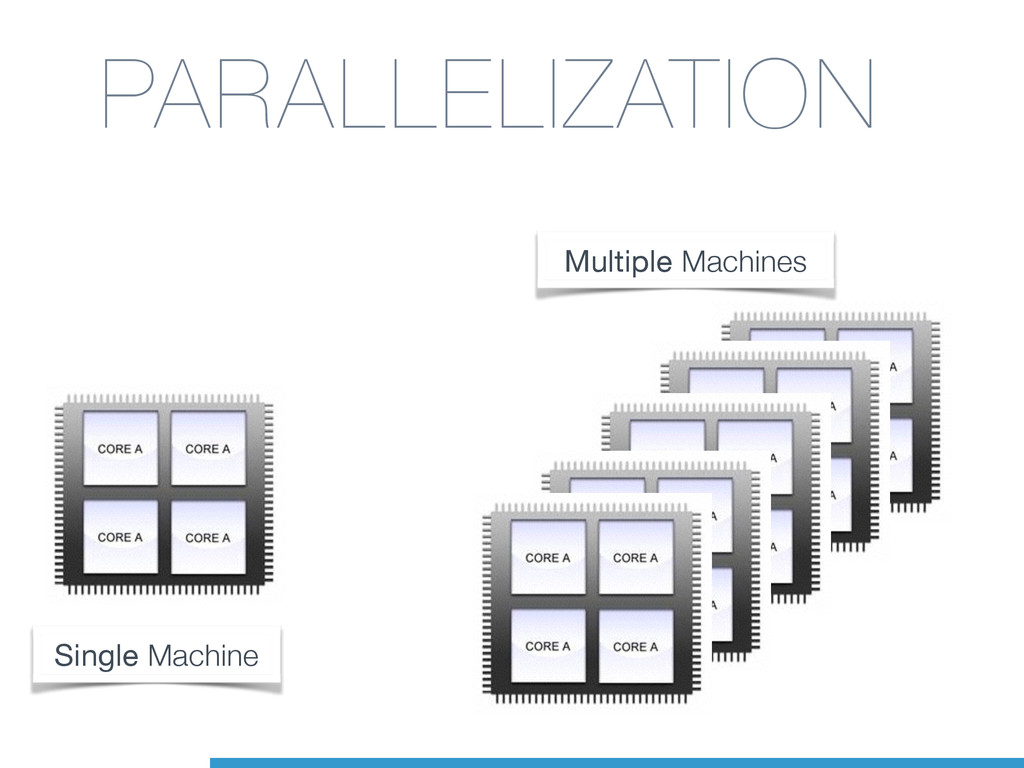
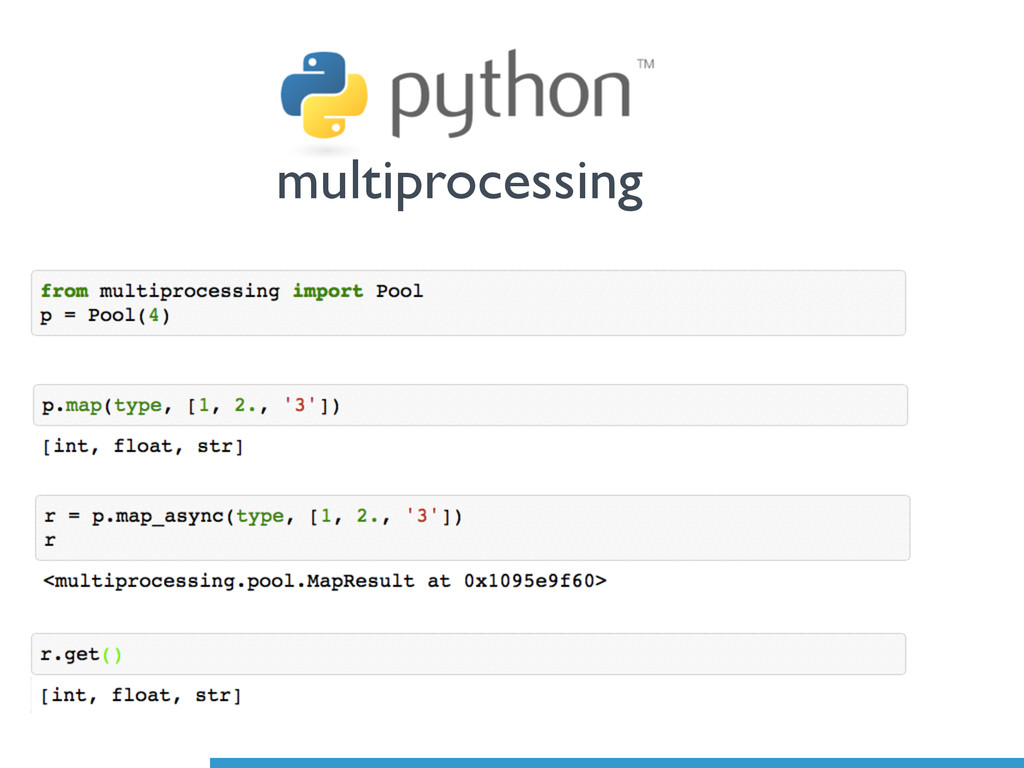
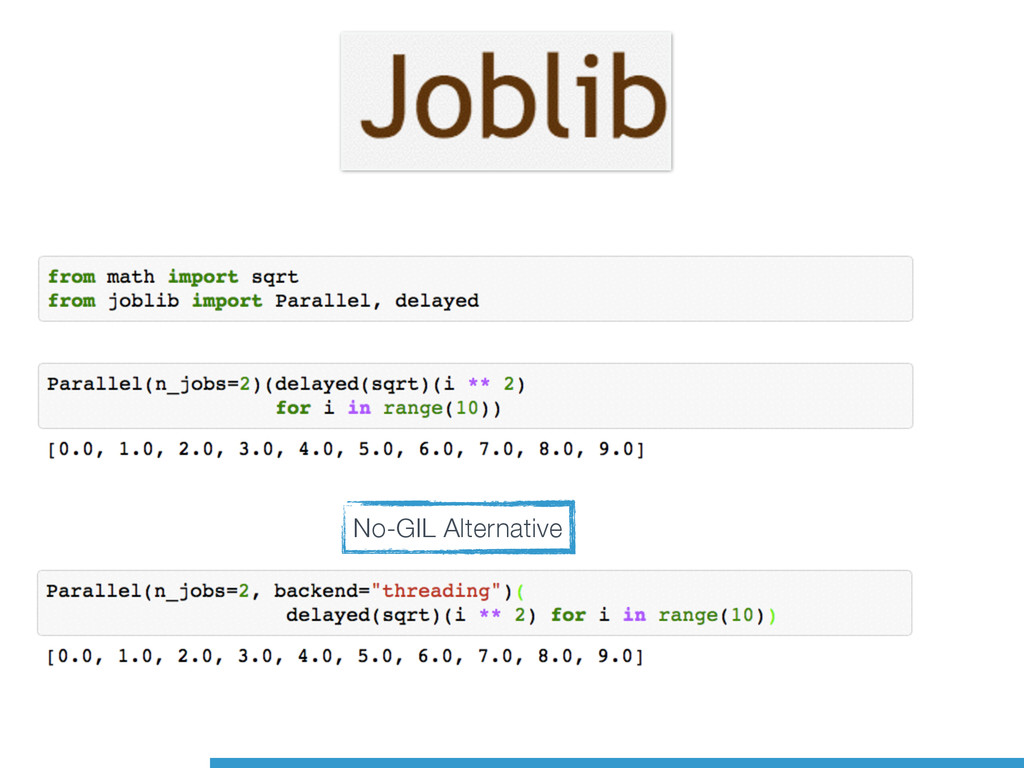
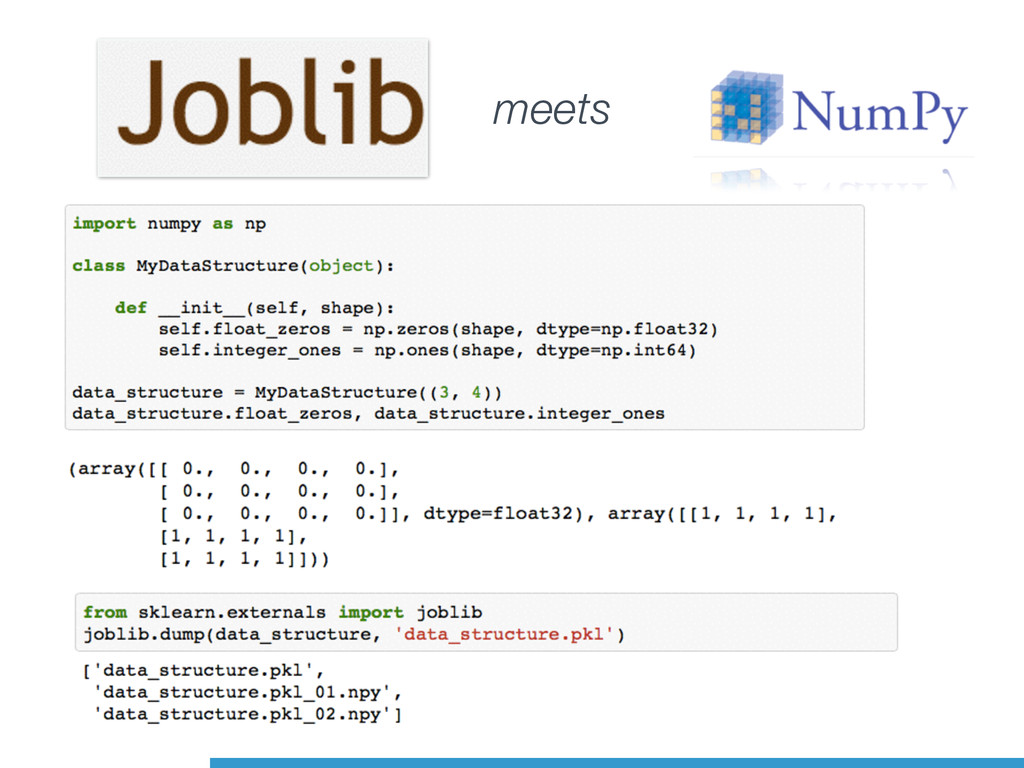
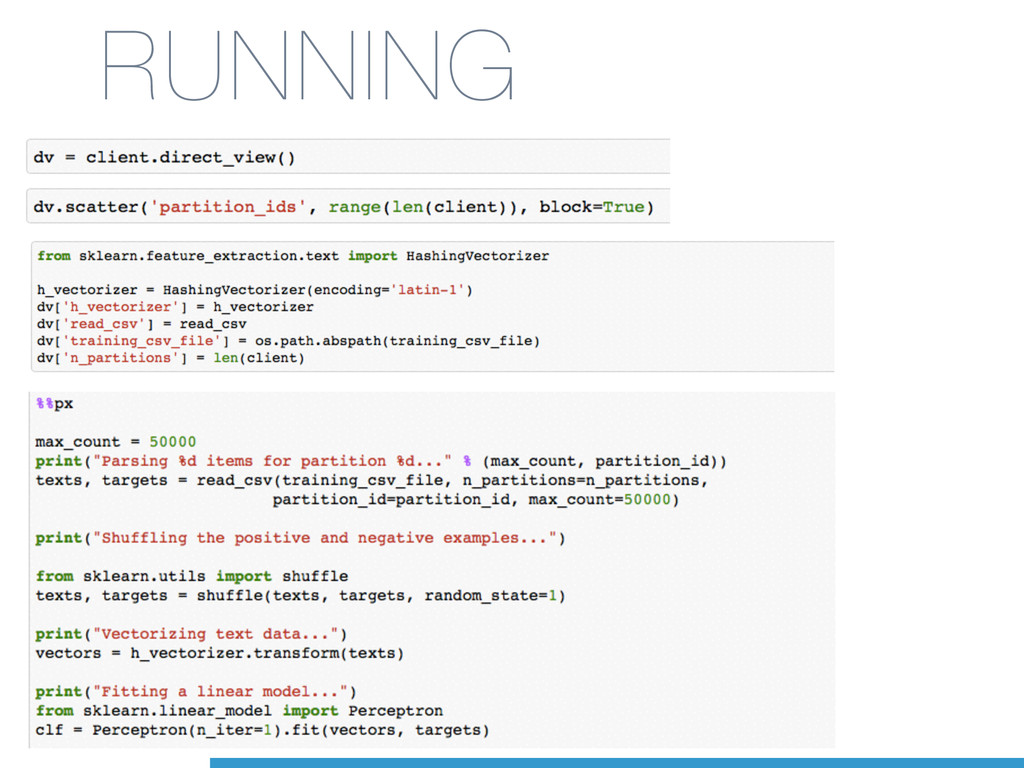
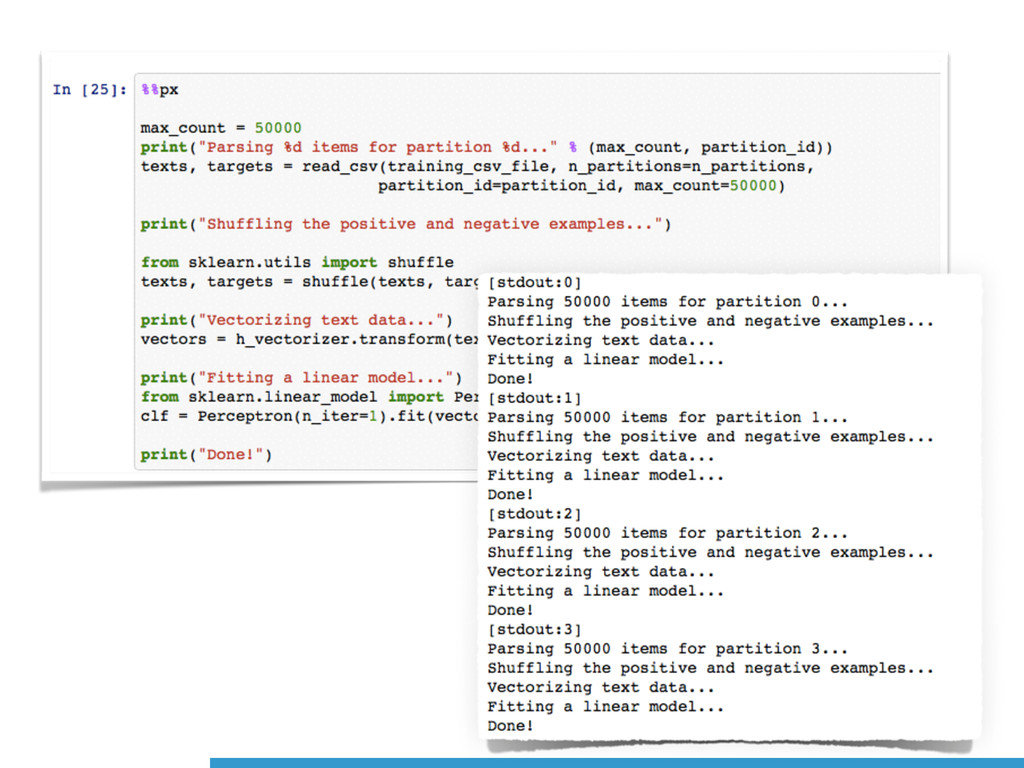
Cross-Platform support (even Windows!) • Improved in Python 3.4 • Py 3.4.3: spawn instead of fork on Unix • Some support for shared memory • Support for synchronisation (lock) multiprocessing
to integer feature indices • A Big Python dict: slow to (un)pickle • Large Corpus: ~106 tokens • Vocabulary == Statefulness == Sync barrier • No easy way to run in parallel
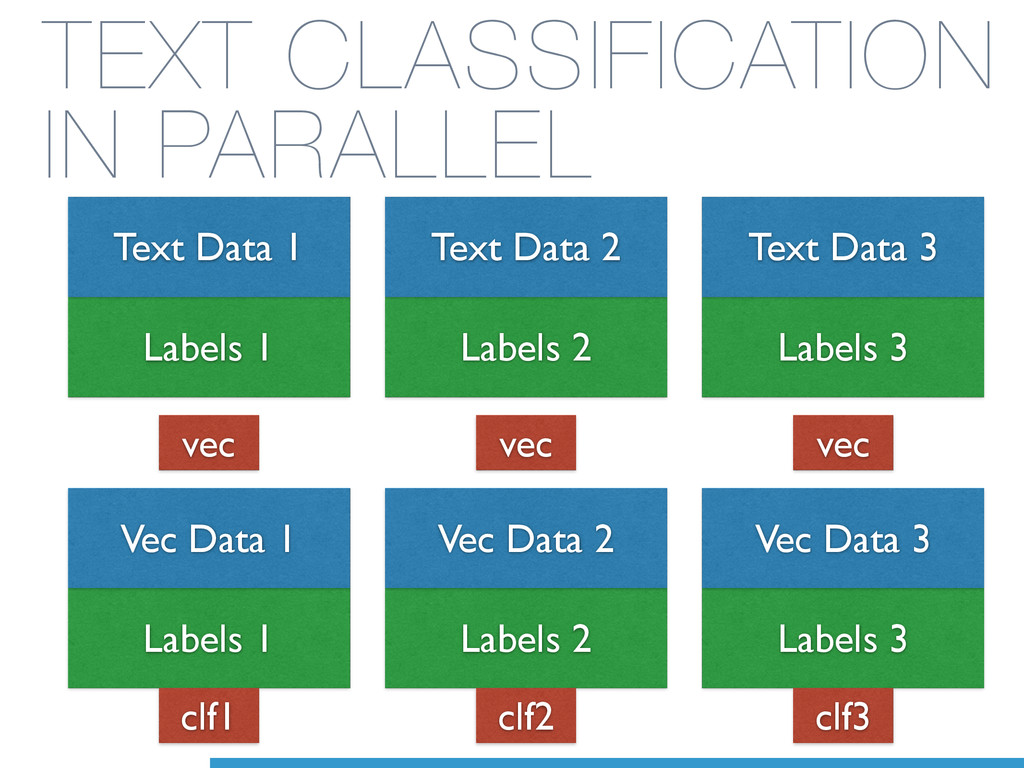
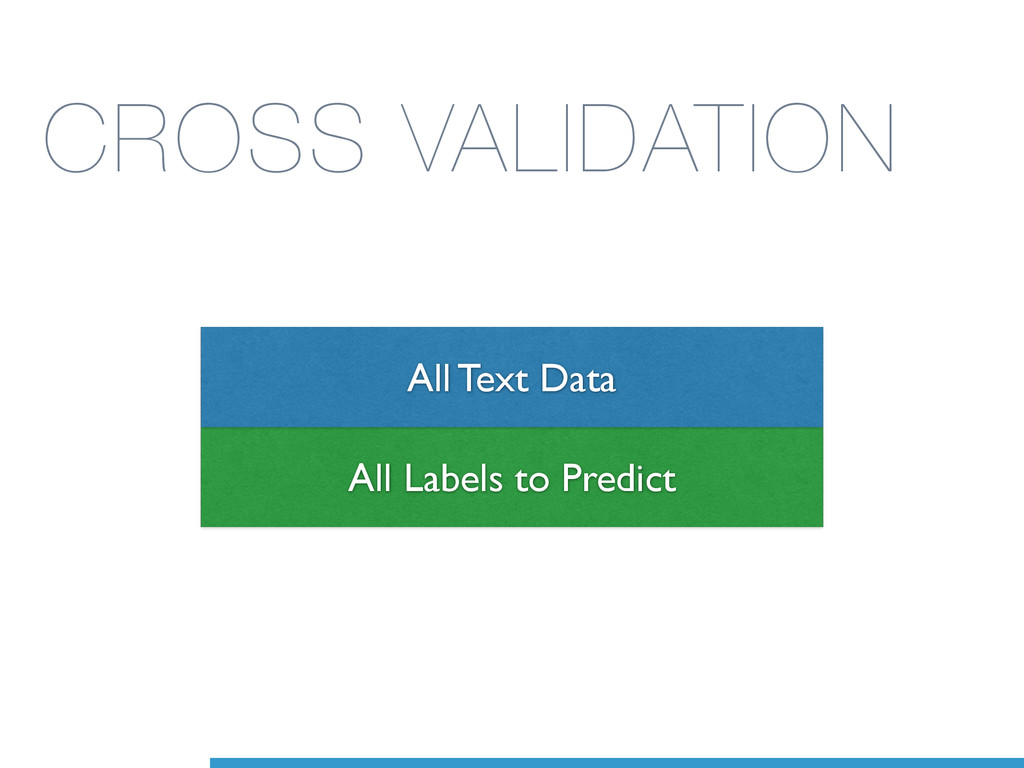
Data 2 Test Labels 3 Test Data 3 Train Labels 1 Train Data 1 Train Labels 3 Train Data 3 Test Labels 2 Test Data 2 Train Labels 2 Train Data 2 Train Labels 3 Train Data 3 Test Labels 1 Test Data 1
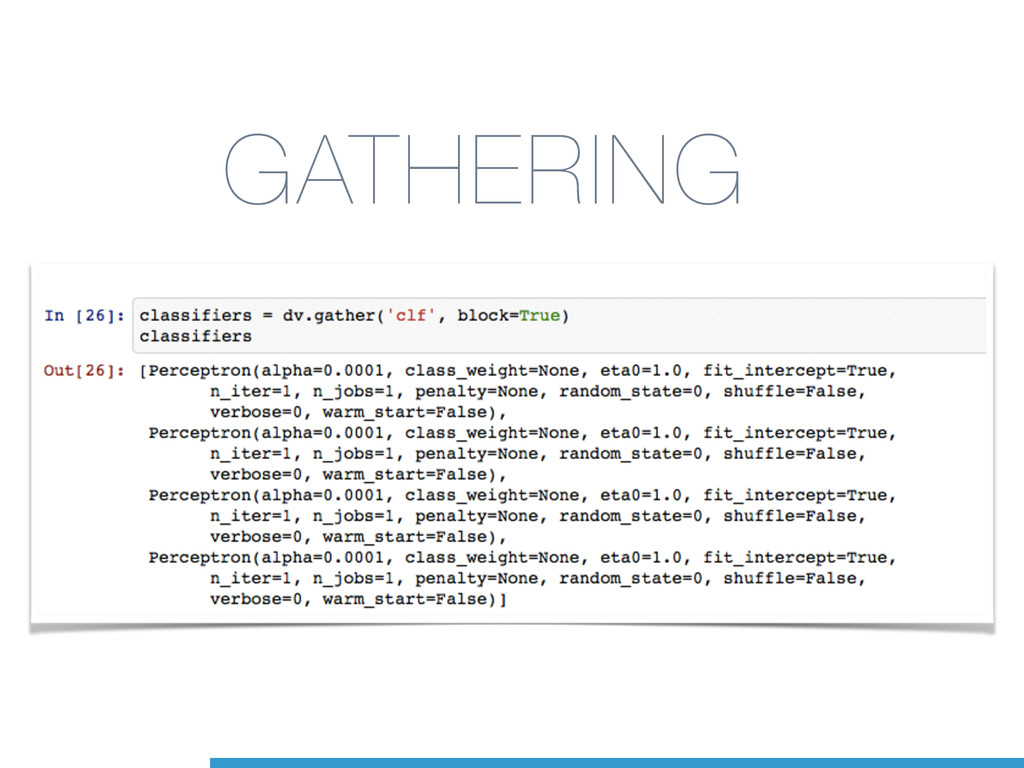
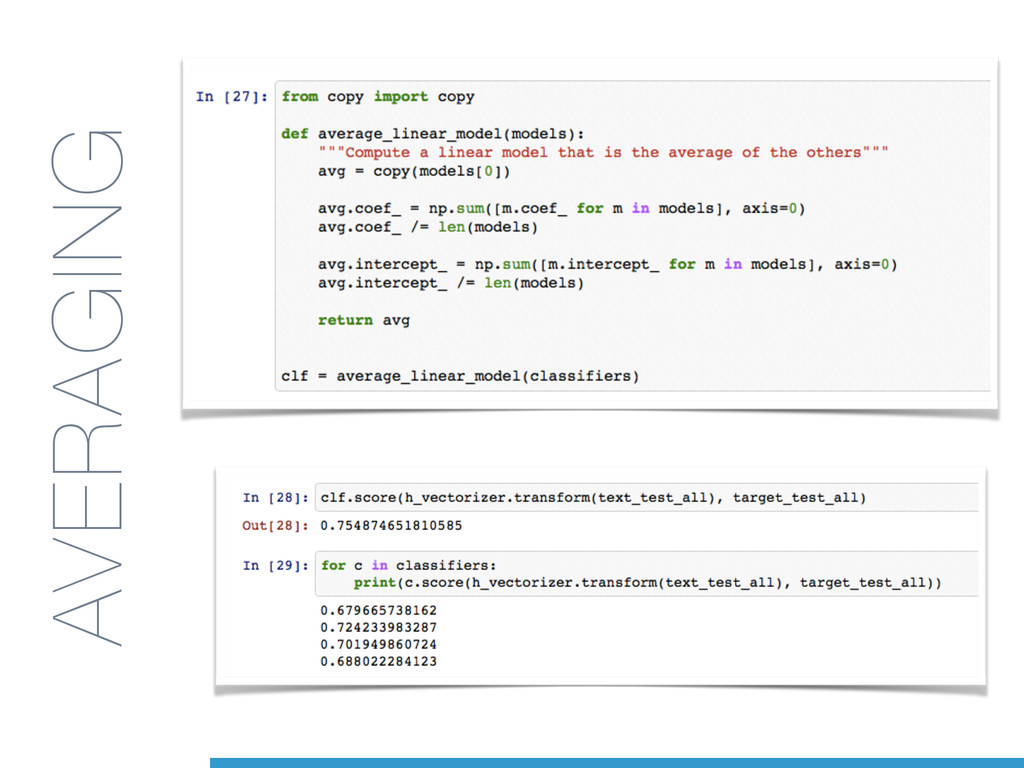
learning model on a dataset that does not fit in the main memory. • a feature extraction layer with fixed output dimensionality • knowing the list of all classes in advance • a machine learning algorithm that supports incremental learning (a.k.a. Online Learning) • the partial_fit method in scikit-learn.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS FOR YOUR KIND ATTENTION [email protected] @leriomaggio +ValerioMaggio](https://files.speakerdeck.com/presentations/6cb6976fd5534afba3b49c3e1e67f1fc/slide_73.jpg){kind=link}