Perl's Regular Expression engine is the envy of all other languages -- notice how many use PCRE. You can parse almost anything with Perl's RE, if you don't go cross-eyed trying to read them first...
A bit of 20/20 hindsight is helping all of our vision these days, with Raku and its grammars. They allow for saner, layered processing of even complicated content.
This talk looks at basics of Raku RE and how they are used in grammars for parsing some real-world examples.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
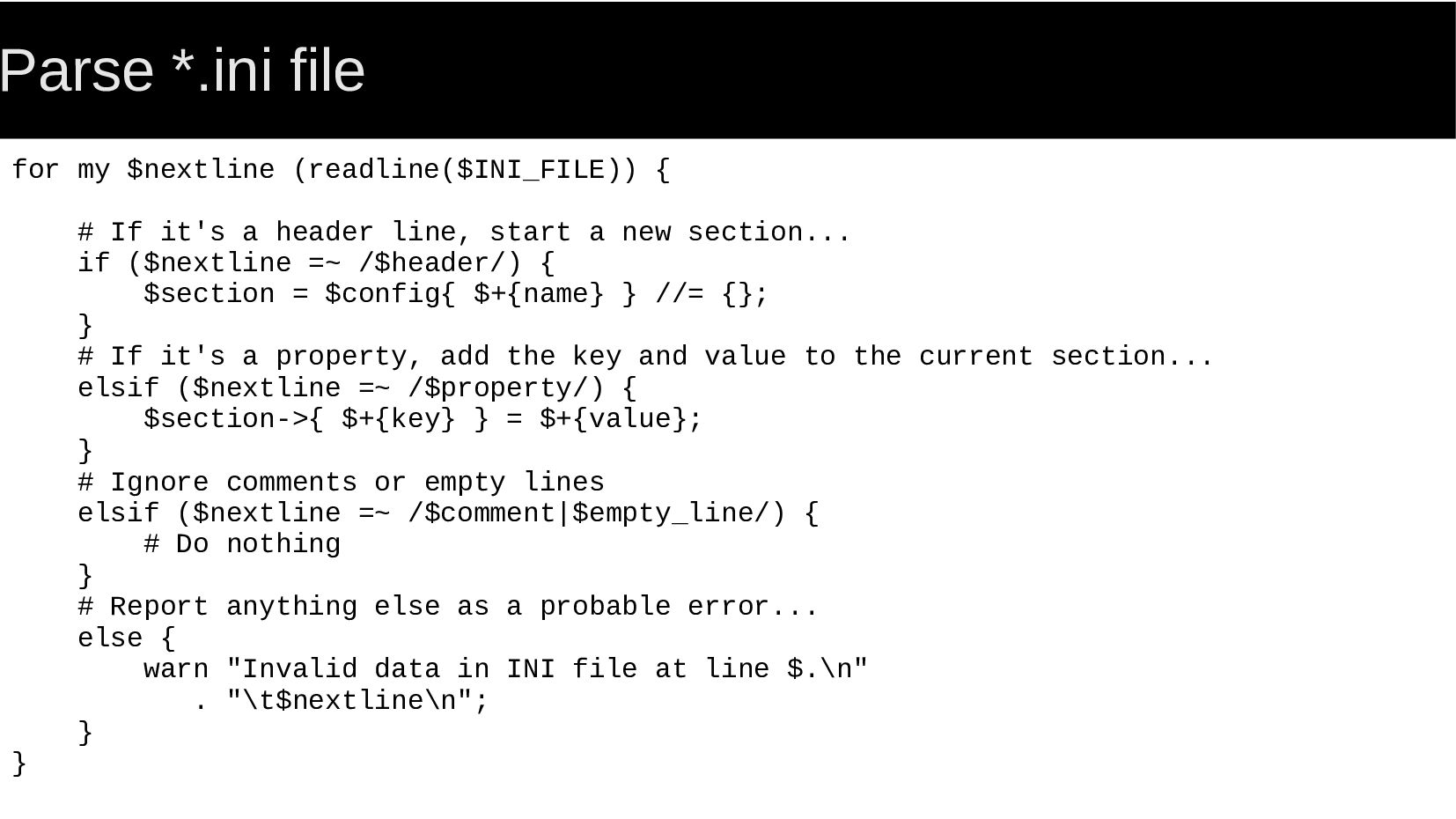{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Care to guess what this does? /{~}!@#$%^(&*)-+=[\/]:;"'<.,>?/](https://files.speakerdeck.com/presentations/65acc220ce2a473c8113c2f39853862a/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Perl6 nested regex #! /usr/bin/env rakudo use v6; '[1,2,[3,3,[4,4]],5]' ~~](https://files.speakerdeck.com/presentations/65acc220ce2a473c8113c2f39853862a/slide_43.jpg){kind=link}
![Perl6 nested regex #! /usr/bin/env rakudo use v6; '[1,2,[3,3,[4,4]],5]' ~~](https://files.speakerdeck.com/presentations/65acc220ce2a473c8113c2f39853862a/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}