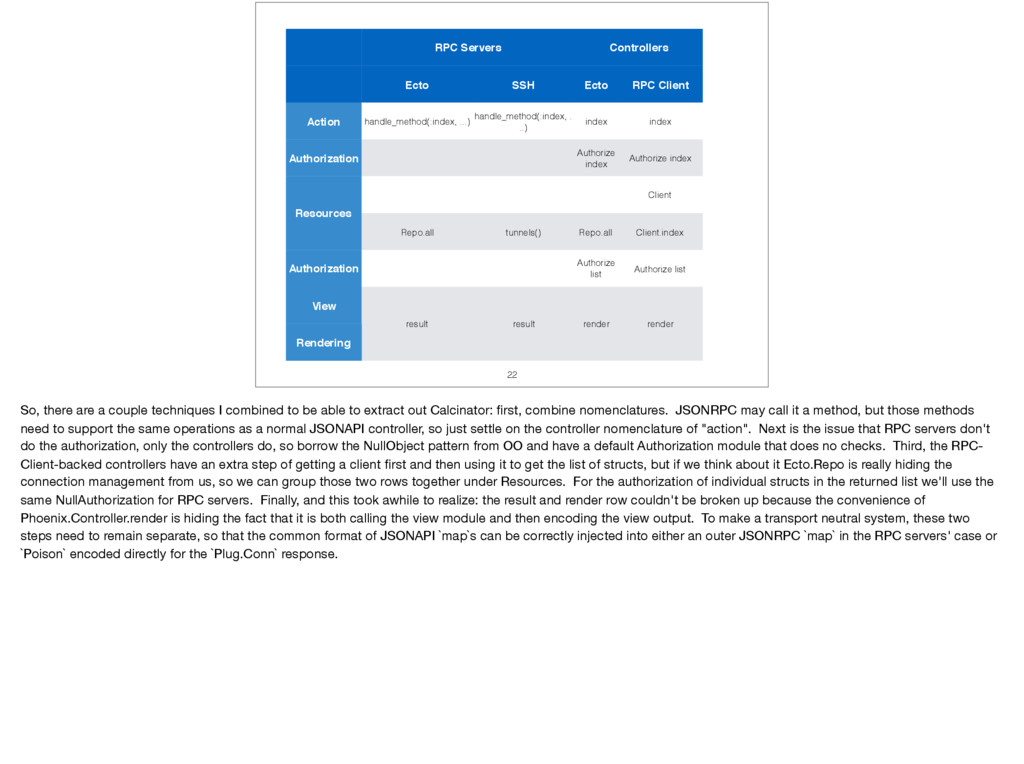{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? 27 Luke Imhoff [email protected] Github: @KronicDeth Twitter: @KronicDeth Elixir](https://files.speakerdeck.com/presentations/877388db05f44d53a923d8b4738fb516/slide_26.jpg){kind=link}