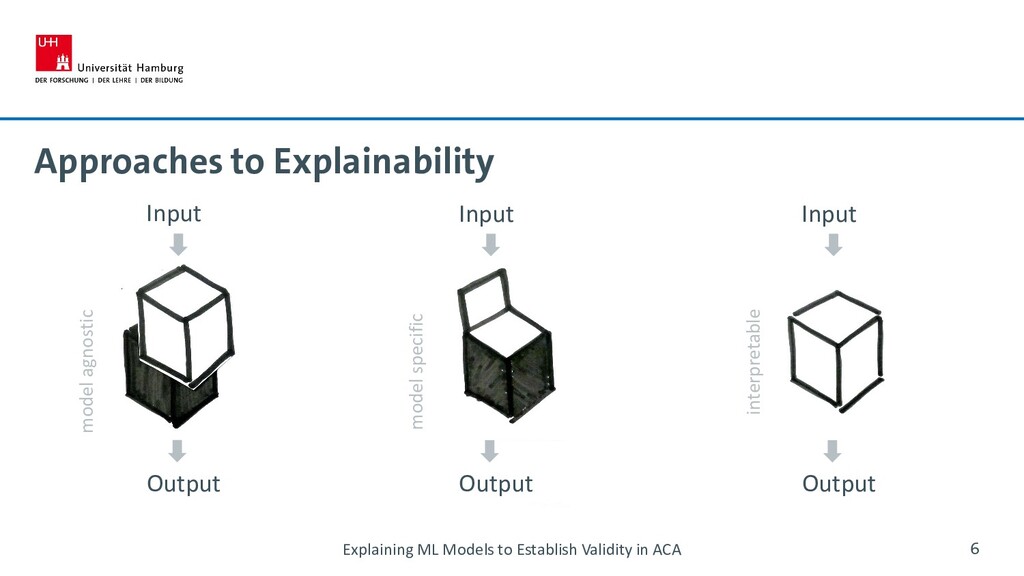
Due to growing amounts of data, accessible tutorials, and evolving computing capacities (Atteveldt and Peng, 2018), content analysis of text in particular is increasingly supported by machine learning methods (Boyd and Crawford, 2012; Trilling and Jonkman, 2018). In merging communication studies’ manual content analysis and machine learning’s supervised text classification, a model is trained to reproduce the labeling of concepts developed for and coded within a manually created corpus (Scharkow, 2012; Boumans and Trilling, 2016). While multiple strategies to measure reliability for automated content analysis (Scharkow, 2012; Krippendorff, 2019) and to increase reproducibility (Pineau, 2020; Mitchell et al., 2019) have recently been suggested, testing the validity of machine learning models is yet to be expanded. Some scholars suggest applying their model to a second dataset in order to test validity of inference (Pilny et al., 2019). Other scholars attempt to examine content validity by examining weights for individual features (Stoll et al., 2020). Based on systemic literature reviews, we have identified five model-agnostic methods, six methods specific to neural networks and three interpretable models which aim at explaining models for supervised text classification. We examine each solution with respect to how they may be leveraged to establish content validity in automated content analysis. We find that interpretable models show the most promise, yet are underrepresented in explainability research. Thus, we encourage communication researchers and machine learning experts to further collaborate on the development of such methods.
Presented at the 71st Annual Conference of the International Communication Association for the Computational Methods Division
Image on the final slide is user under a Creative Commons License from https://www.wocintechchat.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}