Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
"Vertical AI製品の品質管理" / 【MNTSQxUbie】Vertical AI ...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Kazuki Inamura
August 10, 2021
Programming
2.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
"Vertical AI製品の品質管理" / 【MNTSQxUbie】Vertical AI Startup Meetup
https://connpass.com/event/219275/
Kazuki Inamura
August 10, 2021
More Decks by Kazuki Inamura
See All by Kazuki Inamura
Harness Engineering and Al Agent
kzinmr
3
1.8k
音声言語モデル手法に関する発表の紹介
kzinmr
0
210
Other Decks in Programming
See All in Programming
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
170
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
700
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
0
110
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
4.2k
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
330
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
220
フィードバックで育てるAI開発
kotaminato
1
110
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
1
180
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
3
380
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
380
初めてのKubernetes 本番運用でハマった話
oku053
0
120
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
200
Featured
See All Featured
WENDY [Excerpt]
tessaabrams
11
38k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Building Adaptive Systems
keathley
44
3.1k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Building Applications with DynamoDB
mza
96
7.1k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Visualization
eitanlees
152
17k
4 Signs Your Business is Dying
shpigford
187
22k
Transcript
Vertical AI製品の品質管理 MNTSQ 株式会社 稲村和樹
自己紹介 - 稲村和樹 ( Twitter: @kzinmr ) - 自然言語処理の仕事をこれまでやらせてもらってきました -
テキストデータの情報抽出や特徴づけが得意 - 前職では自然言語処理の PoC 開発が主業務 - タスク定義と教師データの作成からやる cold-start 設定がほとんど - 構文解析結果や知識処理の組み合わせで勝負することも多かった - 関心推移 : 新手法 → 技術モジュール → MLOps とデータエンジニアリング - 先月会社名義で概説記事を寄稿 : https://ainow.ai/2021/07/21/257004/
会社・製品紹介 MNTSQ( モンテスキュー ) 株式会社 • 契約書管理システム MNTSQ • アップロードした契約書に解析が走り、検索や調査や分析を助ける
◦ 契約業務のデータワークフロー全体を助けるように現在進行系で進化中 • AI 製品としての特徴 : ◦ 機械学習の分類モデルや抽出モデルが ” 多種類 ” 走っている ◦ 業界横断で企業機能(法務)を支援するエンタープライズ SaaS ▪ 共通軸:契約に関連する法的知識 ▪ 変化軸:各業界別・企業規模別で、データ性質や機能要求にずれが存在 ◦ モデル仕様の背後にある専門知識が深い
前提: Vertical vs Horizontal = ドメイン応用 vs 汎用技術 金融 保険
医療 法律 製薬 ︙ 法務 財務 税務 経理 人事 労務 ︙ DB 計算資源 監視 小売 製造業 実験管理 AutoML アノテーション … … セキュリティ vertical horizontal
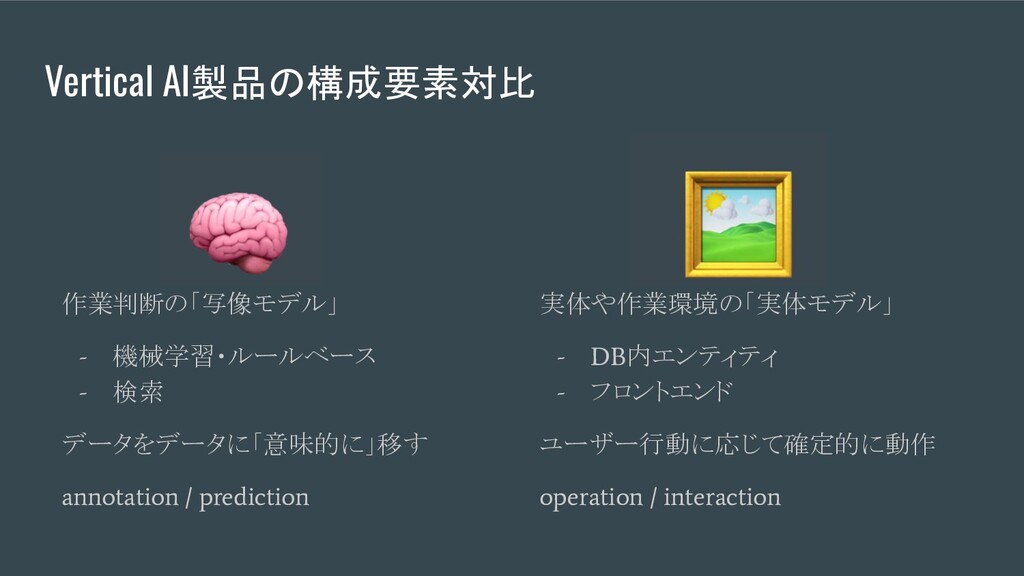
Vertical AI製品の構成要素対比 作業判断の「写像モデル」 - 機械学習・ルールベース - 検索 データをデータに「意味的に」移す annotation /
prediction 実体や作業環境の「実体モデル」 - DB 内エンティティ - フロントエンド ユーザー行動に応じて確定的に動作 operation / interaction
Vertical AI製品の構成要素対比 知識 / 内容的な動作側面 - 法概念 - 専門用語 /
タクソノミー ユーザーの認識・知識に訴求 annotation / prediction 業務 / 箱的な動作側面 - 契約書ライフサイクル - 実作業フロー ユーザーの作業行動に訴求 operation / interaction
Vertical AI開発における「正しさ」 • 使い勝手の良いものを作る : ユーザーファーストの正しさ • ユーザーに利するものを作る : コスト
/ リスク減・アップセルの正しさ これらを支える要素として : • 判断が信頼できるものを作る : 判断内容の正しさ ◦ 一般的な知識として正しい ▪ 「一般的な法概念としての整理は〇〇」 ◦ ビジネスロジックの知識として正しい ▪ 「当社における呼称・略称は〇〇」 ◦ 信頼性の高いコンテンツ:判断の難しいケース ▪ 「〇〇監修のコンテンツ」
箱の外と内を行き来する開発 おそらく実践するのが最も難しいポイント 製品に対する内と外の品質要求・正しさの目線が求められる - 箱の内部🧠 - 内容検証と品質管理に重き - ドメインの専門家や実務家的な目線 -
箱の外部📈 - コスト調査と機能提案に重き - ロジック的・ビジネス的な目線 👈 今日はこちらの品質保証に焦点 (従来型のソフトウェア開発では注目されて こなかった側面だと理解している)
タスクとデータ品質 1. データ整備の目標:タスクを正しく解けるデータ品質を達成すること🧠 ◦ データ量・データ多様性の十分性(カバレッジ) ◦ データ分布の平衡性(過学習防止) ◦ ラベルの正しさ(エラー率、一貫性)、等の品質要求 2.
製品開発の ROI を直に左右するのはタスク定義📈 ◦ タスクの初期定義 : 専門知識がリード ▪ アノテーター間に判断ぶれが生じにくい基準(ガイドライン)の吟味が重要 ◦ タスクの再定義・優先順位調整のイタレーション : 業務・製品仕様に適応 ▪ ただし方針転換のコストは大きいので初期定義が適切なことが重要 ◦ どのタスクを解くかの ROI はもちろん重要(ただし今日の主テーマではない) ▪ 参考 . 弊社安野の記事 [1]: Lean AI 開発論 : コードを書く前に機械学習プロジェクトを評価する方法 [1] https://note.com/takahiroanno/n/ncb7d77bfd9f1
精度向上ROI: データ品質 ≫ データ量 ノイズの多いデータの費用対効果はデータ品質向上が優勢(数千オーダーまでなら) [Andrew Ng, 2021] https://www.deeplearning.ai/wp-content/uploads/2021/06/MLOps-From-Model-centric-to-Data-centric-AI.pdf より引用
データ品質: データエンジニアリング文脈 「データ品質保証」技術というと ETL の動作テスト等をまず連想する - 主目的 : - 施策決定のための分析用途
- アプリケーションが使用するデータリソース - 品質項目の典型例 : Uber のデータ品質チェック項目を引用 [1] - 鮮度 (freshness), 欠損値率 (completeness), 重複率 (duplicates), - 環境間の一貫性 (cross-datacenter consistency) - その他 (others): データの意味やビジネスロジックに関わるテスト(個別ケース技術) - 品質を担保する技術要素 - テストに加えて、トレーサビリティ (data lineage) 管理やバックフィル等実行管理、監視など [1] https://eng.uber.com/operational-excellence-data-quality/
データ品質: 機械学習製品モデル開発文脈 「データの意味」が重要で品質保証コストが大きい - 主目的 : - 機械学習モデルの学習のため ( データ作成
) - 機械学習モデルの動作保証のため ( モデル検証 ) - 品質項目の例 ( 弊社の事例を元に列挙 ; grammarly の事例も類似 [1]) - データ量・データ多様性・データ分布 - 欠損値率・重複率・リーク防止 - ラベル誤り率・ラベル一貫性・アノテータ間合意 - 除外事例 ( ごみデータやプライバシー情報 ) や 限界事例 ( 判断が難しいデータなど ) の扱い - 教師データ外事例(ドメイン外 , アノテーション仕様漏れ) - マニュアル管理や専門家合同のエラー分析などのプロセス管理が重要 [1] https://www.grammarly.com/blog/high-quality-nlp-datasets/
品質保証コストが高い例: データドリフト 自動検知が難しく、外部品質に直接影響が出やすいため厄介 1. モデル適用ドメインが汎用ドメインからドリフト ◦ 契約書の語彙 vs 新聞やウェブコーパスの語彙 ◦
特殊な意味を孕むフレーズ: e.g. 「事業譲渡」 ≠ 「事業の譲渡」 ◦ 逆にドメインを絞ればより秩序だつことも 2. 適用ドメイン内部でもドリフト(ドメイン軸が多観点) ◦ 契約書はあらゆる企業活動で必須 ◦ 「業界」ごとに単語分布や知識の特殊性が顕れる ▪ 金融、不動産、商社、製造業、メディア、製薬、 … ◦ → データが少ないうちは、専門家の知識による補正が有効 ( NLP のような解釈可能な汎化では、評価設定と現象が乖離していないかの「想像力」が求められる)
データ品質担保の効率化 Human-in-the-loop なプロセス管理を中心として効率化の余地がある 1. データ収集・検証 ◦ データ作成の効率化: データの条件検索 , 半自動ラベリング
, アノテーションツール , … ◦ データ検証の効率化: ( 擬 ) 重複判定 , 匿名化 , 層化抽出 , クラスタリング , … 2. モデル検証 ◦ アノテーション支援機能の流用 ▪ モデル適用状況、データレビュー状況を管理するシステム内機能 3. モデル性能監視 ◦ 統計値ベースのドリフト検知や、データサンプル込みの logging ▪ Amazon SageMaker Model Monitor や Vertex AI Model Monitoring 等を意識
まとめ Vertical AI 製品とはコードに加えてデータ品質の管理が重要 - 実体:コード + モデル + データ
- 正しさ:専門知 + 業務知 - 品質:内部品質 + 外部品質 - 開発主体:開発者 + 専門家 + ユーザー ( の代弁者 ) - ドメイン専門家やカスタマーサクセスは実質開発者 ( コードを書かなくとも品質に貢献 ) - 製品品質向上のためにデータ品質向上が重要
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![精度向上ROI: データ品質 ≫ データ量 ノイズの多いデータの費用対効果はデータ品質向上が優勢(数千オーダーまでなら) [Andrew Ng, 2021] https://www.deeplearning.ai/wp-content/uploads/2021/06/MLOps-From-Model-centric-to-Data-centric-AI.pdf より引用](https://files.speakerdeck.com/presentations/337943f093384d66b61944e9d7a1da24/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}