Pure C/Java: q = p / 6 4 o w = w [ q ] ; n w = o w | ( 1 < < ( p % 6 4 ) ) ; c a r d i n a l i t y + = ( o w ^ n w ) > > ( p % 6 4 ) ; / / E X T R A w [ q ] = n w ; 4
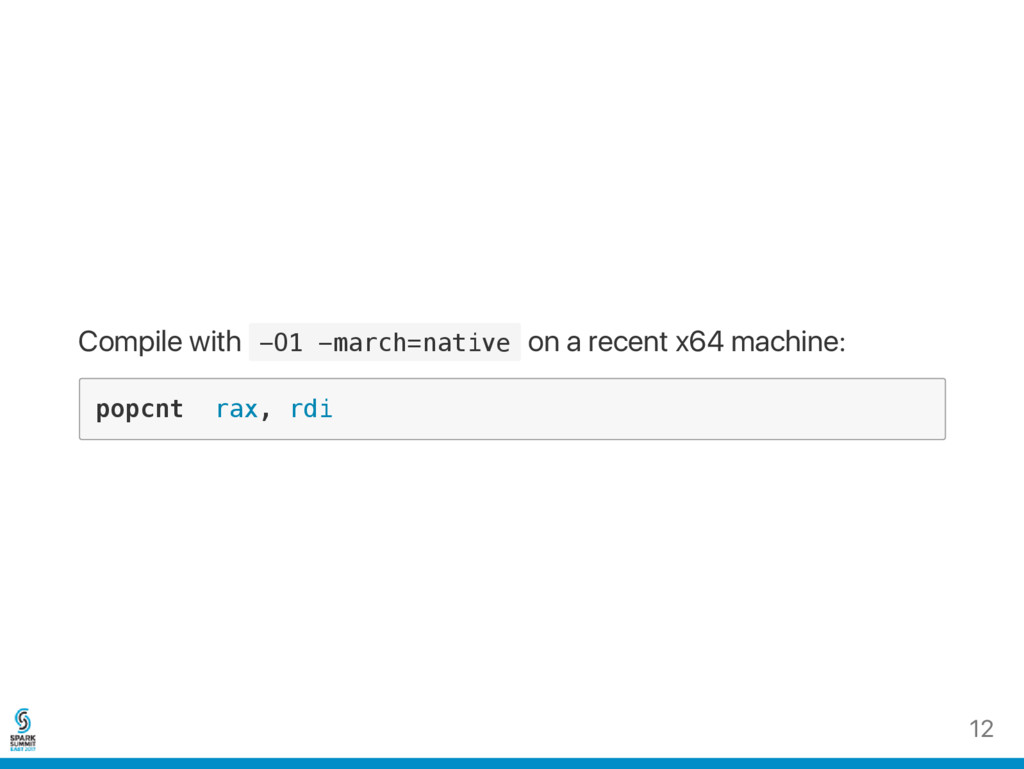
% [ 6 ] , % [ p ] , % [ q ] / / q = p / 6 4 m o v ( % [ w ] , % [ q ] , 8 ) , % [ o w ] / / o w = w [ q ] b t s % [ p ] , % [ o w ] / / o w | = ( 1 < < ( p % 6 4 ) ) + f l a g s b b $ - 1 , % [ c a r d i n a l i t y ] / / u p d a t e c a r d b a s e d o n f l a g m o v % [ l o a d ] , ( % [ w ] , % [ q ] , 8 ) / / w [ q ] = o w s b b is the extra work 5
result. If low, use an array for the result (slow), otherwise generate a bitset (fast). Union: Always generate a bitset (fast). (Unless cardinality is high then maybe create a run!) We generally keep track of the cardinality of the result. 8
i n t c = 0 ; f o r ( i n t k = 0 ; k < 1 0 2 4 ; + + k ) { c + = L o n g . b i t C o u n t ( A [ k ] & B [ k ] ) ; } We have 1024 calls to L o n g . b i t C o u n t . This counts the number of 1s in a 64‑bit word. 9
e r ` s D e l i g h t i n t b i t C o u n t ( l o n g i ) { / / H D , F i g u r e 5 - 1 4 i = i - ( ( i > > > 1 ) & 0 x 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 L ) ; i = ( i & 0 x 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 L ) + ( ( i > > > 2 ) & 0 x 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 L ) ; i = ( i + ( i > > > 4 ) ) & 0 x 0 f 0 f 0 f 0 f 0 f 0 f 0 f 0 f L ; i = i + ( i > > > 8 ) ; i = i + ( i > > > 1 6 ) ; i = i + ( i > > > 3 2 ) ; r e t u r n ( i n t ) i & 0 x 7 f ; } Sounds expensive? 10
C compiler c l a n g compiles this code? # i n c l u d e < s t d i n t . h > i n t c o u n t ( u i n t 6 4 _ t x ) { i n t v = 0 ; w h i l e ( x ! = 0 ) { x & = x - 1 ; v + + ; } r e t u r n v ; } 11
e r ` s D e l i g h t i n t b i t C o u n t ( l o n g i ) { / / H D , F i g u r e 5 - 1 4 i = i - ( ( i > > > 1 ) & 0 x 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 L ) ; i = ( i & 0 x 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 L ) + ( ( i > > > 2 ) & 0 x 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 L ) ; i = ( i + ( i > > > 4 ) ) & 0 x 0 f 0 f 0 f 0 f 0 f 0 f 0 f 0 f L ; i = i + ( i > > > 8 ) ; i = i + ( i > > > 1 6 ) ; i = i + ( i > > > 3 2 ) ; r e t u r n ( i n t ) i & 0 x 7 f ; } 14
c n t if hardware supports it $ j a v a - X X : + P r i n t F l a g s F i n a l | g r e p U s e P o p C o u n t I n s t r u c t i o n b o o l U s e P o p C o u n t I n s t r u c t i o n = t r u e But only if you call it from L o n g . b i t C o u n t 15
C o u n t , I n t e g e r . b i t C o u n t I n t e g e r . r e v e r s e B y t e s , L o n g . r e v e r s e B y t e s I n t e g e r . n u m b e r O f L e a d i n g Z e r o s , L o n g . n u m b e r O f L e a d i n g Z e r o s I n t e g e r . n u m b e r O f T r a i l i n g Z e r o s , L o n g . n u m b e r O f T r a i l i n g Z e r o s S y s t e m . a r r a y c o p y ... 16
i n t c = 0 ; f o r ( i n t k = 0 ; k < 1 0 2 4 ; + + k ) { c + = L o n g . b i t C o u n t ( A [ k ] & B [ k ] ) ; } A bit over ≈ 2 cycles per pair of 64‑bit words. load A, load B bitwise AND p o p c n t 17
O(m log n) if the sizes differs a lot. i n t i n t e r s e c t ( A , B ) { i f ( A . l e n g t h * 2 5 < B . l e n g t h ) { r e t u r n g a l l o p i n g ( A , B ) ; } e l s e i f ( B . l e n g t h * 2 5 < A . l e n g t h ) { r e t u r n g a l l o p i n g ( B , A ) ; } e l s e { r e t u r n b o r i n g _ i n t e r s e c t i o n ( A , B ) ; } } 19
large one... w h i l e ( t r u e ) { i f ( l a r g e S e t [ k 1 ] < s m a l l S e t [ k 2 ] ) { f i n d k 1 b y b i n a r y s e a r c h s u c h t h a t l a r g e S e t [ k 1 ] > = s m a l l S e t [ k 2 ] } i f ( s m a l l S e t [ k 2 ] < l a r g e S e t [ k 1 ] ) { + + k 2 ; } e l s e { / / g o t a m a t c h ! ( s m a l l S e t [ k 2 ] = = l a r g e S e t [ k 1 ] ) } } If the small set is tiny, runs in O(log(size of big set)) 20
large, go for a bitset. Revert to an array if we got it wrong. u n i o n ( A , B ) { t o t a l = A . l e n g t h + B . l e n g t h ; i f ( t o t a l > D E F A U L T _ M A X _ S I Z E ) { / / b i t m a p ? c r e a t e e m p t y b i t m a p C a n d a d d b o t h A a n d B t o i t i f ( C . c a r d i n a l i t y < = D E F A U L T _ M A X _ S I Z E ) { c o n v e r t C t o a r r a y } e l s e i f ( C i s f u l l ) { c o n v e r t C t o r u n } e l s e { C i s f i n e a s a b i t m a p } } o t h e r w i s e m e r g e t w o a r r a y s a n d o u t p u t a r r a y } 21
to 16 cycles per array value): a n s w e r = n e w a r r a y f o r v a l u e i n a r r a y { i f v a l u e i n b i t s e t { a p p e n d v a l u e t o a n s w e r } } 22
e r = n e w a r r a y p o s = 0 f o r v a l u e i n a r r a y { a n s w e r [ p o s ] = v a l u e p o s + = b i t _ v a l u e ( b i t s e t , v a l u e ) } 23
cycles per value in array. a n s w e r = c l o n e t h e b i t s e t f o r v a l u e i n a r r a y { / / b r a n c h l e s s s e t b i t i n a n s w e r a t i n d e x v a l u e } Without tracking the cardinality ≈ 1.65 cycles per value Tracking the cardinality ≈ 2.2 cycles per value 24
commodity processors support Single instruction, multiple data (SIMD) instructions. Raspberry Pi Your phone Your PC Working with words x × larger has the potential of multiplying the performance by x. No lock needed. Purely deterministic/testable. 25
16‑bit integers is not 2 × faster than 32‑bit integers. But with SIMD instructions, going from 64‑bit integers to 16‑bit integers can mean 4 × gain. Roaring uses arrays of 16‑bit integers. 27
computed fast with Single instruction, multiple data (SIMD) instructions. Intel Cannonlake (late 2017), AVX‑512 Operate on 64 bytes with ONE instruction → Several 512‑bit ops/cycle Java 9's Hotspot can use AVX 512 ARM v8‑A to get Scalable Vector Extension... up to 2048 bits!!! 28
_ t i = 0 ; i < l e n ; i + + ) { a [ i ] | = b [ i ] ; } using scalar : 1.5 cycles per byte with AVX2 : 0.43 cycles per byte (3.5 × better) With AVX‑512, the performance gap exceeds 5 × Can also vectorize OR, AND, ANDNOT, XOR + population count (AVX2‑Harley‑Seal) 30
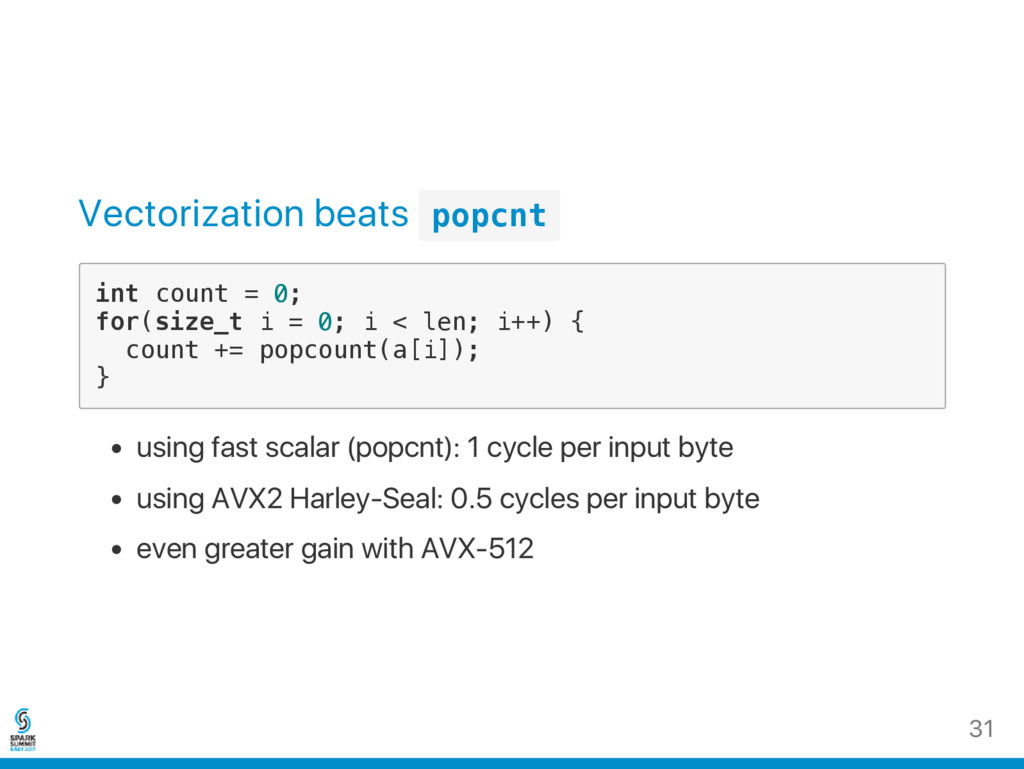
t c o u n t = 0 ; f o r ( s i z e _ t i = 0 ; i < l e n ; i + + ) { c o u n t + = p o p c o u n t ( a [ i ] ) ; } using fast scalar (popcnt): 1 cycle per input byte using AVX2 Harley‑Seal: 0.5 cycles per input byte even greater gain with AVX‑512 31
for binding closely to hardware is to process wider data flows in SIMD modes. (And IMO this is a long‑term trend towards right‑sizing data channel widths, as hardware grows wider in various ways.) AVX bindings are where we are experimenting, today (John Rose, Oracle) 34
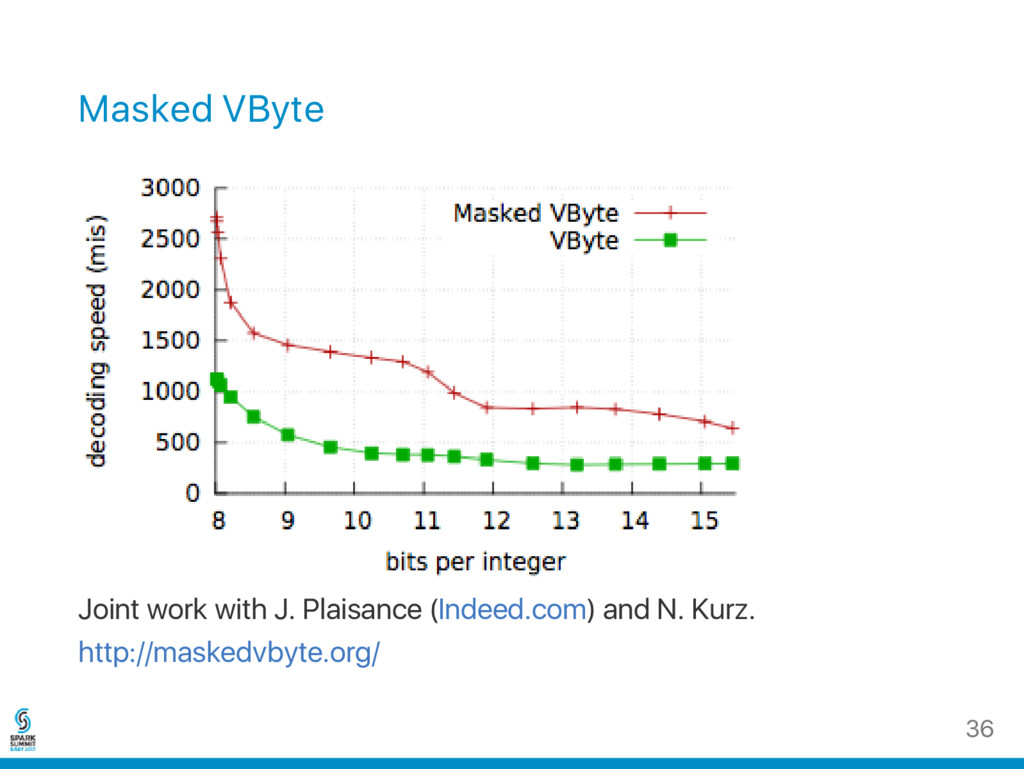
the ubiquitous VByte format: Use 1 byte to store all integers in [0, 2 ) Use 2 bytes to store all integers in [2 , 2 ) ... Decoding can become a bottleneck. Google developed Varint‑GB. What if you are stuck with the conventional format? (E.g., Lucene, LEB128, Protocol Buffers...) 7 7 14 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}