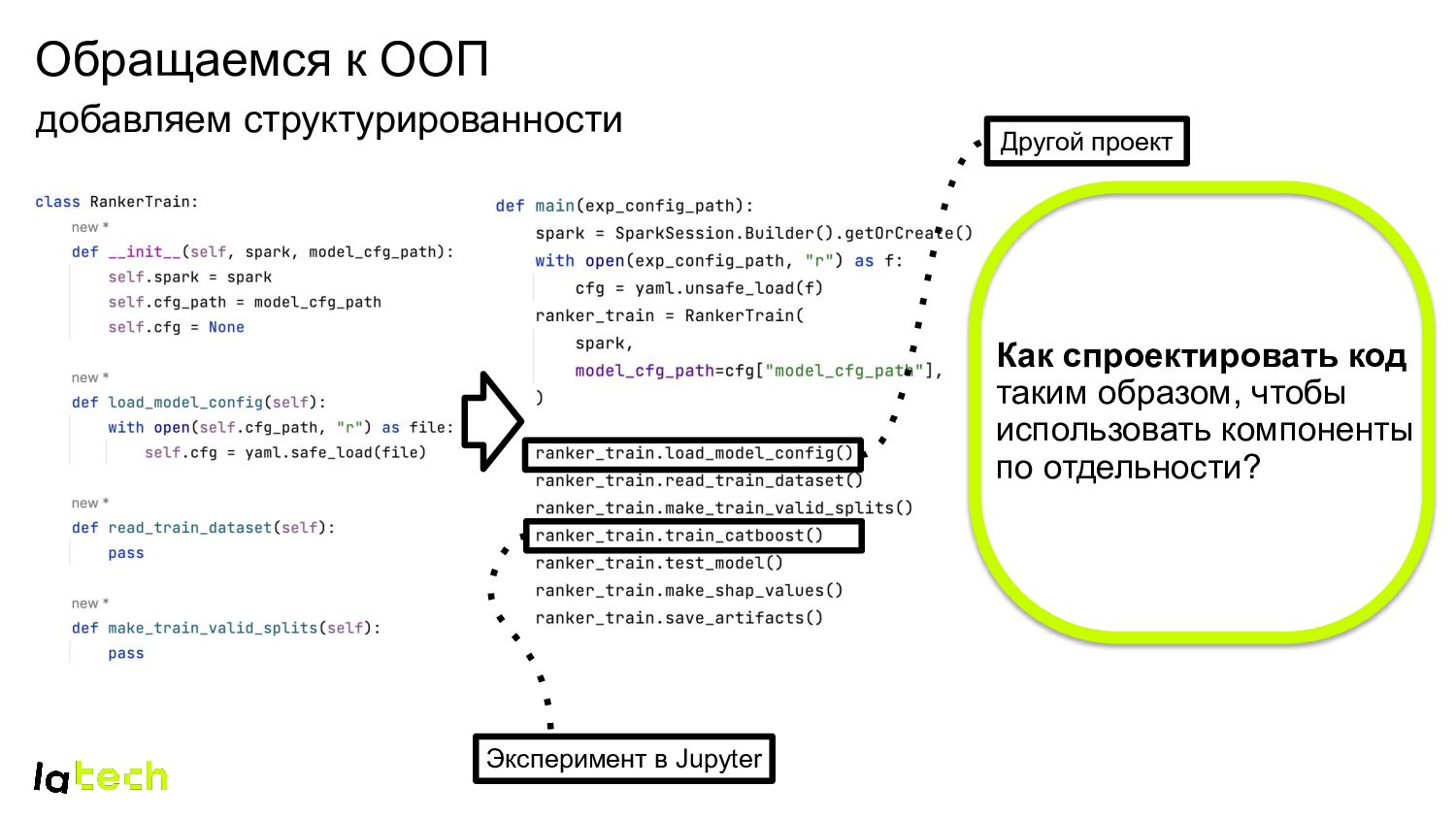
Между research и prod несколько монореп в разрезе команд для исследований Между ML-проектами как внутри одной команды, так и между разными Внутри проекта с учетом нашей специфики
helpers внутри проекта и как отдельная библиотека Вспомогательные операции: сохранение / загрузка данных и моделей, расчет и отправка метрик, логирование и т.д.
helpers внутри проекта и как отдельная библиотека Сначала структурировать и декомпозировать код, после: • Библиотека – для потенциально не изменяемых компонент кода, используемых внутри проектов. • Шаблон проекта или Jupyter ноутбука – для потенциально изменяемых компонент кода. Вспомогательные операции Этапы ML процесса пост- и пред- обработка данных train / valid / test разбиение обучение модели расчет метрик применение модели и т.д.
их компоновки и запуска. Пример: CI/CD, Data, ML, … • Чем отличаются именно ML? На концептуальном уровне только содержимым, и то не всегда. Пример: задача по обработке данных, может быть как Data, так и ML пайплайном, в зависимости от контекста. Если коротко на концептуальном уровне
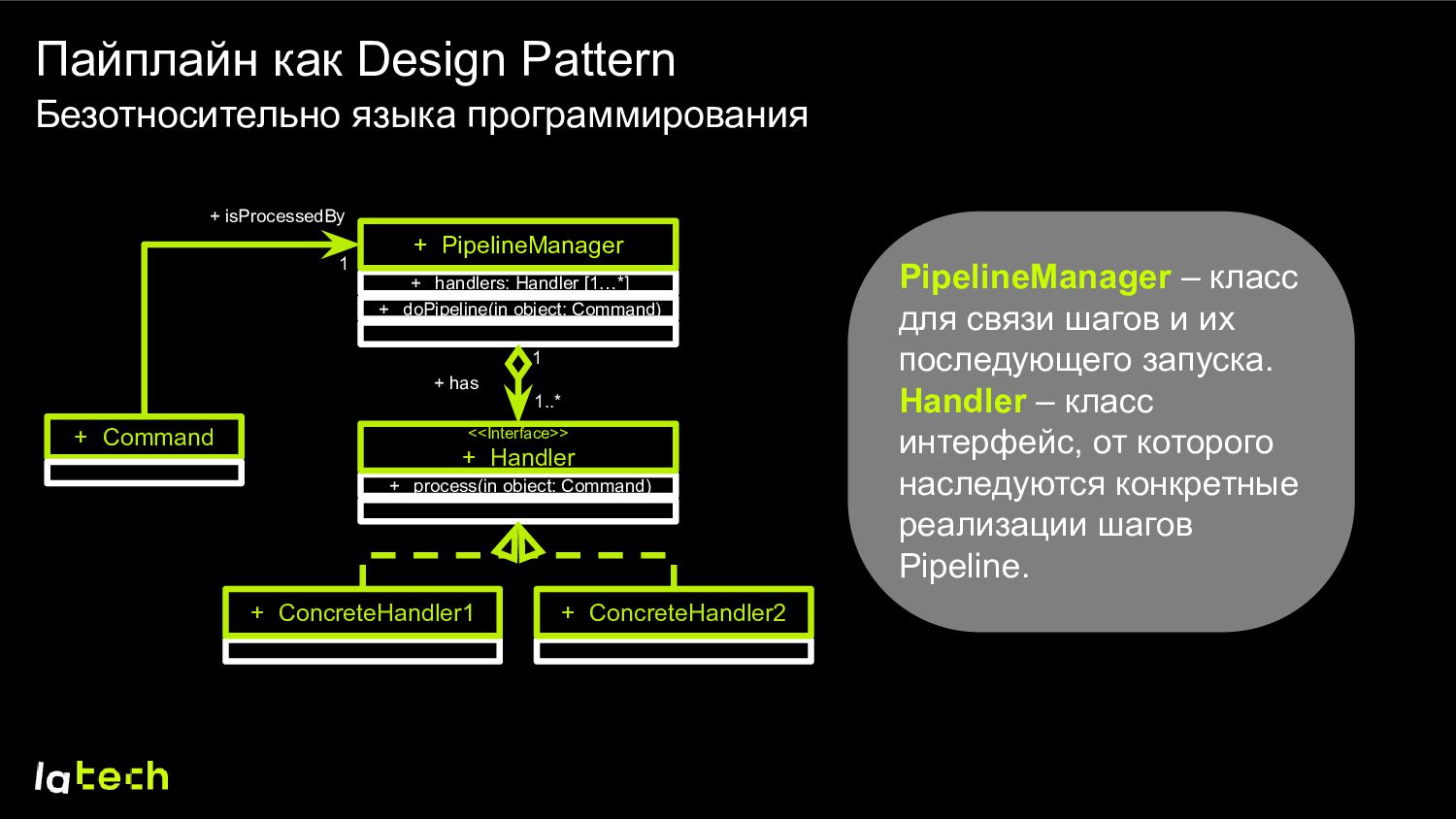
Handler [1…*] + PipelineManager + Command + process(in object: Command) <<Interface>> + Handler + ConcreteHandler1 + ConcreteHandler2 + has 1 1..* 1 + isProcessedBy PipelineManager – класс для связи шагов и их последующего запуска. Handler – класс интерфейс, от которого наследуются конкретные реализации шагов Pipeline. Безотносительно языка программирования
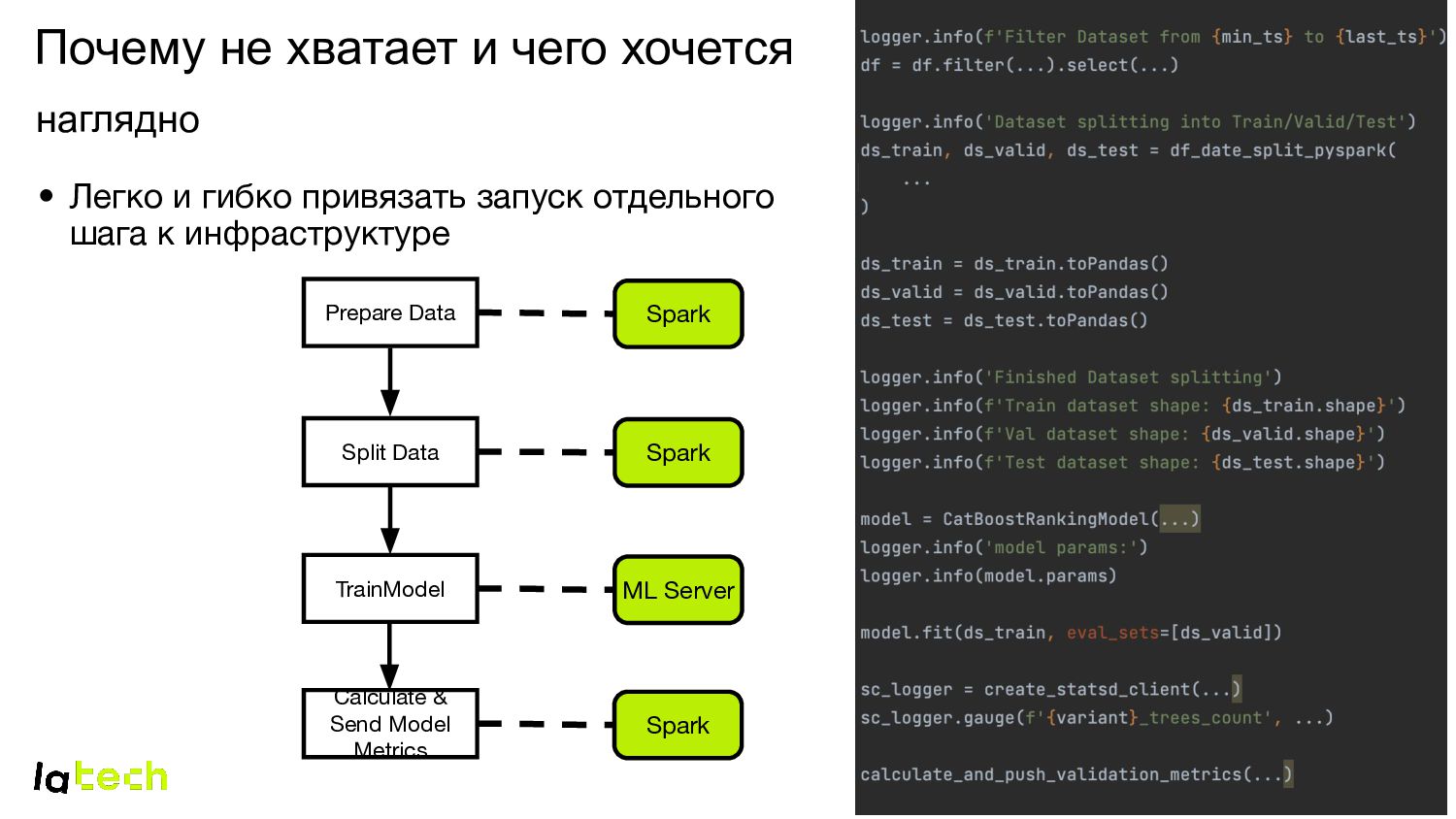
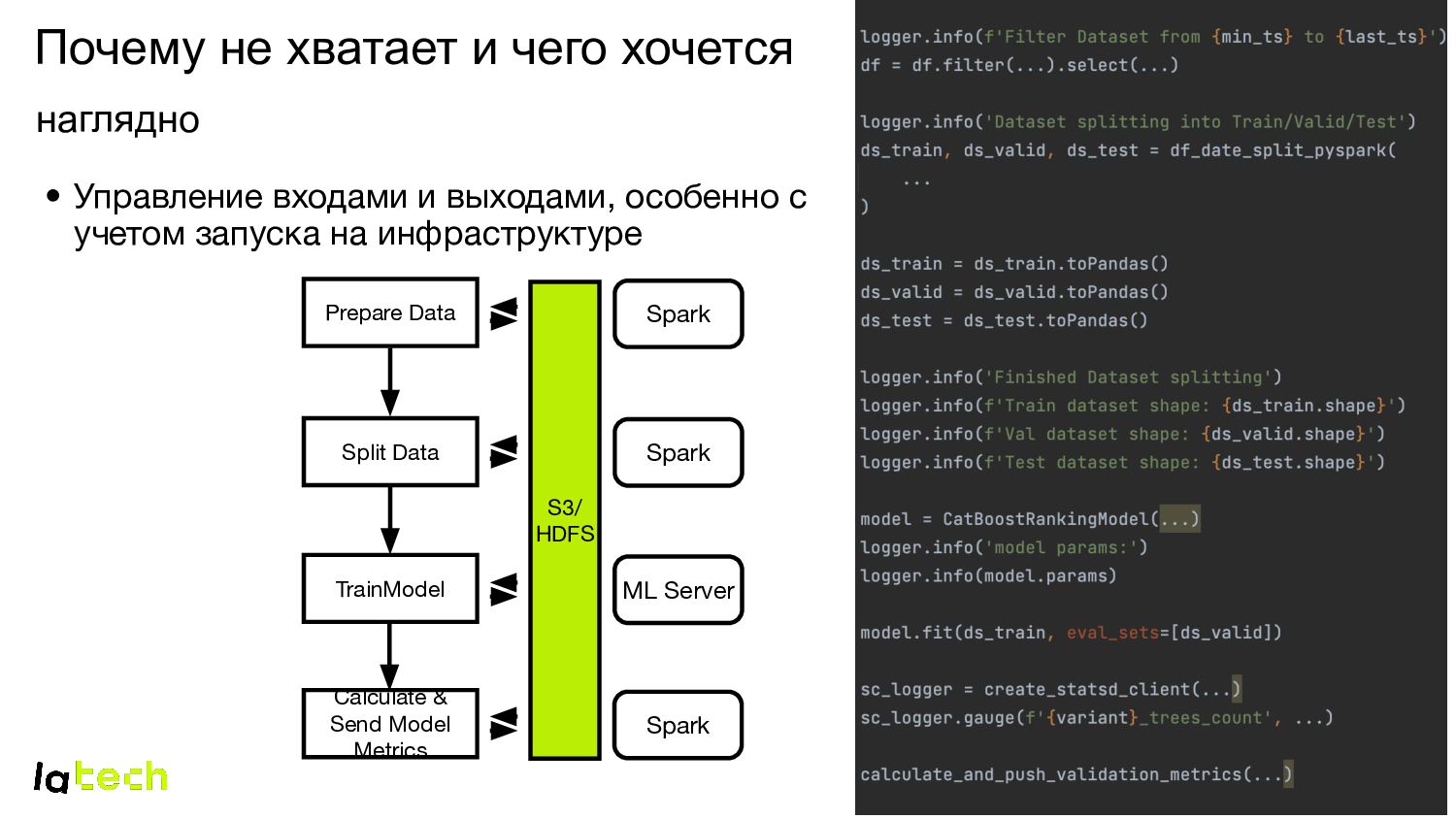
и выходами, особенно с учетом запуска на инфраструктуре Spark ML Server Spark TrainModel Calculate & Send Model Metrics Split Data Prepare Data Spark S3/ HDFS
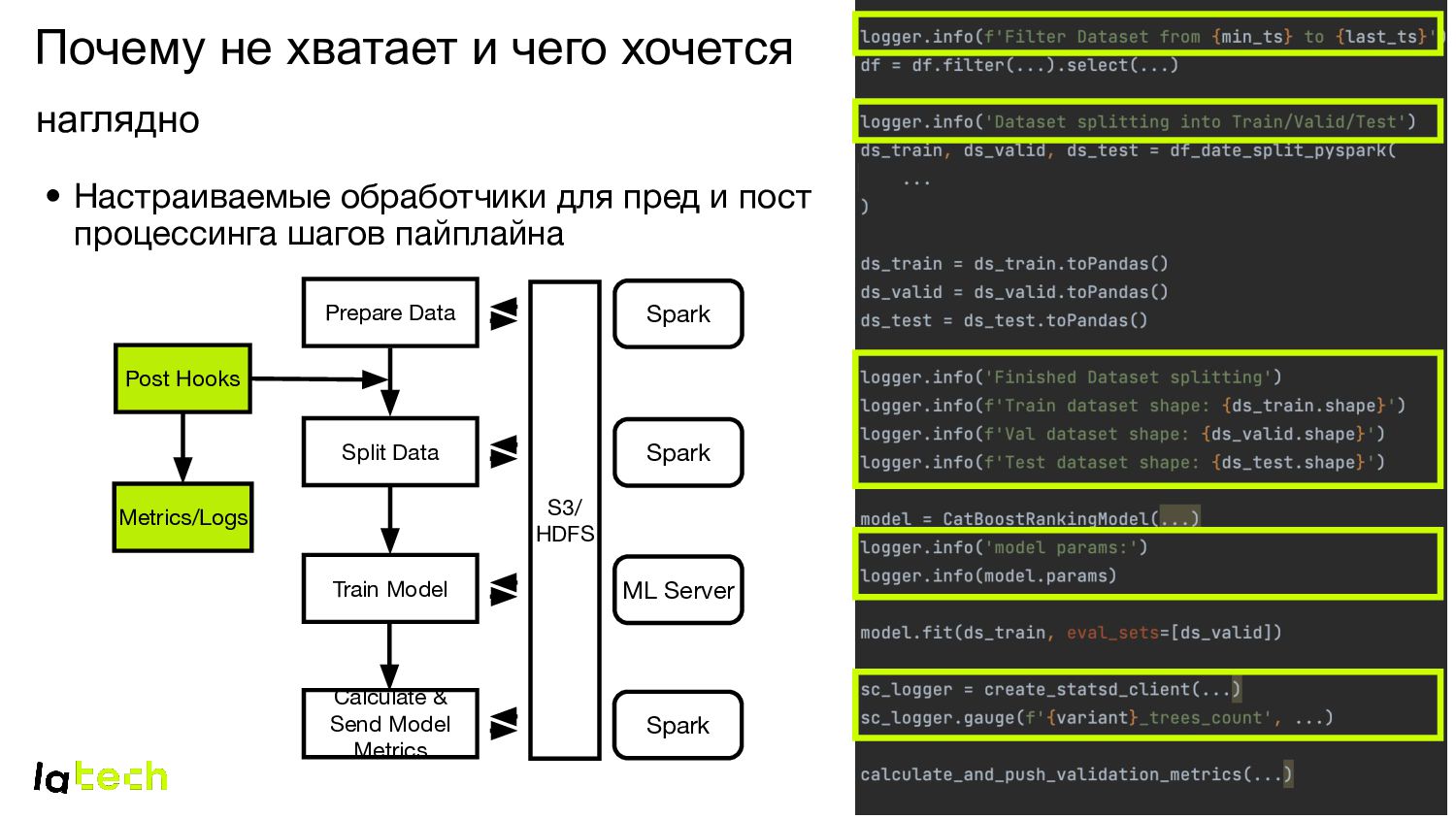
• Настраиваемые обработчики для пред и пост процессинга шагов пайплайна Spark ML Server Spark Train Model Calculate & Send Model Metrics Split Data Prepare Data Spark S3/ HDFS
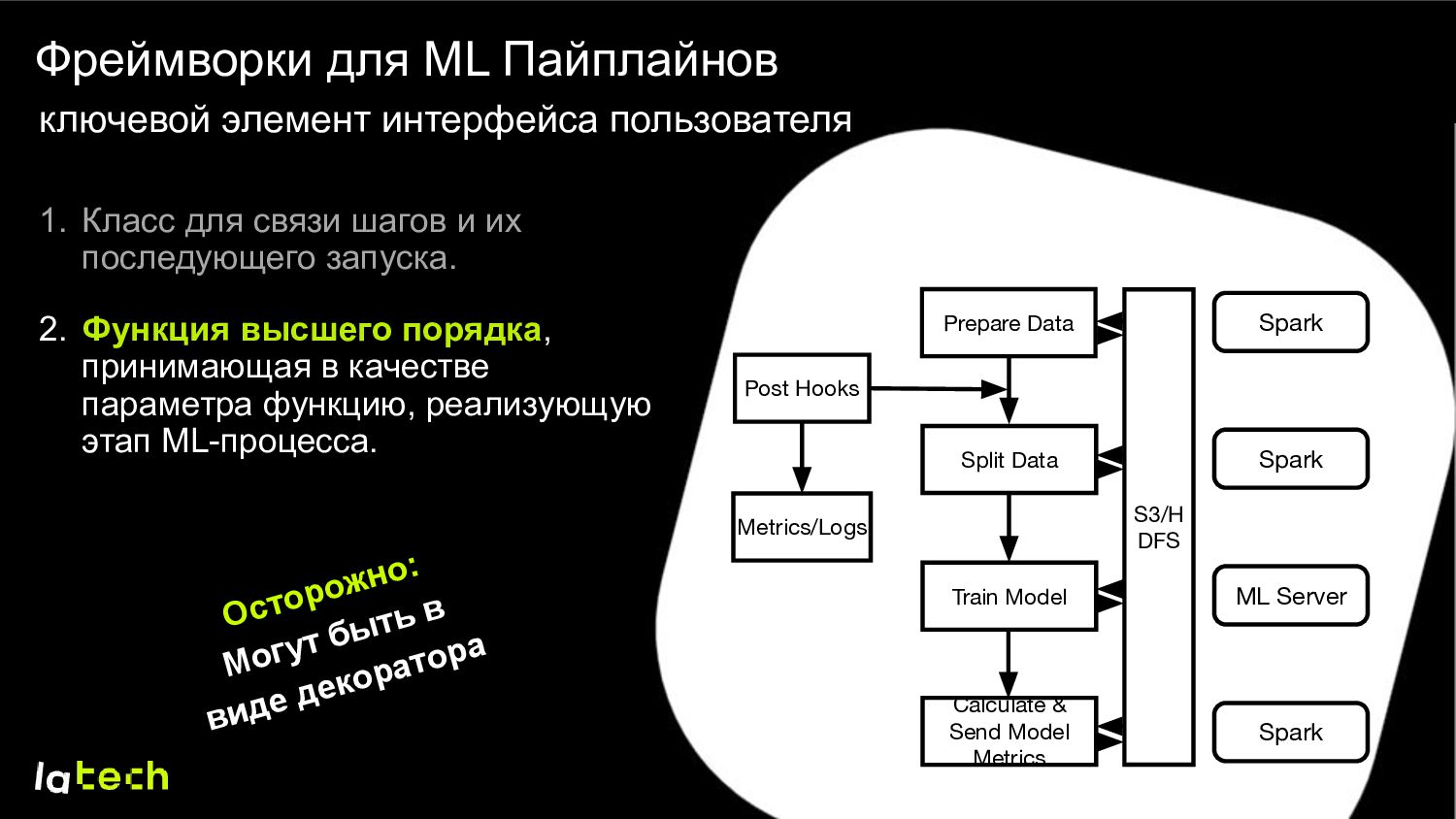
Data Spark ML Server Spark Spark Post Hooks S3/H DFS Metrics/Logs Фреймворки для ML Пайплайнов ключевой элемент интерфейса пользователя 1. Класс для связи шагов и их последующего запуска. 2. Функция высшего порядка, принимающая в качестве параметра функцию, реализующую этап ML-процесса. Осторожно: Могут быть в виде декоратора
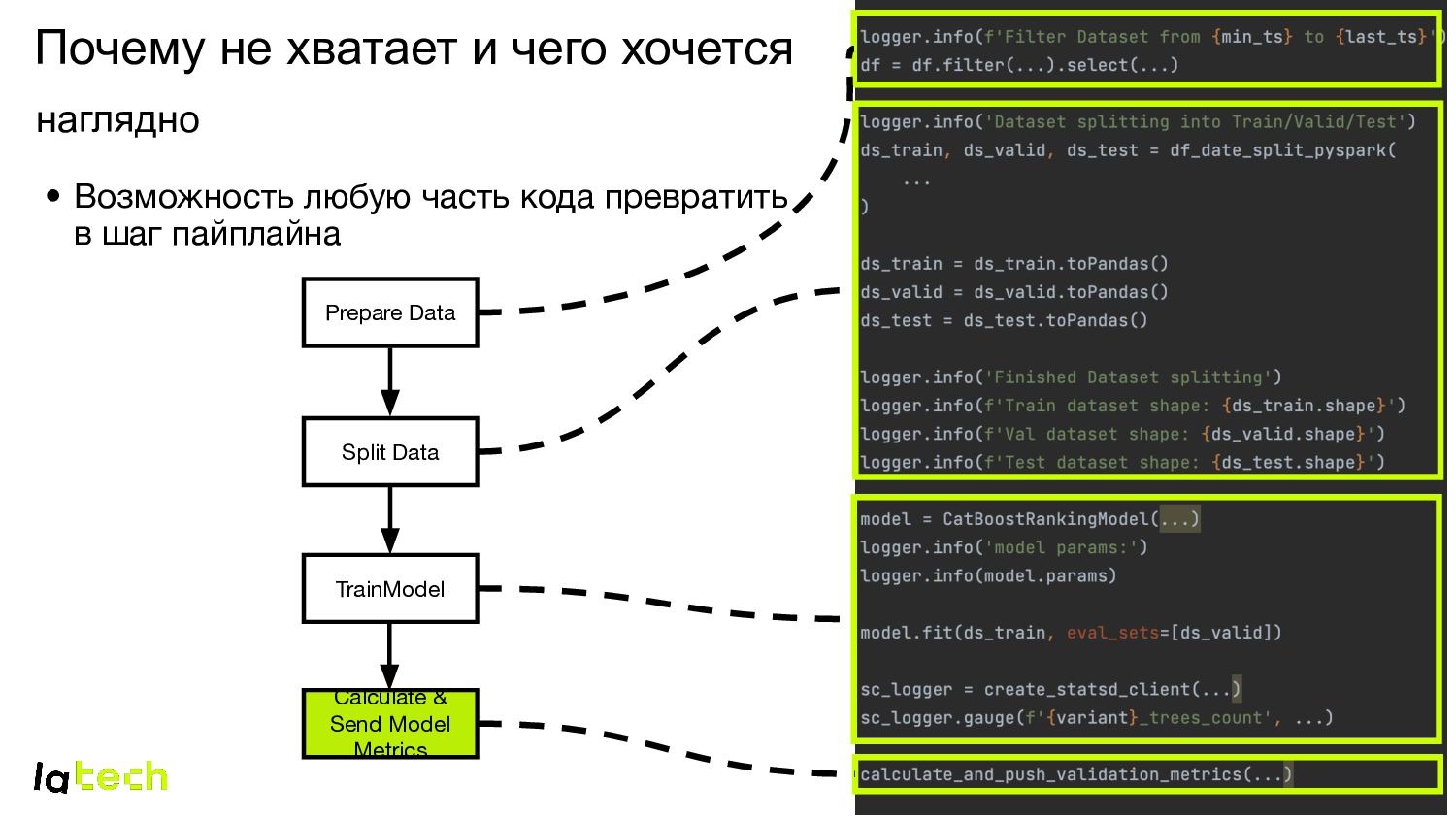
шагов Пайплайна на Spark и ML Server • Единый и удобный «инструмент» для проведения экспериментов • Схожая структура проектов Помимо повторного использования кода
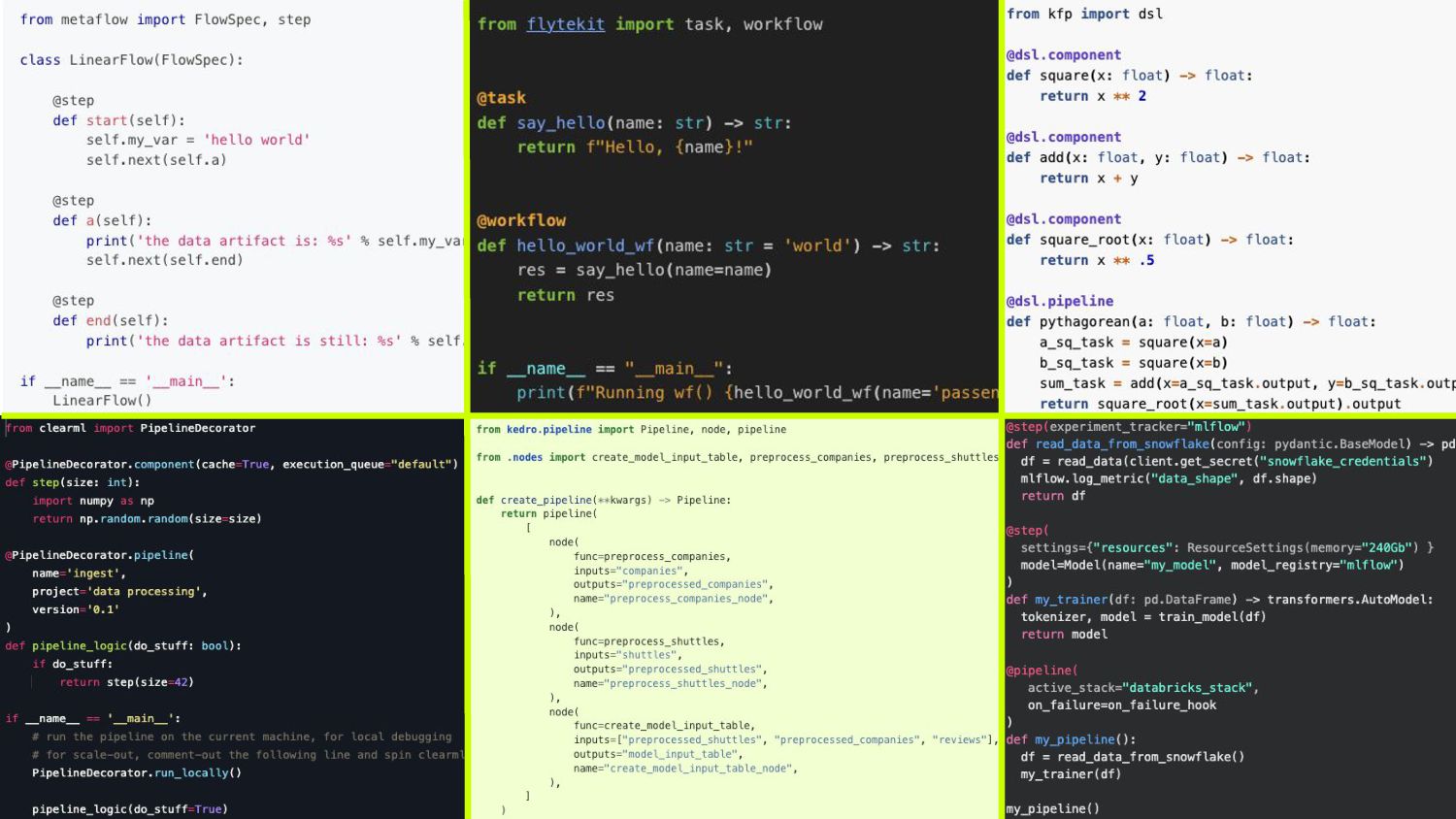
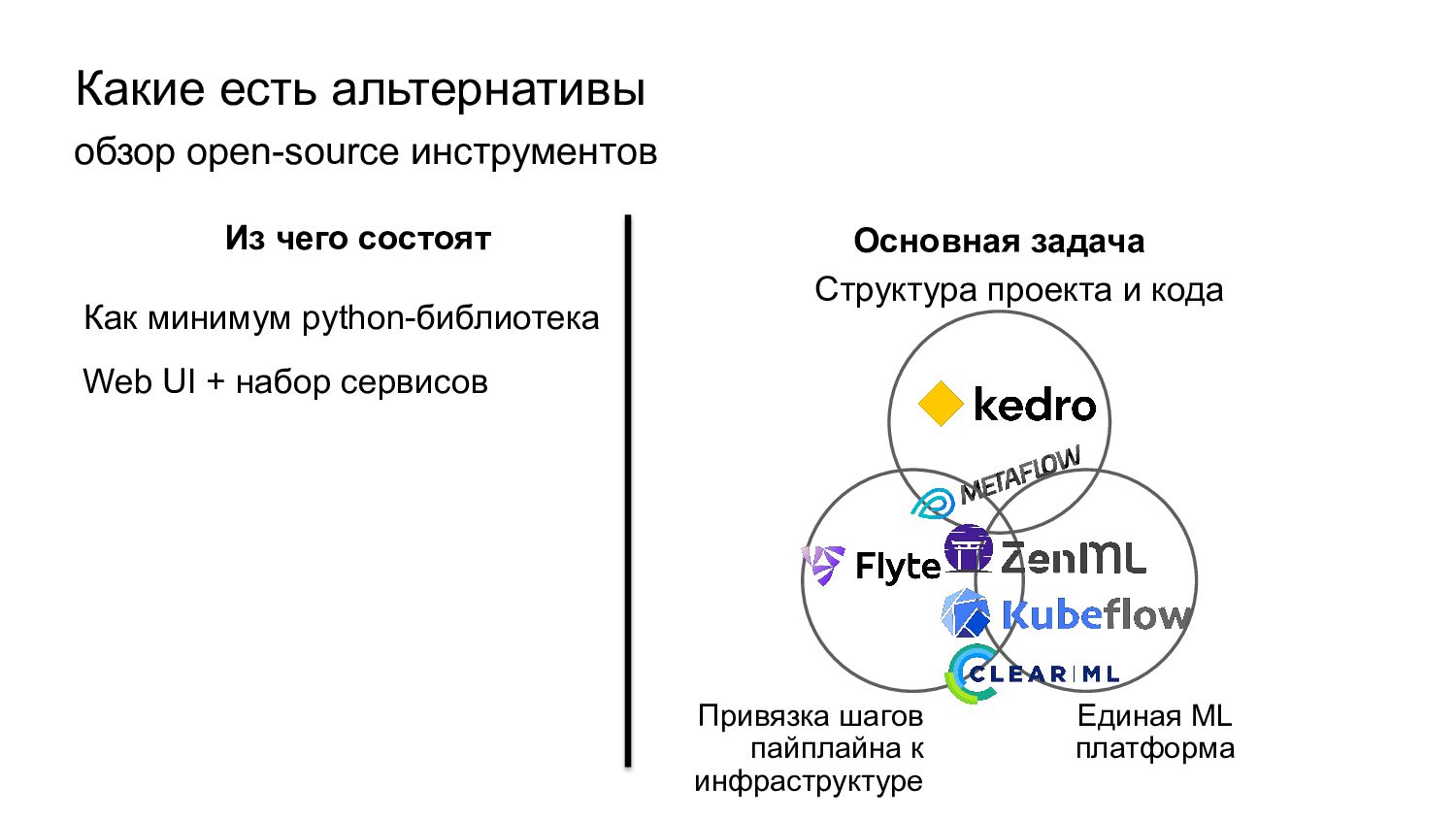
У нас есть сильный Spark on Yarn кластер (36 TB Ram, 3.5k vCores) • Пока нет Kubernetes кластера для ML, но есть выделенный сервер для «тяжелых» моделей • Исследования проводим в Jupyter • , , • , Не подходят: Остаются: • DSL кажется не самый простой – риск принятия Остаются: – Сложный DSL и много не требующегося нам функционала – На момент старта проекта не знали про фреймворк, требует изучения
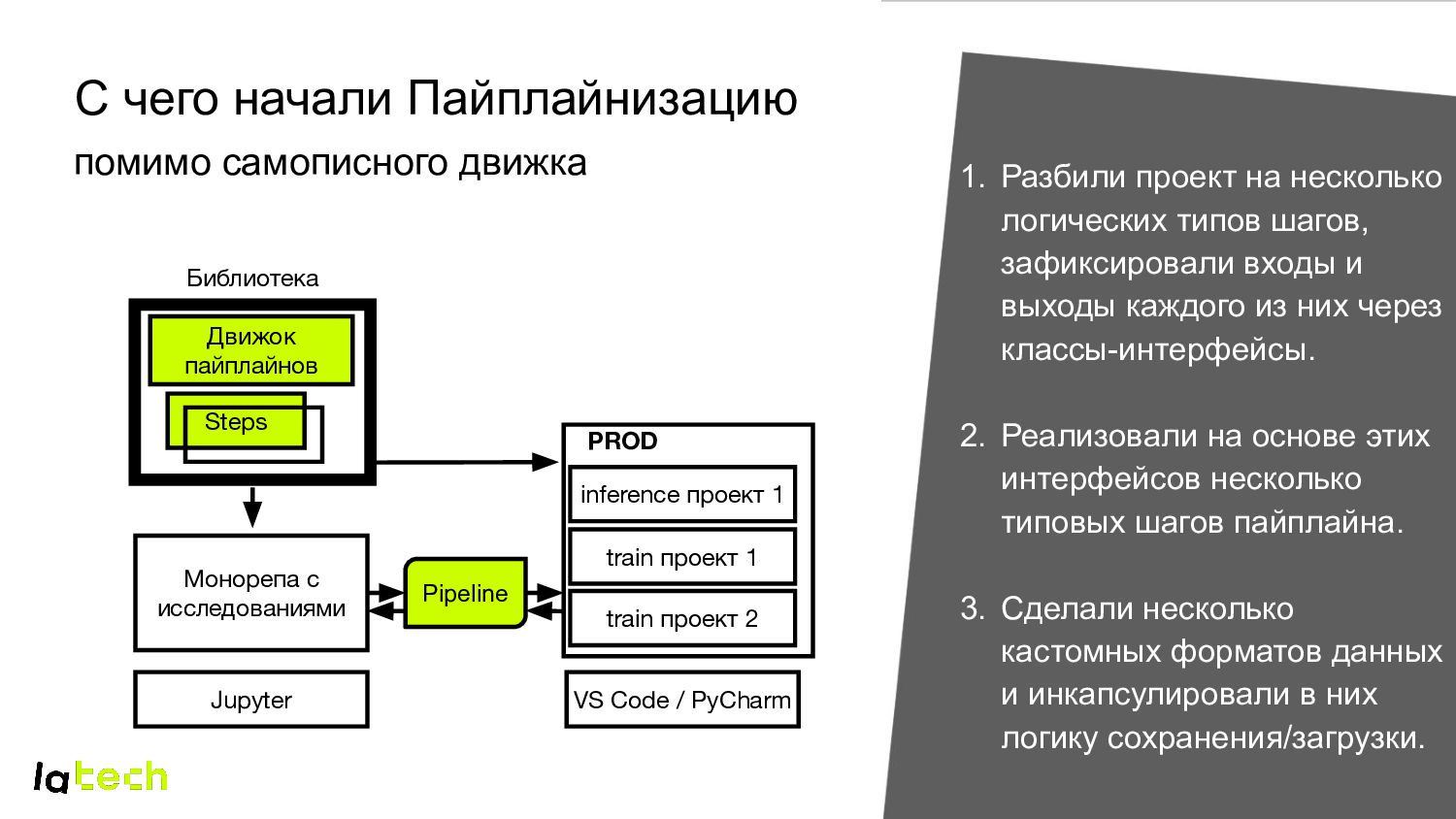
с исследованиями train проект 2 Steps Jupyter VS Code / PyCharm PROD train проект 1 Pipeline 1. Разбили проект на несколько логических типов шагов, зафиксировали входы и выходы каждого из них через классы-интерфейсы. 2. Реализовали на основе этих интерфейсов несколько типовых шагов пайплайна. 3. Сделали несколько кастомных форматов данных и инкапсулировали в них логику сохранения/загрузки. inference проект 1 Библиотека
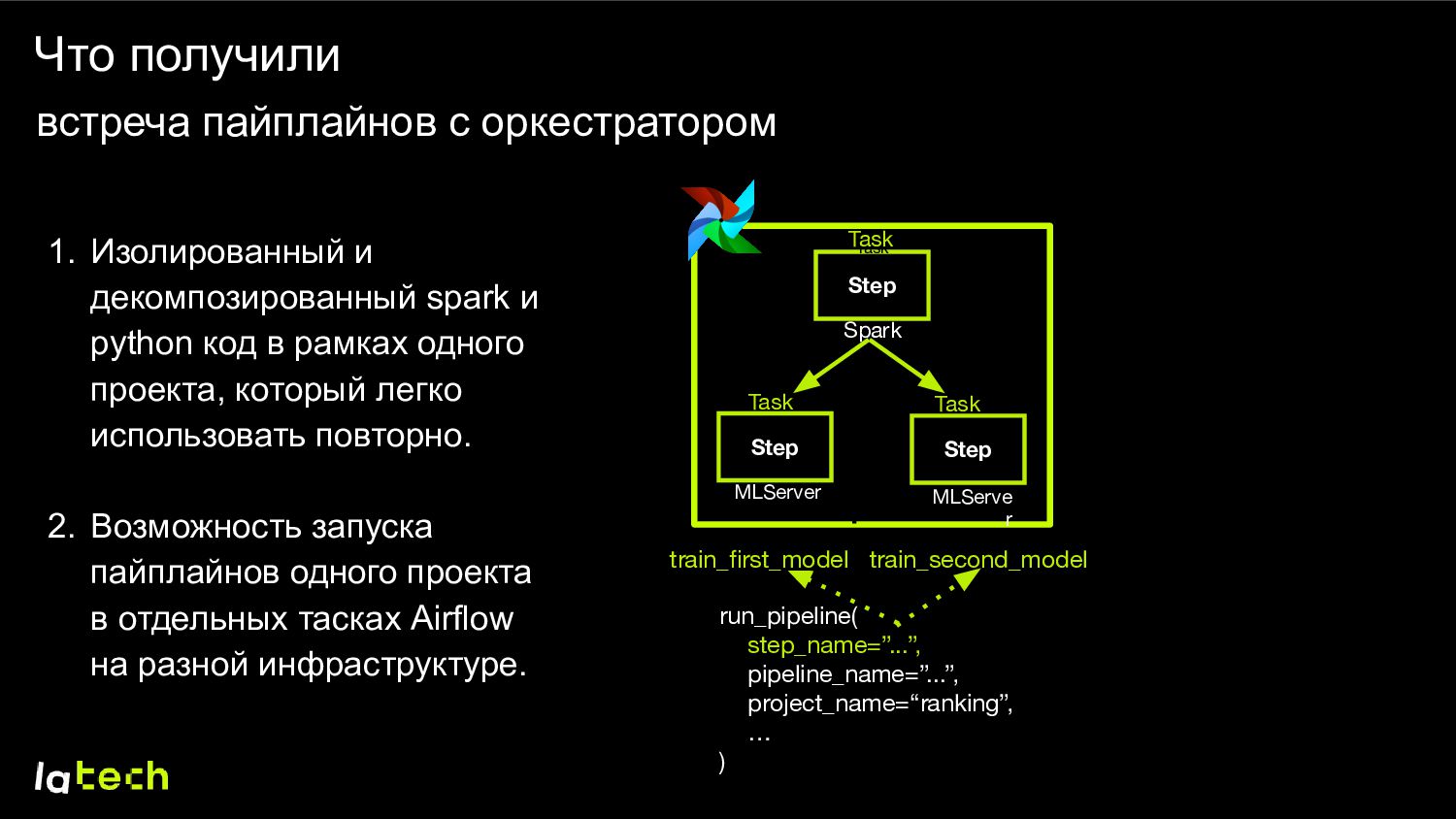
spark и python код в рамках одного проекта, который легко использовать повторно. 2. Возможность запуска пайплайнов одного проекта в отдельных тасках Airflow на разной инфраструктуре. Step Step Step Task Task Task MLServer Spark MLServe r run_pipeline( step_name=”...”, pipeline_name=”...”, project_name=“ranking”, … ) train_second_model train_first_model Task
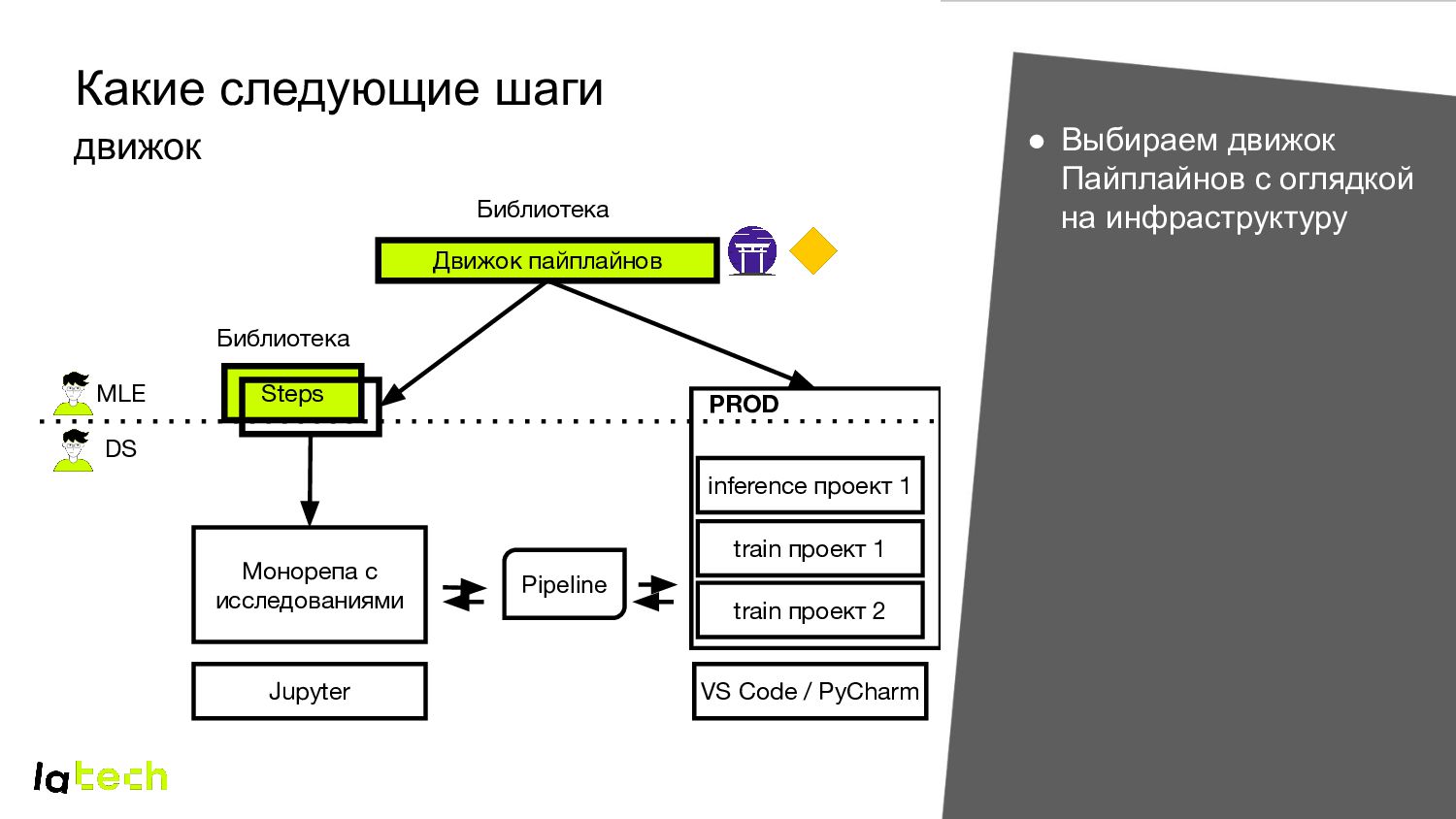
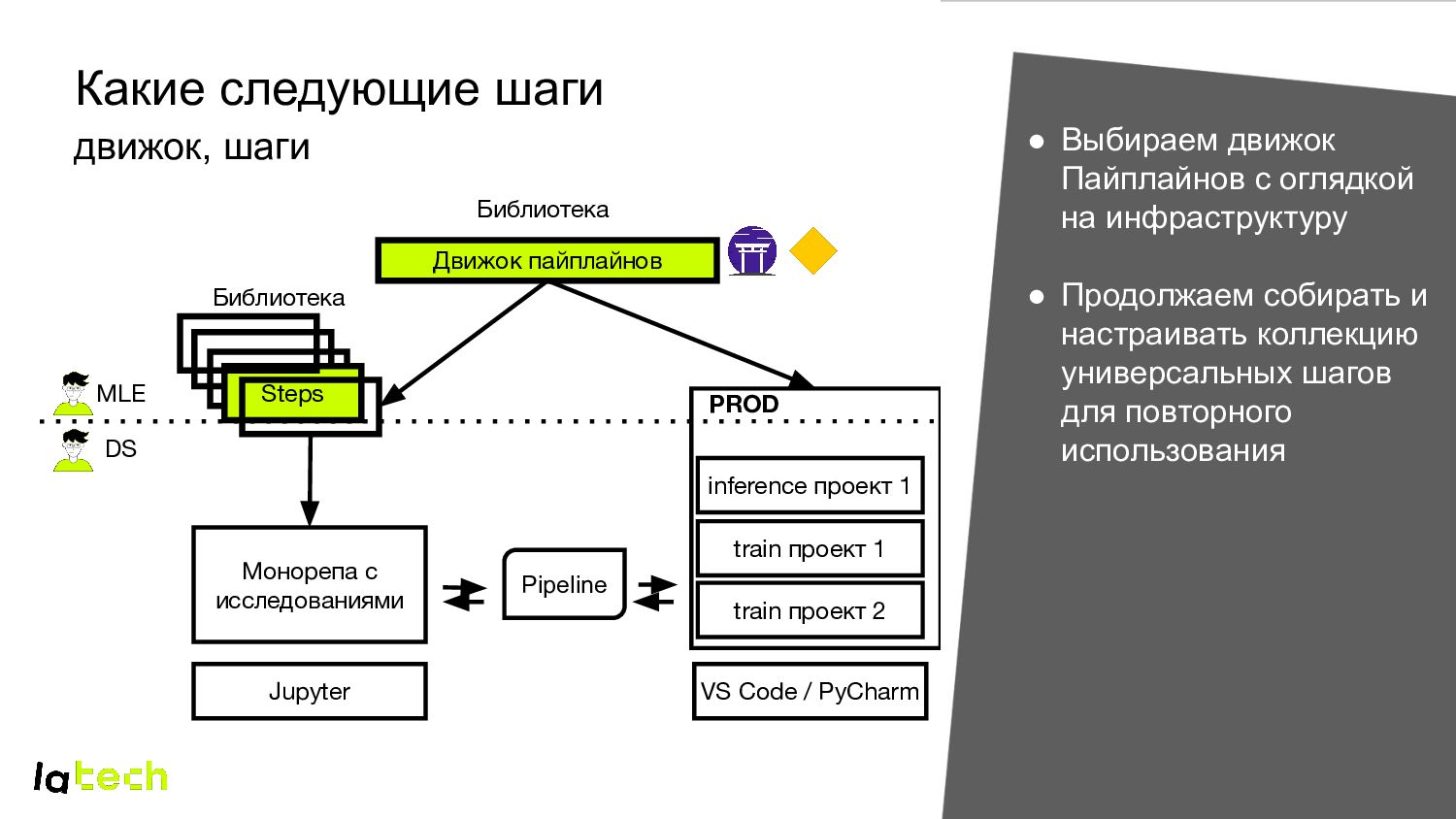
проект 2 Steps Jupyter VS Code / PyCharm PROD train проект 1 • Выбираем движок Пайплайнов с оглядкой на инфраструктуру MLE DS Pipeline Библиотека Библиотека inference проект 1
train проект 2 Steps Jupyter VS Code / PyCharm PROD train проект 1 • Выбираем движок Пайплайнов с оглядкой на инфраструктуру • Продолжаем собирать и настраивать коллекцию универсальных шагов для повторного использования MLE DS Pipeline Библиотека Библиотека inference проект 1
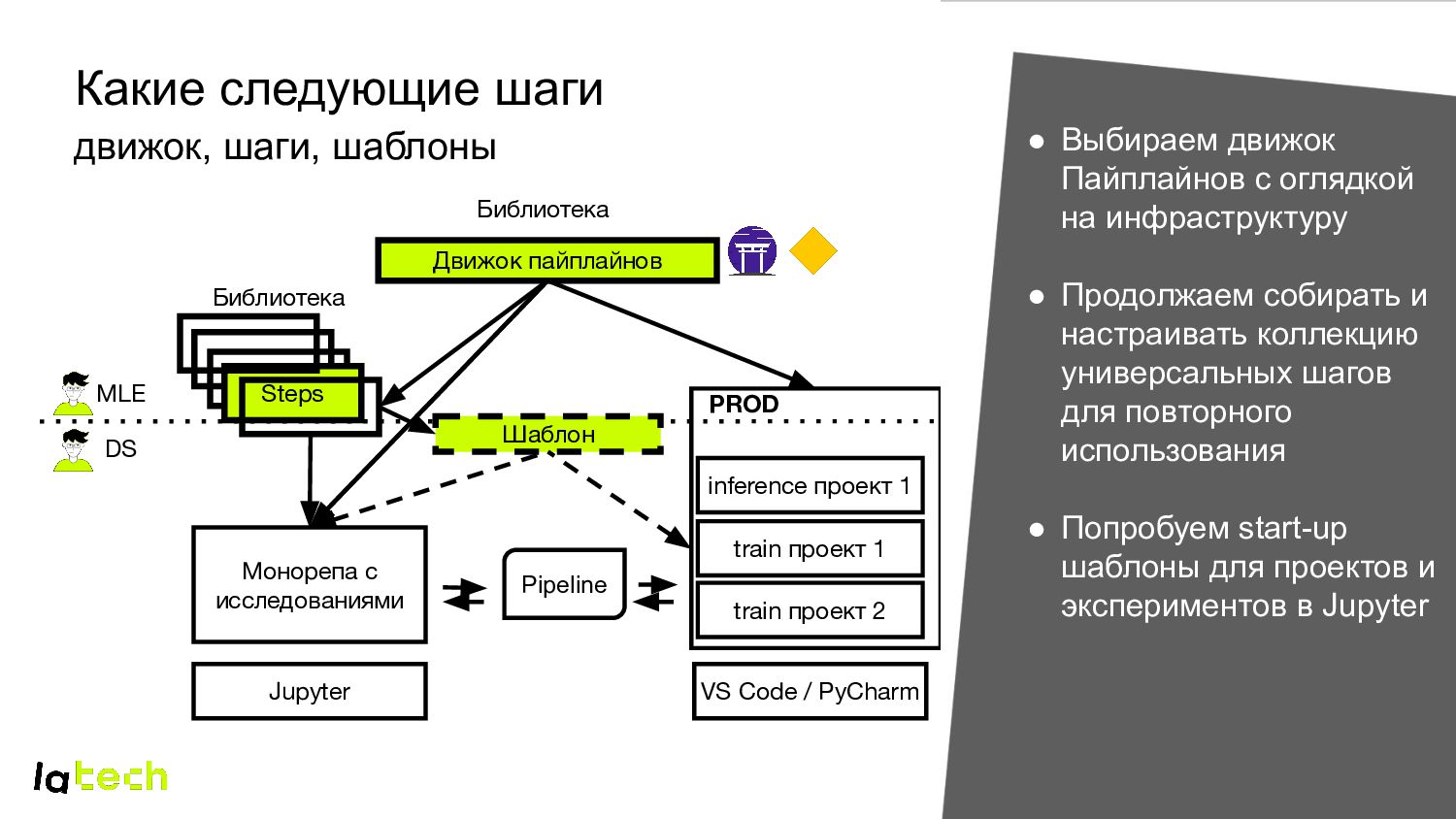
исследованиями train проект 2 Steps Jupyter VS Code / PyCharm PROD train проект 1 • Выбираем движок Пайплайнов с оглядкой на инфраструктуру • Продолжаем собирать и настраивать коллекцию универсальных шагов для повторного использования • Попробуем start-up шаблоны для проектов и экспериментов в Jupyter MLE DS Pipeline Библиотека Библиотека inference проект 1 Шаблон
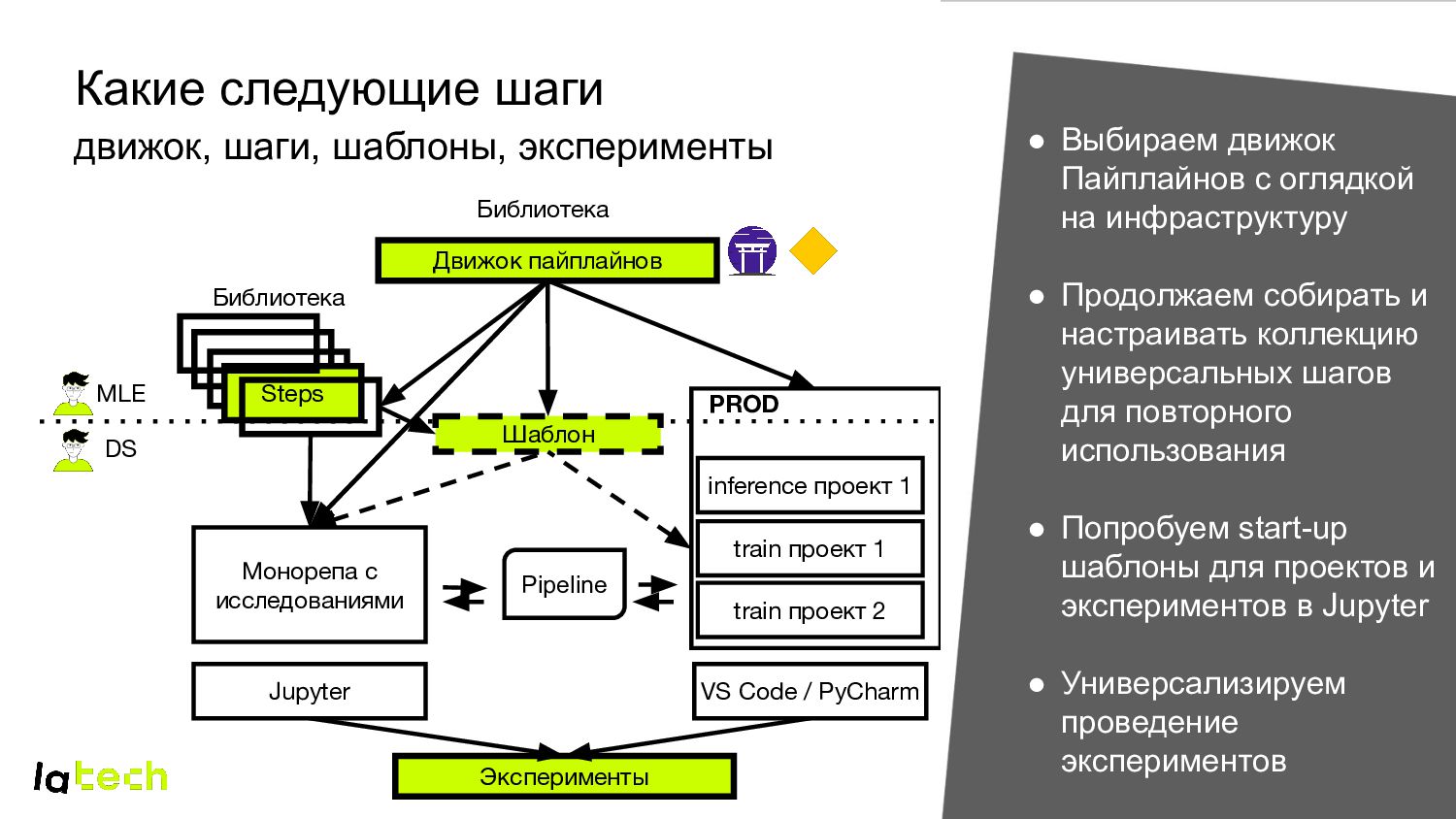
с исследованиями train проект 2 Steps Jupyter VS Code / PyCharm PROD train проект 1 • Выбираем движок Пайплайнов с оглядкой на инфраструктуру • Продолжаем собирать и настраивать коллекцию универсальных шагов для повторного использования • Попробуем start-up шаблоны для проектов и экспериментов в Jupyter • Универсализируем проведение экспериментов MLE DS Pipeline Библиотека inference проект 1 Шаблон Эксперименты Библиотека
код, который легче использовать повторно. 2. Пайплайны полезны для проведения экспериментов. 3. Шаги пайплайна удобно привязать к инфраструктуре, есть много фреймворков для этого, но выбрать, развернуть и привить любой из них в компании может быть не просто.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}