Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Cardiff 12-5-2017
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Daniel Lakens
May 12, 2017
Science
1
65
Cardiff 12-5-2017
Invited Colloquium on Designing Efficient and Informative Studies
Daniel Lakens
May 12, 2017
Tweet
Share
Other Decks in Science
See All in Science
Collective Predictive Coding as a Unified Theory for the Socio-Cognitive Human Minds
tanichu
0
160
蔵本モデルが解き明かす同期と相転移の秘密 〜拍手のリズムはなぜ揃うのか?〜
syotasasaki593876
1
210
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
あなたに水耕栽培を愛していないとは言わせない
mutsumix
1
250
知能とはなにかーヒトとAIのあいだー
tagtag
PRO
0
140
LayerXにおける業務の完全自動運転化に向けたAI技術活用事例 / layerx-ai-jsai2025
shimacos
5
21k
データベース04: SQL (1/3) 単純質問 & 集約演算
trycycle
PRO
0
1.1k
academist Prize 4期生 研究トーク延長戦!「美は世界を救う」っていうけど、どうやって?
jimpe_hitsuwari
0
470
データベース15: ビッグデータ時代のデータベース
trycycle
PRO
0
440
コンピュータビジョンによるロボットの視覚と判断:宇宙空間での適応と課題
hf149
1
530
論文紹介 音源分離:SCNET SPARSE COMPRESSION NETWORK FOR MUSIC SOURCE SEPARATION
kenmatsu4
0
520
SpatialRDDパッケージによる空間回帰不連続デザイン
saltcooky12
0
160
Featured
See All Featured
Technical Leadership for Architectural Decision Making
baasie
1
240
Believing is Seeing
oripsolob
1
55
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
359
30k
Optimising Largest Contentful Paint
csswizardry
37
3.6k
Discover your Explorer Soul
emna__ayadi
2
1.1k
Facilitating Awesome Meetings
lara
57
6.8k
HDC tutorial
michielstock
1
380
Building Adaptive Systems
keathley
44
2.9k
Visualization
eitanlees
150
17k
Practical Orchestrator
shlominoach
191
11k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.1k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
1
440
Transcript
Designing Efficient and Informative Studies Daniel Lakens @Lakens Eindhoven University
of Technology
How do you determine the sample size for a new
study?
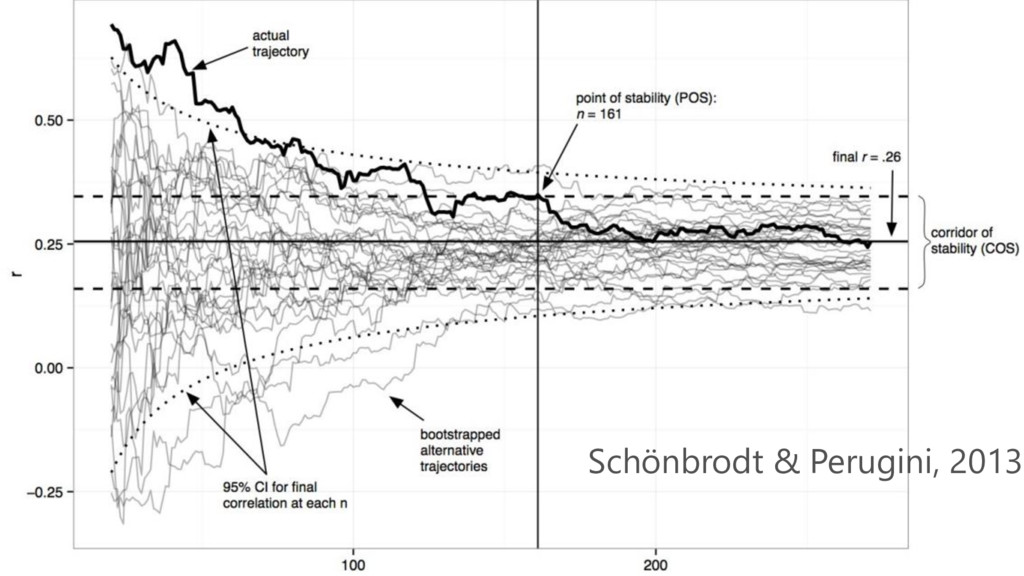
Small samples have large variation, more Type 2 errors, and
inaccurate estimates.
Schönbrodt & Perugini, 2013
None
Studies in psychology often have low power. Estimates average around
50%. Cohen, 1962; Fraley & Vazire, 2014
One reason for low power is that people use heuristics
to plan their sample size.
You need to justify the sample size of a study.
What goal do you want to achieve?
Goal according to JPSP:
Goal according to JESP:
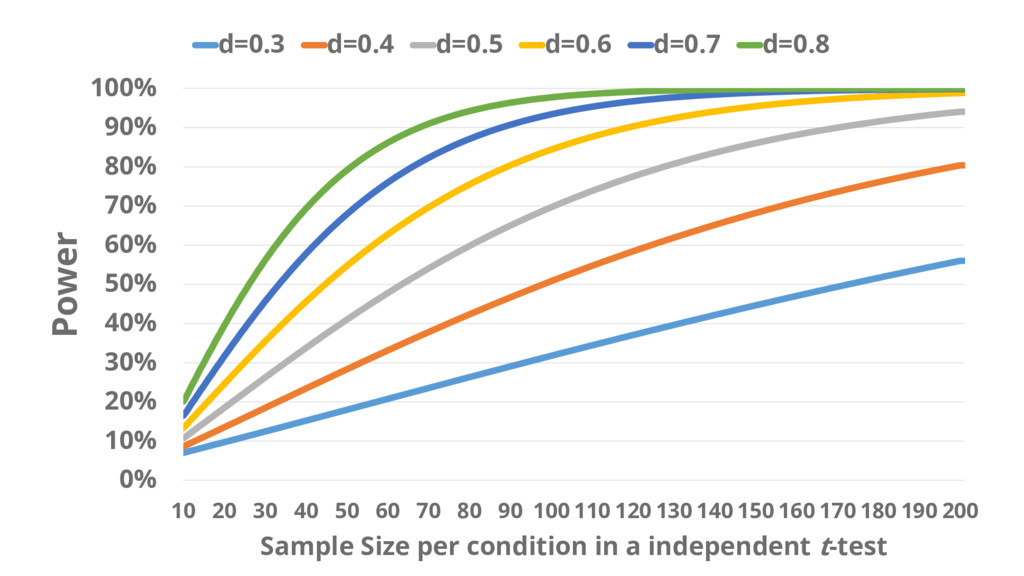
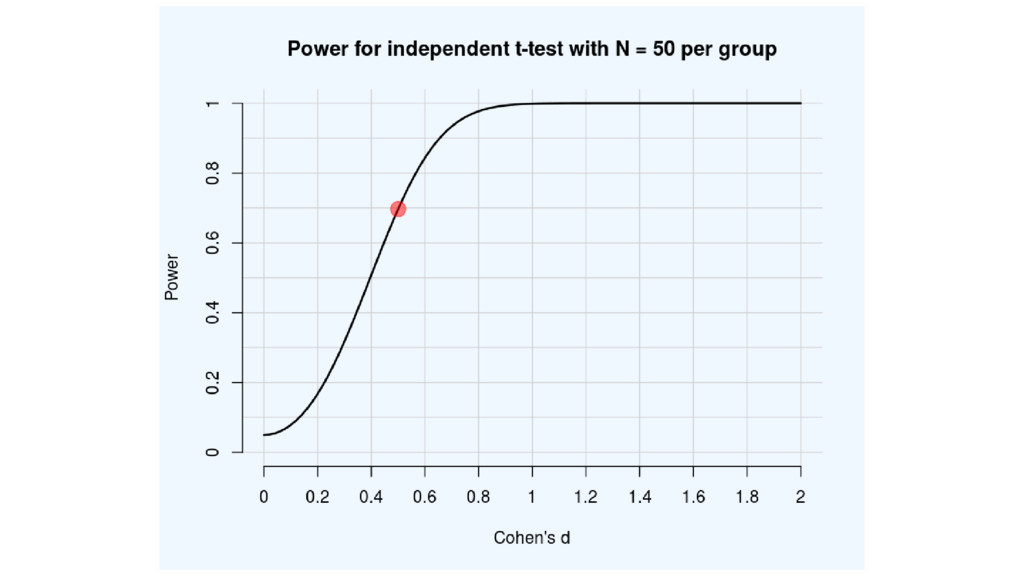
Statistical power is the long-run probability of observing p <
α with N participants, assuming a specific effect size.
But 1) You never know the true effect size, and
the literature is biased, and 2) If you expect a true effect of 0, power is 0
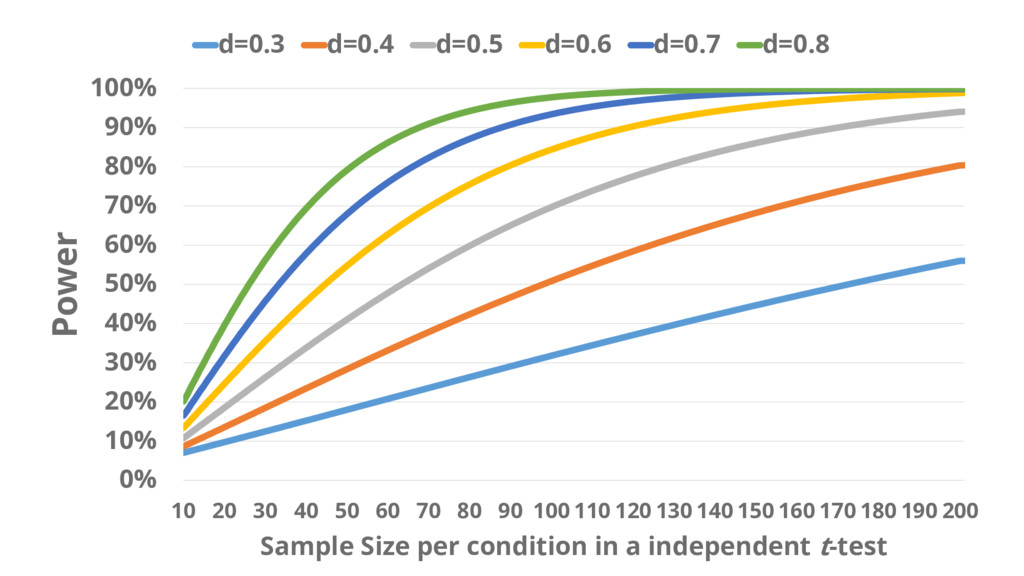
0% 10% 20% 30% 40% 50% 60% 70% 80% 90%
100% 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 Power Sample Size per condition in a independent t-test d=0.3 d=0.4 d=0.5 d=0.6 d=0.7 d=0.8
My department requires sample size justification before funding a study.
One justification the IRB accepts is 90% power.
What is ‘evidence’?
Evidence is always relative. You want a higher likelihood of
p<0.05 when H1 is true than when H0 is true.
High power leads to informative studies only when we control
alpha levels.
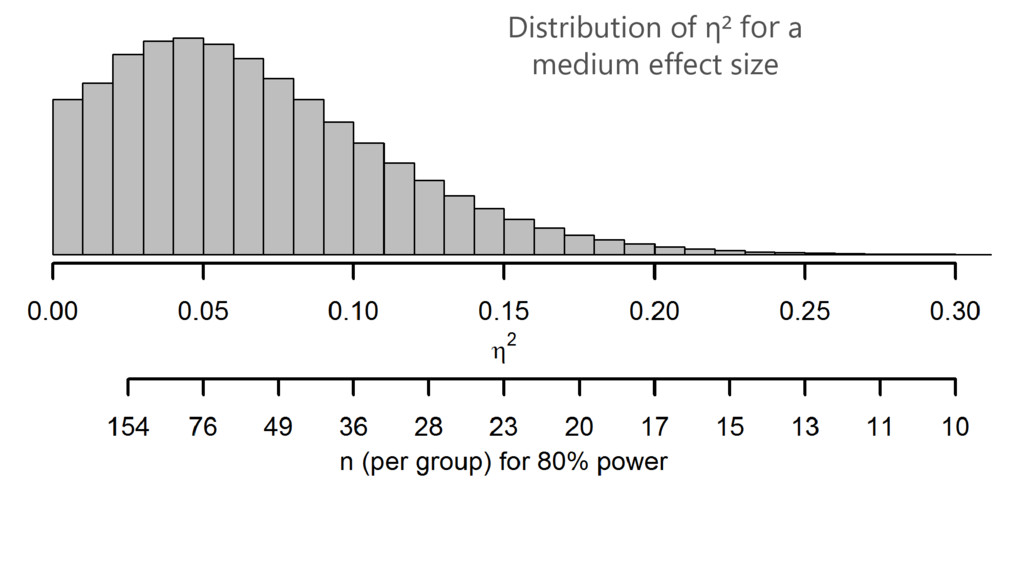
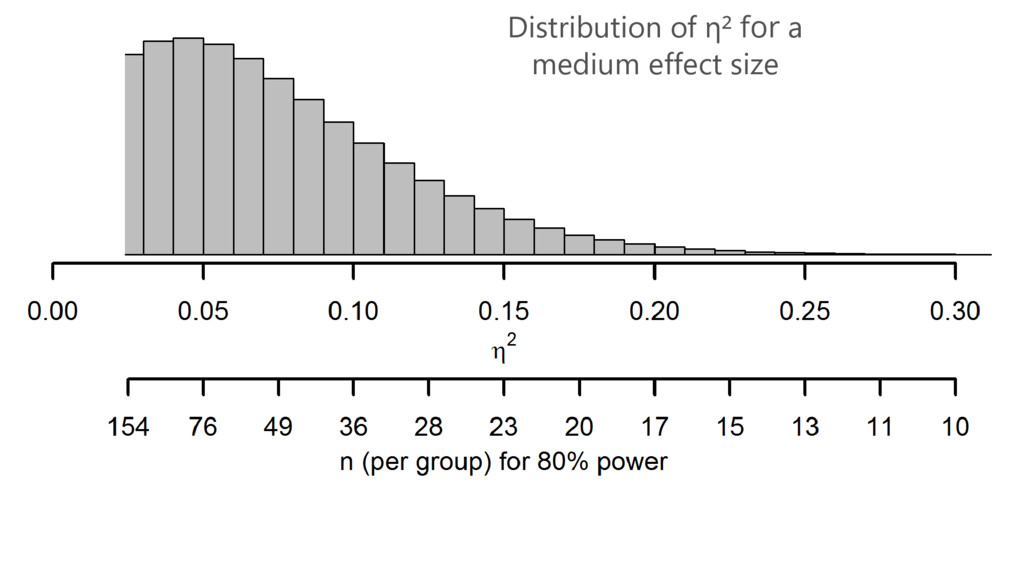
What we have been doing wrong: Using previous studies as
an effect size estimate
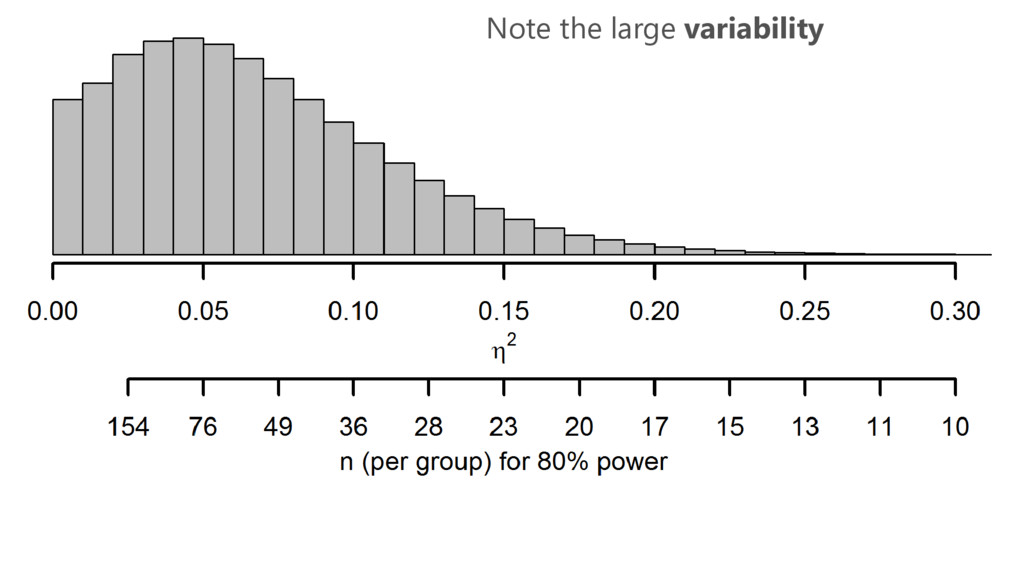
Distribution of η² for a medium effect size
Distribution of η² for a medium effect size
A pilot study does not provide a meaningful effect size
estimate for planning subsequent studies. Leon, Davis, & Kraemer, 2011
Power analysis based on significant studies need to be based
on a truncated F distribution. Taylor & Muller, 1996
Note the large variability
You can also take into account variability (‘assurance’) – e.g.,
using safeguard power. Perugini, Gallucci, & Constantini, 2014
Effect sizes from the published literature are always smaller than
you expect, even when you take into account that effect sizes from the published literature are always smaller than you expect.
Plan for the change you would like to see in
the world. Ask yourself: What is your smallest effect size of interest?
Requires you to specify H1! That’s a good thing. What
does you theory predict, or what do you care about if H0 is false?
If we don’t, science becomes unfalsifiable. We can never ‘accept
the null’.
But ‘I’m not interested in the size of the effect
– the presence of any effect supports my theory!’ Really?
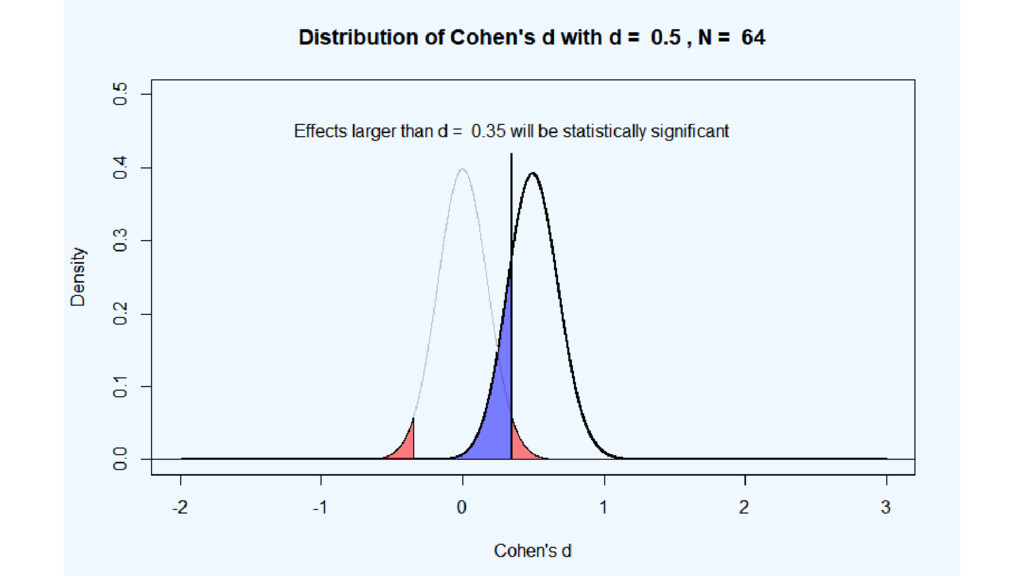
Detecting d = 0.001 requires 42 million people.
You make implicit choices about which effects are too small
to matter all the time.
None
If you expect a ‘medium’ effect size and plan for
80% power, d<0.35 will never be significant.
If nothing else, the maximum sample you are willing to
collect determines your SESOI.
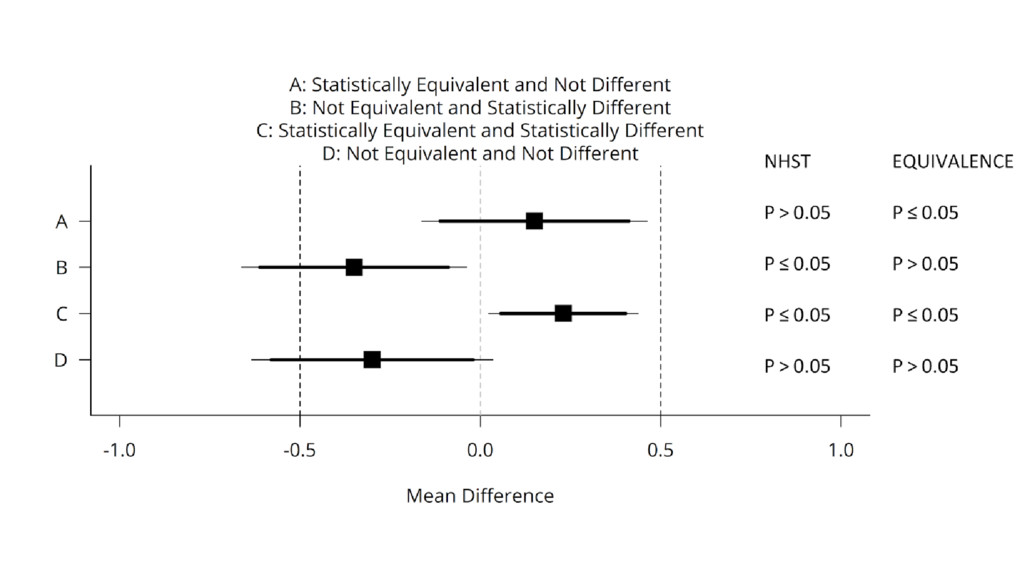
Now you can also reject effects as large as, or
larger than, your SESOI, using an equivalence test.
None
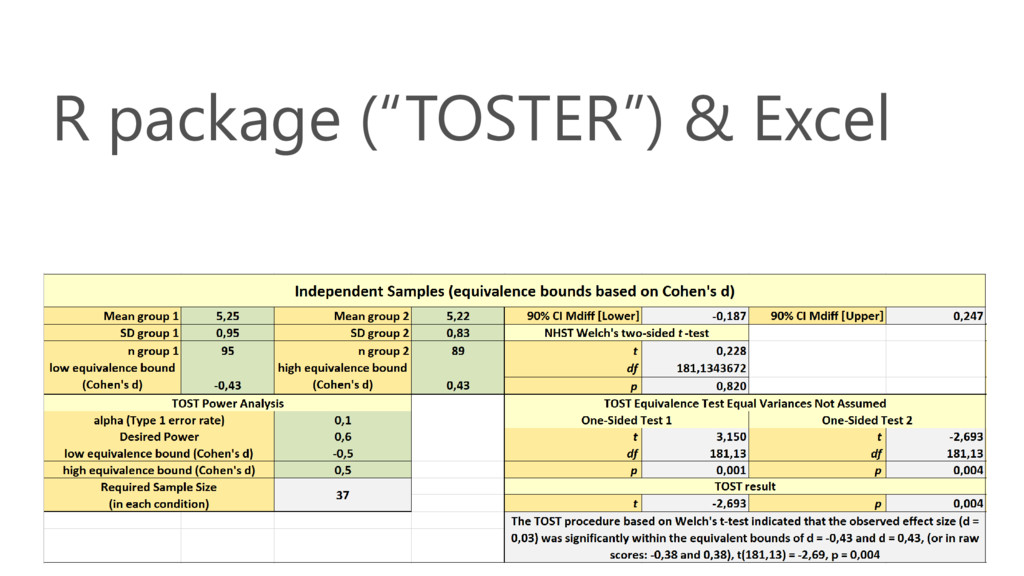
R package (“TOSTER”) & Excel
My prediction: Publishing a paper that say ‘p > 0.05,
thus no effect’ will be difficult in 2019.
Extending your statistical tool kit with equivalence tests is an
easy way to improve your inferences. Lakens, 2017
However, when the true effect size is larger than the
SESOI, powering for it is inefficient (and possibly wasteful).
Social Sciences Replication Project
0% 10% 20% 30% 40% 50% 60% 70% 80% 90%
100% 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 Power Sample Size per condition in a independent t-test d=0.3 d=0.4 d=0.5 d=0.6 d=0.7 d=0.8
None
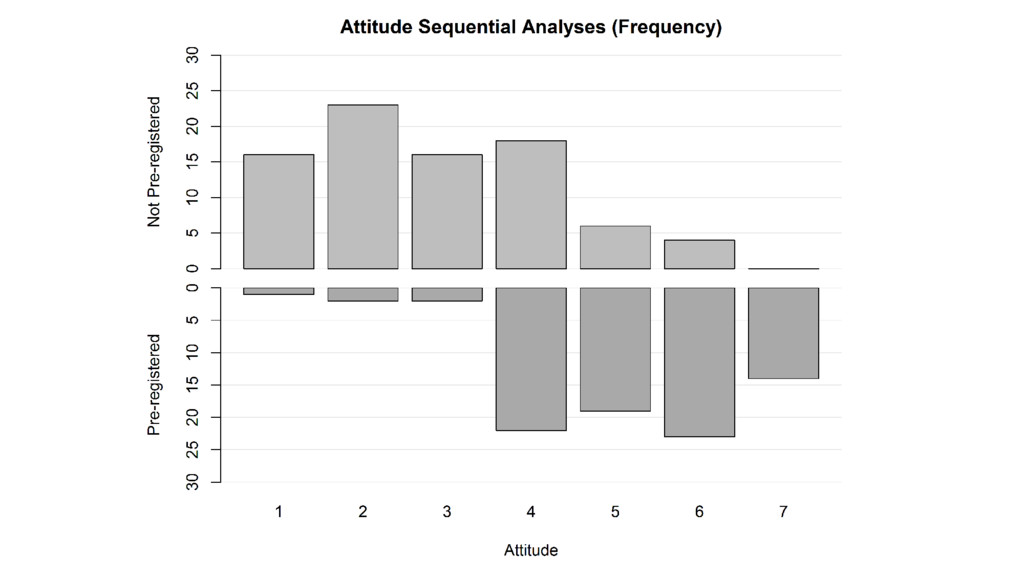
When effect sizes are uncertain (=always), a better approach is
sequential analyses.
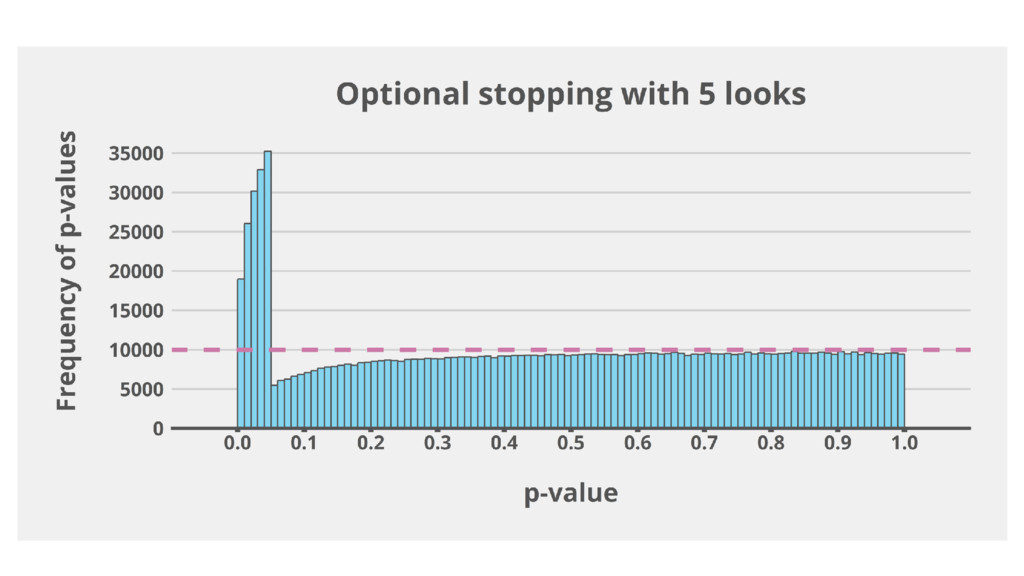
Optional stopping: Collecting data until p < 0.05 inflates the
Type 1 error.
A user of NHST could always obtain a significant result
through optional stopping. Wagenmakers, 2007
None
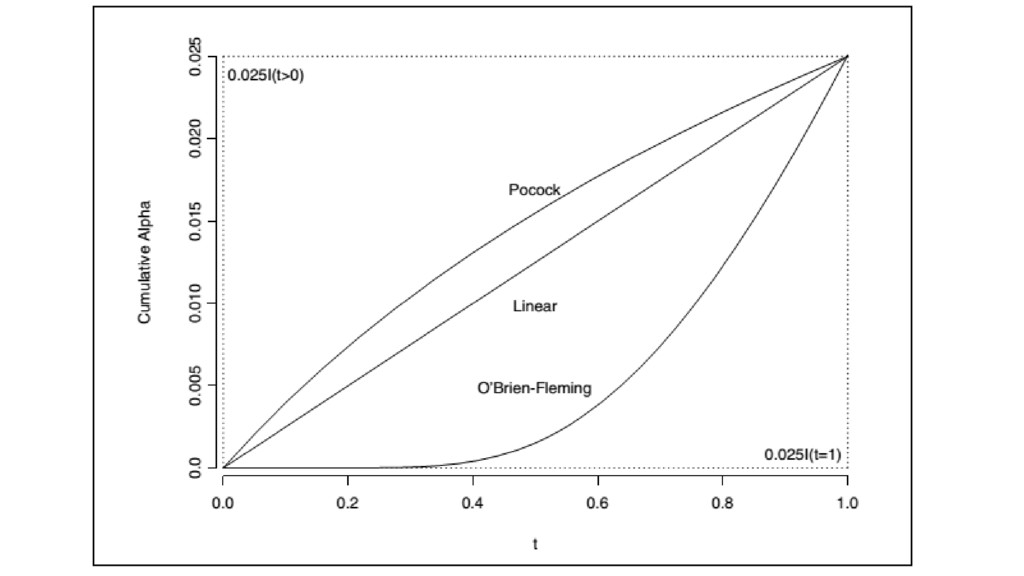
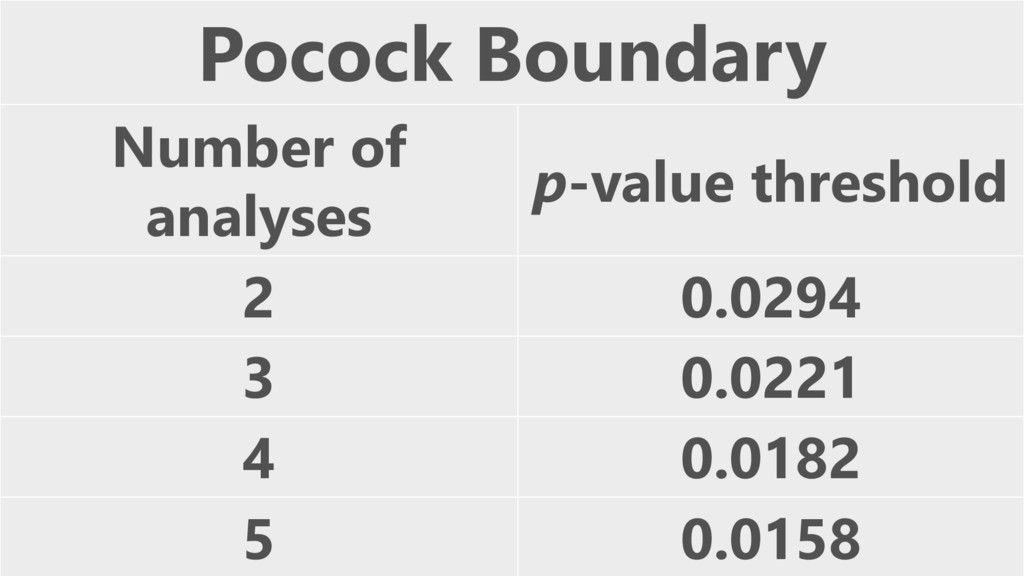
Sequential analysis controls Type 1 error rates (e.g., Pocock correction).
Wald, 1945
None
Pocock Boundary Number of analyses p-value threshold 2 0.0294 3
0.0221 4 0.0182 5 0.0158
None
None
You also correct alpha levels for equivalence tests (and can
calculate power for equivalence).
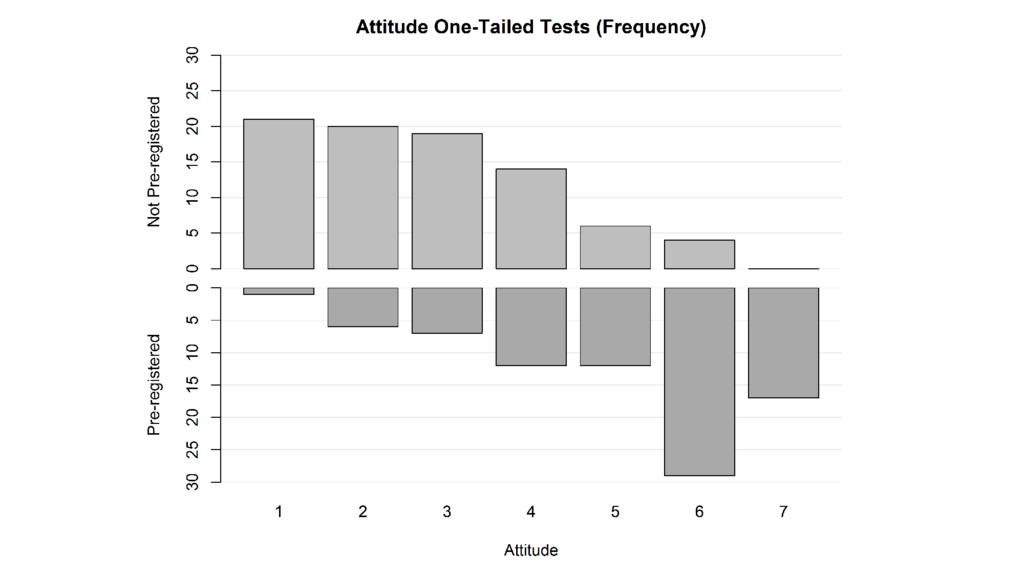
If you pre-register anyway, you can use one-sided tests (more
logical & more efficient)
None
Use decision rules based on p-values or Bayes factors, but
check Frequentist properties. Schonbrodt, Wagenmakers, Zehetleitner, & Perugini, 2015
The SESOI for the Higgs boson was not based on
feasibility, but theory.
If you think the current reproducibility crisis was bad, wait
till the theory crisis in psychology starts.
Thanks! @lakens https://www.coursera.org/learn/statistical-inferences
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}