Streamlit è un progetto open source che permette di creare in pochi minuti delle data-web-app (e non solo) scrivendo solamente codice Python senza necessità di avere esperienza di front-end. In questa sessione scopriremo il suo funzionamento, come deployare un’app e vedremo un possibile caso d’uso.
Abstract
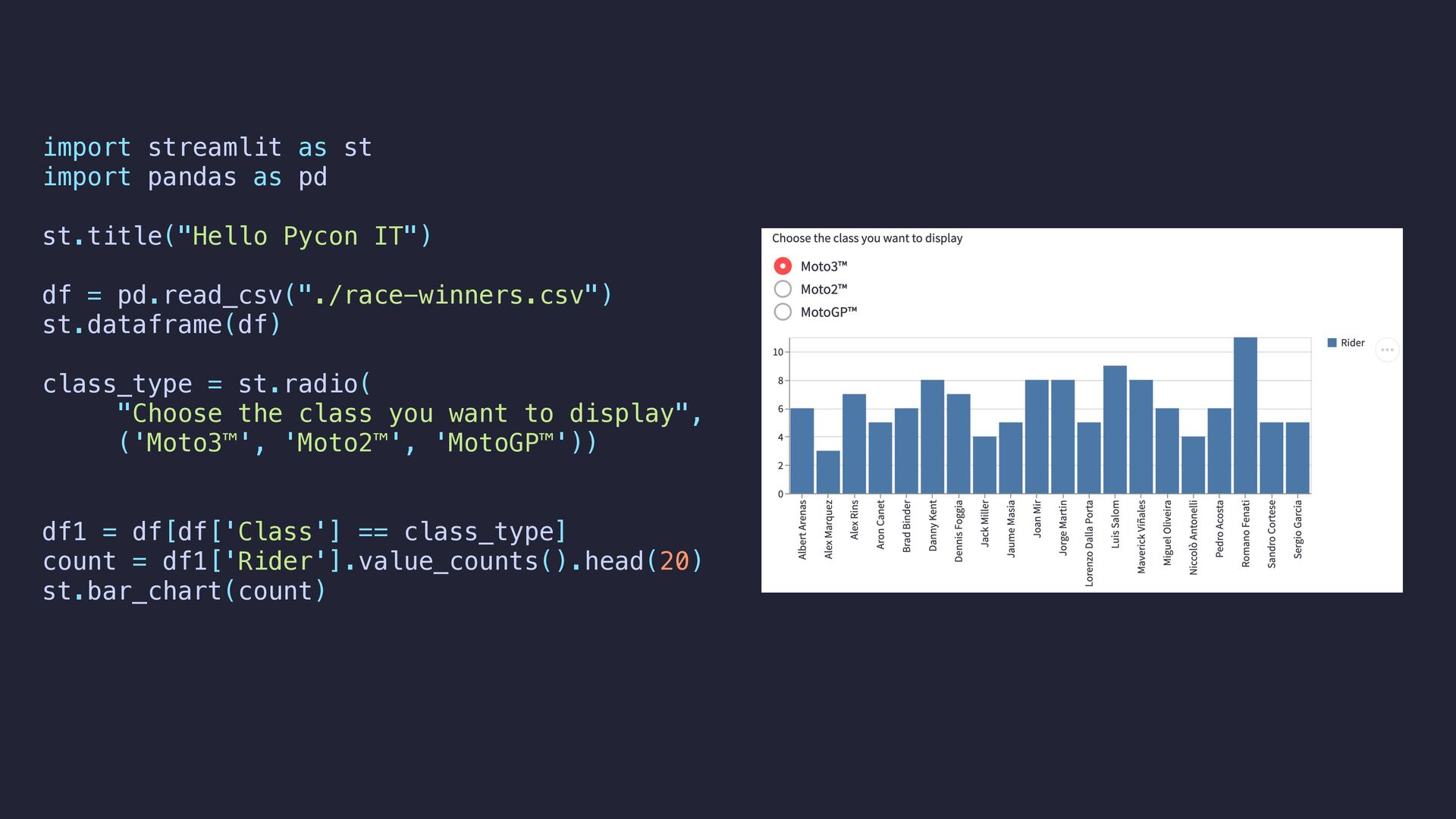
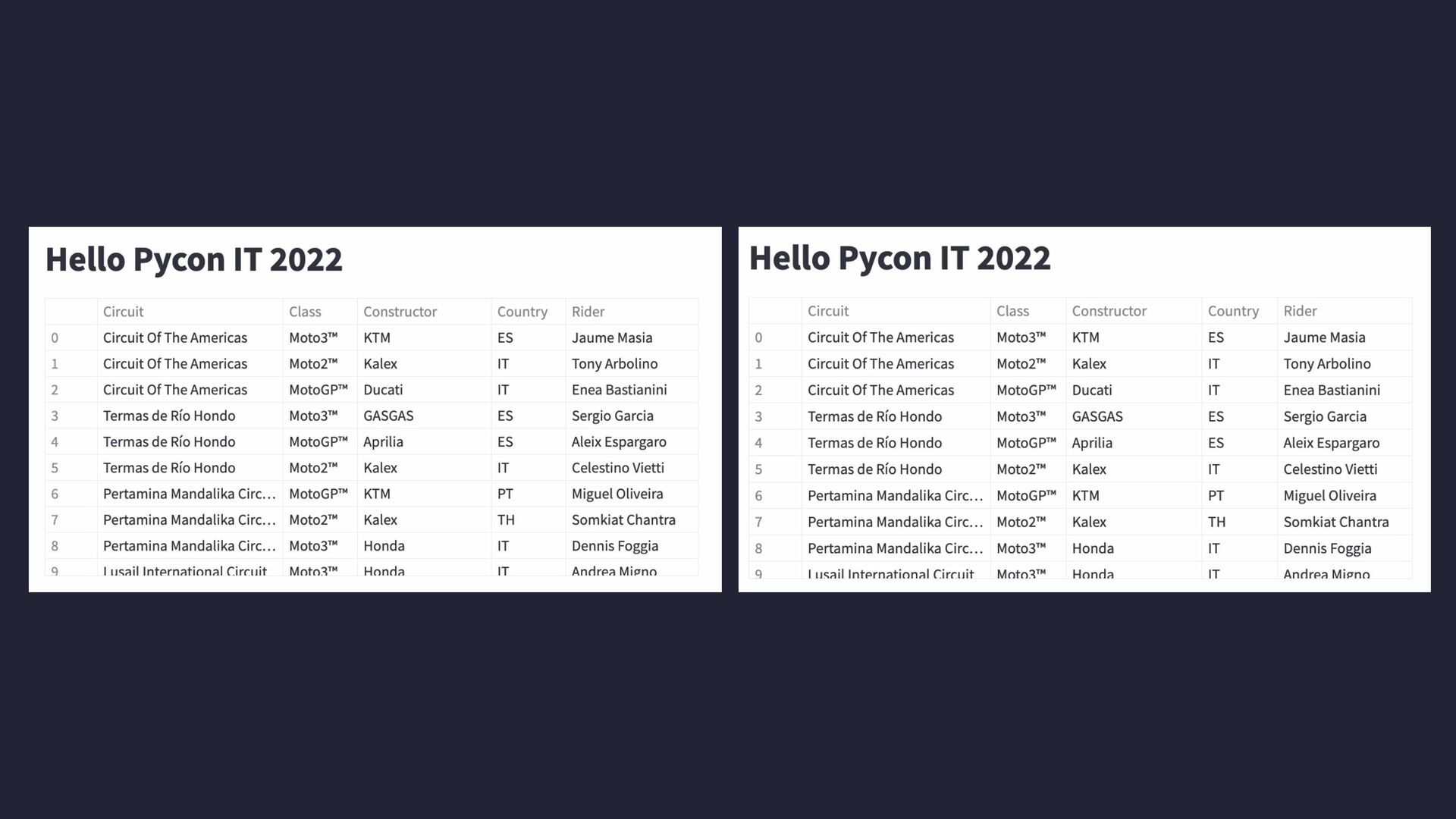
Vi è mai capitato di dover mostrare e spiegare i risultati di un progetto di analisi di dati? Non c’è sempre tempo e modo di sviluppare da zero una dashboard per l’occasione e presentare direttamente un jupyter notebook potrebbe non essere la soluzione ideale.
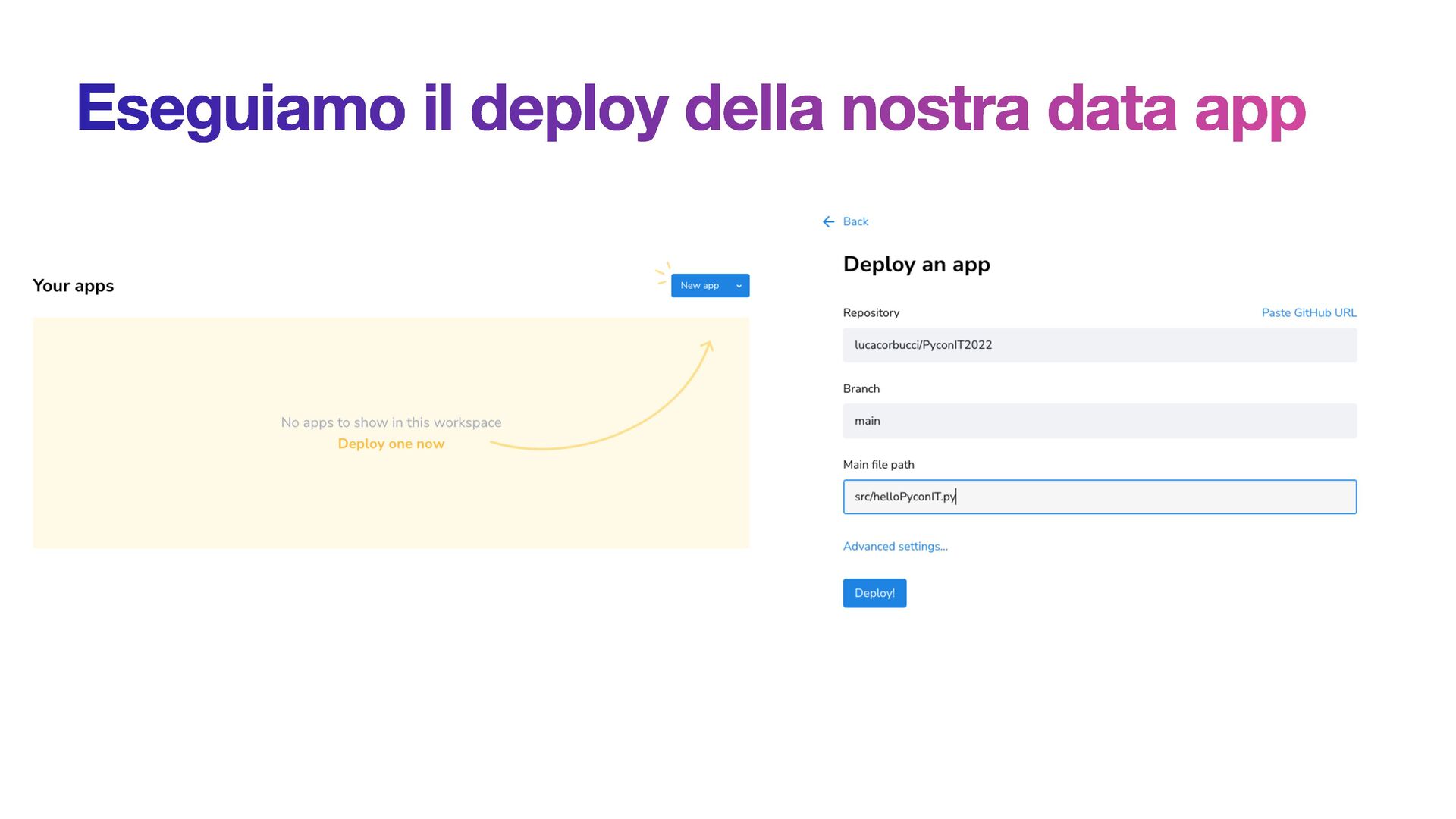
E qui arriva in soccorso Streamlit: si tratta di un progetto open source che permette di creare in pochissimi minuti una data-web-app (e non solo) scrivendo solamente codice Python senza necessità di avere esperienza di front-end.
In questa sessione scopriremo come funziona Streamlit, come deployare un’app e vedremo un possibile caso d’uso.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you @lucacorbucci 🌏 lucacorbucci.me 👨💻 github.com/lucacorbucci/ 📥 [email protected] 💬](https://files.speakerdeck.com/presentations/2af4521151614f76af99d8de5c65a7f0/slide_23.jpg){kind=link}